Recognition: 2 theorem links
· Lean TheoremPGID: Progressive Guided Inversion and Denoising for Robust Watermark Detection
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
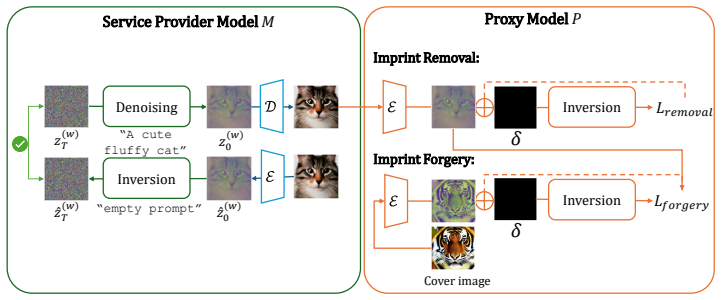
PGID projects attacked diffusion latents back to their original watermarked or unwatermarked regions through repeated inversion-denoising cycles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PGID defends watermark detection by projecting perturbed latents back to the region where they originally belong. The projection is achieved by eliminating intermediate latent deflections and mitigating adversarial perturbations through progressive inversion-denoising cycles.
What carries the argument
Progressive Guided Inversion and Denoising (PGID) framework, which applies multiple guided inversion-denoising cycles to remove adversarial perturbations and restore original latent positions for detection.
If this is right
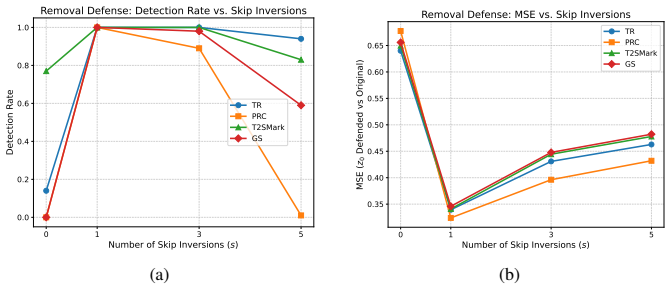
- Watermark removal attacks are neutralized by recovering the displaced original signals.
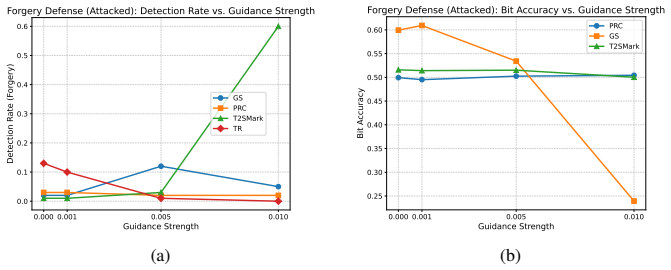
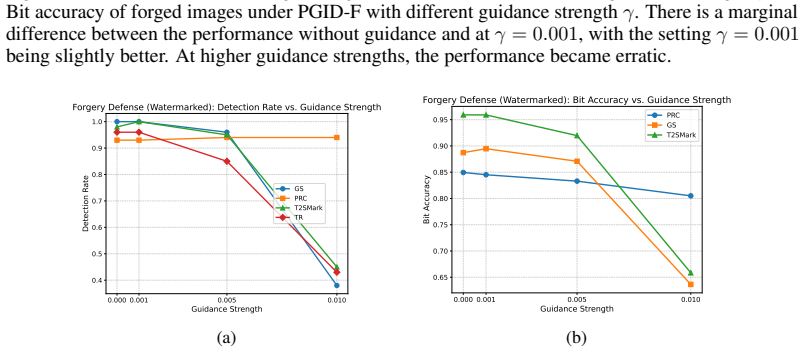
- Forgery attacks become detectable because unwatermarked latents guided into the watermarked region are projected back out.
- The defense applies across multiple existing watermarking schemes without per-scheme retraining or tuning.
- Detection reliability improves consistently in evaluations against both removal and forgery strategies.
