Recognition: 2 theorem links
· Lean TheoremLLM Agents Already Know When to Call Tools -- Even Without Reasoning
Pith reviewed 2026-05-12 02:37 UTC · model grok-4.3
The pith
LLM agents already encode whether a tool is needed in their hidden states before generating any output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
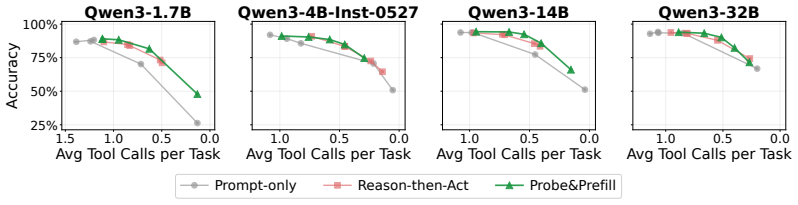
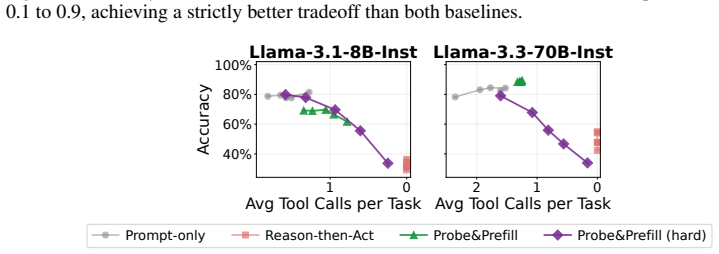
Tool necessity is linearly decodable from the pre-generation representation with AUROC 0.89-0.96 across six models, substantially exceeding the model's own verbalized reasoning. This reveals that models already know when tools are needed, but fail to act on this knowledge during generation. A linear probe that reads this signal and prefills a steering sentence reduces tool calls by 48 percent with only 1.7 percent accuracy loss, outperforming prompt-only and reason-then-act baselines.
What carries the argument
A linear probe trained on hidden states before generation that detects tool necessity and steers output by prefilling a short sentence.
If this is right
- Forcing explicit verbal reasoning before tool use does not reliably improve decisions and can reduce accuracy on difficult tasks.
- Prompt modifications that discourage tool calls also suppress many necessary ones.
- Hidden-state steering achieves a better accuracy-versus-tool-use trade-off than either prompt engineering or forced reasoning.
- The internal signal appears consistently across multiple model families and sizes.
Where Pith is reading between the lines
- Agent designs that rely on explicit reasoning steps may be less efficient than methods that directly read and use the model's internal representations.
- Similar linear probes could be applied to other agent decisions such as when to stop or how to break a problem into steps.
- Making models act on what they already know internally may improve efficiency more than further scaling alone.
- If the signal proves stable, agent systems could routinely monitor hidden states to minimize unnecessary external calls.
Load-bearing premise
The linear relationship between hidden states and tool necessity found on the benchmark will continue to hold on new tasks and new models.
What would settle it
On a fresh collection of tasks, a linear probe on pre-generation states yields AUROC below 0.75 or the steering method produces more than 5 percent accuracy loss at the same level of tool-call reduction.
Figures




read the original abstract
Tool-augmented LLM agents tend to call tools indiscriminately, even when the model can answer directly. Each unnecessary call wastes API fees and latency, yet no existing benchmark systematically studies when a tool call is actually needed. We propose When2Tool, a benchmark of 18 environments (15 single-hop, 3 multi-hop) spanning three categories of tool necessity -- computational scale, knowledge boundaries, and execution reliability -- each with controlled difficulty levels that create a clear decision boundary between tool-necessary and tool-unnecessary tasks. We evaluate two families of training-free baselines: Prompt-only (varying the prompt to discourage unnecessary calls) and Reason-then-Act (requiring the model to reason about tool necessity before acting). Both provide limited control: Prompt-only suppresses necessary calls alongside unnecessary ones, and Reason-then-Act still incurs a disproportionate accuracy cost on hard tasks. To understand why these baselines fail, we probe the models' hidden states and find that tool necessity is linearly decodable from the pre-generation representation with AUROC 0.89--0.96 across six models, substantially exceeding the model's own verbalized reasoning. This reveals that models already know when tools are needed, but fail to act on this knowledge during generation. Building on this finding, we propose Probe&Prefill, which uses a lightweight linear probe to read the hidden-state signal and prefills the model's response with a steering sentence. Across all models tested, Probe&Prefill reduces tool calls by 48% with only 1.7% accuracy loss, while the best baseline at comparable accuracy only reduces 6% of tool calls, or achieves a similar tool call reduction but incurs a 5$\times$ higher accuracy loss. Our code is available at https://github.com/Trustworthy-ML-Lab/when2tool
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the When2Tool benchmark of 18 environments (15 single-hop, 3 multi-hop) spanning three categories of tool necessity—computational scale, knowledge boundaries, and execution reliability—with controlled difficulty levels that create clear decision boundaries. It evaluates prompt-only and reason-then-act baselines, which either suppress necessary calls or incur high accuracy costs. Probing shows tool necessity is linearly decodable from pre-generation hidden states with AUROC 0.89–0.96 across six models, exceeding verbalized reasoning. It proposes Probe&Prefill, which uses a linear probe on hidden states to prefill a steering sentence, reducing tool calls by 48% with 1.7% accuracy loss while outperforming baselines.
