Recognition: no theorem link
Data-Driven Inverse Reinforcement Learning of Linear Systems with Model Uncertainty: A Convex Optimization View
Pith reviewed 2026-05-12 02:48 UTC · model grok-4.3
The pith
A generalized LQR cost with state-input cross term enables convex data-driven inverse reinforcement learning for linear systems under model uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For uncertain local systems a standard LQR cost is generally insufficient to represent every stabilizing target gain. A generalized LQR cost with a state-input cross term supplies a semidefinite characterization of inverse optimality. This characterization produces a convex data-driven inverse-RL method that recovers an equivalent state-cost matrix together with a stabilizing controller from expert trajectories by substituting a regressed kernel matrix for the unknown system matrices. The formulation further extends to robust cost design over a population of perturbations through differentiable semidefinite programming and stochastic approximation.
What carries the argument
The generalized LQR cost with state-input cross term, which supplies a semidefinite characterization of inverse optimality and converts the inverse problem into a convex program solvable from data via a regressed kernel matrix.
If this is right
- The method recovers expert behavior accurately on a discrete-time power-system example.
- Robustness to gain-estimation error and model mismatch improves compared with standard approaches.
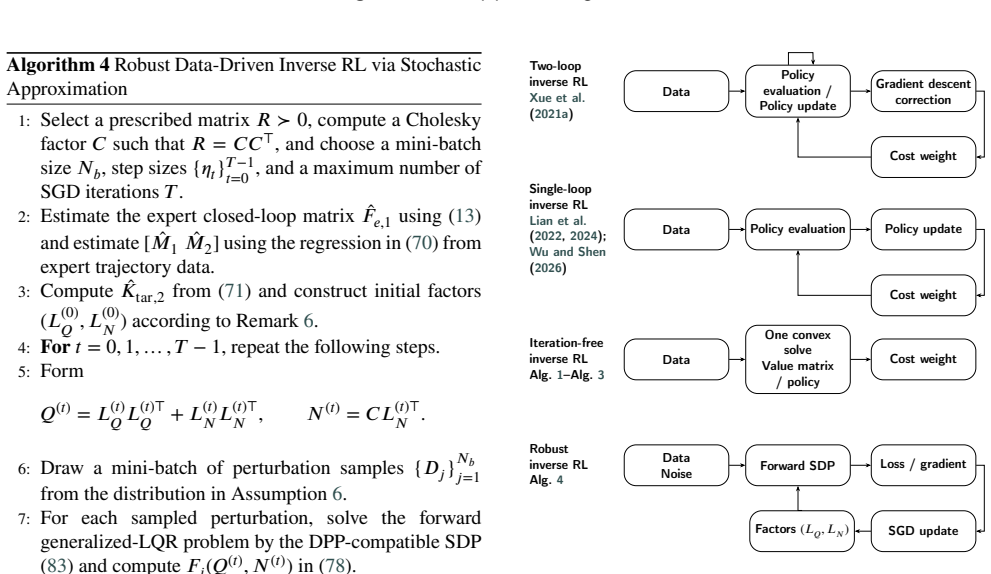
- The computational pipeline is simpler than classical iterative inverse-RL schemes that rely on repeated policy or value updates.
- Robust costs can be designed over populations of system perturbations using differentiable semidefinite programming and stochastic approximation.
Where Pith is reading between the lines
- The convex, one-shot structure may reduce sensitivity to initialization compared with iterative IRL methods that require an initial stabilizing controller.
- The model-free kernel reformulation opens the possibility of applying the same recovery procedure to streaming data without repeated system identification.
- Differentiable semidefinite programming for the robust extension could be embedded inside larger end-to-end training pipelines that optimize both cost parameters and policy performance jointly.
Load-bearing premise
Expert trajectories are generated by an optimal policy for some cost in the generalized LQR class, and local input-state data are sufficiently rich and noise-free to yield an accurate regressed kernel matrix without bias that invalidates the subsequent SDP.
What would settle it
A stabilizing target gain for which no generalized LQR cost matrix exists, or a set of expert trajectories and local data from which the convex program recovers a controller that fails to reproduce the expert behavior or stabilize the system under the modeled perturbations.
