Recognition: 3 theorem links
· Lean TheoremShaping Schema via Language Representation as the Next Frontier for LLM Intelligence Expanding
Pith reviewed 2026-05-12 04:56 UTC · model grok-4.3
The pith
Shaping schemas through advanced language representation is the next frontier for expanding LLM intelligence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
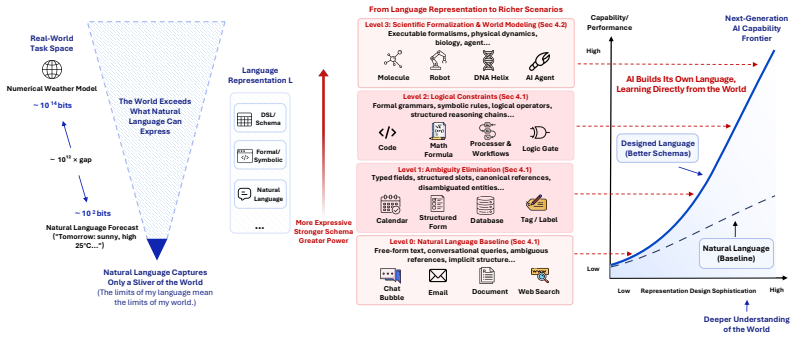
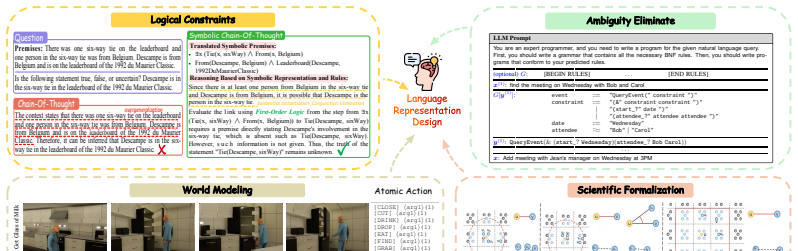
An LLM's schema, its knowledge activation and organization, depends heavily on the structural and symbolic sophistication of the language used to represent a given task. Shaping schemas through advanced language representation therefore constitutes the next frontier for expanding LLM intelligence, as shown by empirical practices and controlled experiments where performance and feature activations vary with different representations of the same task.
What carries the argument
The schema, defined as the LLM's knowledge activation and organization, which is shaped by the language representation consisting of linguistic and symbolic constructs that map the real world.
If this is right
- Deliberate design of language representations can yield substantial performance gains on complex problems without modifying model parameters or increasing scale.
- LLM internal feature activations change in response to the symbolic structure of the input language for an identical task.
- Future research should emphasize language representation design as a primary direction alongside or instead of scaling.
- The bottleneck of natural language's limited expressivity for problem-solving can be addressed through custom symbolic and structural enhancements.
Where Pith is reading between the lines
- One could explore whether automatically generated language representations optimized for schema shaping would outperform human-designed ones on specific domains.
- The approach may connect to how formal languages in mathematics enable more precise reasoning, suggesting similar benefits for LLMs in technical fields.
- If schema shaping proves robust, it could reduce reliance on massive training datasets by improving how existing knowledge is accessed and structured.
Load-bearing premise
Performance differences across language representations of the same task arise specifically from schema shaping rather than tokenization, attention patterns, or surface-level prompting effects.
What would settle it
Finding that different language representations of the same task lead to identical internal feature activations and task performance levels, after matching for token count and basic structure, would falsify the claim that representation shapes schema in a distinct and measurable way.
Figures



























read the original abstract
Although natural language is the default medium for Large Language Models (LLMs), its limited expressive capacity creates a profound bottleneck for complex problem-solving. While recent advancements in AI have relied heavily on scaling, merely internalizing knowledge does not guarantee its effective application. Defining language representation as the linguistic and symbolic constructs used to map and model the real world, this paper argues that shaping schemas through advanced language representation is the next frontier for expanding LLM intelligence. We posit that an LLM's knowledge activation and organization -- its schema -- depends heavily on the structural and symbolic sophistication of the language used to represent a given task. This paper contributes both a formalization of this claim and the empirical evidence to support it. With a new formalization, we present multiple lines of evidence to support our position: Firstly, we review recent empirical practices and emerging methodologies that demonstrate the substantial performance gains achievable through deliberate language representation design, even without modifying model parameters or scale. Secondly, we conduct controlled experiments showing that LLM performance and its internal feature activations vary under different language representations of the same underlying task. Together, these findings highlight language representation design as a promising direction for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that an LLM's schema—its knowledge activation and organization—depends on the structural and symbolic sophistication of the language representation used to encode tasks. It positions deliberate language representation design as the next frontier for LLM intelligence beyond scaling, supported by a new formalization, a review of empirical practices showing performance gains without parameter changes, and controlled experiments demonstrating that performance and internal feature activations vary across different language representations of the same underlying task.
