Recognition: 2 theorem links
· Lean TheoremChain-of-Thought Reasoning Enhances In-Context Learning for LLM-Based Mobile Traffic Prediction
Pith reviewed 2026-05-12 04:48 UTC · model grok-4.3
The pith
Chain-of-thought reasoning in LLMs improves mobile traffic prediction accuracy by up to 15 percent over standard in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying a plan-based chain-of-thought pipeline to generate rationales for traffic data and retrieving similar demonstrations via a policy that accounts for both historical throughput and short-term variations, the CoT-LLM approach reduces prediction errors compared to plain in-context learning and classical methods, with up to 14.88% better mean absolute error, 15.03% better root mean square error, and 22.41% better R2-score on real-world 5G measurements.
What carries the argument
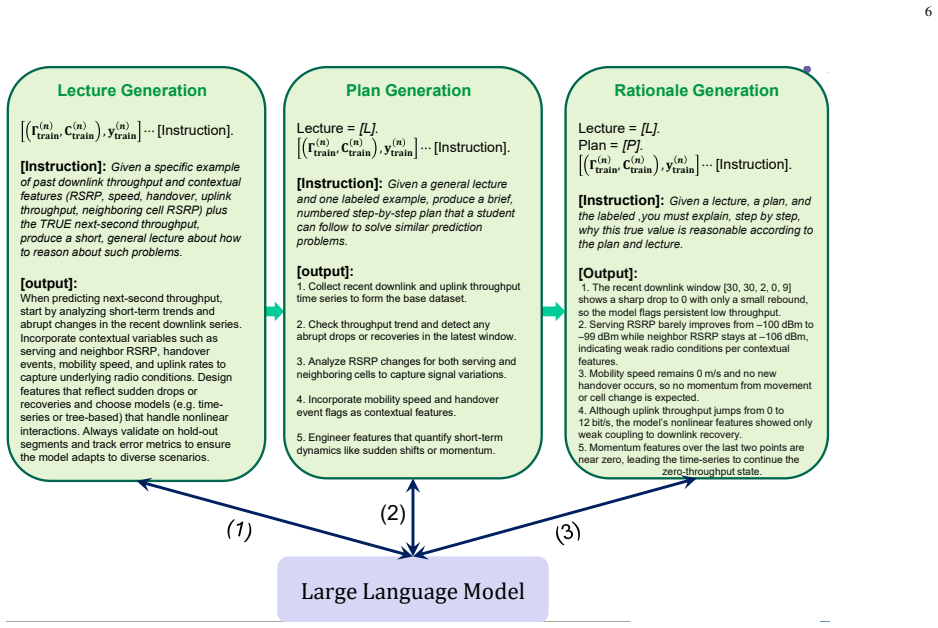
The plan-based CoT (PCoT) pipeline (lecture, plan, and rationale) that structures the LLM's reasoning about temporal traffic dynamics, paired with a similarity policy for demonstration retrieval.
If this is right
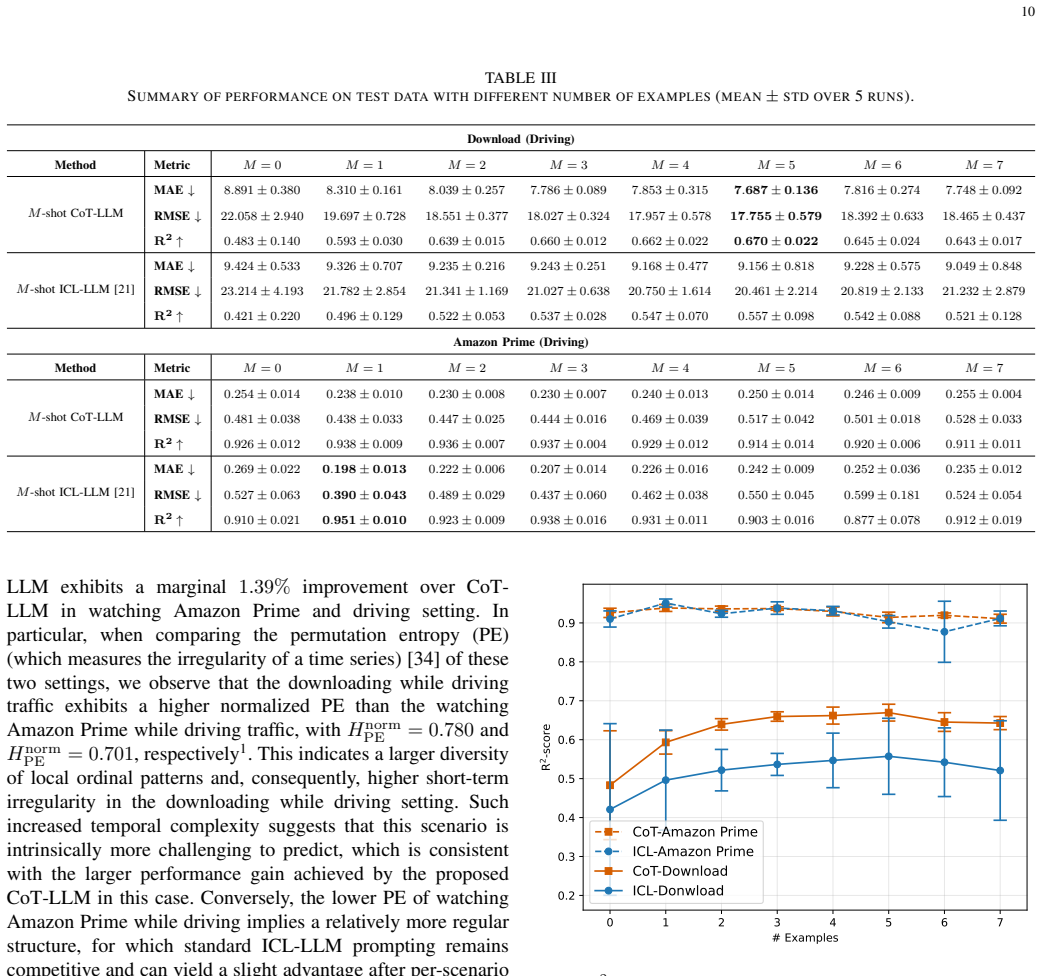
- Using 2-shot CoT-LLM yields improvements of up to 14.88% in MAE, 15.03% in RMSE, and 22.41% in R2-score over 2-shot ICL-LLM and classical baselines.
- Optimizing the number of in-context examples provides additional gains of 4.58% in MAE, 5.70% in RMSE, and 4.85% in R2-score.
- The framework supports close to real-time prediction in both driving and static scenarios across various applications.
- Structured rationales help address numerical instability and limited temporal reasoning in naive ICL for fluctuating traffic data.
Where Pith is reading between the lines
- If the rationales capture general dynamics, the approach could apply to other sequential prediction tasks like user mobility or energy usage in networks.
- Further work might test whether increasing the number of shots beyond the optimized value continues to improve results or leads to diminishing returns.
- Replacing the similarity policy with random selection would likely eliminate the observed gains, isolating the contribution of CoT.
Load-bearing premise
The plan-based CoT pipeline generates rationales that truly capture temporal traffic dynamics and the similarity policy selects demonstrations that generalize to new short-term fluctuations.
What would settle it
