Recognition: 2 theorem links
· Lean TheoremCIVeX: Causal Intervention Verification for Language Agents
Pith reviewed 2026-05-12 02:22 UTC · model grok-4.3
The pith
CIVeX verifies tool calls by checking whether they produce identifiable causal effects on a committed action-state graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Intervention identifiability is the missing primitive for reliable tool use. CIVeX maps proposed actions to structural causal queries over a committed action-state graph, checks identifiability, and returns one of four auditable verdicts—EXECUTE, REJECT, EXPERIMENT, or ABSTAIN—each backed by an assumption-scoped causal certificate containing graph commitments, an identification argument, a one-sided lower confidence bound, provenance, and risk limits.
What carries the argument
CIVeX, the verifier that maps proposed actions to structural causal queries over a committed action-state graph, checks for identifiability, and returns a verdict with an assumption-scoped causal certificate.
If this is right
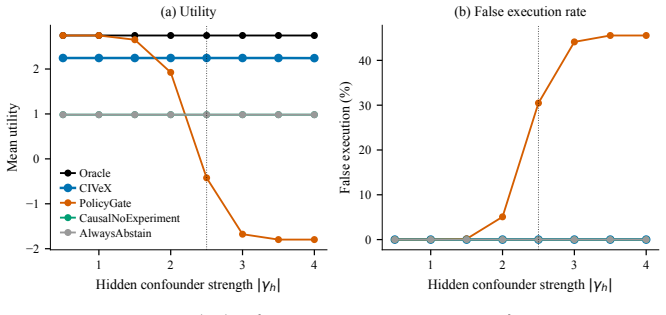
- Zero observed false executions on Causal-ToolBench across moderate and adversarial confounding.
- 84.9 percent accuracy and 81.1 percent of oracle utility under adversarial confounding, the only non-oracle method whose constrained utility exceeds the AlwaysAbstain floor.
- Matches oracle correct-execution within 0.1 percentage points on IHDP and ZOZO Open Bandit real production logs while cutting per-execute false-execution by at least 50 times over naive baselines.
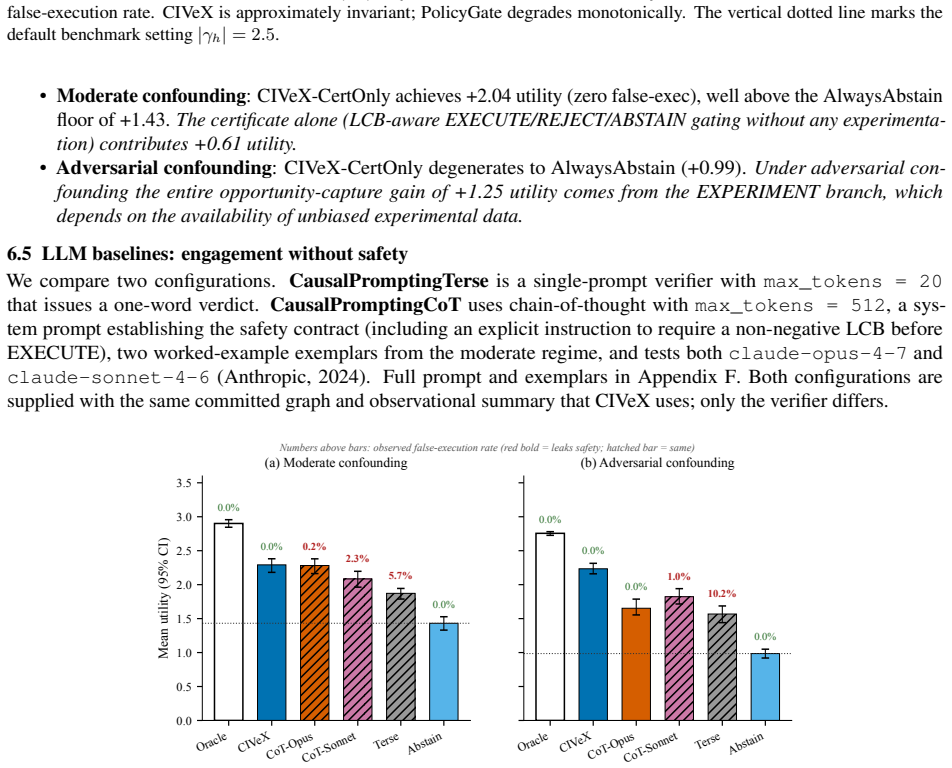
- Chain-of-thought LLM verifiers reduce false executions by an order of magnitude over terse baselines yet reach only 74 percent of CIVeX utility under adversarial confounding.
