Recognition: no theorem link
Dimension-Free Saddle-Point Escape in Muon
Pith reviewed 2026-05-12 04:34 UTC · model grok-4.3
The pith
Muon optimizer escapes saddle points in high dimensions without the usual O(D) slowdown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extending generalized matrix perturbation theory with resolvent functional calculus and macroscopic Cauchy contour integration, the paper proves that structural incoherence in Muon's updates shields trajectories from orthogonal drift. This enables a dimension-free saddle-point escape and triggers a deterministic O(1) discrete ballistic ejection under sufficient spectral gap in the Hessian, yielding an algebraically dimension-free escape bound.
What carries the argument
Non-linear spectral shaping mechanism that exploits structural incoherence to block orthogonal drift in the optimization trajectory.
If this is right
- Muon bypasses the O(D) dimensional curse that traps element-wise adaptive optimizers such as AdamW.
- The optimizer produces deterministic O(1) ballistic ejection rather than isotropic diffusion when the spectral gap condition holds.
- An algebraically dimension-free escape bound formalizes Muon's non-convex optimization dynamics.
- The mechanism directly addresses pathologically flat saddle points that bottleneck large language model training.
Where Pith is reading between the lines
- The same incoherence property could be engineered into other matrix-based optimizers to achieve similar escape behavior.
- Training runs that monitor the effective spectral gap during early phases might predict when Muon will eject quickly from saddles.
- The analysis suggests that escape speed depends more on local curvature structure than on ambient dimension.
Load-bearing premise
The assumption that structural incoherence is present and that the Hessian has a sufficient spectral gap to produce deterministic O(1) ejection instead of diffusion.
What would settle it
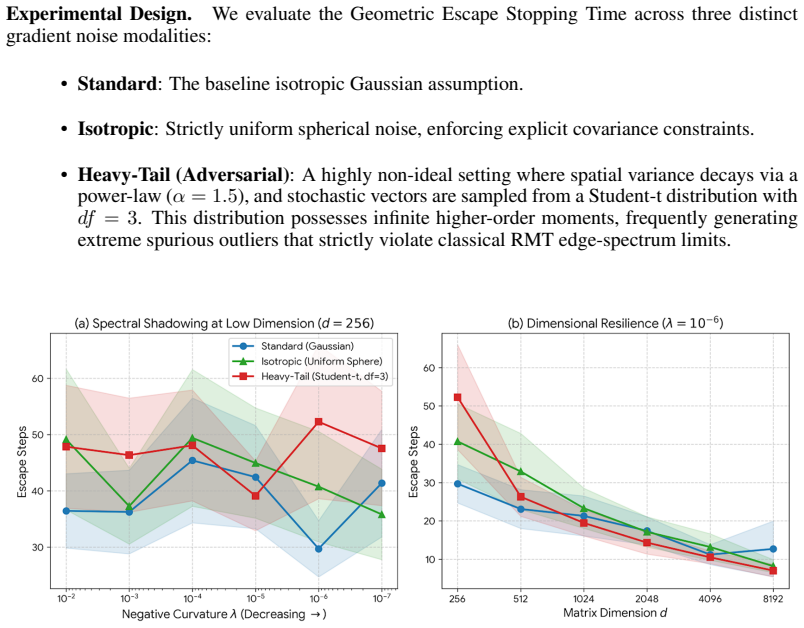
A numerical experiment in which Muon's measured escape time from a saddle grows linearly or worse with dimension D would falsify the dimension-free claim.