Evaluating the model on traffic data containing abrupt changes or patterns absent from the demonstration set and checking whether the reported error reductions still hold.
Figures



read the original abstract
Accurate short-term mobile traffic prediction is important for proactive resource allocation and low-latency network management in fifth generation (5G) and sixth generation (6G). While large language models (LLMs) can perform in-context learning (ICL) without task-specific retraining, naive ICL prompting may suffer from numerical instability and limited temporal reasoning when traffic dynamics fluctuate rapidly. In this paper, we propose a chain-of-thought (CoT)-enabled LLM-based mobile traffic prediction framework that operates in two phases: (i) an offline phase that constructs structured CoT demonstrations by generating rationales via a plan-based CoT (PCoT) pipeline (lecture, plan, and rationale), and (ii) an online phase that performs close to real-time prediction by retrieving the most relevant demonstrations using a similarity policy that considers both the historical throughput pattern and its short-term changes. We evaluate the proposed framework using a real-world 5G measurement dataset that includes both driving and static scenarios across diverse applications. Our numerical results reveal that the proposed 2-shot CoT-LLM can improve mean absolute error (MAE), root mean square error (RMSE) and R2-score by up to 14.88%, 15.03%, and 22.41%, respectively, compared to the 2-shot ICL-LLM and classical baselines. Furthermore, by optimizing the number of in-context examples, we achieve additional improvements of 4.58%, 5.70%, and 4.85% in MAE, RMSE, and R2-score, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-phase CoT-enabled LLM framework for short-term mobile traffic prediction: an offline phase that builds structured demonstrations using a plan-based CoT (PCoT) pipeline (lecture, plan, rationale) and an online phase that retrieves the most similar demonstrations via a similarity policy based on historical throughput patterns and short-term changes. Evaluated on a real 5G dataset covering driving and static scenarios, the 2-shot CoT-LLM variant reports up to 14.88% MAE, 15.03% RMSE, and 22.41% R² improvements over 2-shot ICL-LLM and classical baselines, with further gains from optimizing the number of in-context examples.