Where Pith is reading between the lines
- Agents equipped with CIVeX could explore tool combinations more freely in environments where observational data contains hidden confounding.
- Tool APIs might need to expose causal structure metadata to make such identifiability checks practical at scale.
- The same pre-execution certification pattern could apply to sequential planning in robotics or web agents with delayed or hidden effects.
Load-bearing premise
The committed action-state graph accurately represents the true causal structure and the identification argument plus one-sided lower confidence bound correctly certifies a non-zero causal effect.
What would settle it
An executed action that passes the identifiability check and certificate but produces no measurable change or a negative change in the target state variable.
Figures

read the original abstract
A valid tool call is not necessarily a valid intervention. Tool-using language agents are guarded by schema validators, policy filters, provenance checks, state predictors, and self-verification, yet such safeguards do not certify that a state-changing action has an identifiable causal effect. In confounded workflows, the action that looks optimal in observational logs can reduce utility when executed. We introduce CIVeX, a causal intervention verifier that maps proposed actions to structural causal queries over a committed action-state graph, checks identifiability, and returns one of four auditable verdicts: EXECUTE, REJECT, EXPERIMENT, or ABSTAIN. Execution requires an assumption-scoped causal certificate carrying graph commitments, an identification argument, a one-sided lower confidence bound (LCB), provenance, and risk limits. On Causal-ToolBench (1,890 instances, 7 seeds), CIVeX yields zero observed false executions across moderate and adversarial confounding. Under adversarial confounding it reaches 84.9% accuracy and 81.1% of oracle utility (+2.23 vs +2.76) and is the only non-oracle method whose constrained utility under a zero-false-execution constraint exceeds the AlwaysAbstain floor. On IHDP and ZOZO Open Bandit (real production logs with uniform-random ground truth), CIVeX matches Oracle correct-execution within 0.1pp and cuts per-execute false-execution by >=50x over naive baselines. A chain-of-thought LLM verifier (Claude Opus, Sonnet) cuts false-execution by an order of magnitude over a terse baseline, yet under adversarial confounding Opus's utility falls to 74% of CIVeX's. Intervention identifiability, not action validity, is the missing primitive for reliable tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CIVeX, a verifier that maps proposed tool calls by language agents to structural causal queries over a committed action-state graph, checks identifiability, and issues one of four verdicts (EXECUTE, REJECT, EXPERIMENT, ABSTAIN) backed by an auditable causal certificate containing graph commitments, an identification argument, a one-sided lower confidence bound, provenance, and risk limits. It reports zero observed false executions on Causal-ToolBench (1,890 instances) under moderate and adversarial confounding, 84.9% accuracy and 81.1% of oracle utility under adversarial conditions, and near-oracle performance on real production logs from IHDP and ZOZO Open Bandit while cutting false-execution rates by >=50x over naive baselines.
Significance. If the core assumptions hold, CIVeX supplies a missing primitive for safe tool use by shifting from action-validity checks to intervention-identifiability certificates, with strong empirical support in the form of zero false executions and utility close to oracle under controlled confounding. The work is notable for grounding agent decisions in causal identification theory rather than purely statistical or LLM-based verification.
major comments (2)
- [Abstract / causal certificate definition] The EXECUTE verdict and all reported performance numbers (zero false executions, 81.1% oracle utility) rest on the assumption that the committed action-state graph exactly encodes the true causal structure (Abstract and methods description of the causal certificate). The manuscript supplies no general procedure by which an agent can commit or infer such a graph from observational data in open tool-use regimes, no sensitivity analysis to edge or variable misspecification, and no propagation bound on how graph error affects invalid EXECUTE verdicts. Experiments instead use graphs given by construction or derived from uniform-random logs, which does not address the open-world setting the work targets.
