Recognition: 2 theorem links
· Lean TheoremNeural Cluster First, Route Second: One-Shot Capacitated Vehicle Routing via Differentiable Optimal Transport
Pith reviewed 2026-05-12 03:28 UTC · model grok-4.3
The pith
A non-autoregressive neural solver for capacitated vehicle routing assigns customers to vehicles first via optimal transport then routes within clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
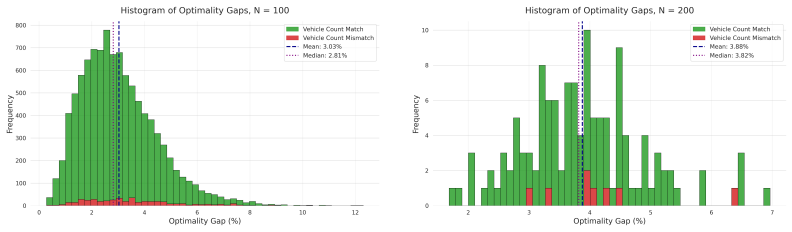
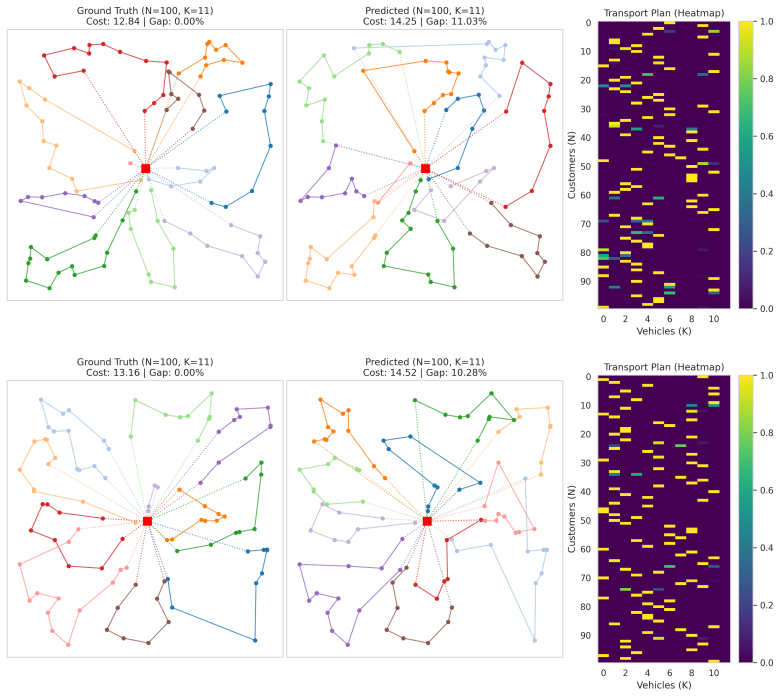
Neural CFRS is the first purely non-autoregressive one-shot neural framework for CVRP that enforces global fleet-capacity constraints end-to-end via a differentiable entropic optimal transport layer, produces a continuous transport plan that is sparsified by an exact capacitated assignment solver, and carries formal guarantees that it abstracts away E(2) spatial symmetries, inter-route permutation symmetries, and intra-route traversal symmetries; equipped with a pre-trained spatial vocabulary it achieves a 2.73 percent optimality gap on size-100 benchmarks and scales to out-of-distribution instances of size 1000 with a gap below 4 percent.
What carries the argument
The differentiable entropic optimal transport layer that produces a continuous customer-to-vehicle transport plan respecting total capacity before an exact solver sparsifies it into a discrete assignment.
If this is right
- The method produces solutions for 1000-customer problems with an optimality gap below 4 percent even when the model is trained only on smaller instances.
- A single-layer version of the architecture retains an approximate 5 percent gap at the 1000-customer scale.
- The architecture is invariant to E(2) spatial transformations, to the ordering of routes, and to the ordering of stops inside routes.
- Deployment on standard benchmarks yields a 2.73 percent optimality gap on 100-customer instances without task-specific fine-tuning.
Where Pith is reading between the lines
- The non-autoregressive design may allow parallel inference across multiple problem instances on the same hardware, reducing wall-clock time in high-volume routing services.
- The separation of assignment and routing stages could be reused as a template for other vehicle-routing variants that admit a natural clustering decomposition.
- Because the spatial vocabulary is pre-trained, the same backbone might transfer to related assignment problems such as multi-depot routing or pickup-and-delivery without retraining the entire network.
Load-bearing premise
The approach assumes real-world spatial customer distributions and a fixed vehicle capacity together with a pre-trained spatial vocabulary that enables zero-shot scaling.
What would settle it
Running the method on 1000-customer instances drawn from a qualitatively different spatial distribution, such as highly clustered or grid-like layouts, and measuring whether the optimality gap remains under 4 percent would directly test the scaling claim.
Figures







read the original abstract
The Capacitated Vehicle Routing Problem (CVRP) underpins modern last-mile logistics. Current Neural Combinatorial Optimization (NCO) methods construct CVRP solutions autoregressively, inheriting sequential decoding bottlenecks, sensitivity to spatial symmetries, and brittle out-of-distribution behavior. We revisit the classical Cluster-First-Route-Second (CFRS) paradigm -- long known to be asymptotically optimal but largely overlooked by NCO -- and argue that it is structurally aligned with the core strengths of deep learning: similarity and assignment over global context, rather than the construction of long sequential tours. We introduce Neural CFRS, the first purely non-autoregressive one-shot neural CFRS framework for the CVRP. It enforces global fleet-capacity constraints end-to-end via a differentiable entropic Optimal Transport layer, producing a continuous transport plan to sparsify an exact capacitated assignment solver. We provide formal theoretical guarantees that our architecture intrinsically abstracts away $E(2)$ spatial, inter-route permutation, and intra-route traversal symmetries. By equipping the framework with a pre-trained spatial vocabulary, we unlock extreme parameter efficiency and zero-shot scaling. Designed primarily for real-world spatial distributions under a constant capacity setting, Neural CFRS scales robustly to out-of-distribution $N=1000$ instances with a < 4% gap -- retaining an approximate 5% gap at this scale even as an ultra-lightweight, single-layer architecture. Furthermore, when deployed out-of-the-box on standard benchmarks, we achieve a highly competitive 2.73% optimality gap on size-100 problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural CFRS, the first purely non-autoregressive one-shot neural framework for the Capacitated Vehicle Routing Problem (CVRP) that revives the classical Cluster-First-Route-Second paradigm. It uses a differentiable entropic Optimal Transport layer to enforce global fleet-capacity constraints end-to-end, produces a continuous transport plan for an exact capacitated assignment solver, and claims formal theoretical guarantees that the architecture abstracts away E(2) spatial symmetries, inter-route permutation symmetries, and intra-route traversal symmetries. Equipped with a pre-trained spatial vocabulary, the method achieves parameter efficiency and zero-shot scaling, reporting a 2.73% optimality gap on size-100 problems and robust scaling to out-of-distribution N=1000 instances with a <4% gap (approximately 5% even for a single-layer variant).
Significance. If the theoretical symmetry guarantees and empirical scaling results hold with proper verification, this work could meaningfully advance neural combinatorial optimization by shifting from autoregressive construction to a differentiable clustering-assignment approach that aligns with deep learning strengths in similarity and assignment. The parameter-efficient zero-shot scaling and explicit handling of symmetries would represent a notable strength over existing NCO methods for routing problems.
major comments (1)
- [Abstract] Abstract: the central scaling claim of robust zero-shot performance to N=1000 instances with a <4% optimality gap (and ~5% for the single-layer variant) is load-bearing for the headline contribution, but true global optima are intractable at this scale; the manuscript must explicitly specify in the experimental evaluation how the gap is computed (e.g., against which heuristic solver such as LKH, lower bound, or best-known solution) and confirm methodological consistency with the size-100 benchmark to substantiate the generalization result.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on our manuscript. We address the single major comment below and will incorporate the requested clarifications in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central scaling claim of robust zero-shot performance to N=1000 instances with a <4% optimality gap (and ~5% for the single-layer variant) is load-bearing for the headline contribution, but true global optima are intractable at this scale; the manuscript must explicitly specify in the experimental evaluation how the gap is computed (e.g., against which heuristic solver such as LKH, lower bound, or best-known solution) and confirm methodological consistency with the size-100 benchmark to substantiate the generalization result.
Authors: We agree that explicit specification of the reference used for optimality-gap computation at large scales is necessary for transparency and to substantiate the zero-shot scaling claims. The revised manuscript will add a clear statement in the experimental evaluation section (and a brief parenthetical note in the abstract) detailing the exact baseline employed for N=1000 instances. We will also explicitly confirm that the identical reference is used for the size-100 benchmark, thereby ensuring methodological consistency across all reported results. This clarification strengthens the presentation without altering any numerical claims or experimental outcomes. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core claims rest on a non-autoregressive CFRS architecture using differentiable entropic OT for capacity constraints, symmetry abstractions via architecture design, and empirical scaling results on benchmarks. These are presented as building on established OT and clustering methods without any quoted reduction of a central result (e.g., a 'prediction' or 'guarantee') to a fitted parameter or self-citation by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described framework. The <4% gap on N=1000 is an empirical performance metric against heuristics (as noted by the skeptic), not a derived quantity forced by the model's own inputs. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- pre-trained spatial vocabulary
axioms (1)
- domain assumption The architecture intrinsically abstracts away E(2) spatial, inter-route permutation, and intra-route traversal symmetries
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleardifferentiable entropic Optimal Transport layer... min Π Δij Πij + ϵ H(Π) subject to marginals
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearformal theoretical guarantees that our architecture intrinsically abstracts away E(2) spatial, inter-route permutation, and intra-route traversal symmetries
Reference graph
Works this paper leans on
-
[1]
B. Athiwaratkun, M. Finzi, P. Izmailov, and A. G. Wilson. There are many consistent ex- planations of unlabeled data: Why you should average.arXiv preprint arXiv:1806.05594, 2018
- [2]
-
[3]
D. Bienstock, J. Bramel, and D. Simchi-Levi. A Probabilistic Analysis of Tour Partitioning Heuristics for the Capacitated Vehicle Routing Problem with Unsplit Demands.Mathematics of Operations Research, 18(4):786–802, 11 1993. ISSN 0364-765X. doi: 10.1287/moor.18.4.786
-
[4]
J. Bramel and D. Simchi-Levi. A location based heuristic for general routing problems.Opera- tions research, 43(4):649–660, 1995
work page 1995
-
[5]
J. Christiaens and G. V . Berghe. Slack induction by string removals for vehicle routing problems. Transportation Science, 54(2):417–433, 2020. ISSN 15265447. doi: 10.1287/trsc.2019.0914
-
[6]
M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
work page 2013
-
[7]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In J. Burstein, C. Doran, and T. Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Paper...
-
[8]
D. Drakulic, S. Michel, F. Mai, A. Sors, and J.-M. Andreoli. BQ-NCO: Bisimula- tion Quotienting for Efficient Neural Combinatorial Optimization. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 77416–77429. Curran Associates, Inc., 2023. URL https://proc...
work page 2023
-
[9]
J. K. Falkner and L. Schmidt-Thieme. Neural Capacitated Clustering. 2 2023
work page 2023
- [10]
-
[11]
M. L. Fisher and R. Jaikumar. A generalized assignment heuristic for vehicle routing.Networks, 11(2):109–124, 1981
work page 1981
-
[12]
B. A. Foster and D. M. Ryan. An Integer Programming Approach to the Vehicle Scheduling Problem.Operational Research Quarterly (1970-1977), 27(2):367, 1976. ISSN 00303623. doi: 10.2307/3009018
- [13]
-
[14]
B. E. Gillett and L. R. Miller. A heuristic algorithm for the vehicle-dispatch problem.Operations research, 22(2):340–349, 1974
work page 1974
-
[15]
Gurobi Optimizer Reference Manual, 2026
Gurobi Optimization LLC. Gurobi Optimizer Reference Manual, 2026. URL https://www. gurobi.com
work page 2026
- [16]
-
[17]
Q. Hou, J. Yang, Y . Su, X. Wang, and Y . Deng. Generalize Learned Heuristics to Solve Large- scale Vehicle Routing Problems in Real-time. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=6ZajpxqTlQ. 10
work page 2023
-
[18]
N. Iyer, V . Thejas, N. Kwatra, R. Ramjee, and M. Sivathanu. Wide-minima density hypothesis and the explore-exploit learning rate schedule.Journal of Machine Learning Research, 24(65): 1–37, 2023
work page 2023
-
[19]
C. K. Joshi, T. Laurent, and X. Bresson. An Efficient Graph Convolutional Network Technique for the Travelling Salesman Problem. 6 2019
work page 2019
- [20]
-
[21]
M. Kim, J. Park, and J. Park. Sym-NCO: Leveraging Symmetricity for Neural Combinatorial Optimization. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 1936–1949. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/ 2022/file/0c...
work page 1936
-
[22]
W. Kool, H. van Hoof, and M. Welling. Attention, Learn to Solve Routing Problems! In International Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=ByxBFsRqYm
work page 2019
-
[23]
W. Kool, H. van Hoof, J. Gromicho, and M. Welling. Deep Policy Dynamic Programming for Vehicle Routing Problems. pages 190–213. 2022. doi: 10.1007/978-3-031-08011-1{\_}14
-
[24]
Y .-D. Kwon, J. Choo, B. Kim, I. Yoon, Y . Gwon, and S. Min. Pomo: Policy optimization with multiple optima for reinforcement learning.Advances in Neural Information Processing Systems, 33:21188–21198, 2020
work page 2020
-
[25]
I. Loshchilov and F. Hutter. Fixing Weight Decay Regularization in Adam, 2018. URL https://openreview.net/forum?id=rk6qdGgCZ
work page 2018
-
[26]
F. Luo, X. Lin, F. Liu, Q. Zhang, and Z. Wang. Neural combinatorial optimization with heavy decoder: Toward large scale generalization.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[27]
Y . Min, Y . Bai, and C. P. Gomes. Unsupervised learning for solving the travelling salesman problem.Advances in neural information processing systems, 36:47264–47278, 2023
work page 2023
- [28]
-
[29]
A. A. Pessoa, M. Poss, R. Sadykov, and F. Vanderbeck. Branch-Cut-and-Price for the Robust Capacitated Vehicle Routing Problem with Knapsack Uncertainty.Operations Research, 69(3): 739–754, 5 2021. ISSN 0030-364X. doi: 10.1287/opre.2020.2035
-
[30]
R. Qiu, Z. Sun, and Y . Yang. DIMES: A Differentiable Meta Solver for Combinatorial Opti- mization Problems. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id= 9u05zr0nhx
work page 2022
- [31]
-
[32]
J. Renaud, F. F. Boctor, and G. Laporte. An Improved Petal Heuristic for the Vehicle Routeing Problem.The Journal of the Operational Research Society, 47(2):329, 2 1996. ISSN 01605682. doi: 10.2307/2584352
-
[33]
J. M. P. Silva, E. Uchoa, and A. Subramanian. Cluster branching for vehicle routing problems. INFORMS Journal on Computing, 2025
work page 2025
- [34]
-
[35]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[36]
T. Vidal. Hybrid genetic search for the CVRP: Open-source implementation and SWAP* neighborhood.Computers & Operations Research, 140:105643, 4 2022. ISSN 03050548. doi: 10.1016/j.cor.2021.105643
-
[37]
O. Vinyals, M. Fortunato, and N. Jaitly. Pointer Networks. InAdvances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://papers.nips. cc/paper/2015/hash/29921001f2f04bd3baee84a12e98098f-Abstract.html
-
[38]
N. A. Wouda, L. Lan, and W. Kool. PyVRP: A High-Performance VRP Solver Package. INFORMS Journal on Computing, 36(4):943–955, 7 2024. ISSN 1091-9856. doi: 10.1287/ijoc. 2023.0055
-
[39]
H. Ye, J. Wang, Z. Cao, H. Liang, and Y . Li. DeepACO: neural-enhanced ant systems for combinatorial optimization.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[40]
H. Ye, J. Wang, H. Liang, Z. Cao, Y . Li, and F. Li. Glop: Learning global partition and local construction for solving large-scale routing problems in real-time. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 20284–20292, 2024. 12 A Problem Setting In this appendix we state the CVRP setting used throughout the paper in ...
work page 2024
-
[41]
Seed Generation: hseed(Ψ, d)7→C∈R K×d model, extracting K dynamic seed represen- tations
-
[42]
Global Assignment: hassign(Ψ, d, C)7→(∆, bY) , where the Clustering Transformer (CT) and entropic Optimal Transport (OT) layer output a latent distance matrix ∆∈R N×K and a continuous transport planbY∈[0,1] N×K
-
[43]
OR Decoding: hCAP(∆,bY , d, Q)7→ Y , where the MIP solver enforces uniform fleet capacityQto recover the discrete boolean assignment matrix Y∈ {0,1} N×K
-
[44]
TSP Recovery: hTSP(Y , Xcoord)7→ T , mapping each column of Y to an independent TSP tour over the corresponding customer subset, computed under Euclidean distances derived fromX coord. The full pipeline is the composition C=h seed(Ψ, d), (∆,bY) =h assign(Ψ, d, C), Y=h CAP(∆,bY , d, Q), T=h TSP(Y , Xcoord).(7) We pass Xcoord explicitly to hTSP to make the ...
-
[45]
Phase 1 and 2.Both ST and CT are standard Transformer encoders, with 8 heads and 6 layers, a hidden dimension of 128 (feedforward 512),k attn = 20, dropout= 0.1.L con has a scalar weight of0.05, and all the other losses are not weighted
-
[46]
Phase 2.The OT layer is configured with ϵ= 0.01 and with a maximum iteration of
-
[47]
The full loss used is Ltotal = Lseed + 0.05× L con + LBCE +L OT
We use ϵ= 0.001 and with a maximum iteration of 1000 for inference but found that this did not have a significant impact on performance. The full loss used is Ltotal = Lseed + 0.05× L con + LBCE +L OT
-
[48]
Phase 3.For the OR solver, we use Gurobi version 12.0.3 [15], parallelized across 16 CPU cores per batch. To ensure standardized evaluation across all decoding variants, Gurobi is configured with a strict time limit of 100s and a target MIPGap of 0.001. Furthermore, we define the confidence threshold for hard assignment decoding as τhigh = 0.99 , and the ...
-
[49]
Weight Saving Strategy.Utilizing the built-in PyTorch [ 28] framework for Stochastic Weight Averaging [1], we initiate the weight averaging process at the midpoint of training (the50%epoch) and systematically save the model states at each subsequent epoch. 19 Note on Measuring Inference TimeTo properly contextualize the computational metrics reported thro...
-
[50]
on the LEHD [26] benchmark datasets. We found that maintaining the 10% nearest-neighbor sparsity ratio during inference (e.g., dynamically setting K_SPARSE= 50 for N= 500 and 100 for N= 1000 ) yielded the strongest overall generalization performance for GLOP across all evaluated scales. Table 3 shows that GLOP has poor performance on small problem sizes. ...
work page 2074
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.