Recognition: no theorem link
The Geometry of Forgetting: Temporal Knowledge Drift as an Independent Axis in LLM Representations
Pith reviewed 2026-05-12 01:50 UTC · model grok-4.3
The pith
Temporal knowledge drift is encoded as a direction in LLM residual streams that is geometrically orthogonal to correctness and uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
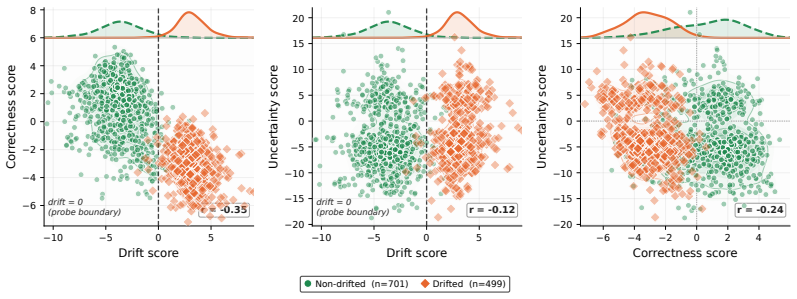
Temporal drift, defined as whether a stored fact has changed since training, is encoded as a direction in the residual stream geometrically orthogonal to both correctness and uncertainty. A linear probe trained on drift labels reaches AUROC 0.83-0.95 across six models, while methods using token entropy, semantic entropy, CCS, and SAPLMA stay near chance at 0.49-0.57. Five tests verify orthogonality through low weight cosines, low score correlations, bidirectional null-space projection, iterative null-space projection, and difference-of-means dissociation. The MLP retrieval circuit produces nearly identical dynamics for stale recall and confabulation, and cross-cutoff experiments show the pro
What carries the argument
The drift direction in the residual stream, isolated by linear probes on temporal labels and verified as orthogonal via cosine similarity, correlation, and null-space projection tests.
If this is right
- Any method that operates only on correctness or uncertainty signals is blind to temporal drift by construction.
- The MLP retrieval circuit produces identical internal dynamics for both outdated facts and confabulations, so output confidence cannot separate them.
- A probe trained on drift labels can distinguish models whose training predates a fact's change from those trained after it, even when given identical inputs.
- Five independent geometric tests, including null-space projections, all confirm that the drift direction shares almost no variance with correctness or uncertainty directions.
Where Pith is reading between the lines
- Targeting this specific direction during model updates could allow selective refresh of outdated knowledge without affecting other representations.
- The same geometric separation might apply to other forms of knowledge inconsistency, such as contradictions within a single training corpus.
- Internal monitoring of this axis could support systems that flag and request updates for stale information without full retraining.
Load-bearing premise
The observed geometric orthogonality between drift, correctness, and uncertainty reflects a general structural property of LLMs rather than an artifact of the six tested models or chosen facts.
What would settle it
Finding a strong correlation (r > 0.5) between a drift probe and an uncertainty or correctness measure on a new set of facts or an additional model would contradict the orthogonality claim.
Figures



read the original abstract
Large language models confidently produce outdated answers, and no existing method can detect them. We show this is not an engineering failure but a structural one: temporal drift, whether a stored fact has changed since training, is encoded as a direction in the residual stream geometrically orthogonal to both correctness and uncertainty. Any method operating on correctness or uncertainty signals is therefore blind to drift by construction. We verify this across six instruction-tuned models. A linear probe trained directly on drift labels achieves AUROC $0.83$--$0.95$; methods based on token entropy, semantic entropy, CCS, and SAPLMA all remain near chance ($0.49$--$0.57$). Five tests confirm the geometric orthogonality: weight cosines ($|\cos| \leq 0.14$), score correlations ($|r| \leq 0.20$), bidirectional null-space projection ($|\Delta| \leq 0.008$), iterative null-space projection with $k{=}10$, and difference-of-means dissociation. Mechanistically, the MLP retrieval circuit produces identical dynamics for stale recall and confabulation ($r > 0.81$, six models), explaining why output confidence cannot separate them. A cross-cutoff experiment holds inputs constant and varies only the model: the probe fires on the model whose training predates the fact's transition and stays silent otherwise ($P(A{>}B) = 0.975$--$0.998$, twelve model pairs), confirming it reads model-internal knowledge state rather than input properties. Our code and datasets will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temporal knowledge drift (whether a stored fact has changed since an LLM's training) is encoded as a direction in the residual stream that is geometrically orthogonal to directions for correctness and uncertainty. This structural property explains why existing detection methods fail, as shown by linear probes achieving AUROC 0.83-0.95 on drift labels while token entropy, semantic entropy, CCS, and SAPLMA remain near chance (0.49-0.57); five geometric tests (cosines, correlations, null-space projections, difference-of-means) confirm orthogonality; MLP retrieval circuits show identical dynamics for stale recall and confabulation; and cross-cutoff experiments (fixed inputs, varying model training dates) isolate internal state with high consistency (P(A>B)=0.975-0.998).