Significance. If the results hold, the work is significant for understanding and improving LLM agent tool use: it provides empirical evidence of an internal, linearly readable signal for tool necessity that is not acted upon during generation, plus a lightweight, training-free intervention that substantially improves efficiency. Credit is due for the multi-model evaluation, head-to-head baseline comparisons, open code release, and the falsifiable prediction that hidden-state decodability should enable better control than verbalized reasoning.
major comments (2)
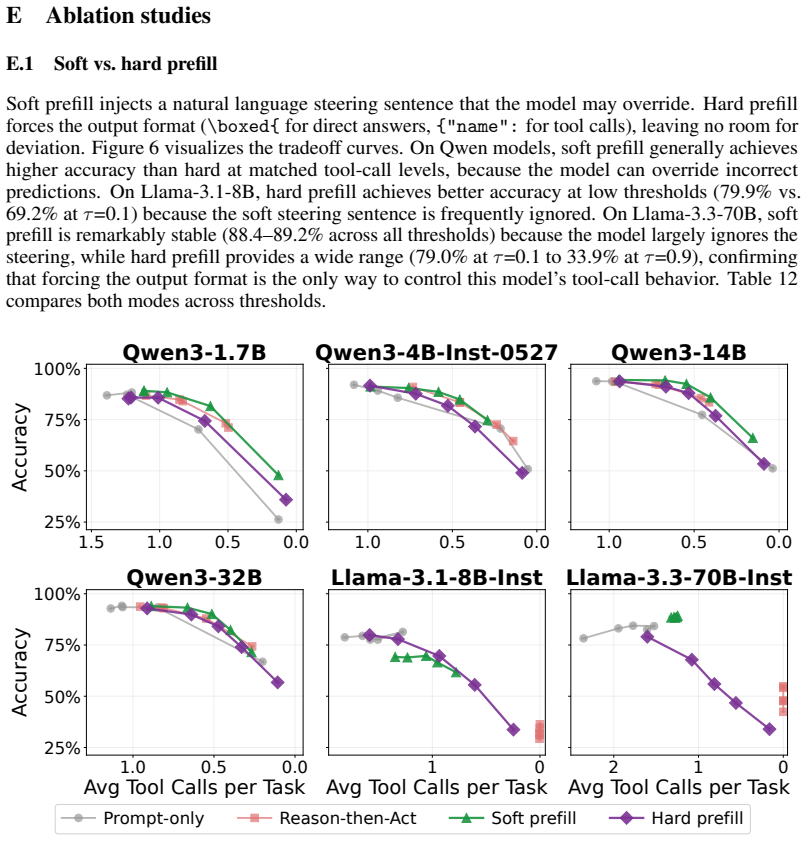
- [§4 (probe evaluation)] §4 (probe evaluation): AUROC 0.89–0.96 is reported on the full When2Tool benchmark without cross-category hold-out experiments. A probe trained only on computational-scale examples could exploit scale-related features in the hidden states while failing on knowledge-boundary or reliability tasks; this would mean the decodability reflects benchmark construction artifacts rather than a unified, actionable model-internal representation, directly undermining the 'already know' claim and the claimed generality of Probe&Prefill.
- [§3.2 and §5 (probe training and Probe&Prefill)] §3.2 and §5 (probe training and Probe&Prefill): the manuscript does not specify the exact hidden-state extraction (layer, token position), the train/validation split used to fit the linear probe, or statistical testing (e.g., confidence intervals or significance tests) for the reported AUROC values and the 48% vs. 1.7% trade-off. These details are load-bearing for interpreting whether the intervention's gains are robust or sensitive to probe-fitting choices.
minor comments (2)
- [Abstract] Abstract: the claim that the probe 'substantially exceed[s] the model's own verbalized reasoning' should include the exact metric and baseline used for the verbalized-reasoning comparison.
- [Tables/figures] Tables/figures: ensure all performance tables report standard deviations or error bars and that figure captions explicitly state the number of runs and random seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the strength of evidence for a unified internal representation of tool necessity. We respond to each major comment below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [§4 (probe evaluation)] §4 (probe evaluation): AUROC 0.89–0.96 is reported on the full When2Tool benchmark without cross-category hold-out experiments. A probe trained only on computational-scale examples could exploit scale-related features in the hidden states while failing on knowledge-boundary or reliability tasks; this would mean the decodability reflects benchmark construction artifacts rather than a unified, actionable model-internal representation, directly undermining the 'already know' claim and the claimed generality of Probe&Prefill.