Figures




read the original abstract
Inverse reinforcement learning (IRL) for linear systems seeks a cost function whose optimal controller reproduces an expert policy from data. Existing data-driven methods for discrete-time linear systems are largely built on iterative policy/value updates, repeated matrix inversions, and, in some cases, an initial stabilizing controller, which can limit numerical robustness and practical applicability. This paper develops a convex-optimization framework for data-driven inverse reinforcement learning of discrete-time linear systems with model uncertainty. For nominal systems, we derive a semidefinite characterization of inverse optimality and a relaxed formulation that recovers an equivalent state-cost matrix together with a stabilizing controller from expert trajectories. We then obtain a model-free, off-policy reformulation by replacing the unknown system matrices with a regressed kernel matrix identified from local input--state data. For uncertain local systems, we show that a standard LQR cost is generally insufficient to represent every stabilizing target gain and therefore introduce a generalized LQR cost with a state--input cross term. Based on this model, we develop a convex data-driven inverse-RL method and extend it to robust cost design over a population of perturbations via differentiable semidefinite programming and stochastic approximation. Simulations on a discrete-time power-system example show accurate recovery of expert behavior, improved robustness to gain-estimation error and model mismatch, and a simpler computational pipeline than classical iterative inverse-RL schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a convex optimization framework for data-driven inverse reinforcement learning (IRL) of discrete-time linear systems with model uncertainty. It derives a semidefinite characterization of inverse optimality for nominal systems and a relaxed formulation recovering an equivalent state-cost matrix and stabilizing controller from expert trajectories. A model-free off-policy version is obtained by replacing unknown system matrices with a regressed kernel matrix identified from local input-state data. For uncertain systems, a generalized LQR cost with state-input cross term is introduced because standard LQR is insufficient to represent every stabilizing target gain; a convex data-driven IRL method is developed on this basis and extended to robust cost design over a population of perturbations via differentiable semidefinite programming and stochastic approximation. Simulations on a discrete-time power-system example demonstrate accurate recovery of expert behavior, improved robustness to gain-estimation error and model mismatch, and a simpler computational pipeline.
Significance. If the central derivations hold and the simulations are representative, the work offers a meaningful contribution to data-driven control by supplying a convex, non-iterative IRL pipeline that avoids repeated matrix inversions and the need for an initial stabilizing controller. The generalized LQR cost and the robust extension via differentiable SDP plus stochastic approximation directly address model uncertainty, which is a practical barrier in many applications. The convex formulation and off-policy data-driven reformulation are clear strengths that could improve numerical robustness and applicability of IRL methods.
major comments (3)
- §4 (model-free reformulation): the regressed kernel matrix obtained from local input-state trajectories is substituted directly into the SDP that certifies inverse optimality. No error bounds, noise model, or uncertainty quantification is supplied for this regression step; any finite-sample bias therefore propagates unchanged into the LMI constraints, so the recovered cost is guaranteed optimal only for the approximate kernel, not necessarily for the true uncertain plant. This assumption is load-bearing for the data-driven claim.
- §5 (robust extension): the population of perturbations is handled by stochastic approximation around the same regressed kernel. Because the kernel itself is not robustified, the stochastic step cannot correct upstream bias; the resulting robust cost may therefore fail to certify inverse optimality on the original uncertain system. This directly affects the central claim of robustness to model mismatch.
- Abstract and §3: the claim of 'accurate recovery of expert behavior' under mismatch is supported only by simulation outcomes; no explicit error bounds, data-exclusion rules, or proof sketches for the recovery guarantee are provided, leaving the central assertion of reliable inverse optimality unverifiable from the presented material.
minor comments (1)
- The notation for the generalized LQR cost (state-input cross term) would benefit from an explicit equation early in the development to clarify how it augments the standard quadratic form.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the data-driven and robust components of the manuscript. We address each major comment point by point below, providing clarifications and noting planned revisions to improve the presentation.
read point-by-point responses
-
Referee: §4 (model-free reformulation): the regressed kernel matrix obtained from local input-state trajectories is substituted directly into the SDP that certifies inverse optimality. No error bounds, noise model, or uncertainty quantification is supplied for this regression step; any finite-sample bias therefore propagates unchanged into the LMI constraints, so the recovered cost is guaranteed optimal only for the approximate kernel, not necessarily for the true uncertain plant. This assumption is load-bearing for the data-driven claim.
Authors: We agree that inverse optimality is certified exactly with respect to the regressed kernel, which approximates the true dynamics from finite data. This is inherent to data-driven control approaches that substitute an identified model into the optimization. The core contribution is the convex SDP that avoids iterative updates and initial stabilizers, with the kernel obtained via standard regression from local trajectories. Section 6 simulations confirm close matching to expert behavior when regression is accurate. We will add a remark in §4 noting the dependence on regression quality and citing kernel approximation bounds from the literature as a direction for future error quantification. revision: partial
-
Referee: §5 (robust extension): the population of perturbations is handled by stochastic approximation around the same regressed kernel. Because the kernel itself is not robustified, the stochastic step cannot correct upstream bias; the resulting robust cost may therefore fail to certify inverse optimality on the original uncertain system. This directly affects the central claim of robustness to model mismatch.
