Recognition: 2 theorem links
· Lean TheoremHow LLMs Are Persuaded: A Few Attention Heads, Rerouted
Pith reviewed 2026-05-12 04:11 UTC · model grok-4.3
The pith
A small set of mid-layer attention heads controls whether an LLM sticks to facts or switches to a persuaded answer by rerouting evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A small set of mid-layer attention heads almost entirely determines the model's answer by writing answer options into distinct vertices of a low-dimensional polyhedron. Persuasion produces a discrete jump from the correct-answer vertex to the persuasion-target vertex. Decision heads do not integrate evidence; they simply copy the option token selected by their attention. This selection is controlled by a rank-one evidence-routing feature that shallower heads construct from persuasive keywords in the input. Direct modification of the feature steers choices and its removal blocks persuasion, with every step confirmed by targeted interventions.
What carries the argument
The rank-one evidence-routing feature, which redirects attention in mid-layer heads so that decision heads copy the selected option token rather than reason over evidence.
If this is right
- Directly editing the routing feature steers the model's choice while preserving factual knowledge in other contexts.
- Removing the routing feature blocks persuasion without broadly impairing model performance.
- The same narrow circuit appears across open-source LLMs and in realistic input-poisoning settings such as Generative Engine Optimization.
- Shallower attention heads build the routing feature from specific persuasive keywords present in the input.
- Answer selection reduces to copying the token attended by the decision heads rather than integrating multiple pieces of evidence.
Where Pith is reading between the lines
- Safety systems could monitor or harden this specific circuit to detect and resist persuasion attempts in real time.
- The same attention-redirection pattern may underlie other controllable behaviors such as following harmful instructions.
- If the polyhedron structure of answer options generalizes, similar geometric switches might explain other forms of output manipulation.
- Testing whether the circuit exists in closed models would clarify how widely the mechanism applies.
Load-bearing premise
The interventions performed on the identified heads and rank-one feature fully isolate the causal mechanism for persuasion without depending on post-hoc selection that works only for the tested models and prompts.
What would settle it
An experiment that removes or alters the identified rank-one feature in a previously untested model or with novel persuasive prompts and still observes the same rate of factual errors would show that the circuit is not the controlling mechanism.
Figures





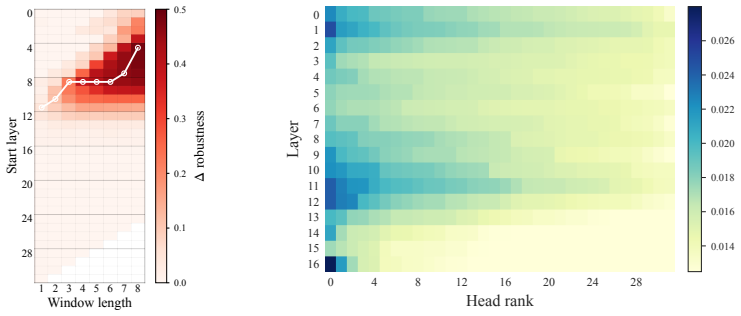
read the original abstract
Language models can be persuaded to abandon factual knowledge. This vulnerability is central to AI safety, but its internal mechanism remains poorly understood. We uncover a compact causal mechanism for persuasion-induced factual errors. A small set of mid-layer attention heads almost entirely determines the model's answer. These heads write answer options into a low-dimensional polyhedron, with options occupying distinct vertices. Persuasion does not blur belief or merely reduce confidence; it causes a discrete latent jump from the correct-answer vertex to the persuasion-target vertex. We show that decision heads are not reasoning over evidence. Instead, they copy whichever option token their attention selects. Persuasion works by redirecting attention. We isolate a rank-one evidence-routing feature that controls the route. Directly modifying this feature steers the model's choice, and removing it blocks persuasion. We then trace the feature back to a band of shallower attention heads that build it from persuasive keywords in the input. Every step is validated by intervention. This mechanism appears across open-source LLMs and realistic poisoning scenarios such as Generative Engine Optimization, revealing persuasion as a narrow, monitorable circuit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to identify a compact causal mechanism for persuasion-induced factual errors in LLMs: a small fixed set of mid-layer attention heads encodes answer options as distinct vertices in a low-dimensional polyhedron; decision heads copy the selected option token rather than reason over evidence; persuasion induces a discrete latent jump between vertices by redirecting attention via a rank-one evidence-routing feature constructed by shallower heads from persuasive keywords. All steps are asserted to be validated by causal interventions (ablation, editing), with the mechanism generalizing across open-source models and realistic scenarios such as Generative Engine Optimization.