Significance. If the empirical gains hold under rigorous controls, the work provides concrete evidence that structured CoT reasoning can improve LLM in-context learning for time-series forecasting in networking applications, without requiring fine-tuning. The use of a real-world 5G measurement dataset and explicit comparison to both ICL and classical methods (e.g., ARIMA, LSTM) adds practical relevance for proactive resource allocation in 5G/6G systems. The reproducible experimental protocol (dataset splits, similarity metric, LLM backbone) is a strength.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): the reported percentage improvements lack accompanying statistical significance tests (e.g., paired t-tests or Wilcoxon tests across multiple runs) and error bars on the MAE/RMSE/R² tables. Given the stochastic nature of LLM outputs and potential sensitivity to prompt ordering, it is unclear whether the 14.88–22.41% gains are robust or could arise from variance; this directly affects the central claim of consistent enhancement.
- [§3.2] §3.2 (Similarity Policy): the retrieval policy combines historical pattern and short-term change similarity, but the manuscript does not report an ablation isolating the contribution of the short-term change component. Without this, it is difficult to confirm that the policy reliably surfaces generalizable demonstrations for unseen fluctuations, which is load-bearing for the online-phase claim.
minor comments (3)
- [Table 1, Figure 3] Table 1 and Figure 3: axis labels and legend entries should explicitly state the units (e.g., Mbps for throughput) and the exact number of runs averaged; current presentation makes it hard to assess scale.
- [§2] §2 (Related Work): the discussion of prior LLM-for-time-series work omits recent papers on CoT for forecasting (e.g., those using plan-and-execute prompting); adding 2–3 targeted citations would better situate the PCoT pipeline.
- [Abstract] The abstract states improvements 'compared to the 2-shot ICL-LLM and classical baselines' but does not name the classical baselines; this should be clarified in the abstract for readers who stop at the first page.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment of our work. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): the reported percentage improvements lack accompanying statistical significance tests (e.g., paired t-tests or Wilcoxon tests across multiple runs) and error bars on the MAE/RMSE/R² tables. Given the stochastic nature of LLM outputs and potential sensitivity to prompt ordering, it is unclear whether the 14.88–22.41% gains are robust or could arise from variance; this directly affects the central claim of consistent enhancement.
Authors: We agree that statistical significance testing and error bars are necessary to demonstrate robustness given LLM stochasticity. In the revised manuscript, we will rerun all experiments across multiple random seeds (at least 5 runs per configuration, varying prompt ordering and sampling temperature) and report mean ± standard deviation for MAE, RMSE, and R² in the tables of §5, with error bars added to the corresponding figures. We will also include paired t-tests (or Wilcoxon signed-rank tests where appropriate) between the proposed CoT-LLM and the ICL-LLM/baselines, reporting p-values to confirm that the observed improvements are statistically significant rather than attributable to variance. revision: yes
-
Referee: [§3.2] §3.2 (Similarity Policy): the retrieval policy combines historical pattern and short-term change similarity, but the manuscript does not report an ablation isolating the contribution of the short-term change component. Without this, it is difficult to confirm that the policy reliably surfaces generalizable demonstrations for unseen fluctuations, which is load-bearing for the online-phase claim.