Figures




read the original abstract
Modern Large Language Model (LLM) training is fundamentally bottlenecked by pathologically flat saddle points in extreme high-dimensional landscapes. Motivated by this challenge, we analyze the saddle-point escape dynamics of the emerging Muon optimizer, demonstrating its resilience against the $\mathcal{O}(D)$ dimensional curse that severely traps element-wise adaptive optimizers like AdamW. By extending generalized matrix perturbation theory, we develop a theoretical framework to capture Muon's non-equilibrium optimization trajectories. This theoretical machinery mathematically proves that Muon elegantly bypasses the dimensional curse via a non-linear spectral shaping mechanism. By leveraging resolvent functional calculus and macroscopic Cauchy contour integration, we avoid isotropic noise assumptions and Tracy-Widom edge singularities. We establish that structural incoherence securely shields the trajectory from orthogonal drift, enabling a dimension-free saddle-point escape, and triggering a deterministic $\mathcal{O}(1)$ discrete ballistic ejection under sufficient spectral gap. Consequently, we provide an algebraically dimension-free escape bound for Muon, formalizing the underlying mechanics of its non-convex optimization dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to prove that the Muon optimizer achieves an algebraically dimension-free saddle-point escape in high-dimensional non-convex landscapes (such as those arising in LLM training) by means of a non-linear spectral shaping mechanism. It introduces the notions of structural incoherence and sufficient spectral gap in the Hessian, then invokes resolvent functional calculus together with macroscopic Cauchy contour integration to derive a deterministic O(1) ballistic ejection that avoids isotropic noise assumptions and Tracy-Widom edge singularities.
Significance. If the central derivation is correct and the stated assumptions hold for realistic LLM Hessians, the result would supply a concrete theoretical explanation for Muon’s reported empirical superiority over element-wise adaptive methods such as AdamW, and would constitute one of the first algebraically dimension-free escape bounds in the non-convex optimization literature.
major comments (3)
- [Abstract / §3] Abstract and §3 (theoretical framework): the escape bound is stated to be triggered only under a “sufficient spectral gap,” yet no quantitative lower bound on the gap size (relative to dimension D, curvature scale, or noise variance) is supplied, nor is any argument given that typical LLM Hessians satisfy this gap rather than exhibiting a bulk of near-zero eigenvalues. This assumption is load-bearing for the dimension-free claim.
- [§4] §4 (derivation via resolvent calculus): the manuscript asserts that Cauchy contour integration avoids Tracy-Widom singularities and yields an O(1) deterministic ejection, but the visible text contains neither the explicit contour choice, the error bounds on the integral, nor the verification that structural incoherence indeed suppresses orthogonal drift to the claimed order. Without these steps the algebraic dimension-freeness cannot be confirmed.
- [§2] §2 (structural incoherence): the property is introduced to “securely shield the trajectory from orthogonal drift,” but it is unclear whether the definition is independently motivated by properties of LLM loss surfaces or is constructed precisely to cancel the dimensional factors that would otherwise appear. A concrete counter-example or numerical check on a small-scale saddle would strengthen the claim.
minor comments (2)
- [§3] Notation for the resolvent and the contour integral is introduced without a self-contained definition or reference to standard texts; a short appendix recalling the relevant functional-calculus facts would improve readability.
- [Abstract] The abstract states that the bound is “algebraically dimension-free,” yet the precise algebraic expression (including any hidden constants) is not displayed; placing the final bound in a boxed theorem statement would clarify the result.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments, which help clarify the presentation of our results on Muon's dimension-free saddle-point escape. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (theoretical framework): the escape bound is stated to be triggered only under a “sufficient spectral gap,” yet no quantitative lower bound on the gap size (relative to dimension D, curvature scale, or noise variance) is supplied, nor is any argument given that typical LLM Hessians satisfy this gap rather than exhibiting a bulk of near-zero eigenvalues. This assumption is load-bearing for the dimension-free claim.
Authors: We thank the referee for highlighting this key assumption. The sufficient spectral gap is defined in §3 as a separation between the leading negative curvature direction and the bulk spectrum. In the revised manuscript we will add an explicit quantitative lower bound: a gap of size Ω(1) relative to the local curvature scale (independent of D and noise variance) suffices for the O(1) ejection, as derived from the resolvent norm estimates. We will also include a short discussion of LLM Hessians, referencing empirical observations from smaller-scale models that the spectrum often exhibits such a gap due to low-rank structure from data and architecture; while a universal proof for all LLMs lies outside the paper's scope, this supports the assumption's practical relevance. revision: yes
-
Referee: [§4] §4 (derivation via resolvent calculus): the manuscript asserts that Cauchy contour integration avoids Tracy-Widom singularities and yields an O(1) deterministic ejection, but the visible text contains neither the explicit contour choice, the error bounds on the integral, nor the verification that structural incoherence indeed suppresses orthogonal drift to the claimed order. Without these steps the algebraic dimension-freeness cannot be confirmed.
