Recognition: 2 theorem links
· Lean TheoremIntrinsic Muon: Spectral Optimization on Riemannian Matrix Manifolds
Pith reviewed 2026-05-12 05:03 UTC · model grok-4.3
The pith
Lifting unitarily invariant norms to tangent spaces via the Riemannian metric yields closed-form Muon updates on fixed-rank, SPD, Stiefel, and Grassmann manifolds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Every Riemannian metric canonically lifts a unitarily invariant Euclidean norm to an intrinsic norm on each tangent space, and the resulting intrinsic-norm-constrained linear maximization oracle is symmetry preserving; building on this single fact produces a unified intrinsic Muon (iMuon) algorithm that returns closed-form updates on the fixed-rank, SPD, Stiefel, and Grassmann manifolds for any unitarily invariant norm and supplies both deterministic and stochastic convergence guarantees whose rate constants depend only on the manifold dimension.
What carries the argument
The intrinsic norm on the tangent space obtained by lifting a unitarily invariant Euclidean norm through the Riemannian metric; this lift makes the constrained linear maximization oracle symmetry-preserving and therefore solvable in closed form.
If this is right
- Deterministic and stochastic versions of iMuon converge with rates whose constants depend only on manifold dimension, independent of factor conditioning on the fixed-rank case.
- No runtime factor-rescaling step is required for fixed-rank optimization.
- The same closed-form machinery applies unchanged to the spectral, Frobenius, and nuclear norms on four different manifolds.
- The framework directly supports LoRA fine-tuning of large language models, image classification, and subspace learning tasks.
Where Pith is reading between the lines
- The dimension-only rate dependence suggests that iMuon could remain practical even when manifold dimension grows, provided the closed-form step itself scales acceptably.
- The same lifting construction might be reusable on other matrix manifolds whose tangent spaces admit natural unitarily invariant structures.
- Because the method removes an explicit rescaling heuristic, implementations on fixed-rank problems become simpler and potentially more stable across different conditioning regimes.
Load-bearing premise
That lifting any unitarily invariant Euclidean norm through the Riemannian metric produces a tangent-space norm whose linear maximization oracle automatically respects the manifold's quotient symmetries.
What would settle it
An explicit computation on the fixed-rank manifold showing that the lifted intrinsic-norm LMO for the spectral norm either fails to admit a closed-form solution or produces a matrix that violates the quotient symmetry of the manifold.
Figures



read the original abstract
Muon and related norm-constrained matrix optimizers have become central to large-scale learning problems. They are formulated as a linear maximization oracle (LMO) over an ambient matrix-norm ball in unconstrained Euclidean space. However, these do not generalize cleanly to manifold-valued parameters such as low-rank factorizations, orthogonality constraints, or symmetric positive definite (SPD) matrices. Naively restricting the Muon LMO to the tangent space (i) breaks quotient symmetries and (ii) couples the tangent-space constraint with an ambient norm bound, thereby obstructing closed-form solutions on various manifolds of interest. We resolve both issues with a single observation: every Riemannian metric canonically lifts a unitarily invariant Euclidean norm to an intrinsic norm on each tangent space, and the resulting intrinsic norm constrained LMO is symmetry preserving. Building on this, we introduce intrinsic Muon (iMuon), a unified framework that yields closed-form updates on the fixed-rank, SPD, Stiefel, and Grassmann manifolds for any unitarily invariant norm, including the spectral, Frobenius, and nuclear norms. We establish convergence guarantees for both deterministic and stochastic iMuon with rate constants that depend only on the manifold dimension. Notably, on the fixed-rank manifold this constant depends only on the rank, making the rate independent of factor conditioning and removing the runtime factor-rescaling required by prior work. Experiments on LoRA finetuning of LLMs, image classification, and subspace learning illustrate the efficacy of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces intrinsic Muon (iMuon), a unified framework extending Muon-style norm-constrained optimization to Riemannian matrix manifolds (fixed-rank, SPD, Stiefel, Grassmann). It defines an intrinsic norm on each tangent space by canonically lifting a unitarily invariant Euclidean norm via the Riemannian metric, yielding symmetry-preserving closed-form LMOs and updates for spectral, Frobenius, and nuclear norms. Convergence guarantees are established for deterministic and stochastic variants, with rates depending only on manifold dimension (or rank alone on the fixed-rank manifold). Experiments on LoRA finetuning of LLMs, image classification, and subspace learning support the approach.