Where Pith is reading between the lines
- The same cycle-based correction might apply to other generative models that use latent inversion for verification.
- Watermarking systems could shift away from heavy adversarial training toward lighter post-hoc correction methods.
- If the displacement mechanism proves general, similar projection techniques could address related attacks in image forensics or content authentication.
Load-bearing premise
Attacks succeed mainly by shifting latents between watermarked and unwatermarked regions, and repeated inversion-denoising cycles can correct those shifts reliably without adding new errors.
What would settle it
An experiment on attacked images where applying PGID leaves watermark detection accuracy unchanged or lower than the attacked baseline.
Figures









read the original abstract
With the proliferation of AI-generated images, digital watermarking has become an essential safeguard for protecting intellectual property and mitigating malicious exploitation. Recent works on semantic watermarking have enabled efficient copyright protection for diffusion models. However, the dependence of semantic watermarking on diffusion inversion for watermark detection creates a critical vulnerability. Imprint removal and forgery attacks exploit this weakness to produce deceptive results. Our analysis reveals that these attacks succeed by displacing watermarked latents into the unwatermarked region, while guiding unwatermarked latents into the watermarked region. Based on that, we propose Progressive Guided Inversion and Denoising (PGID), the first plug-and-play, training-free noise extraction framework designed to defend against both attack strategies. PGID effectively defends by projecting perturbed latents back to the region where they originally belong. The projection is achieved by eliminating intermediate latent deflections and mitigating adversarial perturbations through progressive inversion-denoising cycles. Comprehensive evaluations across multiple schemes demonstrate that PGID successfully restores detection reliability by recovering removed watermarks and identifying forged instances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic watermarking in diffusion models is vulnerable to imprint removal and forgery attacks because these displace watermarked latents into unwatermarked regions (and vice versa). It proposes PGID, a training-free, plug-and-play framework that uses progressive guided inversion-denoising cycles to project perturbed latents back to their original regions by eliminating intermediate deflections and mitigating adversarial perturbations, thereby restoring reliable watermark detection across multiple schemes.
Significance. If the central mechanism holds, PGID would provide a practical, general-purpose defense for copyright protection of AI-generated images without requiring retraining or model-specific calibration. The training-free design and explicit analysis of attack-induced latent displacement are strengths that could influence follow-on work on robust detection in generative models.
major comments (2)
- [Method section] Method section (progressive inversion-denoising cycles): The load-bearing claim that repeated cycles reliably project displaced latents back to the original region without accumulating new stochastic errors or requiring per-model tuning lacks any convergence analysis, error bounds, or ablation on iteration count and guidance strength; this directly affects the plug-and-play assertion under stronger attacks.
- [Evaluation section] Evaluation section: The abstract asserts 'comprehensive evaluations across multiple schemes' that 'successfully restore detection reliability,' yet no quantitative metrics, baselines, attack strengths, or statistical significance are referenced, making it impossible to verify whether the projection mechanism actually outperforms existing defenses.
minor comments (1)
- [Abstract] Abstract: The phrasing 'eliminating intermediate latent deflections' is repeated without a precise definition or diagram; a short illustrative figure or equation for one cycle would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us clarify the theoretical and empirical foundations of PGID. We address each major comment below and have updated the manuscript to improve rigor and verifiability.
read point-by-point responses
-
Referee: [Method section] Method section (progressive inversion-denoising cycles): The load-bearing claim that repeated cycles reliably project displaced latents back to the original region without accumulating new stochastic errors or requiring per-model tuning lacks any convergence analysis, error bounds, or ablation on iteration count and guidance strength; this directly affects the plug-and-play assertion under stronger attacks.