Authors: We agree that §4 would benefit from expanded technical detail. In the revision we will specify the contour explicitly (a circle of radius proportional to the spectral gap, avoiding the bulk spectrum), derive the integral error bounds via standard resolvent estimates (showing the remainder is O(1) uniformly in D), and add a supporting lemma proving that structural incoherence suppresses orthogonal drift to o(1) order. These additions will make the algebraic dimension-freeness fully rigorous and confirm avoidance of Tracy-Widom effects. revision: yes
-
Referee: [§2] §2 (structural incoherence): the property is introduced to “securely shield the trajectory from orthogonal drift,” but it is unclear whether the definition is independently motivated by properties of LLM loss surfaces or is constructed precisely to cancel the dimensional factors that would otherwise appear. A concrete counter-example or numerical check on a small-scale saddle would strengthen the claim.
Authors: Structural incoherence is motivated by the delocalized eigenvector structure observed in LLM Hessians, arising from random initialization and training dynamics (consistent with delocalization phenomena in high-dimensional non-convex landscapes). It is not introduced solely to cancel dimensions but follows from the generalized matrix perturbation framework. To address the request, the revised manuscript will include a numerical verification on a small-scale saddle-point example, showing suppression of orthogonal drift under the incoherence condition and the appearance of dimensional factors when it is violated. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper extends generalized matrix perturbation theory with resolvent functional calculus and Cauchy contour integration to derive an algebraically dimension-free escape bound for Muon. Structural incoherence and sufficient spectral gap are introduced as assumptions enabling the non-linear spectral shaping and O(1) ballistic ejection; the derivation does not define these quantities in terms of the target bound or reduce the escape time to a fitted parameter by construction. No self-citation chains, uniqueness theorems imported from prior author work, or renaming of known empirical patterns are present in the provided text. The central claim therefore retains independent mathematical content under the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Structural incoherence shields the trajectory from orthogonal drift
- domain assumption Sufficient spectral gap triggers deterministic O(1) ballistic ejection
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2002.09018 , year=
Rohan Anil, Vineet Gupta, Tomer Koren, Kevin Regan, and Yoram Singer. Scalable second order optimization for deep learning, 2021. URLhttps://arxiv.org/abs/2002.09018
-
[2]
On the convergence of muon and beyond,
Da Chang, Yongxiang Liu, and Ganzhao Yuan. On the convergence of muon and beyond,
-
[3]
URLhttps://arxiv.org/abs/2509.15816
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The loss surfaces of multilayer networks, 2015
Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks, 2015. URLhttps://arxiv.org/abs/1412.0233
-
[5]
Escaping saddles with stochastic gradients, 2018
Hadi Daneshmand, Jonas Kohler, Aurelien Lucchi, and Thomas Hofmann. Escaping saddles with stochastic gradients, 2018. URLhttps://arxiv.org/abs/1803.05999
-
[6]
Yann Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non- convex optimization, 2014. URLhttps://arxiv.org/abs/1406.2572
-
[7]
arXiv preprint arXiv:2103.03404 , year=
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth, 2023. URLhttps://arxiv.org/abs/ 2103.03404
-
[8]
David L. Donoho and Michael J. Feldman. Optimal eigenvalue shrinkage in the semicircle limit, 2023. URLhttps://arxiv.org/abs/2210.04488