Significance. If the explicit constructions and proofs hold, this is a significant contribution to constrained optimization in machine learning. The framework unifies Muon across multiple manifolds with closed-form updates that avoid coupling issues and factor rescaling, while delivering dimension-dependent convergence rates via standard Riemannian descent lemmas. The parameter-free character of the rates (depending solely on dimension or rank) and the symmetry preservation on quotient manifolds are notable strengths, with direct applicability to large-scale tasks like LLM adaptation.
minor comments (3)
- [Abstract] In the abstract and introduction, the statement that rates 'depend only on the manifold dimension' could be accompanied by a brief parenthetical note on the precise constants or lemmas used, to immediately highlight the independence from conditioning.
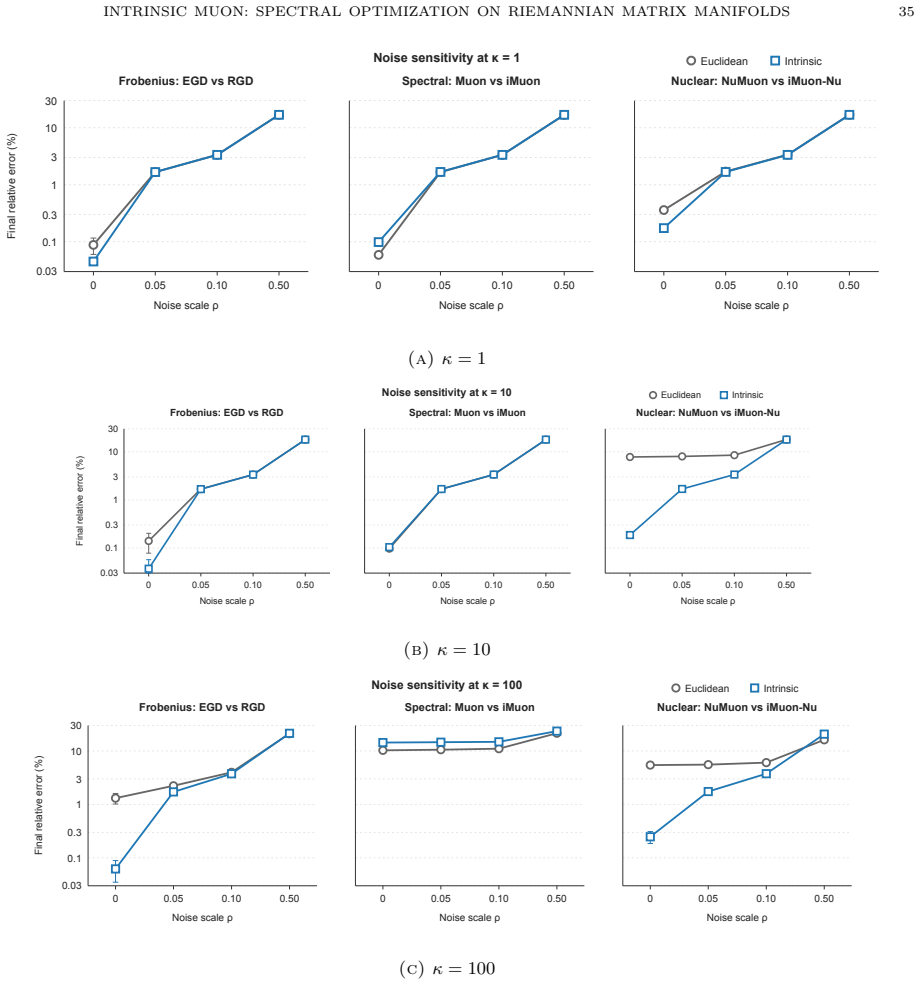
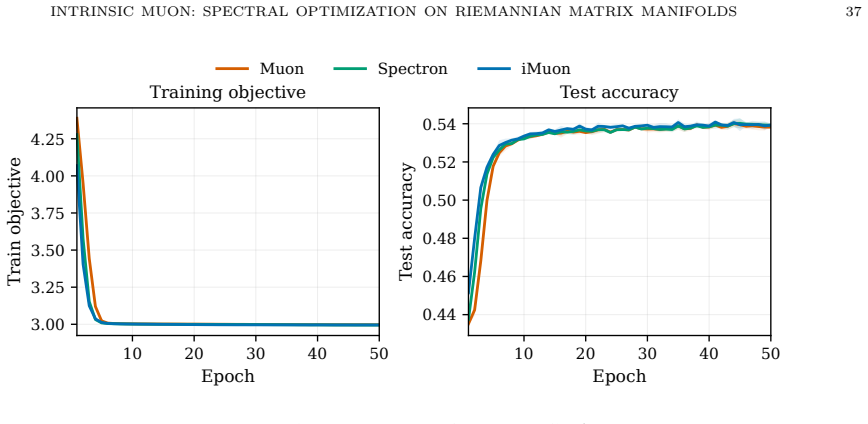
- [Experiments] Section 5 (experiments): the LoRA finetuning plots would benefit from reporting standard deviations across multiple random seeds, as single-run curves make it harder to assess robustness of the observed gains over baselines.
- [Preliminaries] Notation for the intrinsic norm (e.g., how the horizontal projection is denoted on Grassmann and fixed-rank manifolds) is introduced clearly but could be collected in a single preliminary table for quick reference.
Simulated Author's Rebuttal
We thank the referee for their detailed summary of our manuscript and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The derivation chain relies on standard Riemannian geometry: the intrinsic norm is obtained by restricting the ambient unitarily invariant norm to the tangent space via the Riemannian metric, which is a direct and non-circular construction. The LMO is then solved using the same singular-vector or eigenvalue routines as Euclidean Muon, with symmetry preservation following immediately from unitary invariance plus horizontal projection on quotient manifolds. Closed-form updates for spectral/Frobenius/nuclear norms on fixed-rank, SPD, Stiefel, and Grassmann manifolds are explicitly derived, and convergence rates are bounded using standard Riemannian descent lemmas with constants depending only on manifold dimension (or rank). No step reduces to a self-definitional loop, a fitted parameter renamed as prediction, or a load-bearing self-citation chain; all central claims are independent of the paper's own inputs and rest on external mathematical facts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Riemannian metrics canonically lift unitarily invariant Euclidean norms to intrinsic norms on tangent spaces that preserve quotient symmetries
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearevery Riemannian metric canonically lifts a unitarily invariant Euclidean norm to an intrinsic norm on each tangent space... ξ^* = arg max ... φ(G^{1/2}_x ξ) ≤ τ ... gx(ξ, grad f)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearZ_x is SV invariant... Z^* = U diag(z^*) V^⊤ ... z^* solves max φ(z)≤τ ⟨z,σ⟩
Reference graph
Works this paper leans on
-
[1]
Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization Algorithms on Matrix Manifolds
P.-A. Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization Algorithms on Matrix Manifolds. Princeton University Press, 2008
work page 2008
-
[2]
Natural gradient works efficiently in learning.Neural Computation, 10(2):251–276, 1998
Shun-Ichi Amari. Natural gradient works efficiently in learning.Neural Computation, 10(2):251–276, 1998
work page 1998
-
[3]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Opti- mal matrix sign methods and their application to the Muon algorithm. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=yRtgZ1K8hO. Outstanding Paper Award; arXiv:2505.16932
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Vincent Arsigny, Pierre Fillard, Xavier Pennec, and Nicholas Ayache. Geometric means in a novel vector space structure on symmetric positive-definite matrices.SIAM Journal on Matrix Analysis and Applications, 29(1):328–347, 2007
work page 2007
-
[5]
Online identification and tracking of subspaces from highly incomplete information
Laura Balzano, Robert Nowak, and Benjamin Recht. Online identification and tracking of subspaces from highly incomplete information. In48th Annual Allerton Conference on Communication, Control, and Computing, pages 704–711, 2010
work page 2010
-
[6]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
-
[7]
Modular duality in deep learning.arXiv preprint arXiv:2410.21265, 2024
Jeremy Bernstein and Laker Newhouse. Modular duality in deep learning. InInternational Conference on Machine Learning (ICML), pages 3920–3930, 2025. arXiv:2410.21265
-
[8]
Princeton Series in Applied Mathematics
Rajendra Bhatia.Positive Definite Matrices. Princeton Series in Applied Mathematics. Princeton University Press, 2007
work page 2007
-
[9]
Rajendra Bhatia, Tanvi Jain, and Yongdo Lim. On the Bures–Wasserstein distance between positive definite matrices.Expositiones Mathematicae, 37(2):165–191, 2019. 10 Y. LI, B. L. PANDEY, R. SAH, A. HAN, C. MOSTAJERAN, P. JA W ANPURIA, AND B. MISHRA
work page 2019
-
[10]
Vladimir Bogachev, Vladimir Aletov, Alexander Molozhavenko, Denis Bobkov, Vera Soboleva, Aibek Alanov, and Maxim Rakhuba. LoRA meets Riemannion: Muon optimizer for parametrization- independent low-rank adapters. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=WtbXgc9GVA. arXiv:2507.12142
-
[11]
Cambridge University Press, 2023
Nicolas Boumal.An Introduction to Optimization on Smooth Manifolds. Cambridge University Press, 2023
work page 2023
-
[12]
Exact matrix completion via convex optimization.Communi- cations of the ACM, 55(6):111–119, 2012
Emmanuel Candes and Benjamin Recht. Exact matrix completion via convex optimization.Communi- cations of the ACM, 55(6):111–119, 2012
work page 2012
-
[13]
Preconditioned spec- tral descent for deep learning
David Carlson, Edo Collins, Ya-Ping Hsieh, Lawrence Carin, and Volkan Cevher. Preconditioned spec- tral descent for deep learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 28. Curran Associates, Inc., 2015. URLhttps://proceedings.neurips.cc/paper_files/ paper/2015/file/f50a6c02a3fc5a3a5d4d9391f05f3efc-Paper.pdf
work page 2015
-
[14]
Muon optimizes under spectral norm constraints.Transac- tions on Machine Learning Research, 2026
