Recognition: 2 theorem links
· Lean TheoremProactBench: Beyond What The User Asked For
Pith reviewed 2026-05-12 02:04 UTC · model grok-4.3
The pith
Recovery after task completion is difficult for LLMs and weakly tied to standard benchmarks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProactBench decomposes conversational proactivity into Emergent, Critical, and Recovery phases. It uses a Planner, User Agent, and Assistant Model with information asymmetries to produce 198 dialogues containing 624 trigger points across 24 communication styles. Evaluation of frontier and open-weight models shows Recovery is difficult and weakly predicted by existing benchmarks, establishing it as a distinct evaluation signal.
What carries the argument
The three-agent architecture with Planner, User Agent, and Assistant Model that maintains information asymmetries to generate unbiased trigger points for proactivity evaluation.
If this is right
- Recovery performance can function as an independent metric when comparing how models handle real conversations.
- Standard benchmarks leave out important aspects of helpfulness that involve anticipating unstated needs.
- The 624 trigger points across 24 styles allow testing model robustness to different user communication patterns.
- Improving recovery may require training methods that emphasize post-task forward-looking inference rather than explicit instructions alone.
Where Pith is reading between the lines
- Interfaces built around recovery checks could lower user frustration during extended chat sessions.
- Developers could apply the benchmark to spot gaps in training data that favor explicit over implicit user signals.
- The information-asymmetry method might extend to testing other subtle skills such as timely clarification requests.
Load-bearing premise
The three-agent setup with information asymmetries successfully prevents style confounding, rubric leakage, and information dumps without introducing new artifacts.
What would settle it
Observing a strong correlation between recovery scores and performance on the six standard benchmarks across additional models would indicate recovery does not provide a useful new signal.