Significance. If the central claim is substantiated with isolated evidence, the work could usefully redirect attention toward input representation engineering as a scalable complement to model scaling. The review of practices and the formalization provide a conceptual starting point that might stimulate targeted follow-up studies on representation effects.
major comments (2)
- [Abstract and Experiments] Abstract / controlled experiments description: the claim that performance and internal activations vary under different language representations is presented as direct support for schema shaping, yet no quantitative results, statistical tests, sample sizes, or controls for tokenization, sequence length, or attention-pattern changes are reported. Without these, the attribution to schema (rather than surface encoding differences) cannot be evaluated.
- [Formalization] Formalization: schema is defined as depending on the structural sophistication of the language representation, rendering the posited dependence largely definitional rather than independently testable. An operationalization of schema that is representation-independent would be required to support the causal claim.
minor comments (1)
- [Title] The title ends abruptly with 'Expanding' and would benefit from grammatical revision for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review of our manuscript. Their comments highlight important areas for clarification and strengthening, particularly regarding the presentation of experimental evidence and the formalization. We address each point below.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract / controlled experiments description: the claim that performance and internal activations vary under different language representations is presented as direct support for schema shaping, yet no quantitative results, statistical tests, sample sizes, or controls for tokenization, sequence length, or attention-pattern changes are reported. Without these, the attribution to schema (rather than surface encoding differences) cannot be evaluated.
Authors: We agree that the abstract, being a concise summary, does not include specific quantitative results or statistical details. The controlled experiments in the full manuscript demonstrate variations in performance and internal activations across language representations of the same task, but we acknowledge the need for more rigorous reporting. We will revise the abstract to summarize key quantitative findings and expand the experiments section to include sample sizes, statistical tests, and explicit controls for tokenization, sequence length, and attention patterns to better isolate schema effects from surface-level differences. revision: yes
-
Referee: [Formalization] Formalization: schema is defined as depending on the structural sophistication of the language representation, rendering the posited dependence largely definitional rather than independently testable. An operationalization of schema that is representation-independent would be required to support the causal claim.
Authors: The formalization is intended to provide a structured way to analyze how language representations influence schema activation, building on established cognitive concepts. While it links the two, the causal claim is supported by the empirical component where we hold the underlying task constant and vary only the representation, observing differences in outcomes and activations. This provides a test independent of the definition. That said, we appreciate the suggestion for a more explicit representation-independent operationalization of schema and will add a subsection discussing potential measures, such as using probing techniques or activation similarity metrics that can be applied uniformly across different representations. revision: partial
Circularity Check
No significant circularity; central claim supported by independent empirical review and experiments
full rationale
The paper posits a dependence between schema (defined as knowledge activation and organization) and language representation sophistication, then supports the position via two external lines of evidence: a review of recent empirical practices showing performance gains from representation design without parameter changes, and controlled experiments documenting variations in performance and feature activations for the same task under different representations. No equations, formalization steps, or predictions are shown to reduce by construction to the initial definition or inputs. No self-citations are invoked as load-bearing uniqueness theorems, and no fitted parameters are relabeled as predictions. The derivation chain remains self-contained against the provided evidence sources.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural language has limited expressive capacity that creates a bottleneck for complex problem-solving in LLMs
- ad hoc to paper LLM knowledge activation and organization (schema) is determined by the structural sophistication of the input language representation
invented entities (1)
-
schema
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe posit that an LLM's knowledge activation and organization -- its schema -- depends heavily on the structural and symbolic sophistication of the language used to represent a given task. ... SM(L) ≜ D_KL(s^L_f || s^L_π)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearProposition 3.6 (Bounds on prediction error) ... σ²_min/2 SM(L) ≤ d(f, f̂_L) ≤ σ²_max/2 SM(L)
Reference graph
Works this paper leans on
-
[1]
Tractatus logico-philosophicus
Ludwig Wittgenstein. Tractatus logico-philosophicus. 1922
work page 1922
-
[2]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877– 1901, 2020
work page 1901
-
[4]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Emergent abilities of large language models.Transactions on Machine Learning Research, 2022
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022
work page 2022
-
[8]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems, pages 30016–30030, 2022
work page 2022
-
[9]
Fabio Petroni, Tim Rockt¨aschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. Language models as knowledge bases? InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2463–2473, 2019
work page 2019
-
[10]
Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5418–5426, 2020
work page 2020
-
[11]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[12]
Neuroscience-inspired artificial intelligence.Neuron, 95(2):245–258, 2017
Demis Hassabis, Dharshan Kumaran, Christopher Summerfield, and Matthew Botvinick. Neuroscience-inspired artificial intelligence.Neuron, 95(2):245–258, 2017
work page 2017
-
[13]
When brain-inspired ai meets agi.Meta-Radiology, 1(1):100005, 2023
Lin Zhao, Lu Zhang, Zihao Wu, Yuzhong Chen, Haixing Dai, Xiaowei Yu, Zhengliang Liu, Tuo Zhang, Xintao Hu, Xi Jiang, et al. When brain-inspired ai meets agi.Meta-Radiology, 1(1):100005, 2023
work page 2023
-
[14]
Debates on the nature of artificial general intelligence, 2024
Melanie Mitchell. Debates on the nature of artificial general intelligence, 2024
work page 2024
-
[15]
Remembering: A study in experimental and social psychology
Frederic C Bartlett. Remembering: A study in experimental and social psychology. 1932
work page 1932
-
[16]
Thinking: An experimental and social study
Frederic Charles Bartlett. Thinking: An experimental and social study. 1958
work page 1958
-
[17]
Gail E Tompkins and Lea M McGee.Teaching reading with literature: Case studies to action plans. Prentice Hall, 1993
work page 1993
-
[18]
Yohan J. John. The power of scale in machine learning. https://kempnerinstitute. harvard.edu/news/the-power-of-scale-in-machine-learning/ , Aug 2025. Kemp- ner Institute at Harvard University. 10
work page 2025
-
[19]
Ilya sutskever: We’re moving from the age of scaling to the age of research
Ilya Sutskever and Dwarkesh Patel. Ilya sutskever: We’re moving from the age of scaling to the age of research. The Dwarkesh Podcast, nov 2025. Published on November 25, 2025
work page 2025
-
[20]
Muhammad Ahmed Mohsin, Muhammad Umer, Ahsan Bilal, Zeeshan Memon, Muham- mad Ibtsaam Qadir, Sagnik Bhattacharya, Hassan Rizwan, Abhiram R Gorle, Maahe Zehra Kazmi, Ayesha Mohsin, et al. On the fundamental limits of llms at scale.arXiv preprint arXiv:2511.12869, 2025
-
[21]
Soroush Mirjalili and Audrey Duarte. Using machine learning to simultaneously quantify multiple cognitive components of episodic memory.Nature Communications, 16(1):2856, 2025
work page 2025
-
[22]
Prefrontal connectomics: from anatomy to human imaging.Neuropsychopharmacology, 47(1):20–40, 2022
Suzanne N Haber, Hesheng Liu, Jakob Seidlitz, and Ed Bullmore. Prefrontal connectomics: from anatomy to human imaging.Neuropsychopharmacology, 47(1):20–40, 2022
work page 2022
-
[23]
Schemata: The building blocks of cognition
David E Rumelhart. Schemata: The building blocks of cognition. InTheoretical issues in reading comprehension, pages 33–58. Routledge, 2017
work page 2017
-
[24]
Schema for in-context learning.arXiv preprint arXiv:2510.13905, 2025
Pan Chen, Shaohong Chen, Mark Wang, Shi Xuan Leong, Priscilla Fung, Varinia Bernales, and Alan Aspuru-Guzik. Schema for in-context learning.arXiv preprint arXiv:2510.13905, 2025
-
[25]
Tricia Smith. Schema theory. https://www.ebsco.com/research-starters/ psychology/schema-theory, 2021
work page 2021
-
[26]
Mohsen Jamali, Benjamin Grannan, Jing Cai, Arjun R Khanna, William Mu˜noz, Irene Caprara, Angelique C Paulk, Sydney S Cash, Evelina Fedorenko, and Ziv M Williams. Semantic encoding during language comprehension at single-cell resolution.Nature, 631(8021):610– 616, 2024
work page 2024
-
[27]
Language, thought, and reality: selected writings of
Benjamin Lee Whorf. Language, thought, and reality: selected writings of. . . .(edited by john b. carroll.). 1956
work page 1956
-
[28]
Linguistic relativity.Annual review of anthropology, 26(1):291–312, 1997
John A Lucy. Linguistic relativity.Annual review of anthropology, 26(1):291–312, 1997
work page 1997
-
[29]
Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nisnevich, et al. Experience grounds language. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8718–8735, 2020
work page 2020
-
[30]
Ulrich Ansorge, Diane Baier, and Soonja Choi. Linguistic skill and stimulus-driven attention: A case for linguistic relativity.Frontiers in Psychology, 13:875744, 2022
work page 2022
-
[31]
Meaning without reference in large language models
Steven Piantadosi and Felix Hill. Meaning without reference in large language models. In NeurIPS 2022 Workshop on Neuro Causal and Symbolic AI (nCSI), 2022
work page 2022
-
[32]
Derek Edwards and Jonathan Potter. Language and causation: A discursive action model of description and attribution.Psychological review, 100(1):23, 1993
work page 1993
-
[33]
English and spanish speakers remember causal agents differently
Caitlin M Fausey and Lera Boroditsky. English and spanish speakers remember causal agents differently. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 30, 2008
work page 2008
-
[34]
Leonard Talmy.Toward a cognitive semantics: Concept structuring systems, volume 1. MIT Press, 2000
work page 2000
-
[35]
Lera Boroditsky. Does language shape thought?: Mandarin and english speakers’ conceptions of time.Cognitive psychology, 43(1):1–22, 2001
work page 2001
-
[36]
Wilhelm von Humboldt.From ‘thought and language’ to ‘thinking for speaking’.Cambridge University Press, 1996
work page 1996
-
[37]
How language shapes thought.Scientific American, 304(2):62–65, 2011
Lera Boroditsky. How language shapes thought.Scientific American, 304(2):62–65, 2011. 11
work page 2011
-
[38]
Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
work page 2017
-
[39]
Marcel Binz and Eric Schulz. Using cognitive psychology to understand gpt-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
work page 2023
-
[40]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, et al. Circuit tracing: Revealing computational graphs in language models.Transformer Circuits Thread, 6, 2025
work page 2025
-
[41]
Semantic structure in large language model embeddings.arXiv preprint arXiv:2508.10003,
Austin C Kozlowski, Callin Dai, and Andrei Boutyline. Semantic structure in large language model embeddings.arXiv preprint arXiv:2508.10003, 2025
-
[42]
Under the shadow of babel: How language shapes reasoning in llms
Chenxi Wang, Yixuan Zhang, Lang Gao, Zixiang Xu, Zirui Song, Yanbo Wang, and Xiuying Chen. Under the shadow of babel: How language shapes reasoning in llms. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 24327–24344, 2025
work page 2025
-
[43]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
work page 2024
-
[44]
Safoora Yousefi, Leo Betthauser, Hosein Hasanbeig, Rapha¨el Milli`ere, and Ida Momennejad. Decoding in-context learning: Neuroscience-inspired analysis of representations in large language models.arXiv preprint arXiv:2310.00313, 2023
-
[45]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[46]
Towards understanding chain-of-thought prompting: An empirical study of what matters
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. Towards understanding chain-of-thought prompting: An empirical study of what matters. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 2717–2739, 2023
work page 2023
-
[47]
Schema and natural language aware in-context learning for improved graphql query generation
Nitin Gupta, Manish Kesarwani, Sambit Ghosh, Sameep Mehta, Carlos Eberhardt, and Dan Debrunner. Schema and natural language aware in-context learning for improved graphql query generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Ind...
work page 2025
-
[48]
Infusing prompts with syntax and semantics
Anton Bulle Labate and Fabio Gagliardi Cozman. Infusing prompts with syntax and semantics. arXiv preprint arXiv:2412.06107, 2024
-
[49]
Sivaramakrishnan Swaminathan, Antoine Dedieu, Rajkumar Vasudeva Raju, Murray Shanahan, Miguel Lazaro-Gredilla, and Dileep George. Schema-learning and rebinding as mechanisms of in-context learning and emergence.Advances in neural information processing systems, 36:28785–28804, 2023
work page 2023
-
[50]
Improving rule-based reasoning in LLMs using neurosym- bolic representations
Varun Dhanraj and Chris Eliasmith. Improving rule-based reasoning in LLMs using neurosym- bolic representations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30577–30596, 2025
work page 2025
-
[51]
Bowen Cao, Deng Cai, Zhisong Zhang, Yuexian Zou, and Wai Lam. On the worst prompt performance of large language models.Advances in Neural Information Processing Systems, 37:69022–69042, 2024
work page 2024
-
[52]
Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, et al. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts. InProceedings of the 1st ACM workshop on large AI systems and models with privacy and safety analysis, pages 57–68, 2023
work page 2023
-
[53]
The communicative function of ambiguity in language.Cognition, 122(3):280–291, 2012
Steven T Piantadosi, Harry Tily, and Edward Gibson. The communicative function of ambiguity in language.Cognition, 122(3):280–291, 2012. 12
work page 2012
-
[54]
Climbing towards nlu: On meaning, form, and understanding in the age of data
Emily M Bender and Alexander Koller. Climbing towards nlu: On meaning, form, and understanding in the age of data. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 5185–5198, 2020
work page 2020
-
[55]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Prompt programming for large language models: Beyond the few-shot paradigm
Laria Reynolds and Kyle McDonell. Prompt programming for large language models: Beyond the few-shot paradigm. InExtended abstracts of the 2021 CHI conference on human factors in computing systems, pages 1–7, 2021
work page 2021
-
[57]
Bailin Wang, Zi Wang, Xuezhi Wang, Yuan Cao, Rif A Saurous, and Yoon Kim. Grammar prompting for domain-specific language generation with large language models.Advances in Neural Information Processing Systems, 36:65030–65055, 2023
work page 2023
-
[58]
Constrained language models yield few-shot semantic parsers
Richard Shin, Christopher Lin, Sam Thomson, Charles Chen Jr, Subhro Roy, Emmanouil Anto- nios Platanios, Adam Pauls, Dan Klein, Jason Eisner, and Benjamin Van Durme. Constrained language models yield few-shot semantic parsers. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7699–7715, 2021
work page 2021
-
[59]
Grammar-aligned decoding.Advances in Neural Information Processing Systems, 37:24547– 24568, 2024
Kanghee Park, Jiayu Wang, Taylor Berg-Kirkpatrick, Nadia Polikarpova, and Loris D’Antoni. Grammar-aligned decoding.Advances in Neural Information Processing Systems, 37:24547– 24568, 2024
work page 2024
-
[60]
Anjiang Wei, Allen Nie, Thiago SFX Teixeira, Rohan Yadav, Wonchan Lee, Ke Wang, and Alex Aiken. Improving parallel program performance through dsl-driven code generation with llm optimizers.arXiv e-prints, pages arXiv–2410, 2024
work page 2024
-
[61]
Making pre-trained language models better few- shot learners
Tianyu Gao, Adam Fisch, and Danqi Chen. Making pre-trained language models better few- shot learners. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 3816–3830, 2021
work page 2021
-
[62]
True few-shot learning with language models
Ethan Perez, Douwe Kiela, and Kyunghyun Cho. True few-shot learning with language models. Advances in neural information processing systems, 34:11054–11070, 2021
work page 2021
-
[63]
Stress test evaluation for natural language inference.arXiv preprint arXiv:1806.00692, 2018
Aakanksha Naik, Abhilasha Ravichander, Norman Sadeh, Carolyn Rose, and Graham Neubig. Stress test evaluation for natural language inference.arXiv preprint arXiv:1806.00692, 2018
-
[64]
Abel Salinas and Fred Morstatter. The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance.arXiv preprint arXiv:2401.03729, 2024
-
[65]
Yichi Zhou, Jianqiu Zhao, Yongxin Zhang, Bohan Wang, Siran Wang, Luoxin Chen, Jiahui Wang, Haowei Chen, Allan Jie, Xinbo Zhang, et al. Solving formal math problems by decomposition and iterative reflection.arXiv preprint arXiv:2507.15225, 2025
-
[66]
Saibo Geng, Hudson Cooper, Michał Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, and Harsha Nori. Generating structured outputs from language models: Benchmark and studies.arXiv e-prints, pages arXiv–2501, 2025
work page 2025
-
[67]
Thiago Barradas, Aline Paes, and Vˆania de Oliveira Neves. Combining tsl and llm to automate rest api testing: A comparative study.arXiv preprint arXiv:2509.05540, 2025
-
[68]
Hyungjoo Chae, Yeonghyeon Kim, Seungone Kim, Kai Tzu-iunn Ong, Beong-woo Kwak, Moohyeon Kim, Sunghwan Mac Kim, Taeyoon Kwon, Jiwan Chung, Youngjae Yu, et al. Language models as compilers: Simulating pseudocode execution improves algorithmic reasoning in language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processi...
work page 2024
-
[69]
Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning
Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 3806–3824, 2023. 13
work page 2023
-
[70]
Vipergpt: Visual inference via python execution for reasoning
D´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023
work page 2023
-
[71]
Weijian Ma, Shizhao Sun, Tianyu Yu, Ruiyu Wang, Tat-Seng Chua, and Jiang Bian. Thinking with blueprints: Assisting vision-language models in spatial reasoning via structured object representation.arXiv preprint arXiv:2601.01984, 2026
-
[72]
Thinking Without Words: Efficient Latent Reasoning with Abstract Chain-of-Thought
Keshav Ramji, Tahira Naseem, and Ram´on Fernandez Astudillo. Thinking without words: Efficient latent reasoning with abstract chain-of-thought.arXiv preprint arXiv:2604.22709, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
The language instinct (1994/2007)
Steven Pinker. The language instinct (1994/2007). 2007
work page 1994
-
[74]
AgentSPEX: An Agent SPecification and EXecution Language
Pengcheng Wang, Jerry Huang, Jiarui Yao, Rui Pan, Peizhi Niu, Yaowenqi Liu, Ruida Wang, Renhao Lu, Yuwei Guo, and Tong Zhang. Agentspex: An agent specification and execution language.arXiv preprint arXiv:2604.13346, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[75]
Jiajie Zou, David Poeppel, and Nai Ding. Constituent-constrained word prediction during language comprehension.Nature Neuroscience, pages 1–12, 2026
work page 2026
-
[76]
Faithful logical reasoning via symbolic chain-of-thought.arXiv preprint arXiv:2405.18357, 2024
Jundong Xu, Hao Fei, Liangming Pan, Qian Liu, Mong-Li Lee, and Wynne Hsu. Faithful logical reasoning via symbolic chain-of-thought.arXiv preprint arXiv:2405.18357, 2024
-
[77]
Geometrically-constrained agent for spatial reasoning.arXiv preprint arXiv:2511.22659, 2025
Zeren Chen, Xiaoya Lu, Zhijie Zheng, Pengrui Li, Lehan He, Yijin Zhou, Jing Shao, Bohan Zhuang, and Lu Sheng. Geometrically-constrained agent for spatial reasoning.arXiv preprint arXiv:2511.22659, 2025
-
[78]
Malik Ghallab, Dana Nau, and Paolo Traverso.Automated Planning: theory and practice. Elsevier, 2004
work page 2004
-
[79]
Llm+ al: Bridging large language models and action languages for complex reasoning about actions
Adam Ishay and Joohyung Lee. Llm+ al: Bridging large language models and action languages for complex reasoning about actions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24212–24220, 2025
work page 2025
-
[80]
Pavel Smirnov, Frank Joublin, Antonello Ceravola, and Michael Gienger. Generating consistent pddl domains with large language models.arXiv preprint arXiv:2404.07751, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.