Authors: We acknowledge that an explicit ablation would better isolate the contribution of the short-term change component. In the revision, we will add a dedicated ablation study in §5 comparing three retrieval variants on the same 5G dataset: (i) historical pattern similarity only, (ii) short-term change similarity only, and (iii) the combined policy. Results will be reported separately for static and driving scenarios to show that the short-term component improves generalization to rapid fluctuations, thereby supporting the online-phase design. revision: yes
Circularity Check
No significant circularity in empirical framework
full rationale
The paper is a purely empirical study proposing a two-phase CoT-LLM framework (offline PCoT demonstration construction via lecture/plan/rationale, online similarity-based retrieval) and reporting measured improvements (MAE/RMSE/R2 gains) on a real 5G dataset against external baselines. No derivation chain, equations, or fitted parameters exist that reduce the claimed predictions to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The evaluation protocol (dataset splits, metrics, LLM backbone) is externally verifiable and contains no internal reduction or renaming of known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
plan-based CoT (PCoT) pipeline (lecture, plan, and rationale) ... similarity policy that considers both the historical throughput pattern and its short-term changes
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
2-shot CoT-LLM ... improve MAE, RMSE and R2-score by up to 14.88%, 15.03%, and 22.41%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. Lykakis, I. O. Vardiambasis, and E. Kokkinos, “Data traffic prediction for 5G and beyond: Emerging trends, challenges, and future directions: A scoping review,”Electronics, vol. 14, no. 23, p. 4611, 2025
work page 2025
-
[2]
A vision of 6G wireless systems: Applications, trends, technologies, and open research problems,
W. Saad, M. Bennis, and M. Chen, “A vision of 6G wireless systems: Applications, trends, technologies, and open research problems,”IEEE Commun. Mag., vol. 58, no. 9, pp. 74–80, 2020
work page 2020
-
[3]
From large AI models to agentic AI: A tutorial on future intelligent communications,
F. Jiang, C. Pan, K. Wang, P. Michiardi, O. A. Dobre, and M. Debbah, “From large AI models to agentic AI: A tutorial on future intelligent communications,”IEEE J. Sel. Areas Commun., vol. 44, pp. 3507–3540, 2026
work page 2026
-
[4]
A survey on modern deep neural network for traffic prediction: Trends, methods and challenges,
D. A. Tedjopurnomo, Z. Bao, B. Zheng, F. M. Choudhury, and A. K. Qin, “A survey on modern deep neural network for traffic prediction: Trends, methods and challenges,”IEEE Trans. Knowl. Data Eng., vol. 34, no. 4, pp. 1544–1561, 2022
work page 2022
-
[5]
Deep learning on traffic prediction: Methods, analysis, and future directions,
X. Yin, G. Wu, J. Wei, Y . Shen, H. Qi, and B. Yin, “Deep learning on traffic prediction: Methods, analysis, and future directions,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 6, pp. 4927–4943, 2022
work page 2022
-
[6]
P. E. Iturria-Rivera, M. Chenier, B. Herscovici, B. Kantarci, and M. Erol- Kantarci, “Rl meets multi-link operation in ieee 802.11be: Multi-headed recurrent soft-actor critic-based traffic allocation,” inProc. IEEE Int. Conf. Commun. (ICC) 2023, 2023, pp. 4001–4006
work page 2023
-
[7]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplanet al., “Language models are few-shot learners,”Adv. Neural Inf. Process. Syst. (NeuroIPS), vol. 33, pp. 1877–1901, 2020
work page 1901
-
[8]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, b. ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdv. Neural Inf. Process. Syst. (NeuroIPS), vol. 35, 2022, pp. 24 824–24 837
work page 2022
-
[9]
Performance analysis of network traffic predictors in the cloud,
B. L. Dalmazo, J. a. P. Vilela, and M. Curado, “Performance analysis of network traffic predictors in the cloud,”J. Netw. Syst. Manage., vol. 25, no. 2, p. 290–320, Apr. 2017
work page 2017
-
[10]
Z. Tian and F. Li, “Network traffic prediction method based on autoregressive integrated moving average and adaptive volterra filter,” Int. J. Commun. Sys., vol. 34, no. 12, 2021. [Online]. Available: https://doi.org/10.1002/dac.4891
-
[11]
Mobile traffic prediction from raw data using LSTM networks,
H. D. Trinh, L. Giupponi, and P. Dini, “Mobile traffic prediction from raw data using LSTM networks,” inProc. IEEE Int. Symp. Personal, Indoor and Mobile Radio Commun. (PIMRC). Bologna, Italy: IEEE, 2018, pp. 1–6
work page 2018
-
[12]
Adaptive graph convolutional recurrent network for traffic forecasting,
L. Bai, L. Yao, C. Li, X. Wang, and C. Wang, “Adaptive graph convolutional recurrent network for traffic forecasting,” inProc. Annual Conf. Neural Inf. Process. Syst. (NeurIPS), 2020
work page 2020
-
[13]
SDGNet: A handover-aware spa- tiotemporal graph neural network for mobile traffic forecasting,
Y . Fang, S. Erg ¨ut, and P. Patras, “SDGNet: A handover-aware spa- tiotemporal graph neural network for mobile traffic forecasting,”IEEE Commun. Lett., vol. 26, no. 3, pp. 582–586, 2022
work page 2022
-
[14]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdv. Neural Inf. Process. Syst. (NeuroIPS), 2017, pp. 5998–6008
work page 2017
-
[15]
Mobile network traffic prediction using temporal fusion transformer,
G. Kougioumtzidis, V . K. Poulkov, P. I. Lazaridis, and Z. D. Zaharis, “Mobile network traffic prediction using temporal fusion transformer,” IEEE Trans. Artif. Intell., vol. 6, no. 10, pp. 2685–2699, 2025
work page 2025
-
[16]
Citywide mobile traffic forecasting using spatial-temporal downsampling transformer neural networks,
Y . Hu, Y . Zhou, J. Song, L. Xu, and X. Zhou, “Citywide mobile traffic forecasting using spatial-temporal downsampling transformer neural networks,”IEEE Trans. Netw. Serv. Manage., vol. 20, no. 1, pp. 152– 165, 2023
work page 2023
-
[17]
STTF: A spatiotemporal transformer framework for multi-task mobile network prediction,
J. Gong, Y . Liu, T. Li, J. Ding, Z. Wang, and D. Jin, “STTF: A spatiotemporal transformer framework for multi-task mobile network prediction,”IEEE Trans. Mobile Comput., vol. 24, no. 5, pp. 4072–4085, 2025
work page 2025
-
[18]
A spatial- temporal transformer network for city-level cellular traffic analysis and prediction,
B. Gu, J. Zhan, S. Gong, W. Liu, Z. Su, and M. Guizani, “A spatial- temporal transformer network for city-level cellular traffic analysis and prediction,”IEEE Trans. Wireless Commun., vol. 22, no. 12, pp. 9412– 9423, 2023
work page 2023
-
[19]
H. Zhou, C. Hu, Y . Yuan, Y . Cui, Y . Jin, C. Chen, H. Wu, D. Yuan, L. Jiang, D. Wu, X. Liu, C. Zhang, X. Wang, and J. Liu, “Large language model (LLM) for telecommunications: A comprehensive survey on principles, key techniques, and opportunities,”IEEE Commun. Surveys Tuts., vol. 27, no. 3, pp. 1955–2005, 2024
work page 1955
-
[20]
H. Zhang, A. B. Sediq, A. Afana, and M. Erol-Kantarci, “Large language models in wireless application design: In-context learning-enhanced automatic network intrusion detection,” inProc. IEEE Global Commun. Conf. (GLOBECOM), 2024, pp. 2479–2484
work page 2024
-
[21]
Mobile traffic prediction using LLMs with efficient in-context demonstration selection,
H. Zhang, A. Bin Sediq, A. Afana, and M. Erol-Kantarci, “Mobile traffic prediction using LLMs with efficient in-context demonstration selection,”IEEE Transactions on Communications, vol. 73, no. 11, pp. 11 170–11 185, 2025
work page 2025
-
[22]
Self-refined generative foundation models for wireless traffic prediction,
C. Hu, H. Zhou, D. Wu, X. Chen, J. Yan, and X. Liu, “Self-refined generative foundation models for wireless traffic prediction,”IEEE Trans. Veh. Technol., 2025
work page 2025
-
[23]
M. A. Habib, P. E. Iturria Rivera, Y . Ozcan, M. H. M. Elsayed, M. Bavand, R. Gaigalas, and M. Erol-Kantarci, “LLM-based intent processing and network optimization using attention-based hierarchical reinforcement learning,” inProc. 2025 IEEE Wireless Commun. Netw. Conf. (WCNC), 2025, pp. 1–6
work page 2025
-
[24]
Tempo: Prompt-based generative pre-trained transformer for time series forecasting,
D. Cao, F. Jia, S. O. Arik, T. Pfister, Y . Zheng, W. Ye, and Y . Liu, “Tempo: Prompt-based generative pre-trained transformer for time series forecasting,” inProc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[25]
LLM4TS: Align- ing pre-trained LLMs as data-efficient time-series forecasters,
C. Chang, W.-Y . Wang, W.-C. Peng, and T.-F. Chen, “LLM4TS: Align- ing pre-trained LLMs as data-efficient time-series forecasters,”ACM Trans. Intell. Syst. Technol., vol. 16, no. 3, pp. 1–20, 2025. 13
work page 2025
-
[26]
Reasoning AI performance degradation in 6G networks with large language models,
L. Huang, Y . Wu, and D. Simeonidou, “Reasoning AI performance degradation in 6G networks with large language models,” inProc. 2025 IEEE Wireless Commun. Netw. Conf. (WCNC), 2025, pp. 1–6
work page 2025
-
[27]
Chain-of-thought for large language model-empowered wireless communications,
X. Wang, J. Zhu, R. Zhang, L. Feng, D. Niyato, J. Wang, H. Du, S. Mao, and Z. Han, “Chain-of-thought for large language model-empowered wireless communications,”arXiv preprint arXiv:2505.22320, 2025
-
[28]
Large language models are zero-shot reasoners,
T. Kojima, S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inAdv. Neural Inf. Process. Syst. (NeuroIPS), vol. 35, 2022, pp. 22 199–22 213
work page 2022
-
[29]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Changet al., “A survey on in-context learning,” inProc. 2024 Conf. Empir. Methods Nat. Lang. Process., 2024, pp. 1107–1128
work page 2024
-
[30]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,
L. Wang, W. Xu, Y . Lan, Z. Hu, Y . Lan, R. K.-W. Lee, and E.-P. Lim, “Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,” inProc. 61st Annu. Meeting Assoc. Comput. Linguistics, Toronto, Canada, 2023, pp. 2609–2634
work page 2023
-
[31]
Beyond throughput, the next generation: A 5G dataset with channel and context metrics,
D. Raca, D. Leahy, C. J. Sreenan, and J. J. Quinlan, “Beyond throughput, the next generation: A 5G dataset with channel and context metrics,” in Proc. 11th ACM Multimedia Syst. Conf. (MMSys ’20). ACM, 2020, pp. 303–308
work page 2020
-
[32]
Realtime mobile bandwidth and handoff predictions in 4G/5G networks,
L. Mei, J. Gou, Y . Cai, H. Cao, and Y . Liu, “Realtime mobile bandwidth and handoff predictions in 4G/5G networks,”Comput. Netw., vol. 204, p. 108736, Feb. 2022
work page 2022
- [33]
-
[34]
Permutation entropy: A natural complexity measure for time series,
C. Bandt and B. Pompe, “Permutation entropy: A natural complexity measure for time series,”Physical Review Letters, vol. 88, no. 17, p. 174102, 2002
work page 2002
-
[35]
Mistral AI, “Ministral 3 3b,” Mistral Docs (Open v25.12), Dec. 2025, accessed 2025-12-28
work page 2025
-
[36]
A. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Phi-4-reasoning technical report, 2025
M. Abdinet al., “Phi-4-reasoning technical report,”arXiv preprint arXiv:2504.21318, 2025
-
[38]
LLM-inference-bench: Inference benchmark- ing of large language models on AI accelerators,
K. Chitty-Venkataet al., “LLM-inference-bench: Inference benchmark- ing of large language models on AI accelerators,” inProc. SC24-W: Workshops Int. Conf. High Perform. Comput., Netw., Storage Anal., Atlanta, GA, USA, 2024, pp. 1362–1379
work page 2024
-
[39]
Latency-aware joint task offloading and energy control for cooperative mobile edge computing,
W. Fan, F. Xiao, Y . Pan, X. Chen, L. Han, and S. Yu, “Latency-aware joint task offloading and energy control for cooperative mobile edge computing,”IEEE Trans. Serv. Comput., vol. 18, no. 3, pp. 1515–1528, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.