Significance. If the central claim holds after addressing methodological gaps, the work would be significant for LLM interpretability: it identifies an independent representational axis for temporal drift, provides a mechanistic explanation via circuit analysis, and demonstrates why correctness/uncertainty-based methods are blind to it by construction. Strengths include the convergent multi-test evidence, the cross-cutoff design that holds inputs fixed to isolate model-internal knowledge, and the planned public release of code and datasets, which supports reproducibility.
major comments (2)
- [Methods] Methods/Experimental Setup: The manuscript provides no details on dataset construction (fact selection criteria, transition date determination, label verification process), model specifications (exact sizes, training cutoffs for the six instruction-tuned models), or controls for confounds (e.g., input phrasing effects, fact popularity). These omissions are load-bearing because the orthogonality claim and probe performance depend on the independence and quality of the drift labels and the representativeness of the tested models.
- [Geometric Tests] Geometric Orthogonality Tests (Abstract and §5): The five tests report low values (e.g., |cos| ≤ 0.14, |r| ≤ 0.20, |Δ| ≤ 0.008), but the paper does not specify whether thresholds were pre-registered, provide p-values or confidence intervals for the dissociation, or test sensitivity to probe training details. This weakens the claim that orthogonality is a robust structural property rather than tied to the specific linear probe or chosen facts.
minor comments (2)
- [Abstract] Abstract: The range of AUROC values (0.83--0.95) and model count (six) are reported without naming the models or providing a table of per-model results, which would aid immediate assessment of consistency.
- [Abstract] Notation: The cross-cutoff probability P(A>B) is introduced without a brief definition or reference to the exact statistical test used across the twelve model pairs.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the opportunity to clarify and strengthen our work. Below, we provide point-by-point responses to the major comments, indicating the revisions we will implement.
read point-by-point responses
-
Referee: Methods/Experimental Setup: The manuscript provides no details on dataset construction (fact selection criteria, transition date determination, label verification process), model specifications (exact sizes, training cutoffs for the six instruction-tuned models), or controls for confounds (e.g., input phrasing effects, fact popularity). These omissions are load-bearing because the orthogonality claim and probe performance depend on the independence and quality of the drift labels and the representativeness of the tested models.
Authors: We concur that more comprehensive details in the Methods section are necessary for reproducibility and to substantiate the claims. In the revised manuscript, we will include: detailed fact selection criteria, emphasizing facts with clear, documented transition dates from sources like official records and edit histories; the methodology for determining transition dates through multi-source verification; and the label verification process, including manual review and agreement metrics on sampled facts. Model specifications will be expanded to list all six models with their exact parameter sizes and training data cutoffs. For confounds, we will describe our controls, including the use of varied input phrasings for each fact and stratification by estimated fact popularity. These details, along with the promised public release of code and datasets, will allow readers to fully assess the quality of the drift labels and the generalizability across models. We believe this will resolve the concerns regarding the load-bearing aspects of the experimental setup. revision: yes
-
Referee: Geometric Orthogonality Tests (Abstract and §5): The five tests report low values (e.g., |cos| ≤ 0.14, |r| ≤ 0.20, |Δ| ≤ 0.008), but the paper does not specify whether thresholds were pre-registered, provide p-values or confidence intervals for the dissociation, or test sensitivity to probe training details. This weakens the claim that orthogonality is a robust structural property rather than tied to the specific linear probe or chosen facts.
Authors: The geometric tests were designed to provide convergent evidence of orthogonality using multiple independent methods. The thresholds reflect standard practices in representation geometry where correlations below 0.2 indicate substantial independence. We did not pre-register specific thresholds, as the work involved iterative exploration of the representational structure. To address this, the revised paper will incorporate p-values derived from permutation tests for each metric, along with bootstrap-derived confidence intervals to quantify the precision of the dissociation. Additionally, we will report sensitivity analyses that vary probe training parameters, such as the number of training examples and regularization, as well as different random subsets of facts, to confirm that the orthogonality holds robustly. The cross-cutoff experiments, which isolate model-internal states without relying on probes, provide complementary evidence that is less sensitive to these choices. These enhancements will bolster the claim of a robust structural property. revision: partial
Circularity Check
No significant circularity; derivation is empirically self-contained
full rationale
The paper's claims rest on direct empirical measurements across six models: linear-probe AUROCs on drift labels (0.83-0.95), near-chance performance of entropy/CCS/SAPLMA baselines (0.49-0.57), five independent geometric tests (cosines ≤0.14, correlations ≤0.20, bidirectional/iterative null-space projections ≤0.008, difference-of-means), MLP circuit correlations (r>0.81), and the cross-cutoff design that holds inputs fixed while varying only model training dates (P(A>B)=0.975-0.998). None of these steps reduce by construction to fitted parameters, self-citations, or definitional renaming; orthogonality is measured rather than assumed, and the cross-cutoff supplies an external falsification check on internal state. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (1)