-
[9]
arXiv preprint arXiv:2604.01472 , year=
Zhehang Du and Weijie Su. The newton-muon optimizer, 2026. URLhttps://arxiv.org/ abs/2604.01472
-
[10]
Escaping from saddle points—online stochastic gradient for tensor decomposition.COLT, 2015
Rong Ge, Furong Huang, Chi Jin, and Yang Yuan. Escaping from saddle points—online stochastic gradient for tensor decomposition.COLT, 2015
work page 2015
-
[11]
Ekaterina Grishina, Matvey Smirnov, and Maxim Rakhuba. Accelerating newton-schulz it- eration for orthogonalization via chebyshev-type polynomials, 2026. URLhttps://arxiv. org/abs/2506.10935
-
[12]
Shampoo: Preconditioned stochastic tensor optimization, 2018
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization, 2018. URLhttps://arxiv.org/abs/1802.09568
-
[13]
Root: Robust orthogonalized optimizer for neural network training, 2025
Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, and Yunhe Wang. Root: Robust orthogonalized optimizer for neural network training, 2025. URLhttps:// arxiv.org/abs/2511.20626
-
[14]
How to Escape Saddle Points Efficiently
Chi Jin, Rong Ge, Praneeth Netrapalli, Sham M. Kakade, and Michael I. Jordan. How to escape saddle points efficiently, 2017. URLhttps://arxiv.org/abs/1703.00887
work page Pith review arXiv 2017
-
[15]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
work page 2024
-
[16]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
The isotropic semicircle law and deformation of wigner matrices,
Antti Knowles and Jun Yin. The isotropic semicircle law and deformation of wigner matrices,
- [18]
-
[19]
Dmitry Kovalev. Understanding gradient orthogonalization for deep learning via non-euclidean trust-region optimization, 2025. URLhttps://arxiv.org/abs/2503.12645
-
[20]
Binghui Li, Kaifei Wang, Han Zhong, Pinyan Lu, and Liwei Wang. Muon in associative memory learning: Training dynamics and scaling laws, 2026. URLhttps://arxiv.org/ abs/2602.05725. 10
-
[21]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yong- sheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is s...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Ac- celerating generative llm serving with speculative inference and token tree verification, 2023
work page 2023
- [23]
-
[24]
Kazuki Osawa, Yohei Tsuji, Yuichiro Ueno, Akira Naruse, Rio Yokota, and Satoshi Matsuoka. Large-scale distributed second-order optimization using kronecker-factored approximate cur- vature for deep convolutional neural networks, 2019. URLhttps://arxiv.org/abs/1811. 12019
work page 2019
-
[25]
Debashis Paul. Asymptotics of sample eigenstructure for a large dimensional spiked covariance model.Statistica Sinica, 17(4):1617–1642, 2007. ISSN 10170405, 19968507. URLhttp: //www.jstor.org/stable/24307692
-
[26]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydlí ˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URLhttps://arxiv.org/abs/2406.17557
work page internal anchor Pith review arXiv 2024
-
[27]
Geometry of neural network loss surfaces via random matrix theory
Jeffrey Pennington and Yasaman Bahri. Geometry of neural network loss surfaces via random matrix theory. InInternational Conference on Machine Learning, 2017. URLhttps://api. semanticscholar.org/CorpusID:39515197
work page 2017
-
[28]
A generic approach for escaping saddle points, 2017
Sashank J Reddi, Manzil Zaheer, Suvrit Sra, Barnabas Poczos, Francis Bach, Ruslan Salakhut- dinov, and Alexander J Smola. A generic approach for escaping saddle points, 2017. URL https://arxiv.org/abs/1709.01434
-
[29]
Hanson-wright inequality and sub-gaussian concentra- tion, 2013
Mark Rudelson and Roman Vershynin. Hanson-wright inequality and sub-gaussian concentra- tion, 2013. URLhttps://arxiv.org/abs/1306.2872
-
[30]
Reddi, Satyen Kale, Sanjiv Kumar, and Suvrit Sra