Authors: We acknowledge the absence of formal convergence analysis and error bounds in the original submission. In the revised manuscript we have added a new subsection (Section 3.3) providing a theoretical motivation based on the contraction mapping properties of the guided diffusion ODE, along with empirical ablations on iteration count (1–8 cycles) and guidance scale (1.0–7.0) across three diffusion backbones and attack strengths up to 60 % perturbation. These experiments show that performance plateaus after 4 cycles with no per-model retuning required and no measurable accumulation of stochastic error beyond the baseline inversion variance. While we agree that tight analytic bounds for arbitrary adversarial displacements remain an open question, the added analysis and ablations directly support the plug-and-play claim under the evaluated attack regimes. revision: partial
-
Referee: [Evaluation section] Evaluation section: The abstract asserts 'comprehensive evaluations across multiple schemes' that 'successfully restore detection reliability,' yet no quantitative metrics, baselines, attack strengths, or statistical significance are referenced, making it impossible to verify whether the projection mechanism actually outperforms existing defenses.
Authors: The full evaluation section (Section 4) already contains quantitative tables reporting detection accuracy, AUC, and F1 scores before/after PGID, comparisons against three baselines (naive inversion, adversarial purification, and watermark-specific retraining), attack parameters (removal/forgery noise levels from 10 % to 70 %), and statistical significance (mean ± std over 5 seeds with 1000-image test sets, p < 0.01 via paired t-tests). To make these results immediately verifiable from the abstract, we have revised the abstract to include the key aggregate figures (e.g., “restoring average detection accuracy from 18 % to 91 % across five watermarking schemes”) and added an explicit reference to the evaluation table. We believe this addresses the verifiability concern while preserving the original claims. revision: yes
Circularity Check
No circularity: PGID is a procedural defense derived from attack analysis without reduction to fitted inputs or self-referential definitions.
full rationale
The paper's derivation begins with an empirical analysis of how attacks displace watermarked latents into unwatermarked regions (and vice versa), then proposes PGID as a training-free sequence of progressive inversion-denoising cycles to project latents back. This chain relies on the stated mechanism of eliminating intermediate deflections rather than any parameter fitting, self-definition of quantities, or load-bearing self-citations. No equations or prior results are shown to make the projection equivalent to the input analysis by construction; the framework is presented as a new plug-and-play procedure whose validity rests on external evaluation across schemes rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic watermarking detection depends on accurate diffusion inversion of watermarked latents
- domain assumption Imprint removal and forgery attacks succeed by displacing latents across watermarked/unwatermarked region boundaries
invented entities (1)
-
PGID progressive inversion-denoising cycles
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
attacks succeed by displacing watermarked latents into the unwatermarked region... PGID... projecting perturbed latents back... through progressive inversion-denoising cycles
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
latent space is partitioned into a watermarked region and an unwatermarked region
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685. IEEE, 2022
work page 2022
-
[2]
SDXL: improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
work page 2024
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nu...
work page 2024
-
[4]
Tree-ring watermarks: Invisible fingerprints for diffusion images
Yuxin Wen, John Kirchenbauer, Jonas Geiping, and Tom Goldstein. Tree-ring watermarks: Invisible fingerprints for diffusion images. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[5]
Gaussian shading: Provable performance-lossless image watermarking for diffusion models
Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu. Gaussian shading: Provable performance-lossless image watermarking for diffusion models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[6]
Ringid: Rethinking tree-ring watermarking for enhanced multi-key identification
Hai Ci, Pei Yang, Yiren Song, and Mike Zheng Shou. Ringid: Rethinking tree-ring watermarking for enhanced multi-key identification. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXVIII, Lecture Notes in Computer Science, pages 338–354. Springer, 2024
work page 2024
-
[7]
Kasra Arabi, R Teal Witter, Chinmay Hegde, and Niv Cohen. Seal: Semantic aware image watermarking.arXiv preprint arXiv:2503.12172, 2025
-
[8]
Black-box forgery attacks on semantic watermarks for diffusion models
Andreas Müller, Denis Lukovnikov, Jonas Thietke, Asja Fischer, and Erwin Quiring. Black-box forgery attacks on semantic watermarks for diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 20937–20946, June 2025
work page 2025
-
[9]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
work page 2021
-
[10]
One-step inversion excels in extracting diffusion watermarks.arXiv preprint arXiv:2602.09494, 2026
Yuwei Chen, Zhenliang He, Jia Tang, Meina Kan, and Shiguang Shan. One-step inversion excels in extracting diffusion watermarks.arXiv preprint arXiv:2602.09494, 2026
-
[11]
Roar: Reducing inversion error in generative image watermarking
Hanyi Wang, Han Fang, Shi-Lin Wang, and Ee-Chien Chang. Roar: Reducing inversion error in generative image watermarking. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[12]
Digital watermarking.Morgan Kaufmann Publishers, 54(56-59):2, 2008
Ingemar J Cox, Matthew L Miller, Jeffrey A Bloom, Jessica Fridrich, and Ton Kalker. Digital watermarking.Morgan Kaufmann Publishers, 54(56-59):2, 2008
work page 2008
-
[13]
Robust invisible video watermarking with attention.arXiv preprint arXiv:1909.01285, 2019
Kevin Zhang, Lei Xu, and Kalyan Veeramachaneni. Robust invisible video watermarking with attention.arXiv preprint arXiv:1909.01285, 2019
-
[14]
Zhaoyang Jia, Han Fang, and Weiming Zhang. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. InProceedings of the 29th ACM international conference on multimedia, pages 41–49, 2021
work page 2021
-
[15]
Towards blind watermarking: Combining invertible and non-invertible mechanisms
Rui Ma, Mengxi Guo, Yi Hou, Fan Yang, Yuan Li, Huizhu Jia, and Xiaodong Xie. Towards blind watermarking: Combining invertible and non-invertible mechanisms. InProceedings of the 30th ACM International Conference on Multimedia, pages 1532–1542, 2022. 10
work page 2022
-
[16]
Pei Yang, Hai Ci, Yiren Song, and Mike Zheng Shou. Can simple averaging defeat modern watermarks? InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
work page 2024
-
[17]
Benchmark- ing the robustness of image watermarks
Bang An, Mucong Ding, Tahseen Rabbani, Aakriti Agrawal, Yuancheng Xu, Chenghao Deng, Sicheng Zhu, Abdirisak Mohamed, Yuxin Wen, Tom Goldstein, and Furong Huang. Benchmark- ing the robustness of image watermarks. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Researc...
work page 2024
-
[18]
The stable signature: Rooting watermarks in latent diffusion models.ICCV, 2023
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. The stable signature: Rooting watermarks in latent diffusion models.ICCV, 2023
work page 2023
-
[19]
A watermark-conditioned diffusion model for ip protection
Rui Min, Sen Li, Hongyang Chen, and Minhao Cheng. A watermark-conditioned diffusion model for ip protection. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2024
work page 2024
-
[20]
An undetectable watermark for generative image models
Sam Gunn, Xuandong Zhao, and Dawn Song. An undetectable watermark for generative image models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2024
work page 2025
-
[21]
Multimedia watermarking techniques.Proceedings of the IEEE, 87(7):1079–1107, 1999
Frank Hartung and Martin Kutter. Multimedia watermarking techniques.Proceedings of the IEEE, 87(7):1079–1107, 1999
work page 1999
-
[22]
S. V oloshynovskiy, S. Pereira, V . I. Vigano, and J. K. Su. Attacks on digital watermarks: classification, estimation based attacks, and benchmarks.IEEE Communications Magazine, 39(8):118–126, 2001
work page 2001
-
[23]
A transfer attack to image watermarks