Lizhang Chen, Jonathan Li, and qiang liu. Muon optimizes under spectral norm constraints.Transac- tions on Machine Learning Research, 2026. ISSN 2835-8856. URLhttps://openreview.net/forum? id=Blz4hjxLwU
work page 2026
- [15]
-
[16]
Alan Edelman, Tomás A. Arias, and Steven T. Smith. The geometry of algorithms with orthogonality constraints.SIAM Journal on Matrix Analysis and Applications, 20(2):303–353, 1998
work page 1998
-
[17]
Mano: Restriking manifold optimization for llm training.arXiv preprint arXiv:2601.23000, 2026
Yufei Gu and Zeke Xie. Mano: Restriking manifold optimization for LLM training.arXiv preprint arXiv:2601.23000, 2026
-
[18]
Grassmann discriminant analysis: a unifying view on subspace-based learning
Jihun Hamm and Daniel D Lee. Grassmann discriminant analysis: a unifying view on subspace-based learning. InProceedings of the 25th international conference on Machine learning, pages 376–383, 2008
work page 2008
-
[19]
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context.Acm transac- tions on interactive intelligent systems (tiis), 5(4):1–19, 2015
work page 2015
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[21]
Higham.Functions of Matrices: Theory and Computation
Nicholas J. Higham.Functions of Matrices: Theory and Computation. SIAM, 2008
work page 2008
-
[22]
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2nd edition, 2012
work page 2012
-
[23]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[24]
A Riemannian network for SPD matrix learning
Zhiwu Huang and Luc Van Gool. A Riemannian network for SPD matrix learning. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
work page 2017
-
[25]
Projection metric learning on Grassmann manifold with application to video based face recognition
Zhiwu Huang, Ruiping Wang, Shiguang Shan, and Xilin Chen. Projection metric learning on Grassmann manifold with application to video based face recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 140–149, 2015
work page 2015
-
[26]
Stabilizing native low-rank LLM pretraining
Paul Janson, Edouard Oyallon, and Eugene Belilovsky. Stabilizing native low-rank LLM pretraining. arXiv preprint arXiv:2602.12429, 2026
-
[27]
Muon: An optimizer for hidden layers in neural networks.https://kellerjordan
Keller Jordan. Muon: An optimizer for hidden layers in neural networks.https://kellerjordan. github.io/posts/muon/, 2024
work page 2024
-
[28]
Michel Journée, Francis Bach, P.-A. Absil, and Rodolphe Sepulchre. Low-rank optimization on the cone of positive semidefinite matrices.SIAM Journal on Optimization, 20(5):2327–2351, 2010
work page 2010
-
[29]
Changmin Kang, Jihun Yun, Baekrok Shin, Yeseul Cho, and Chulhee Yun. Uniform spectral growth and convergence of Muon in LoRA-style matrix factorization.arXiv preprint arXiv:2602.06385, 2026
-
[30]
Matrix completion from a few entries
Raghunandan H Keshavan, Andrea Montanari, and Sewoong Oh. Matrix completion from a few entries. IEEE transactions on information theory, 56(6):2980–2998, 2010
work page 2010
-
[31]
Convergence of Muon with Newton-Schulz.arXiv preprint arXiv:2601.19156, 2026
Gyu Yeol Kim and Min-hwan Oh. Convergence of Muon with Newton–Schulz. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id= lJSfxtLpLm. arXiv:2601.19156
-
[32]