- standard math Residual stream activations form a vector space in which directions can be meaningfully orthogonal.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[3]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
work page 2023
-
[4]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. Leace: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems, 36:66044–66063, 2023
work page 2023
-
[6]
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827, 2022
-
[7]
Iván Vicente Moreno Cencerrado, Arnau Padrés Masdemont, Anton Gonzalvez Hawthorne, David Demitri Africa, and Lorenzo Pacchiardi. No answer needed: Predicting llm answer accuracy from question-only linear probes.arXiv preprint arXiv:2509.10625, 2025
-
[8]
A dataset for answering time-sensitive questions.arXiv preprint arXiv:2108.06314, 2021
Wenhu Chen, Xinyi Wang, and William Yang Wang. A dataset for answering time-sensitive questions.arXiv preprint arXiv:2108.06314, 2021
-
[9]
Dated data: Tracing knowledge cutoffs in large language models.arXiv preprint arXiv:2403.12958, 2024
Jeffrey Cheng, Marc Marone, Orion Weller, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme. Dated data: Tracing knowledge cutoffs in large language models.arXiv preprint arXiv:2403.12958, 2024
-
[10]
Seonglae Cho, Zekun Wu, Kleyton Da Costa, and Adriano Koshiyama. The confidence manifold: Geometric structure of correctness representations in language models.arXiv preprint arXiv:2602.08159, 2026
-
[11]
Minyeong Choe, Haehyun Cho, Changho Seo, and Hyunil Kim. Do all autoregressive trans- formers remember facts the same way? a cross-architecture analysis of recall mechanisms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28482–28501, 2025
work page 2025
-
[12]
Bhuwan Dhingra, Jeremy R Cole, Julian Martin Eisenschlos, Daniel Gillick, Jacob Eisenstein, and William W Cohen. Time-aware language models as temporal knowledge bases.Transactions of the Association for Computational Linguistics, 10:257–273, 2022
work page 2022
-
[13]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
work page 2021
-
[14]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
work page 2024
-
[15]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 30–45, 2022
work page 2022
-
[16]
An adversarial example for direct logit attribution
Stefan Heimersheim and Neel Nanda. An adversarial example for direct logit attribution. In Proceedings of the 7th BlackboxNLP Workshop, 2024
work page 2024
-
[17]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching.arXiv preprint arXiv:2404.15255, 2024. 10
-
[18]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[19]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
work page 2023
- [20]
-
[21]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Stream- ingqa: A benchmark for adaptation to new knowledge over time in question answering models
Adam Liska, Tomas Kocisky, Elena Gribovskaya, Tayfun Terzi, Eren Sezener, Devang Agrawal, Cyprien De Masson D’Autume, Tim Scholtes, Manzil Zaheer, Susannah Young, et al. Stream- ingqa: A benchmark for adaptation to new knowledge over time in question answering models. InInternational Conference on Machine Learning, pages 13604–13622. PMLR, 2022
work page 2022
-
[23]
Aleksandar Makelov, Georg Lange, and Neel Nanda. Is this the subspace you are looking for? an interpretability illusion for subspace activation patching. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[24]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 9802–9822, 2023
work page 2023
-
[25]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[27]
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022
-
[28]
Miranda Muqing Miao and Lyle Ungar. Closing the confidence-faithfulness gap in large language models.arXiv preprint arXiv:2603.25052, 2026
-
[29]
Memory-based model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. InInternational Conference on Machine Learning, pages 15817–15831. PMLR, 2022
work page 2022
-
[30]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Does time have its place? temporal heads: Where language models recall time-specific information
Yein Park, Chanwoong Yoon, Jungwoo Park, Minbyul Jeong, and Jaewoo Kang. Does time have its place? temporal heads: Where language models recall time-specific information. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16616–16643, 2025
work page 2025
-
[32]
Het Patel, Tiejin Chen, Hua Wei, Evangelos E Papalexakis, and Jia Chen. Are llm uncertainty and correctness encoded by the same features? a functional dissociation via sparse autoencoders. arXiv preprint arXiv:2604.19974, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Null it out: Guarding protected attributes by iterative nullspace projection
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. Null it out: Guarding protected attributes by iterative nullspace projection. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 7237–7256, 2020. 11
work page 2020
-
[34]
Extracting latent steering vectors from pretrained language models
Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models. InFindings of the Association for Computational Linguistics: ACL 2022, pages 566–581, 2022
work page 2022
-
[35]
Bert rediscovers the classical nlp pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscovers the classical nlp pipeline. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 4593–4601, 2019
work page 2019
-
[36]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Freshllms: Refreshing large language models with search engine augmentation
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, et al. Freshllms: Refreshing large language models with search engine augmentation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13697–13720, 2024
work page 2024
-
[38]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small.arXiv preprint arXiv:2211.00593, 2022. 12 Appendix A Dataset Details Table 12: Models with HuggingFace checkpoints. All loaded in float16 on a single A100. Model Family Params Cutof...
work page internal anchor Pith review arXiv 2022
-
[39]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.