- [Abstract / identification argument] The one-sided lower confidence bound (LCB) used to certify a non-zero causal effect is load-bearing for the EXECUTE decision, yet the manuscript provides no derivation details, error-bar methodology, or data-exclusion rules for its computation (Abstract reports the empirical outcomes but omits these). Without this, it is impossible to verify that the LCB correctly certifies identifiability under the reported confounding regimes.
minor comments (2)
- [methods] The four verdicts and their exact decision criteria should be formalized with pseudocode or a decision table to improve reproducibility.
- [experiments] Clarify whether the Causal-ToolBench graphs are provided as input or constructed by the method itself, and include the exact seed and data-partitioning protocol used for the 7 seeds.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, clarifying the intended scope of CIVeX while proposing targeted revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / causal certificate definition] The EXECUTE verdict and all reported performance numbers (zero false executions, 81.1% oracle utility) rest on the assumption that the committed action-state graph exactly encodes the true causal structure (Abstract and methods description of the causal certificate). The manuscript supplies no general procedure by which an agent can commit or infer such a graph from observational data in open tool-use regimes, no sensitivity analysis to edge or variable misspecification, and no propagation bound on how graph error affects invalid EXECUTE verdicts. Experiments instead use graphs given by construction or derived from uniform-random logs, which does not address the open-world setting the work targets.
Authors: We agree that EXECUTE verdicts are valid only under the assumption that the committed action-state graph matches the true causal structure. CIVeX is explicitly a verifier that takes a committed graph as input; the manuscript focuses on the mapping to structural queries, identifiability checks, and auditable certificates rather than on automated graph inference or discovery. In practice, the graph may be supplied by domain experts, system designers, or derived from prior observational analyses, but we do not claim a general open-world inference procedure. Experiments deliberately use known graphs (by construction or from uniform-random logs) to isolate verifier performance under controlled confounding. We acknowledge the absence of sensitivity analysis and error-propagation bounds as a limitation of the current draft and will add a dedicated subsection in the revised manuscript discussing graph misspecification risks, qualitative bounds on false EXECUTE rates, and directions for future robustness checks. revision: partial
-
Referee: [Abstract / identification argument] The one-sided lower confidence bound (LCB) used to certify a non-zero causal effect is load-bearing for the EXECUTE decision, yet the manuscript provides no derivation details, error-bar methodology, or data-exclusion rules for its computation (Abstract reports the empirical outcomes but omits these). Without this, it is impossible to verify that the LCB correctly certifies identifiability under the reported confounding regimes.
Authors: The one-sided LCB is derived directly from the identification formula obtained via do-calculus on the committed graph, estimated via nonparametric bootstrap (1,000 resamples) with a one-sided 95% lower bound on the causal effect. Observations with insufficient support (fewer than 10 samples in the relevant adjustment strata) are excluded prior to estimation to avoid unstable bounds. These methodological details appear in the Methods section under identification and statistical estimation. We will revise the abstract and add a concise summary paragraph in the main text to make the LCB derivation, bootstrap procedure, and exclusion rules explicit and self-contained. revision: yes
Circularity Check
No significant circularity; derivation applies external causal identification to committed graphs
full rationale
The paper defines CIVeX as mapping actions to structural causal queries on a pre-committed action-state graph, then applying standard identifiability checks and one-sided LCBs drawn from external causal theory. Performance is reported on benchmarks where the graph is either given by construction or derived from uniform-random logs, with no parameters fitted to the reported metrics and no self-referential definitions or predictions. The central claims rest on external causal-identification results and empirical evaluation rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A committed action-state graph accurately encodes the relevant causal structure between proposed tool calls and observable state changes.