Matrix factorization techniques for recommender systems.Computer, 42(8):30–37, 2009
Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems.Computer, 42(8):30–37, 2009
work page 2009
-
[33]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. INTRINSIC MUON: SPECTRAL OPTIMIZATION ON RIEMANNIAN MATRIX MANIFOLDS 11
work page 2009
-
[34]
Scalable optimization in the modular norm
Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, and Jeremy Bernstein. Scalable optimization in the modular norm. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[35]
Awell-conditionedestimatorforlarge-dimensionalcovariancematrices
OlivierLedoitandMichaelWolf. Awell-conditionedestimatorforlarge-dimensionalcovariancematrices. Journal of multivariate analysis, 88(2):365–411, 2004
work page 2004
-
[36]
Jiaxiang Li and Mingyi Hong. A note on the convergence of Muon.arXiv preprint arXiv:2502.02900, 2025
-
[37]
Preconditioning benefits of spectral orthogonalization in Muon.arXiv preprint arXiv:2601.13474, 2026
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonal- ization in Muon.arXiv preprint arXiv:2601.13474, 2026
-
[38]
Wasserstein Riemannian geometry of Gaussian densities.Information Geometry, 1(2):137–179, 2018
Luigi Malagò, Luigi Montrucchio, and Giovanni Pistone. Wasserstein Riemannian geometry of Gaussian densities.Information Geometry, 1(2):137–179, 2018
work page 2018
-
[39]
Riemannian preconditioning.SIAM Journal on Optimization, 26(1):635–660, 2016
Bamdev Mishra and Rodolphe Sepulchre. Riemannian preconditioning.SIAM Journal on Optimization, 26(1):635–660, 2016
work page 2016
-
[40]
A Riemannian geometry for low-rank matrix completion.arXiv preprint arXiv:1211.1550, 2012
Bamdev Mishra, K Aditya Apuroop, and Rodolphe Sepulchre. A Riemannian geometry for low-rank matrix completion.arXiv preprint arXiv:1211.1550, 2012
-
[41]
Bamdev Mishra, Gilles Meyer, Silvère Bonnabel, and Rodolphe Sepulchre. Fixed-rank matrix factor- izations and Riemannian low-rank optimization.Computational Statistics, 29(3–4):591–621, 2014
work page 2014
-
[42]
Parameter and memory efficient pretraining via low-rank Riemannian optimization
Zhanfeng Mo, Long-Kai Huang, and Sinno Jialin Pan. Parameter and memory efficient pretraining via low-rank Riemannian optimization. InInternational Conference on Learning Representations (ICLR),
-
[43]
URLhttps://openreview.net/forum?id=i0zzO7Hslk
-
[44]
Hadi Mohaghegh Dolatabadi, Thalaiyasingam Ajanthan, Sameera Ramasinghe, Chamin P. Hewa Koneputugodage, Shamane Siriwardhana, Violetta Shevchenko, Karol Pajak, James Snewin, Gil Avra- ham, and Alexander Long. NuMuon: Nuclear-norm-constrained Muon for compressible LLM training. arXiv preprint arXiv:2603.03597, 2026
-
[45]
Aryan Mokhtari, Hamed Hassani, and Amin Karbasi. Stochastic conditional gradient methods: From convex minimization to submodular maximization.Journal of Machine Learning Research, 21(105): 1–49, 2020
work page 2020
-
[46]
The E2E dataset: New challenges for end-to- end generation
Jekaterina Novikova, Ondřej Dušek, and Verena Rieser. The E2E dataset: New challenges for end-to- end generation. InProceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 201–206, 2017
work page 2017
-
[47]
Riemannian optimization for LoRA on the Stiefel manifold
