Recognition: 2 theorem links
· Lean TheoremBeyond Thinking: Imagining in 360^circ for Humanoid Visual Search
Pith reviewed 2026-05-12 02:48 UTC · model grok-4.3
The pith
A single-step probabilistic predictor of semantic layouts lets humanoids search 360° scenes efficiently without building cumulative reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
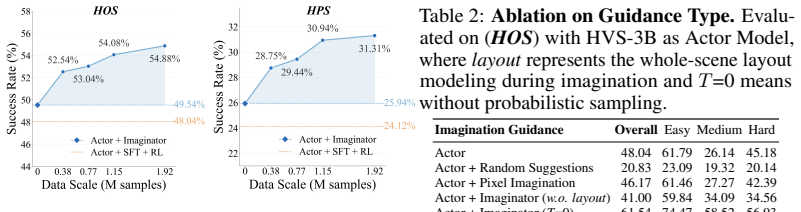
By replacing cumulative multi-turn reasoning with a single-step probabilistic Imaginator that infers semantic spatial priors for observed and unobserved areas and supplies a distribution of hypotheses to the Actor, the framework supplies robust guidance that hedges uncertainty, eliminates trajectory-level annotations, and yields large training sets that improve efficiency and success rates in in-the-wild 360° search.
What carries the argument
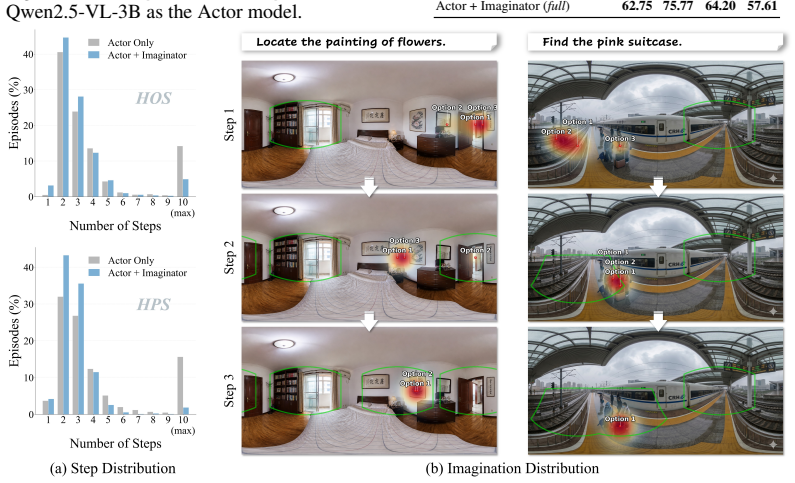
The Imaginator, a probabilistic model that predicts full semantic spatial layouts of both observed and unobserved regions in one step and samples multiple hypotheses to guide the Actor.
If this is right
- Full-trajectory Chain-of-Thought annotations are no longer required, allowing generation of over 1.96 million curated training samples.
- Multiple sampled hypotheses from the semantic prior hedge uncertainty and reduce dead-end explorations.
- Search efficiency and success rates rise in complex, in-the-wild 360° environments compared with monolithic reasoning approaches.
- The cognitive load of maintaining long reasoning chains is removed from the action policy.
Where Pith is reading between the lines
- The same single-step prior prediction could be tested in other embodied tasks such as object manipulation or long-range navigation where full-scene semantics matter.
- Training data volume could grow further if the Imaginator is trained on synthetic 360° renderings rather than real trajectories.
- In dynamic scenes the framework might need an update rule that refreshes the prior after each new observation while keeping the single-step structure.
Load-bearing premise
That a single probabilistic prediction of semantic layouts can supply enough robust guidance to hedge uncertainty without needing iterative multi-turn reasoning.
What would settle it
A head-to-head test in environments with high visual ambiguity or sudden changes where the single-step predictions produce lower success rates or longer paths than cumulative-reasoning baselines.