Authors: The stochastic approximation designs a cost robust to perturbations in the system matrices, using the regressed kernel as the nominal identified from data. Robustness is therefore relative to this data-driven model rather than correcting regression bias directly. Simulations demonstrate improved robustness to gain-estimation error and mismatch compared to non-robust methods. We will revise §5 to explicitly clarify that the robust design operates around the identified kernel and discuss implications for upstream approximation error. revision: yes
-
Referee: Abstract and §3: the claim of 'accurate recovery of expert behavior' under mismatch is supported only by simulation outcomes; no explicit error bounds, data-exclusion rules, or proof sketches for the recovery guarantee are provided, leaving the central assertion of reliable inverse optimality unverifiable from the presented material.
Authors: The statements in the abstract and §3 refer to the numerical results in Section 6, which show accurate recovery and improved robustness on the power-system example. The theoretical results in §3 provide an exact SDP characterization of inverse optimality for the nominal case and introduce the generalized LQR cost to represent any stabilizing gain; the data-driven reformulation in §4 is exact for the kernel. We do not claim or provide general finite-sample error bounds or probabilistic recovery guarantees under mismatch, as the focus is the convex framework and its empirical validation. We will update the abstract to read 'numerical experiments demonstrate accurate recovery' for precision. revision: partial
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper's central chain replaces unknown (A,B) with a regressed kernel matrix from local input-state trajectories, then solves an SDP for generalized-LQR cost parameters that render the expert policy optimal. The kernel regression uses separate local data, while the SDP constraints are populated from independent expert trajectories; neither step reduces the recovered cost matrix to a fitted parameter by construction, nor does any self-citation load-bear the inverse-optimality characterization. The robust extension via differentiable SDP and stochastic approximation inherits the same separation of data sources. The derivation is therefore externally falsifiable against held-out trajectories and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- regressed kernel matrix
axioms (2)
- domain assumption Expert policy is optimal for some cost in the generalized LQR class
- domain assumption Discrete-time linear dynamics
invented entities (1)
-
generalized LQR cost with state-input cross term
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
IEEE Transactions on Cybernetics , volume=
Inverse reinforcement learning in tracking control based on inverse optimal control , author=. IEEE Transactions on Cybernetics , volume=. 2021 , publisher=
work page 2021
-
[3]
2022 IEEE 61st Conference on Decision and Control (CDC) , pages=
Inverse reinforcement learning control for linear multiplayer games , author=. 2022 IEEE 61st Conference on Decision and Control (CDC) , pages=. 2022 , organization=
work page 2022
-
[4]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Inverse reinforcement Q-learning through expert imitation for discrete-time systems , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2021 , publisher=
work page 2021
-
[5]
Proceedings of 1995 American Control Conference-ACC'95 , volume=
Connections between duality in control theory and convex optimization , author=. Proceedings of 1995 American Control Conference-ACC'95 , volume=. 1995 , organization=
work page 1995
-
[6]
Model-free LQR design by Q-function learning , author=. Automatica , volume=. 2022 , publisher=
work page 2022
-
[7]
IEEE Transactions on Automatic Control , volume=
Primal-dual Q-learning framework for LQR design , author=. IEEE Transactions on Automatic Control , volume=. 2018 , publisher=
work page 2018
-
[8]
IEEE Transactions on Cybernetics , year=
Output-Feedback Control of Linear Continuous-Time Systems Using Discounted Inverse Reinforcement Learning , author=. IEEE Transactions on Cybernetics , year=
-
[9]
Data-driven linear quadratic regulation via semidefinite programming , author=. IFAC-PapersOnLine , volume=. 2020 , publisher=
work page 2020
-
[10]
Introduction to mathematical systems theory: linear systems, identification and control , author=. 2007 , publisher=
work page 2007
-
[11]
Linear matrix inequalities in system and control theory , author=. 1994 , publisher=
work page 1994
-
[12]
Advances in neural information processing systems , volume=
Differentiable convex optimization layers , author=. Advances in neural information processing systems , volume=
-
[13]
IEEE Transactions on Automatic Control , year=
Inverse Reinforcement Learning via a Modified Kleinman Iteration Approach , author=. IEEE Transactions on Automatic Control , year=
-
[14]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , publisher=
work page 1951
- [15]
-
[16]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Inverse value iteration and Q-learning: Algorithms, stability, and robustness , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2024 , publisher=
work page 2024
-
[17]
IEEE transactions on neural networks and learning systems , volume=
Asymptotically stable adaptive--optimal control algorithm with saturating actuators and relaxed persistence of excitation , author=. IEEE transactions on neural networks and learning systems , volume=. 2015 , publisher=
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.