Significance. If the causal claims hold without post-hoc selection artifacts, the work would be significant for AI safety and mechanistic interpretability. It would demonstrate that persuasion is a narrow, monitorable circuit rather than diffuse belief degradation, enabling targeted interventions and defenses. The emphasis on intervention validation and cross-model consistency, if rigorously shown, would strengthen the contribution beyond correlational analyses common in the field.
major comments (2)
- [Methods and results on head identification] The head-discovery and feature-identification procedure (described in the methods and results sections on attention-head analysis) must explicitly state whether the small set of mid-layer heads and the rank-one evidence-routing feature were identified via search on the same prompts and models used for the reported interventions and generalization tests. If selection occurred on the evaluation data, the interventions establish correlation on those cases but do not support the claim of a fixed, general mechanism that 'almost entirely determines' answers independently of post-hoc tuning.
- [Analysis of polyhedron geometry] The polyhedron geometry claim (in the section analyzing latent representations of answer options) requires quantitative evidence that the low-dimensional structure and distinct vertices persist under broader prompt distributions and model scales, rather than emerging only for the tested factual questions and persuasion scenarios. Without this, the discrete-jump interpretation of persuasion remains tied to the specific experimental conditions.
minor comments (2)
- [Figure captions and methods] Clarify the exact dimensionality of the polyhedron and provide the precise metric used to identify vertices (e.g., cosine similarity thresholds or clustering method) to allow replication.
- [Discussion] Add a limitations paragraph discussing the scope of tested models and scenarios, including any negative results on other architectures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our causal claims. We address each major point below with additional methodological details and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods and results on head identification] The head-discovery and feature-identification procedure (described in the methods and results sections on attention-head analysis) must explicitly state whether the small set of mid-layer heads and the rank-one evidence-routing feature were identified via search on the same prompts and models used for the reported interventions and generalization tests. If selection occurred on the evaluation data, the interventions establish correlation on those cases but do not support the claim of a fixed, general mechanism that 'almost entirely determines' answers independently of post-hoc tuning.
Authors: We agree that explicit documentation of the discovery procedure is necessary to support claims of a fixed mechanism. The head set and rank-one feature were identified through systematic layer-wise ablation on a development split of factual prompts (distinct from the held-out test prompts used for all reported interventions, editing experiments, and cross-model generalization tests). The procedure first ranks heads by causal effect on answer choice across the development split, then isolates the routing feature via activation patching on the same split before freezing the identified components for evaluation. To eliminate any ambiguity, we will revise the Methods section to include a dedicated subsection on data partitioning, the exact ablation ranking protocol, and confirmation that no test prompts influenced selection. This revision will also report the size of the development split and the stability of the identified heads across random partitions. revision: yes
-
Referee: [Analysis of polyhedron geometry] The polyhedron geometry claim (in the section analyzing latent representations of answer options) requires quantitative evidence that the low-dimensional structure and distinct vertices persist under broader prompt distributions and model scales, rather than emerging only for the tested factual questions and persuasion scenarios. Without this, the discrete-jump interpretation of persuasion remains tied to the specific experimental conditions.
Authors: The referee correctly notes that the current geometry analysis is limited to the factual-question distribution used throughout the paper. While the discrete-jump behavior is directly validated by targeted interventions that move representations between vertices on held-out prompts, we lack systematic quantification (e.g., vertex separation metrics, effective dimensionality, and stability under paraphrases or out-of-distribution prompts) across wider distributions and larger model scales. We will therefore add a new subsection with quantitative results: (i) PCA dimensionality and inter-vertex distances computed on an expanded prompt set including paraphrases and non-factual queries; (ii) the same metrics evaluated on additional model scales; and (iii) a table reporting how often the low-dimensional polyhedron structure is recovered. These additions will be placed in the revised geometry analysis section. revision: yes
Circularity Check
No significant circularity; claims rest on intervention-validated empirical identification rather than definitional or fitted reduction
full rationale
The paper's central claims concern a compact causal circuit for persuasion identified via targeted interventions on attention heads and a rank-one feature, with validation stated to hold across models and scenarios. No equations or derivations are presented that reduce a claimed result to a quantity defined by the same fitted parameters or inputs. Head and feature identification is described as intervention-validated rather than obtained by optimizing a loss on the target behavior itself. Self-citations are not invoked as load-bearing uniqueness theorems. The derivation chain therefore remains self-contained against external benchmarks of causal intervention, with no step reducing by construction to its own selection criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attention heads implement discrete, copy-based decision rules rather than distributed reasoning
- domain assumption The low-dimensional polyhedron structure faithfully represents the model's internal answer selection
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoesDecision heads encode choices in a low-dimensional tetrahedral subspace... maps samples into four well-separated clusters, one for each answer option, arranged near the vertices of an approximate regular triangular pyramid... persuasion... causes a discrete jump from the correct-answer vertex to the persuasion-target vertex.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesA rank-one evidence-routing feature that controls the route... the high-dimensional routing decision reduces to a scalar feature on candidate option tokens.