Figures







read the original abstract
Humanoid Visual Search (HVS) requires agents to actively explore immersive 360$^\circ$ environments. While prior methods treat this as a monolithic task relying on cumulative, multi-turn Chain-of-Thought (CoT) reasoning, they impose heavy cognitive burdens and require expensive trajectory-level annotations. In this paper, we propose Imagining in 360$^\circ$, a novel framework that decouples the exploration process into a specialized Imaginator and an Actor. The Imaginator functions as a probabilistic predictor of spatial priors; instead of maintaining a cumulative reasoning chain, it infers the semantic layout of both observed and unobserved regions in a single step. By sampling multiple hypotheses within this semantic space, we provide the Actor with a distribution of effective spatial information, offering robust guidance that hedges against uncertainty during active search. This decoupled architecture significantly lowers data engineering costs by eliminating the need for full-trajectory CoT annotations, enabling the generation of over 1.96 million curated training samples. Extensive experiments demonstrate that explicitly modeling semantic spatial priors drastically improves search efficiency and success rates in complex, in-the-wild environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'Imagining in 360°', a decoupled framework for Humanoid Visual Search (HVS) in immersive 360° environments. It introduces an Imaginator module that performs single-step probabilistic prediction of semantic spatial layouts over both observed and unobserved regions, sampling multiple hypotheses to guide an Actor module. This replaces cumulative multi-turn Chain-of-Thought reasoning, reduces annotation costs, and enables creation of a 1.96 million sample dataset. The central claim is that explicitly modeling these semantic priors yields substantial gains in search efficiency and success rates in complex in-the-wild settings.
Significance. If the experimental claims hold with proper controls, the work could meaningfully advance efficient active perception for humanoid agents by shifting from heavy reasoning chains to prior-based hypothesis sampling. The scale of the curated dataset is a concrete strength that may support future research in robotics and embodied AI.
major comments (3)
- [Abstract] Abstract: the assertion of 'drastically improves search efficiency and success rates' is load-bearing for the contribution yet supplies no baselines, metrics (e.g., success rate, steps-to-goal), error bars, or statistical controls, leaving the magnitude and reliability of the improvement impossible to evaluate from the provided text.
- [Method] Method description (Imaginator): the claim that single-step probabilistic output over observed+unobserved semantics supplies the Actor with a distribution 'sufficient for efficient search' and 'hedges against uncertainty' without multi-turn accumulation is central, but the manuscript provides no analysis of prediction error rates on unobserved regions, how multiple hypothesis sampling bounds compounding errors, or failure cases when the prior is inaccurate.
- [Experiments] Experiments: no comparison is shown to strong multi-turn CoT baselines or ablations that isolate the contribution of the Imaginator versus the Actor, which is required to substantiate the decoupling benefit and the dataset-size advantage.
minor comments (2)
- [Abstract] Abstract: 'in-the-wild environments' should be accompanied by concrete dataset statistics or scene diversity metrics to clarify the evaluation scope.
- [Method] Notation: the distinction between 'semantic layout' and 'spatial priors' is used interchangeably in places; a short clarifying sentence or diagram would improve readability.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below. We have revised the manuscript to strengthen the presentation of results and analysis where the comments identify gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'drastically improves search efficiency and success rates' is load-bearing for the contribution yet supplies no baselines, metrics (e.g., success rate, steps-to-goal), error bars, or statistical controls, leaving the magnitude and reliability of the improvement impossible to evaluate from the provided text.
Authors: We agree that the abstract should convey concrete quantitative support for the central claim. The full experimental section already reports success rates, steps-to-goal, baselines, error bars, and statistical controls. We have revised the abstract to explicitly reference these metrics (e.g., relative success-rate gains and efficiency reductions) while remaining within length limits, directing readers to the detailed tables and controls in the experiments. revision: yes
-
Referee: [Method] Method description (Imaginator): the claim that single-step probabilistic output over observed+unobserved semantics supplies the Actor with a distribution 'sufficient for efficient search' and 'hedges against uncertainty' without multi-turn accumulation is central, but the manuscript provides no analysis of prediction error rates on unobserved regions, how multiple hypothesis sampling bounds compounding errors, or failure cases when the prior is inaccurate.
Authors: This observation correctly identifies an opportunity to make the Imaginator's robustness more explicit. Although end-to-end task performance already demonstrates the practical value of the single-step prior, we have added a dedicated analysis subsection quantifying Imaginator error rates on unobserved regions, showing how multi-hypothesis sampling limits error propagation, and including representative failure cases with discussion of when the semantic prior is inaccurate. revision: yes
-
Referee: [Experiments] Experiments: no comparison is shown to strong multi-turn CoT baselines or ablations that isolate the contribution of the Imaginator versus the Actor, which is required to substantiate the decoupling benefit and the dataset-size advantage.