- standard math Standard causal identification criteria (back-door, front-door, etc.) can be applied to the committed graph to determine whether the intervention effect is identifiable.
invented entities (1)
-
Causal intervention certificate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CIVeX maps a proposed action to a structural causal query of the form E[Y|do(T=t*)] and asks whether it is identifiable under the committed graph G... issues a certificate only if (i) the query is identifiable under G via pi, (ii) LCB_alpha >= tau_u
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2. Under (A1)-(A4), P(EXECUTE cap theta < 0) <= alpha
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1111/ectj.12097. Carlos Cinelli and Chad Hazlett. Making sense of sensitivity: Extending omitted variable bias.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1):39–67,
-
[2]
Vincent Dorie, Jennifer Hill, Uri Shalit, Marc Scott, and Dan Cervone
doi: 10.1111/rssb.12348. Vincent Dorie, Jennifer Hill, Uri Shalit, Marc Scott, and Dan Cervone. Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition.Statistical Science, 34(1):43–68,
-
[3]
doi: 10.1214/18-STS667. Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Monographs on Statistics and Applied Probability. Chapman & Hall, New York,
-
[4]
Javier García and Fernando Fernández
doi: 10.1136/bmj.311.7005.619. Javier García and Fernando Fernández. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16(1):1437–1480,
-
[5]
doi: 10.1001/jama.1983. 03330370053031. Miguel A. Hernán and James M. Robins.Causal Inference: What If. Chapman & Hall/CRC, Boca Raton,
-
[6]
doi: 10.1198/jcgs.2010.08162. Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, and Bernhard Schölkopf. CLadder: Assessing causal reasoning in language models. InAdvances in Neural Information Processing Systems 36 (NeurIPS),
- [7]
-
[8]
Causal reasoning and large language models: Opening a new frontier for causality
Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. Causal reasoning and large language models: Opening a new frontier for causality.arXiv preprint arXiv:2305.00050,
-
[9]
doi: 10.1145/3287560.3287596. Hongseok Namkoong, Ramtin Keramati, Steve Yadlowsky, and Emma Brunskill. Off-policy policy evaluation for sequential decisions under unobserved confounding. InAdvances in Neural Information Processing Systems 33 (NeurIPS),
-
[10]
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. InProceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAccT), pages 33–44,
work page 2020
-
[11]
doi: 10.1145/3351095.3372873. Paul R. Rosenbaum and Donald B. Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70(1):41–55,
-
[12]
doi: 10.1093/biomet/70.1.41. Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. Open bandit dataset and pipeline: Towards realistic and reproducible off-policy evaluation.arXiv preprint arXiv:2008.07146,
-
[13]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V
doi: 10.7326/M16-2607. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR),
-
[14]
arXiv:2308.13067. A Proofs of Section 4 Proof of Proposition 1.Let Ii be the indicator that on instance i the bias has the opposite sign to θi and |bi|>|θ i|. By assumption E[Ii]≥p . On those instances Πobs executes when θi <0 , yielding regret |θi|. Total expected regret over H instances is at leastP i E[Ii · |θi|]≥H·p·E[|θ i| |I i = 1] by linearity of e...
-
[15]
provides realistic covariates from the Infant Health and Development Program (a US RCT) paired with a simulated potential-outcome surface generated under known confounding bias (Dorie et al., 2019). It is asemi-syntheticbenchmark widely used in the causal-inference literature; we use it to check that CIVeX’s safety property survives outside the bespoke Ca...
work page 2019
-
[16]
provides logged ZOZOTOWN e-commerce recommender data under both a Bernoulli Thompson Sampling policy ( bts) and a uniform-random policy. We use the small release bundled with the obp package (10,000 rounds per policy, 80 items, 48 with sufficient random-arm coverage) and define an item assafeif its true click rate under the random arm exceeds the populati...
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.