Reference graph
Works this paper leans on
-
[1]
Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958,
Simple synthetic data reduces sycophancy in large language models , author=. arXiv preprint arXiv:2308.03958 , year=
- [2]
-
[3]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Benchmarking and defending against indirect prompt injection attacks on large language models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[4]
Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
-
[5]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ PoisonedRAG \ : Knowledge corruption attacks to \ Retrieval-Augmented \ generation of large language models , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[6]
Advances in neural information processing systems , volume=
Template-based algorithms for connectionist rule extraction , author=. Advances in neural information processing systems , volume=
-
[7]
The book of GENESIS: exploring realistic neural models with the GEneral NEural SImulation System , author=. 2012 , publisher=
work page 2012
-
[8]
Journal of Neuroscience , volume=
Dynamics of learning and recall at excitatory recurrent synapses and cholinergic modulation in rat hippocampal region CA3 , author=. Journal of Neuroscience , volume=. 1995 , publisher=
work page 1995
-
[9]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Syceval: Evaluating llm sycophancy , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[10]
The earth is flat because...: Investigating llms’ belief towards misinformation via persuasive conversation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Activation oracles: Training and evaluating llms as general-purpose activation explainers , author=. arXiv preprint arXiv:2512.15674 , year=
-
[12]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[13]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
How to use and interpret activation patching , author=. arXiv preprint arXiv:2404.15255 , year=
-
[14]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Towards faithful natural language explanations: A study using activation patching in large language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[15]
Towards best practices of activation patching in language models: Metrics and methods , author=. arXiv preprint arXiv:2309.16042 , year=
-
[16]
Linear representations of sentiment in large language models , author=. arXiv preprint arXiv:2310.15154 , year=
-
[17]
Copy Suppression: Comprehensively Understanding an Attention Head , shorttitle =
Copy suppression: Comprehensively understanding an attention head , author=. arXiv preprint arXiv:2310.04625 , year=
-
[18]
Does circuit analysis interpretability scale? evidence from multiple choice capabilities in chinchilla , author=. arXiv preprint arXiv:2307.09458 , year=
-
[19]
The Hydra Effect: Emergent Self-repair in Language Model Computations , journal =
The hydra effect: Emergent self-repair in language model computations , author=. arXiv preprint arXiv:2307.15771 , year=
-
[20]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Geo: Generative engine optimization , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:2403.18680 , year=
Non-linear inference time intervention: Improving llm truthfulness , author=. arXiv preprint arXiv:2403.18680 , year=
-
[23]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[24]
arXiv preprint arXiv:2510.04721 , year=
BrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs , author=. arXiv preprint arXiv:2510.04721 , year=
-
[25]
Measuring Opinion Bias and Sycophancy via LLM-based Persuasion
Measuring Opinion Bias and Sycophancy via LLM-based Coercion , author=. arXiv preprint arXiv:2604.21564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2410.02653 , year=
Measuring and improving persuasiveness of large language models , author=. arXiv preprint arXiv:2410.02653 , year=
-
[27]
Flattery in Motion: Benchmarking and Analyzing Sycophancy in Video-LLMs
Flattery in motion: Benchmarking and analyzing sycophancy in video-llms , author=. arXiv preprint arXiv:2506.07180 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Towards Understanding Sycophancy in Language Models
Towards understanding sycophancy in language models , author=. arXiv preprint arXiv:2310.13548 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Mass-editing memory in a transformer , author=. arXiv preprint arXiv:2210.07229 , year=
-
[30]
Separating tongue from thought: Activation patching reveals language-agnostic concept representations in transformers , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
arXiv preprint arXiv:2603.13652 , year=
Causal Attribution via Activation Patching , author=. arXiv preprint arXiv:2603.13652 , year=
-
[32]
arXiv preprint arXiv:2403.00745 , year=
Atp*: An efficient and scalable method for localizing llm behaviour to components , author=. arXiv preprint arXiv:2403.00745 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.