Authors: We accept that direct isolation of the decoupling benefit strengthens the claims. The original experiments compared against prior HVS methods, but we have now added (i) strong multi-turn CoT baselines adapted to the 360° setting and (ii) ablations that disable or replace the Imaginator while keeping the Actor fixed. These additions quantify the contribution of the single-step prior and the annotation-efficiency advantage that enabled the 1.96 M sample dataset. revision: yes
Circularity Check
No circularity in architectural proposal or claims
full rationale
The paper introduces a decoupled Imaginator-Actor framework for humanoid visual search, where the Imaginator performs single-step probabilistic semantic layout prediction over observed and unobserved regions, and multiple hypotheses are sampled to guide the Actor. No equations, derivations, or parameter-fitting steps are described that reduce outputs to inputs by construction. The architecture is presented as a novel design choice that eliminates the need for trajectory-level CoT annotations, enabling large-scale data generation as a downstream benefit rather than a fitted input. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The central claim of improved efficiency rests on experimental validation in in-the-wild environments, not on self-referential definitions. This is a self-contained architectural contribution with no detectable circular steps.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Imaginator
no independent evidence
-
Actor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearThe Imaginator functions as a probabilistic predictor of spatial priors; instead of maintaining a cumulative reasoning chain, it infers the semantic layout of both observed and unobserved regions in a single step. By sampling multiple hypotheses within this semantic space, we provide the Actor with a distribution of effective spatial information, offering robust guidance that hedges against uncertainty during active search.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearwe propose Imagining in 360◦, a framework designed to explicitly decouple probabilistic spatial imagination from rigorous CoT reasoning.
Reference graph
Works this paper leans on
-
[1]
Vision: A computational investigation into the human representation and processing of visual information , author=. 2010 , publisher=
work page 2010
-
[2]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training , author=. 2025 , booktitle=
work page 2025
-
[3]
arXiv preprint arXiv:2505.08243 , year=
Training Strategies for Efficient Embodied Reasoning , author=. arXiv preprint arXiv:2505.08243 , year=
-
[4]
Eye and head movements in peripheral vision: nature of compensatory eye movements , author=. Science , volume=. 1966 , publisher=
work page 1966
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V*: Guided visual search as a core mechanism in multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
The Thirteenth International Conference on Learning Representations , year=
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[8]
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL , author=. arXiv preprint arXiv:2505.15436 , year=
-
[9]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[10]
Are multimodal large language models ready for omnidirectional spatial reasoning?, 2025
Are Multimodal Large Language Models Ready for Omnidirectional Spatial Reasoning? , author=. arXiv preprint arXiv:2505.11907 , year=
-
[11]
Forty-first International Conference on Machine Learning , year=
Genie: Generative interactive environments , author=. Forty-first International Conference on Machine Learning , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations , author=. 2025 , eprint=
work page 2025
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
work page 2021
-
[15]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers , author=. 2025 , eprint=
work page 2025
- [16]
-
[17]
Xu and Jun-Mei Song and Mingchuan Zhang and Y
Zhihong Shao and Peiyi Wang and Qihao Zhu and R. Xu and Jun-Mei Song and Mingchuan Zhang and Y. K. Li and Yu Wu and Daya Guo , booktitle =. ArXiv , title =
-
[18]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [23]
-
[24]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
work page 2025
-
[25]
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , title =. NeurIPS , year =
-
[26]
Transactions on Machine Learning Research , year =
LLaVA-OneVision: Easy Visual Task Transfer , author=. Transactions on Machine Learning Research , year =
-
[27]
International Conference on Machine Learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[28]
International Conference on Machine Learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
- [29]
-
[30]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
work page 2025
- [31]
- [32]
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
360+x: A Panoptic Multi-modal Scene Understanding Dataset , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
- [34]
- [35]
-
[36]
Proceedings 2003 international conference on image processing (Cat
Top-down control of visual attention in object detection , author=. Proceedings 2003 international conference on image processing (Cat. No. 03CH37429) , volume=. 2003 , organization=
work page 2003
-
[37]
Advances in neural information processing systems , volume=
The role of top-down and bottom-up processes in guiding eye movements during visual search , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search , author=. arXiv preprint arXiv:2509.07969 , year=