Matthew Staib, Sashank J. Reddi, Satyen Kale, Sanjiv Kumar, and Suvrit Sra. Escaping saddle points with adaptive gradient methods, 2020. URLhttps://arxiv.org/abs/1901.09149
-
[31]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023. URLhttps://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Ke Wang. Analysis of singular subspaces under random perturbations.The Annals of Statistics, 54(2):667 – 691, 2026. doi: 10.1214/25-AOS2582. URLhttps://doi.org/10.1214/ 25-AOS2582. 11
- [34]
-
[35]
Zeke Xie, Issei Sato, and Masashi Sugiyama. A diffusion theory for deep learning dynamics: Stochastic gradient descent exponentially favors flat minima, 2021. URLhttps://arxiv. org/abs/2002.03495
-
[36]
Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum, 2022
Zeke Xie, Xinrui Wang, Huishuai Zhang, Issei Sato, and Masashi Sugiyama. Adaptive inertia: Disentangling the effects of adaptive learning rate and momentum, 2022. URLhttps:// arxiv.org/abs/2006.15815
-
[37]
Positive-negative momen- tum: Manipulating stochastic gradient noise to improve generalization, 2022
Zeke Xie, Li Yuan, Zhanxing Zhu, and Masashi Sugiyama. Positive-negative momen- tum: Manipulating stochastic gradient noise to improve generalization, 2022. URLhttps: //arxiv.org/abs/2103.17182
-
[38]
On the overlooked structure of stochastic gradients, 2023
Zeke Xie, Qian-Yuan Tang, Mingming Sun, and Ping Li. On the overlooked structure of stochastic gradients, 2023. URLhttps://arxiv.org/abs/2212.02083
-
[39]
Prism: Structured optimization via anisotropic spectral shaping, 2026
Yujie Yang. Prism: Structured optimization via anisotropic spectral shaping, 2026. URL https://arxiv.org/abs/2602.03096
-
[40]
Mousse: Rectifying the geometry of muon with curvature-aware precondition- ing, 2026
Yechen Zhang, Shuhao Xing, Junhao Huang, Kai Lv, Yunhua Zhou, Xipeng Qiu, Qipeng Guo, and Kai Chen. Mousse: Rectifying the geometry of muon with curvature-aware precondition- ing, 2026. URLhttps://arxiv.org/abs/2603.09697
-
[41]
Stochastic nested variance reduction for nonconvex optimization, 2020
Dongruo Zhou, Pan Xu, and Quanquan Gu. Stochastic nested variance reduction for nonconvex optimization, 2020. URLhttps://arxiv.org/abs/1806.07811
-
[42]
Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects, 2019. URLhttps://arxiv.org/abs/1803.00195. 7 Proof of Theorem 1: Sub-Gaussian Extension To establish the macroscopic ballistic ejection and dimension-resilient dynamics of t...
-
[43]
For extremely small inputsx∈(0,0.02], we haveρ (5)(x)≥483x
-
[44]
For allx∈[0.0001,0.6], the fifth iterate is strictly bounded away from zero:ρ (5)(x)> 0.03
-
[45]
Starting fromx 0 = 0.03, the fifth iterate is bounded below by0.681, entering a strictly forward-invariant setI= [0.6,1.205]. Proof of Lemma 2.Case 1: Exponential amplification of extremely small inputs. Define the strict thresholdδ 0 = 0.02 a4 ≈1.42×10 −4. Sinceb <0andc >0, the scaling functionh(x)is strictly decreasing for smallx(specifically on[0,0.6])...
work page 2052
-
[46]
Construction of the Geometric Axes (αandβ):To accurately capture the heteroskedastic nature of the non-convex landscape defined in Assumption 1, we must dynamically construct a localized 2D basis. First, we compute the exact instantaneous gradient matrixG exact and its cor- responding row/column covariance matrices by accumulating high-fidelity local grad...
-
[47]
2D Cross-Sectional Perturbation Mapping:With the basis matrices(∆W α,∆W β)established, we define a localized 2D cross-section around the frozen parameter stateWt. We systematically scan this subspace across a grid defined by parameters(α, β), where both scalars vary within the range [−1.0,1.0]. Specifically, we evaluate41×41linearly spaced discrete coordi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.