Authors: We agree that explicit cross-category hold-out experiments are necessary to substantiate the claim of a general, model-internal signal rather than category-specific artifacts. The reported AUROCs aggregate performance across all 18 environments and three categories, but do not isolate generalization. We will add these experiments to §4 by training the probe on two categories and evaluating AUROC on the held-out category (and all pairwise combinations). Results will be reported for all six models; if AUROCs remain in the 0.85+ range, this will support the unified-representation interpretation, and we will update the discussion of Probe&Prefill generality accordingly. revision: yes
-
Referee: [§3.2 and §5 (probe training and Probe&Prefill)] §3.2 and §5 (probe training and Probe&Prefill): the manuscript does not specify the exact hidden-state extraction (layer, token position), the train/validation split used to fit the linear probe, or statistical testing (e.g., confidence intervals or significance tests) for the reported AUROC values and the 48% vs. 1.7% trade-off. These details are load-bearing for interpreting whether the intervention's gains are robust or sensitive to probe-fitting choices.
Authors: We acknowledge that these implementation details were insufficiently specified. The linear probe is fit to the final-layer hidden state at the last input token position (immediately prior to generation start). Training uses an 80/20 stratified split by environment and category, with the validation portion used only for probe selection. We will add these specifications verbatim to §3.2. In §5 we will also report 95% bootstrap confidence intervals on all AUROC figures and on the accuracy/tool-call metrics, plus paired significance tests (McNemar) comparing Probe&Prefill against the strongest baseline at matched accuracy. These additions will allow readers to assess robustness directly. revision: yes
Circularity Check
No circularity: empirical measurements of decodability and intervention effects are direct and self-contained.
full rationale
The paper constructs the When2Tool benchmark, evaluates prompt and reasoning baselines, trains linear probes on pre-generation hidden states to measure AUROC for tool necessity, and tests the Probe&Prefill intervention. None of these steps involve a derivation, equation, or first-principles result that reduces to its own inputs by construction. The reported AUROC values (0.89-0.96) are observable outcomes of fitting and evaluating a probe on the benchmark data; they are not tautological or forced by redefining the target quantity. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The findings are therefore self-contained empirical results that can be reproduced or falsified independently of the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tool necessity is linearly separable in the model's pre-generation hidden-state representation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability uncleartool necessity is linearly decodable from the pre-generation representation with AUROC 0.89--0.96 across six models
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPROBE&PREFILL reduces tool calls by 48% with only 1.7% accuracy loss
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[2]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. arXiv preprint arXiv:2307.16789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Alignment for efficient tool calling of large language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[5]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
A joint optimization framework for enhancing efficiency of tool utilization in llm agents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[6]
arXiv preprint arXiv:2601.14192 , year=
Toward Efficient Agents: Memory, Tool learning, and Planning , author=. arXiv preprint arXiv:2601.14192 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Toolqa: A dataset for llm question answering with external tools , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[9]
A structural probe for finding syntax in word representations , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
work page 2019
-
[10]
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2412.07992 , year=
Concept bottleneck large language models , author=. arXiv preprint arXiv:2412.07992 , year=
-
[14]
Activation addition: Steering language models without optimization , author=
-
[15]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Thinkedit: Interpretable weight editing to mitigate overly short thinking in reasoning models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[17]
Effective skill unlearning through intervention and abstention , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[18]
arXiv preprint arXiv:2512.13979 , year=
ReflCtrl: Controlling LLM Reflection via Representation Engineering , author=. arXiv preprint arXiv:2512.13979 , year=
-
[19]
arXiv preprint arXiv:2602.09870 , year=
Steer2Edit: From Activation Steering to Component-Level Editing , author=. arXiv preprint arXiv:2602.09870 , year=
-
[20]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Search-o1: Agentic search-enhanced large reasoning models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[21]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[22]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[23]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[24]
Dr tulu: Reinforcement learning with evolving rubrics for deep research , author=. arXiv preprint arXiv:2511.19399 , year=
- [25]
-
[26]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2505.09569 , year=
MigrationBench: Repository-Level Code Migration Benchmark from Java 8 , author=. arXiv preprint arXiv:2505.09569 , year=
-
[28]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? , author=. arXiv preprint arXiv:2509.16941 , year=
work page internal anchor Pith review arXiv
-
[29]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. arXiv preprint arXiv:2506.07982 , year=
work page internal anchor Pith review arXiv
-
[32]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces , author=. arXiv preprint arXiv:2601.11868 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.