-
[40]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[41]
Training language models to follow instructions with human feedback , author=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A fully open, vision-centric exploration of multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl , author=. arXiv preprint arXiv:2508.07976 , year=
-
[45]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning , author=. arXiv preprint arXiv:2505.24298 , year=
-
[46]
Reinforcing Visual State Reasoning for Multi-Turn VLM Agents , author=. 2025 , url=
work page 2025
- [47]
-
[48]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-Group Policy Optimization for LLM Agent Training , author=. arXiv preprint arXiv:2505.10978 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Royal Society Open Science , volume=
Eye and head movements are complementary in visual selection , author=. Royal Society Open Science , volume=. 2017 , publisher=
work page 2017
-
[51]
Eye and head movements in visual search in the extended field of view , author=. Scientific Reports , volume=. 2024 , publisher=
work page 2024
- [52]
-
[53]
Biological cybernetics , volume=
Interactions between eye and head control signals can account for movement kinematics , author=. Biological cybernetics , volume=. 2001 , publisher=
work page 2001
-
[54]
Experimental Brain Research , volume=
Human eye-head coordination in two dimensions under different sensorimotor conditions , author=. Experimental Brain Research , volume=. 1997 , publisher=
work page 1997
-
[55]
The coordination of eye and head movement during smooth pursuit , author=. Brain research , volume=. 1978 , publisher=
work page 1978
- [56]
-
[57]
CogCoM: A Visual Language Model with Chain-of-Manipulations Reasoning , author=. ICLR , year=
-
[58]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
arXiv preprint arXiv:2411.16044 , year=
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration , author=. arXiv preprint arXiv:2411.16044 , year=
-
[60]
arXiv preprint arXiv:2403.12966 , year=
Chain-of-spot: Interactive reasoning improves large vision-language models , author=. arXiv preprint arXiv:2403.12966 , year=
-
[61]
Cosmos-reason1: From physical common sense to embodied reasoning , author=. arXiv preprint arXiv:2503.15558 , year=
-
[62]
Gemini Robotics: Bringing AI into the Physical World
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Conference on Robot Learning , pages=
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models , author=. Conference on Robot Learning , pages=. 2025 , organization=
work page 2025
-
[64]
Conference on Robot Learning , pages=
Robotic Control via Embodied Chain-of-Thought Reasoning , author=. Conference on Robot Learning , pages=. 2025 , organization=
work page 2025
-
[65]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[66]
Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Emma: End-to-end multimodal model for autonomous driving , author=. arXiv preprint arXiv:2410.23262 , year=
-
[67]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
work page 2024
-
[69]
Proceedings of The 9th Conference on Robot Learning , pages =
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop , author =. Proceedings of The 9th Conference on Robot Learning , pages =. 2025 , editor =
work page 2025
-
[70]
arXiv preprint arXiv:2511.00153 , year=
EgoMI: Learning Active Vision and Whole-Body Manipulation from Egocentric Human Demonstrations , author=. arXiv preprint arXiv:2511.00153 , year=
-
[71]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Habitat: A platform for embodied ai research , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[72]
Conference on robot learning , pages=
CARLA: An open urban driving simulator , author=. Conference on robot learning , pages=. 2017 , organization=
work page 2017
-
[73]
Field and service robotics: Results of the 11th international conference , pages=
Airsim: High-fidelity visual and physical simulation for autonomous vehicles , author=. Field and service robotics: Results of the 11th international conference , pages=. 2017 , organization=
work page 2017
-
[74]
International Conference on Learning Representation , year=
MetaUrban: An Embodied AI Simulation Platform for Urban Micromobility , author=. International Conference on Learning Representation , year=
-
[75]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Gibson env: Real-world perception for embodied agents , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[76]
Conference on Robot Learning , pages=
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation , author=. Conference on Robot Learning , pages=. 2023 , organization=
work page 2023
-
[77]
2017 IEEE international conference on robotics and automation (ICRA) , pages=
Target-driven visual navigation in indoor scenes using deep reinforcement learning , author=. 2017 IEEE international conference on robotics and automation (ICRA) , pages=. 2017 , organization=
work page 2017
-
[78]
Advances in Neural Information Processing Systems , volume=
Object goal navigation using goal-oriented semantic exploration , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Robotics: Science and Systems , year=
GOAT: GO to Any Thing , author=. Robotics: Science and Systems , year=
-
[80]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Neural topological slam for visual navigation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.