Figures

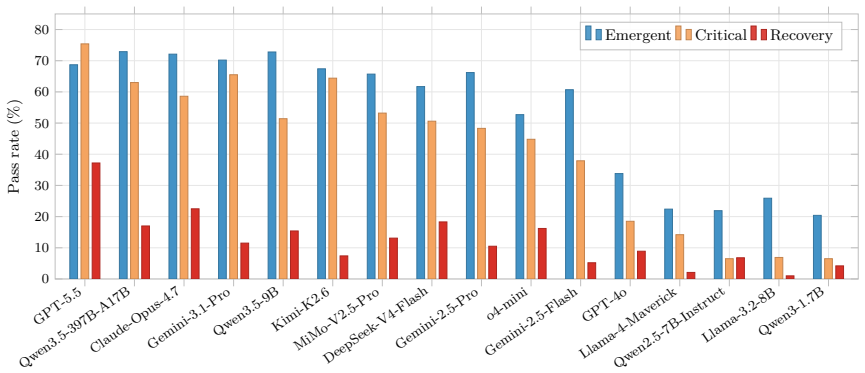


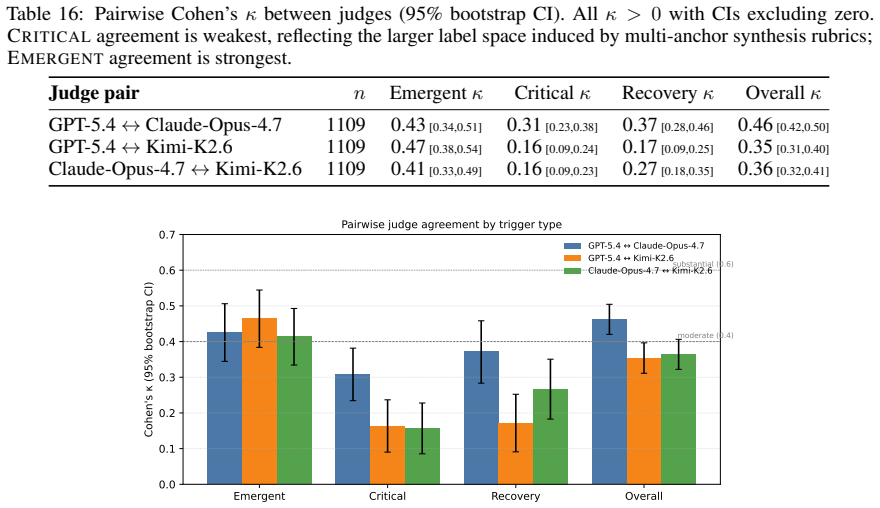
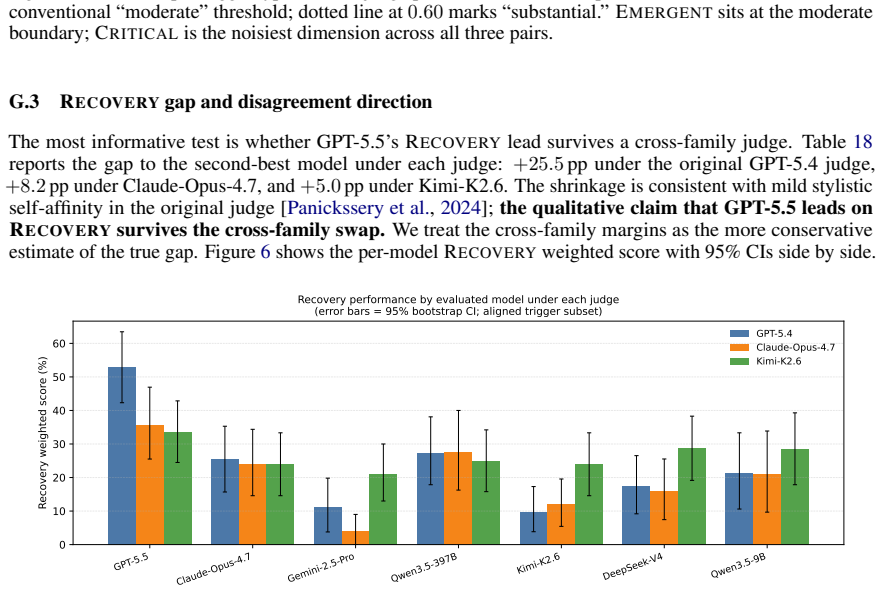


read the original abstract
Most LLM benchmarks score how well a model responds to explicit requests. They leave unmeasured a different conversational ability: noticing and acting on needs the user has implied but not said. We call this \emph{conversational proactivity}. ProactBench decomposes it into three phase-tied types: \textsc{Emergent}, inference from a single disclosed anchor; \textsc{Critical}, synthesis across multiple anchors; and \textsc{Recovery}, grounded forward-looking value after task completion. We operationalise the benchmark with three agents: a Planner, a User Agent, and an Assistant Model. Their information asymmetries defend against style-confounded scoring, rubric leakage, external-context contamination, and information dumps. The released corpus contains 198 curated dialogues with 624 trigger points across 24 communication styles drawn from a psychometric inventory and audited by an independent LLM judge. Across 16 frontier and open-weight models, \textsc{Recovery} is both difficult and weakly predicted by six standard benchmarks, making it a useful new evaluation signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProactBench to measure conversational proactivity in LLMs—the ability to notice and act on implied but unstated user needs. It decomposes proactivity into three phase-tied types (Emergent: inference from one anchor; Critical: synthesis across anchors; Recovery: grounded forward-looking value post-task) and operationalizes the benchmark via a three-agent protocol (Planner, User Agent, Assistant) whose information asymmetries are intended to block style confounding, rubric leakage, and information dumps. The released corpus comprises 198 dialogues with 624 trigger points spanning 24 psychometric communication styles; evaluations across 16 models indicate that Recovery is difficult and only weakly predicted by six standard benchmarks, positioning it as a distinct evaluation signal.
Significance. If the multi-agent construction successfully isolates genuine proactivity without introducing new artifacts, the reported weak correlation between Recovery scores and existing benchmarks would constitute a useful new signal for capabilities not captured by instruction-following evaluations. The release of the curated corpus and the psychometric grounding of styles are concrete strengths that could enable follow-on work.
major comments (2)
- [§3] §3 (three-agent operationalization): The central claim that Recovery scores reflect proactivity rather than protocol artifacts rests on the assertion that Planner/User-Agent/Assistant information asymmetries prevent style confounding, rubric leakage, and information dumps. The manuscript does not enumerate the precise knowledge partitions (e.g., whether the User Agent ever receives the Planner’s trigger list, the Assistant’s prior turns, or the full rubric), leaving open the possibility that residual style signals or handoff artifacts inflate Recovery difficulty and produce the observed weak correlations with the six external benchmarks.
- [Results] Results section (evaluation of 16 models): The claim that Recovery “is both difficult and weakly predicted” by six standard benchmarks is load-bearing for the paper’s contribution. Without reported correlation coefficients, confidence intervals, or explicit exclusion criteria for the six benchmarks, it is impossible to verify that the weak relationship is statistically distinguishable from noise or from the difficulty of the task itself.
minor comments (2)
- [Abstract] The abstract introduces “anchor” and “trigger points” without a concise definition on first use; a parenthetical gloss would improve readability.
- [§3] The auditing procedure by the independent LLM judge is mentioned but lacks details on prompt, agreement metric, or disagreement resolution; these should be added to the corpus-construction subsection.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (three-agent operationalization): The central claim that Recovery scores reflect proactivity rather than protocol artifacts rests on the assertion that Planner/User-Agent/Assistant information asymmetries prevent style confounding, rubric leakage, and information dumps. The manuscript does not enumerate the precise knowledge partitions (e.g., whether the User Agent ever receives the Planner’s trigger list, the Assistant’s prior turns, or the full rubric), leaving open the possibility that residual style signals or handoff artifacts inflate Recovery difficulty and produce the observed weak correlations with the six external benchmarks.
Authors: We acknowledge that the original description of the three-agent protocol, while outlining the intended information asymmetries, did not include an exhaustive enumeration of knowledge partitions. In the revised manuscript we have added a dedicated table in §3 that specifies the exact information available to each agent at every stage. The User Agent receives only the current simulated utterance and dialogue history and has no access to the Planner’s trigger list or the full rubric; the Assistant receives solely the conversation history without any prior knowledge of triggers, styles, or evaluation criteria. This explicit partitioning directly mitigates concerns about residual style signals or handoff artifacts and supports the claim that Recovery scores reflect proactivity rather than protocol effects. revision: yes
-
Referee: [Results] Results section (evaluation of 16 models): The claim that Recovery “is both difficult and weakly predicted” by six standard benchmarks is load-bearing for the paper’s contribution. Without reported correlation coefficients, confidence intervals, or explicit exclusion criteria for the six benchmarks, it is impossible to verify that the weak relationship is statistically distinguishable from noise or from the difficulty of the task itself.
Authors: We agree that quantitative statistical support is required to substantiate the claim. The revised Results section now includes a table reporting Pearson and Spearman correlations between Recovery scores and each of the six benchmarks, together with 95% confidence intervals and p-values. We have also added explicit selection criteria for the benchmarks (representative instruction-following, reasoning, and knowledge tasks) and note that the observed correlations remain low (|r| < 0.3) even after accounting for task difficulty. These additions allow readers to confirm that the weak relationship is statistically distinguishable from stronger correlations seen for the other proactivity phases. revision: yes
Circularity Check
No significant circularity in benchmark definition or empirical claims
full rationale
The paper constructs ProactBench via a three-agent protocol (Planner/User-Agent/Assistant) to generate 198 dialogues with 624 trigger points, then runs 16 models to measure Recovery difficulty and its weak correlation with six external benchmarks. No equations, fitted parameters, self-citations, or ansatzes appear in the derivation; the central result is an empirical observation from the released corpus and model evaluations rather than a quantity forced by construction or prior self-referential definitions. The three-agent asymmetries are presented as a methodological choice whose effectiveness is left to external verification, not asserted by internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The three-phase taxonomy (Emergent, Critical, Recovery) captures the main forms of conversational proactivity.
- domain assumption Information asymmetries between Planner, User Agent, and Assistant Model eliminate style confounding and leakage.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Their information asymmetries defend against style-confounded scoring, rubric leakage, external-context contamination, and information dumps.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RECOVERY is both difficult and weakly predicted by six standard benchmarks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[5]
Kaur, Kirandeep and Gupta, Vinayak and Gupta, Aditya and Shah, Chirag , journal=
-
[6]
Samarinas, Chris and Zamani, Hamed , journal=. Pro
-
[7]
A Survey on Proactive Dialogue Systems: Problems, Methods, and Prospects , author=. arXiv preprint arXiv:2305.02750 , url=
-
[8]
Deng, Yang and Liao, Lizi and Lei, Wenqiang and Yang, Grace Hui and Lam, Wai and Chua, Tat-Seng , journal=. Proactive Conversational. 2025 , doi=
work page 2025
-
[9]
Prompting and Evaluating Large Language Models for Proactive Dialogues: Clarification, Target-guided, and Non-collaboration , author=. Findings of EMNLP , year=
-
[10]
Towards Human-centered Proactive Conversational Agents , author=. Proceedings of SIGIR , year=
-
[11]
Smarter Response with Proactive Suggestion: A New Generative Neural Conversation Paradigm , author=. Proceedings of IJCAI , pages=. 2018 , url=
work page 2018
-
[12]
Zheng, Lianmin and Chiang, Wei-Lin and others , journal=. Judging
-
[13]
Lin, Bill Yuchen and Deng, Yuntian and others , journal=. WildBench: Benchmarking
-
[14]
Chatbot Arena: An Open Platform for Evaluating
Chiang, Wei-Lin and Zheng, Lianmin and others , journal=. Chatbot Arena: An Open Platform for Evaluating
-
[15]
Chang, Serina and Anderson, Ashton and Hofman, Jake M. , journal=. ChatBench: From Static Benchmarks to Human-
-
[17]
Gan, Yujian and Li, Changling and others , journal=. ClarQ-
-
[18]
arXiv preprint arXiv:2602.03429 , url=
DiscoverLLM: From Executing Intents to Discovering Them , author=. arXiv preprint arXiv:2602.03429 , url=
work page internal anchor Pith review arXiv
-
[20]
Zhou, Xuhui and Zhu, Hao and Mathur, Leena and others , journal=
-
[21]
Dong, Wenjie and Chen, Sirong and Yang, Yan , booktitle=. Pro. 2025 , url=
work page 2025
-
[22]
Measuring Massive Multitask Language Understanding , author=. Proceedings of ICLR , year=
-
[23]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and others , booktitle=. 2024 , url=
work page 2024
-
[24]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and others , booktitle=. 2024 , url=
work page 2024
-
[27]
2025 , howpublished=
work page 2025
-
[28]
Luo, Xiaotian and Jiang, Xun and Wu, Jiangcheng , journal=. MedDialBench: Benchmarking
-
[29]
and Bakker-Pieper, Angelique and Konings, Femke E
de Vries, Reinout E. and Bakker-Pieper, Angelique and Konings, Femke E. and Schouten, Barbara , journal=. The. 2013 , publisher=
work page 2013
-
[30]
Communication Research , volume=
The Content and Dimensionality of Communication Styles , author=. Communication Research , volume=. 2009 , publisher=
work page 2009
-
[31]
Diotaiuti, Pierluigi and Valente, Giuseppe and Mancone, Stefania and Grambone, Angela , journal=. Psychometric Properties and a Preliminary Validation Study of the Italian Brief Version of the Communication Styles Inventory (. 2020 , doi=
work page 2020
-
[32]
Tint, Joshua and Sagar, Som and others , journal=
-
[33]
arXiv preprint arXiv:2501.00383 , url=
Proactive Conversational Agents with Inner Thoughts , author=. arXiv preprint arXiv:2501.00383 , url=
-
[34]
Huang, Shuai and Zhao, Wenxuan and Gao, Jun , journal=
-
[35]
Interactive Agents: Simulating Counselor-Client Psychological Counseling via Role-Playing
Qiu, Huachuan and Lan, Zhenzhong , journal=. Interactive Agents: Simulating Counselor-Client Psychological Counseling via Role-Playing
-
[36]
Yang, An and others , journal=
- [37]
-
[38]
Near-Optimal Sensor Placements in
Guestrin, Carlos and Krause, Andreas and Singh, Ajit Paul , booktitle=. Near-Optimal Sensor Placements in. 2005 , url=
work page 2005
-
[39]
Neural Theory-of-Mind? On the Limits of Social Intelligence in Large
Sap, Maarten and LeBras, Ronan and Fried, Daniel and Choi, Yejin , booktitle=. Neural Theory-of-Mind? On the Limits of Social Intelligence in Large. 2022 , url=
work page 2022
-
[40]
Kim, Hyunwoo and Sclar, Melanie and Zhou, Xuhui and Bras, Ronan Le and Kim, Gunhee and Choi, Yejin and Sap, Maarten , booktitle=. 2023 , url=
work page 2023
-
[41]
Proceedings of EMNLP-IJCNLP , year=
Revisiting the Evaluation of Theory of Mind through Question Answering , author=. Proceedings of EMNLP-IJCNLP , year=
-
[42]
Nature Human Behaviour , year=
Testing theory of mind in large language models and humans , author=. Nature Human Behaviour , year=
-
[43]
Large language models fail on trivial alterations to theory-of-mind tasks, 2023
Large Language Models Fail on Trivial Alterations to Theory-of-Mind Tasks , author=. arXiv preprint arXiv:2302.08399 , url=
-
[44]
Towards Understanding Sycophancy in Language Models , author=. Proceedings of ICLR , year=
-
[45]
Discovering Language Model Behaviors with Model-Written Evaluations , author=. Findings of ACL , year=
-
[46]
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and others , journal=. Constitutional
-
[48]
arXiv preprint arXiv:2212.10711 , url=
Task Ambiguity in Humans and Language Models , author=. arXiv preprint arXiv:2212.10711 , url=
-
[51]
Asking Clarifying Questions in Open-Domain Information-Seeking Conversations , author=. Proceedings of SIGIR , year=
-
[52]
Shi, Taiwei and Wang, Zhuoer and Yang, Longqi and Lin, Ying-Chun and He, Zexue and Wan, Mengting and Zhou, Pei and Jauhar, Sujay and Chen, Sihao and Xia, Shan and Zhang, Hongfei and Zhao, Jieyu and Xu, Xiaofeng and Song, Xia and Neville, Jennifer , booktitle=. 2024 , eprint=
work page 2024
-
[53]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , url=
work page 2024
-
[54]
Needle in a Haystack -- Pressure Testing
Kamradt, Greg , year=. Needle in a Haystack -- Pressure Testing
-
[55]
An, Chenxin and Gong, Shansan and Zhong, Ming and Zhao, Xingjian and Li, Mukai and Zhang, Jun and Kong, Lingpeng and Qiu, Xipeng , booktitle=. 2024 , url=
work page 2024
-
[56]
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and others , journal=
-
[57]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and others , booktitle=. 2024 , url=
work page 2024
-
[58]
Wang, Xingyao and Wang, Zihan and Liu, Jiateng and others , booktitle=. 2024 , url=
work page 2024
-
[59]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , url=
work page internal anchor Pith review Pith/arXiv arXiv
- [60]
-
[61]
Contributing to discourse , author=. Cognitive Science , volume=. 1989 , url=
work page 1989
- [62]
-
[63]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume=
Conceptual pacts and lexical choice in conversation , author=. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume=. 1996 , url=
work page 1996
-
[64]
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed , booktitle=. 2024 , url=
work page 2024
-
[65]
Foundations and Trends in Information Retrieval , volume=
Conversational Information Seeking , author=. Foundations and Trends in Information Retrieval , volume=. 2023 , url=
work page 2023
-
[66]
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , booktitle=. 2024 , url=
work page 2024
-
[68]
Large Language Models are not Fair Evaluators , author=. Proceedings of ACL , year=
-
[69]
NeurIPS Datasets and Benchmarks , year=
Benchmarking Foundation Models with Language-Model-as-an-Examiner , author=. NeurIPS Datasets and Benchmarks , year=
-
[70]
Quantifying the Persona Effect in
Hu, Tiancheng and Collier, Nigel , booktitle=. Quantifying the Persona Effect in. 2024 , url=
work page 2024
-
[71]
Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting , author=. Proceedings of EACL , year=
-
[72]
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models , author=. arXiv preprint arXiv:2504.07070 , url=
-
[73]
Nemotron-Personas: A Collection of Synthetic Persona Datasets Aligned to Real-World Distributions , author=. 2025 , publisher=
work page 2025
-
[74]
Transactions on Machine Learning Research , year=
Emergent abilities of large language models , author=. Transactions on Machine Learning Research , year=
-
[75]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Are Emergent Abilities of Large Language Models a Mirage? , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[76]
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , booktitle=. tiny. 2024 , url=
work page 2024
- [77]
- [78]
- [79]
-
[80]
2026 , howpublished=
work page 2026
- [81]
-
[82]
2024 , howpublished=
work page 2024
-
[84]
Educational and Psychological Measurement , volume=
A Coefficient of Agreement for Nominal Scales , author=. Educational and Psychological Measurement , volume=. 1960 , doi=
work page 1960
-
[85]
Psychological Bulletin , volume=
Weighted Kappa: Nominal Scale Agreement Provision for Scaled Disagreement or Partial Credit , author=. Psychological Bulletin , volume=. 1968 , doi=
work page 1968
-
[86]
The American Journal of Psychology , volume=
The Proof and Measurement of Association Between Two Things , author=. The American Journal of Psychology , volume=. 1904 , doi=
work page 1904
-
[87]
The Annals of Statistics , volume=
Bootstrap Methods: Another Look at the Jackknife , author=. The Annals of Statistics , volume=. 1979 , doi=
work page 1979
-
[88]
Communications of the ACM , volume=
Datasheets for Datasets , author=. Communications of the ACM , volume=. 2021 , doi=
work page 2021
-
[89]
Croissant: A Metadata Format for
Akhtar, Mubashara and Benjelloun, Omar and Conforti, Costanza and Gijsbers, Pieter and Giner-Miguelez, Joan and Jain, Nitisha and Kuchnik, Michael and Lhoest, Quentin and Marcenac, Pierre and Maskey, Manil and Mattson, Peter and Oala, Luis and Ruyssen, Pierre and Shinde, Rajat and Simperl, Elena and Thomas, Goeffry and Tykhonov, Slava and Vanschoren, Joaq...
-
[90]
Human Communication Research , volume=
Reliability in Content Analysis: Some Common Misconceptions and Recommendations , author=. Human Communication Research , volume=. 2004 , doi=
work page 2004
-
[91]
Scandinavian Journal of Statistics , volume=
A Simple Sequentially Rejective Multiple Test Procedure , author=. Scandinavian Journal of Statistics , volume=. 1979 , publisher=
work page 1979
-
[92]
Journal of the Royal Statistical Society
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , author=. Journal of the Royal Statistical Society. Series B (Methodological) , volume=. 1995 , publisher=
work page 1995
-
[93]
Croissant: A metadata format for ML -ready datasets
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Pieter Gijsbers, Joan Giner-Miguelez, Nitisha Jain, Michael Kuchnik, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Pierre Ruyssen, Rajat Shinde, Elena Simperl, Goeffry Thomas, Slava Tykhonov, Joaquin Vanschoren, Susheel Varma, Jos van der Velde, Steffen Vogler, Carole-Jean Wu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.