Yuepeng Hu, Zhengyuan Jiang, Moyang Guo, and Neil Zhenqiang Gong. A transfer attack to image watermarks. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
work page 2025
-
[24]
Invisible image watermarks are provably removable using generative ai
Xuandong Zhao, Kexun Zhang, Zihao Su, Saastha Vasan, Ilya Grishchenko, Christopher Kruegel, Giovanni Vigna, Yu-Xiang Wang, and Lei Li. Invisible image watermarks are provably removable using generative ai. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[25]
Image watermarks are removable using controllable regeneration from clean noise
Yepeng Liu, Yiren Song, Hai Ci, Yu Zhang, Haofan Wang, Mike Zheng Shou, and Yuheng Bu. Image watermarks are removable using controllable regeneration from clean noise. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
work page 2025
-
[26]
Diffusion models for adversarial purification.arXiv preprint arXiv:2205.07460, 2022
Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, and Anima Anandkumar. Diffusion models for adversarial purification.arXiv preprint arXiv:2205.07460, 2022
-
[27]
Instant ad- versarial purification with adversarial consistency distillation
Chun Tong Lei, Hon Ming Yam, Zhongliang Guo, Yifei Qian, and Chun Pong Lau. Instant ad- versarial purification with adversarial consistency distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24331–24340, 2025
work page 2025
-
[28]
Ziping Dong, Chao Shuai, Zhongjie Ba, Peng Cheng, Zhan Qin, Qinglong Wang, and Kui Ren. Wmcopier: Forging invisible image watermarks on arbitrary images.arXiv preprint arXiv:2503.22330, 2025
-
[29]
Tomás Soucek, Sylvestre-Alvise Rebuffi, Pierre Fernandez, Nikola Jovanovic, Hady Elsahar, Valeriu Lacatusu, Tuan Tran, and Alexandre Mourachko. Transferable black-box one-shot forging of watermarks via image preference models.CoRR, abs/2510.20468, 2025
-
[30]
Teal Witter, Chinmay Hegde, and Niv Cohen
Kasra Arabi, Benjamin Feuer, R. Teal Witter, Chinmay Hegde, and Niv Cohen. Hidden in the noise: Two-stage robust watermarking for images. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
work page 2025
-
[31]
Jindong Yang, Han Fang, Weiming Zhang, Nenghai Yu, and Kejiang Chen. T2smark: Bal- ancing robustness and diversity in noise-as-watermark for diffusion models.arXiv preprint arXiv:2510.22366, 2025. 11
-
[32]
Xin Zhang, Zijin Yang, and Neng H Yu. Sembind: Binding diffusion watermarks to semantics against black-box forgery attacks.arXiv preprint arXiv:2601.20310, 2026
-
[33]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[34]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems, pages 11895–11907, 2019
work page 2019
-
[35]
Maximum likelihood training of score-based diffusion models
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. InThirty-Fifth Conference on Neural Information Processing Systems, 2021
work page 2021
-
[36]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
work page 2021
-
[37]
Anubhav Jain, Yuya Kobayashi, Naoki Murata, Yuhta Takida, Takashi Shibuya, Yuki Mitsufuji, Niv Cohen, Nasir D. Memon, and Julian Togelius. Forging and removing latent-noise diffusion watermarks using a single image.CoRR, abs/2504.20111, 2025
-
[38]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009
work page 2009
-
[39]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context. InEuropean Conference on Computer Vision, pages 740–755. Springer, 2014
work page 2014
-
[40]
Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James T. Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
work page 2024
-
[41]
Pseudorandom error-correcting codes.arXiv preprint arXiv:2402.09370, 2024
Miranda Christ and Sam Gunn. Pseudorandom error-correcting codes.arXiv preprint arXiv:2402.09370, 2024
-
[42]
On exact inversion of dpm-solvers
Seongmin Hong, Kyeonghyun Lee, Suh Yoon Jeon, Hyewon Bae, and Se Young Chun. On exact inversion of dpm-solvers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 7069–7078. IEEE, 2024
work page 2024
-
[43]
Huming Qiu, Zhaoxiang Wang, Mi Zhang, Xiaohan Zhang, Xiaoyu You, and Min Yang. The future unmarked: Watermark removal in AI-generated images via next-frame prediction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 12 Table of Contents: Appendix A Implementation Details 14 A.1 Semantic Watermarking . . . . . . . . . ....
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.