Recognition: 2 theorem links
· