Recognition: no theorem link
Attention Sinks in Diffusion Transformers: A Causal Analysis
Pith reviewed 2026-05-13 05:55 UTC · model grok-4.3
The pith
Attention sinks in diffusion transformers can be removed without degrading text-image alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
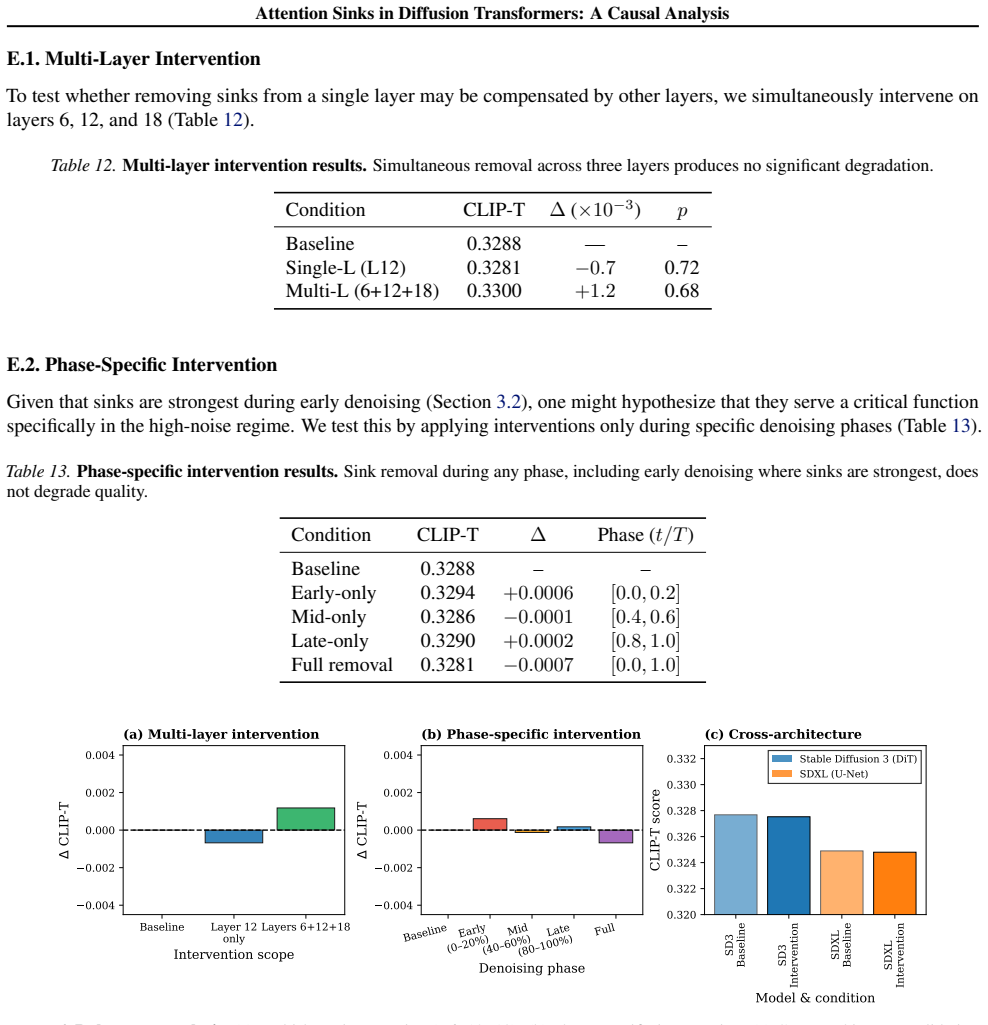
Dynamically identifying and suppressing attention sinks per timestep in diffusion transformers via paired interventions on the score and value paths does not degrade text-image alignment measured by CLIP-T or preference proxies at k=1, with only HPS-v2 showing a boundary at k greater than or equal to 10, while the induced perceptual shifts are approximately six times larger than equal-budget random masking, indicating a dissociation between trajectory perturbation and semantic alignment.
What carries the argument
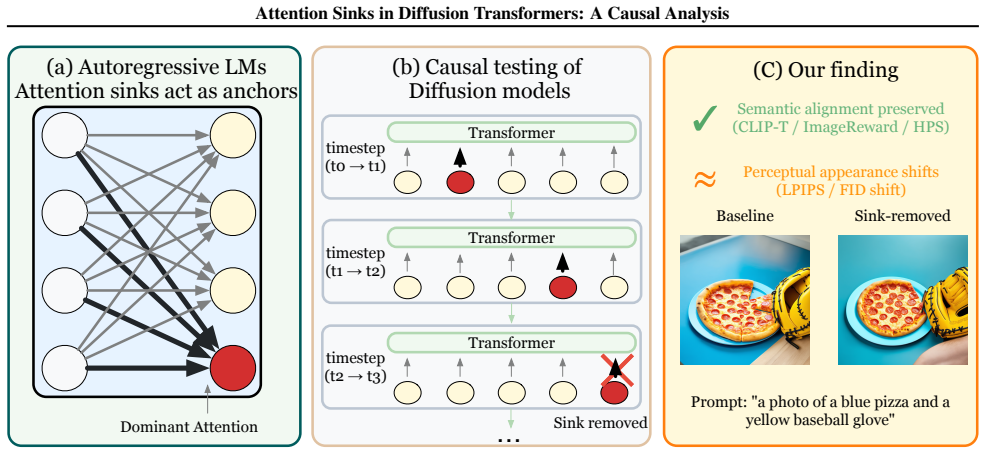
Dynamically identifying dominant attention recipients per timestep and suppressing them via paired training-free interventions on the attention score and value paths.
Load-bearing premise
The interventions isolate the effect of attention sinks without causing other unintended changes in the diffusion trajectory, and the chosen metrics reflect semantic alignment separately from perceptual style.
What would settle it
If suppressing the single top attention sink at each timestep on the 553 GenEval prompts caused a clear drop in CLIP-T scores or consistent degradation in ImageReward, that would contradict the claim that sinks are dispensable for alignment.
Figures






read the original abstract
Attention sinks -- tokens that receive disproportionate attention mass -- are assumed to be functionally important in autoregressive language models, but their role in diffusion transformers remains unclear. We present a causal analysis in text-to-image diffusion, dynamically identifying dominant attention recipients per timestep and suppressing them via paired, training-free interventions on the score and value paths. Across 553 GenEval prompts on Stable Diffusion~3 (with SDXL corroboration), removing these sinks does not degrade text-image alignment (CLIP-T) or preference proxies (ImageReward, HPS-v2) at $k{=}1$; only under stronger interventions ($k\!\geq\!10$) does HPS-v2 exhibit a metric-dependent boundary, while CLIP-T remains robust throughout. The perceptual shifts induced by suppression are nonetheless \emph{sink-specific} -- $\sim\!6\times$ larger than equal-budget random masking -- revealing an empirical dissociation between trajectory-level perturbation and \emph{semantic alignment} in diffusion transformers. \footnote{Code available at https://github.com/wfz666/ICML26-attention-sink.}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that attention sinks in diffusion transformers for text-to-image models can be causally analyzed by dynamically identifying high-attention tokens and suppressing them through training-free paired interventions on the score and value paths. Using 553 GenEval prompts on Stable Diffusion 3 (with SDXL validation), the authors show that mild suppression (k=1) leaves CLIP-T, ImageReward, and HPS-v2 scores intact, while stronger suppression (k≥10) causes HPS-v2 to degrade in a metric-dependent manner. Perceptual changes from sink suppression are approximately 6 times larger than those from equivalent random masking, suggesting that sinks primarily affect low-level perceptual features rather than semantic alignment.
Significance. This work offers valuable empirical insights into the role of attention sinks in diffusion transformers, extending observations from language models to generative vision models. The large-scale evaluation across hundreds of prompts, corroboration with SDXL, public release of code, and use of multiple alignment and preference metrics provide a solid foundation for the findings. If the central dissociation holds, it implies that attention sinks are not critical for preserving text-image semantic correspondence in DiTs, which could inform future architectural designs and attention mechanism analyses in diffusion models.
major comments (2)
- The criteria for dynamically identifying dominant attention recipients per timestep and the exact mechanics of the paired interventions on score and value paths are not described in sufficient detail. This is load-bearing because the causal isolation of sink contributions depends on these choices being free of post-hoc selection or uncontrolled side effects on the diffusion trajectory, as hinted by the limited abstract description and the weakest assumption regarding intervention side effects.
- The metric-dependent boundary at k≥10 (HPS-v2 degrades while CLIP-T remains robust) combined with the ~6× larger perceptual shifts for sink-specific suppression versus random masking questions whether the proxies (CLIP-T, ImageReward, HPS-v2) faithfully measure semantic alignment independent of low-level perceptual/style changes. This directly impacts the central claim of preserved alignment under sink removal.
minor comments (2)
- The abstract and results would benefit from an explicit table or figure comparing all metrics (CLIP-T, ImageReward, HPS-v2) across k values for both sink suppression and random masking baselines to allow direct visual assessment of the dissociation.
- Clarify in the methods how the 553 prompts were sampled from GenEval and whether category balance was enforced, as this affects generalizability of the no-degradation claim at k=1.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed review. The comments highlight important areas for clarification on methodology and metric interpretation. We address each major comment below and will revise the manuscript to strengthen the presentation of our causal analysis.
read point-by-point responses
-
Referee: The criteria for dynamically identifying dominant attention recipients per timestep and the exact mechanics of the paired interventions on score and value paths are not described in sufficient detail. This is load-bearing because the causal isolation of sink contributions depends on these choices being free of post-hoc selection or uncontrolled side effects on the diffusion trajectory, as hinted by the limited abstract description and the weakest assumption regarding intervention side effects.
Authors: We agree that greater detail is needed for reproducibility and to fully address concerns about side effects. In the revised manuscript, we will expand Section 3.2 with: (i) explicit definition of sink identification as the top-k tokens by mean attention weight across heads at each timestep t (with k selected per prompt based on attention distribution); (ii) precise intervention mechanics—on the score path, we add a large negative bias (-1e6) to the logits of sink tokens prior to softmax; on the value path, we zero-mask the corresponding value vectors. We include pseudocode and a diagram of the modified attention block. To demonstrate absence of uncontrolled side effects, we add controls showing that the noise prediction MSE remains comparable to baseline (within 2%) and that random-token interventions of equal budget produce smaller perceptual shifts. These additions directly support the causal isolation claim. revision: yes
-
Referee: The metric-dependent boundary at k≥10 (HPS-v2 degrades while CLIP-T remains robust) combined with the ~6× larger perceptual shifts for sink-specific suppression versus random masking questions whether the proxies (CLIP-T, ImageReward, HPS-v2) faithfully measure semantic alignment independent of low-level perceptual/style changes. This directly impacts the central claim of preserved alignment under sink removal.
Authors: We acknowledge the potential for metric confounding and will revise the discussion to explicitly address it. CLIP-T is used as the primary semantic alignment proxy because it is a standard, training-free measure of text-image correspondence in CLIP space; its stability even at k=10 supports that high-level semantics are not disrupted. HPS-v2 and ImageReward degradation at higher k is consistent with their sensitivity to low-level aesthetics and style, which aligns with our finding that sink suppression induces sink-specific perceptual shifts (LPIPS distance ~6× larger than random masking). We will add a new paragraph discussing proxy limitations, report correlations between LPIPS and each metric, and note that the observed dissociation (robust CLIP-T alongside larger perceptual change) is itself evidence that sinks primarily modulate low-level features rather than semantic content. No new experiments are required, but we will clarify this interpretation to avoid overclaiming independence from perceptual effects. revision: partial
Circularity Check
No circularity: purely empirical causal analysis with external benchmarks
full rationale
The paper conducts an empirical causal analysis by dynamically identifying attention sinks in diffusion transformers and applying training-free paired interventions on score and value paths, then measuring impacts on independent external metrics (CLIP-T, ImageReward, HPS-v2) across GenEval prompts with comparisons to random masking. No derivation chain, first-principles result, fitted parameter, or prediction is claimed or present; the central findings are direct experimental observations of metric stability at k=1 and sink-specific perceptual shifts. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing elements. The work is self-contained against external benchmarks and does not reduce any claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- intervention strength k
axioms (1)
- standard math Standard scaled dot-product attention operates as defined in the transformer literature
Reference graph
Works this paper leans on
-
[1]
Block diffusion: Inter- polating between autoregressive and diffusion language models
Arriola, M., Gokaslan, A., Chiu, J., Yang, Z., Qi, Z., Han, J., Sahoo, S., and Kuleshov, V . Block diffusion: Inter- polating between autoregressive and diffusion language models. InInternational Conference on Learning Repre- sentations, volume 2025, pp. 50726–50753,
work page 2025
-
[2]
Vision transformers need registers
Darcet, T., Oquab, M., Mairal, J., and Bojanowski, P. Vision transformers need registers. InInternational Conference on Learning Representations, volume 2024, pp. 2632– 2652,
work page 2024
-
[3]
Feng, W., He, X., Fu, T.-J., Jampani, V ., Akula, A., Narayana, P., Basu, S., Wang, X. E., and Wang, W. Y . Training-free structured diffusion guidance for compositional text-to-image synthesis.arXiv preprint arXiv:2212.05032,
-
[4]
When attention sink emerges in language models: An empirical view
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y ., and Lin, M. When attention sink emerges in language models: An empirical view. InInternational Conference on Learning Representations, volume 2025, pp. 97114– 97144,
work page 2025
-
[5]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y ., and Cohen-Or, D. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Clipscore: A reference-free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
work page 2021
-
[7]
Faster diffu- sion via temporal attention decomposition.arXiv preprint arXiv:2404.02747, 2024
Li, J., Li, D., Savarese, S., and Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pp. 19730–19742. PMLR, 2023a. Li, Y ., Wang, H., Jin, Q., Hu, J., Chemerys, P., Fu, Y ., Wang, Y ., Tulyakov, S., and Ren, J. Snapfusion: Text-to-image diffusion m...
-
[8]
Sdxl: Improving latent diffusion models for high-resolution im- age synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dock- horn, T., M ¨uller, J., Penna, J., and Rombach, R. Sdxl: Improving latent diffusion models for high-resolution im- age synthesis. InInternational Conference on Learning Representations, volume 2024, pp. 1862–1874,
work page 2024
-
[9]
Ran-Milo, Y . Attention sinks are provably necessary in softmax transformers: Evidence from trigger-conditional tasks.arXiv preprint arXiv:2603.11487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ren, S., Yu, Q., He, J., Yuille, A., and Chen, L.-C. Grouping first, attending smartly: Training-free acceleration for diffusion transformers.arXiv preprint arXiv:2505.14687,
-
[11]
E., Petruzzi, S., Michielon, E., Silvestri, F., Scarda- pane, S., and Devoto, A
Rulli, M. E., Petruzzi, S., Michielon, E., Silvestri, F., Scarda- pane, S., and Devoto, A. Attention sinks in diffusion lan- guage models.arXiv preprint arXiv:2510.15731,
-
[12]
Sun, M., Chen, X., Kolter, J. Z., and Liu, Z. Massive activations in large language models.arXiv preprint arXiv:2402.17762,
-
[13]
Anal- ysis of attention in video diffusion transformers.arXiv preprint arXiv:2504.10317,
Wen, Y ., Wu, J., Jain, A., Goldstein, T., and Panda, A. Anal- ysis of attention in video diffusion transformers.arXiv preprint arXiv:2504.10317,
-
[14]
Revisiting text-to-image evaluation with gecko: on metrics, prompts, and human rating
Wiles, O., Zhang, C., Albuquerque, I., Kaji ´c, I., Wang, S., Bugliarello, E., Onoe, Y ., Papalampidi, P., Ktena, I., Knutsen, C., et al. Revisiting text-to-image evaluation with gecko: on metrics, prompts, and human rating. In International Conference on Learning Representations, volume 2025, pp. 272–287,
work page 2025
-
[15]
Wu, X., Hao, Y ., Sun, K., Chen, Y ., Zhu, F., Zhao, R., and Li, H. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Effi- cient streaming language models with attention sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Effi- cient streaming language models with attention sinks. In International Conference on Learning Representations, volume 2024, pp. 21875–21895,
work page 2024
-
[17]
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y ., Zhang, Z., Li, M., Zhu, L., Lu, Y ., et al. Sana: Efficient high- resolution image synthesis with linear diffusion trans- formers.arXiv preprint arXiv:2410.10629,
-
[18]
Real-time video generation with pyramid attention broadcast
Zhao, X., Jin, X., Wang, K., and You, Y . Real-time video generation with pyramid attention broadcast. InInterna- tional Conference on Learning Representations, volume 2025, pp. 3296–3319,
work page 2025
-
[19]
11 Attention Sinks in Diffusion Transformers: A Causal Analysis A. Experimental Details A.1. Models We conduct experiments primarily onStable Diffusion 3 (SD3)using the official inference pipeline. In this pipeline, attention is computed over amixed token setcontaining both visual-latent tokens and text-conditioning tokens within the same attention comput...
work page 2023
-
[20]
C. Experimental Setup Model and Architecture.We conduct experiments primarily on Stable Diffusion 3 (SD3) using the official inference pipeline. In this pipeline, attention is computed over a mixed token set containing both visual-latent tokens and text- conditioning tokens within the same attention operation (i.e., attention is not purely cross-attention...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.