JuneYoungPark, MinjaeKang, SeongbaeLee, HaegangLee, SeongwanKim, andJaehoLee. Riemannian optimization for LoRA on the Stiefel manifold. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 20971–20985, 2025. arXiv:2508.17901
-
[48]
A Riemannian framework for tensor computing
Xavier Pennec, Pierre Fillard, and Nicholas Ayache. A Riemannian framework for tensor computing. International Journal of computer vision, 66(1):41–66, 2006
work page 2006
-
[49]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained LMOs. InInternational Conference on Machine Learning (ICML), 2025. arXiv:2502.07529
-
[50]
A simpler approach to matrix completion.Journal of Machine Learning Research, 12 (12), 2011
Benjamin Recht. A simpler approach to matrix completion.Journal of Machine Learning Research, 12 (12), 2011
work page 2011
-
[51]
Artem Riabinin, Egor Shulgin, Kaja Gruntkowska, and Peter Richtárik. Gluon: Making Muon & Scion great again! (bridging theory and practice of LMO-based optimizers for LLMs).arXiv preprint arXiv:2505.13416, 2025
-
[52]
arXiv preprint arXiv:2507.01598 , year =
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Convergence bound and critical batch size of Muon optimizer.arXiv preprint arXiv:2507.01598, 2025
-
[53]
A geometric framework for momentum-based optimizers for low-rank training
Steffen Schotthöfer, Timon Klein, and Jonas Kusch. A geometric framework for momentum-based optimizers for low-rank training. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[54]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of Muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Complexities in projection-free stochastic non-convex minimization
Zebang Shen, Cong Fang, Peilin Zhao, Junzhou Huang, and Hui Qian. Complexities in projection-free stochastic non-convex minimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 2868–2876. PMLR, 2019. 12 Y. LI, B. L. PANDEY, R. SAH, A. HAN, C. MOSTAJERAN, P. JA W ANPURIA, AND B. MISHRA
work page 2019
-
[56]
Tian Tong, Cong Ma, and Yuejie Chi. Accelerating ill-conditioned low-rank matrix estimation via scaled gradient descent.Journal of Machine Learning Research, 22(150):1–63, 2021
work page 2021
-
[57]
Region covariance: A fast descriptor for detection and classification
Oncel Tuzel, Fatih Porikli, and Peter Meer. Region covariance: A fast descriptor for detection and classification. InEuropean conference on computer vision, pages 589–600. Springer, 2006
work page 2006
-
[58]
Oncel Tuzel, Fatih Porikli, and Peter Meer. Pedestrian detection via classification on Riemannian manifolds.IEEE transactions on pattern analysis and machine intelligence, 30(10):1713–1727, 2008
work page 2008
-
[59]
Bart Vandereycken. Low-rank matrix completion by Riemannian optimization.SIAM Journal on Optimization, 23(2):1214–1236, 2013
work page 2013
-
[60]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. InInternational Conference on Learning Representations (ICLR), 2019. URLhttps://openreview.net/forum?id= rJ4km2R5t7. arXiv:1804.07461
work page internal anchor Pith review arXiv 2019
-
[61]
Additive margin softmax for face verification
Feng Wang, Jian Cheng, Weiyang Liu, and Haijun Liu. Additive margin softmax for face verification. IEEE Signal Processing Letters, 25(7):926–930, 2018
work page 2018
-
[62]
Taming momentum: Rethinking opti- mizer states through low-rank approximation
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. Taming momentum: Rethinking opti- mizer states through low-rank approximation. InInternational Conference on Learning Representations (ICLR), 2026. Oral; arXiv:2602.24283
-
[63]
Riemannian optimization via Frank–Wolfe methods.Mathematical Programming, 199:525–556, 2023
Melanie Weber and Suvrit Sra. Riemannian optimization via Frank–Wolfe methods.Mathematical Programming, 199:525–556, 2023
work page 2023
-
[64]
Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps: //openreview.net/forum?id=2J51qUZ0iG. arXiv:2509.02046
-
[65]
Face recognition in unconstrained videos with matched back- ground similarity
Lior Wolf, Tal Hassner, and Itay Maoz. Face recognition in unconstrained videos with matched back- ground similarity. InCVPR 2011, pages 529–534. IEEE, 2011
work page 2011
-
[66]
Controlled llm training on spectral sphere.arXiv preprint arXiv: 2601.08393,
TianXie, HaomingLuo, HaoyuTang, YiwenHu, JasonKleinLiu, QingnanRen, YangWang, WayneXin Zhao, Rui Yan, Bing Su, Chong Luo, and Baining Guo. Controlled LLM training on spectral sphere. arXiv preprint arXiv:2601.08393, 2026
-
[67]
Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tuning large neural networks via zero-shot hyperpa- rameter transfer. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, 2021. arXiv:2203.03466
-
[68]
A spectral condition for feature learning
Greg Yang, James B. Simon, and Jeremy Bernstein. A spectral condition for feature learning.arXiv preprint arXiv:2310.17813, 2024
-
[69]
Manifold constrained steepest descent.arXiv preprint arXiv:2601.21487, 2026
Kaiwei Yang and Lexiao Lai. Manifold constrained steepest descent.arXiv preprint arXiv:2601.21487, 2026
-
[70]
Riemannian preconditioned LoRA for fine-tuning foundation models
Fangzhao Zhang and Mert Pilanci. Riemannian preconditioned LoRA for fine-tuning foundation models. InInternational Conference on Machine Learning (ICML), 2024. arXiv:2402.02347
-
[71]
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. GaLore: Memory-efficient LLM training by gradient low-rank projection. InInternational Conference on Machine Learning (ICML), 2024. arXiv:2403.03507. Appendix Appendix A. Broader Societal Impact 13 Appendix B. Limitations 14 Appendix C. Closed-Form LMO Solutions vi...
-
[72]
observe that the objective function in feedforward neural networks admits a tighter majorization bound under the Schatten-∞norm than under the Frobenius norm, and derive the corresponding steepest-descent operator, which is precisely the orthogonal polar factorOrtho(·)used by Muon. They further combine this non-Euclidean gradient with element-wise adaptiv...
-
[73]
We then build a shrinkage regularized covariance descriptorCi ∈S 32 ++ [24, 35, 57] for each image using covariance shrinkage0.1and diagonal stabilizationε= 10 −4. We use the standard CIFAR-100 train/test split and reserve10%of the training set as a validation split for learning-rate selection. Results. Table 15 reports validation-selected test accuracy f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.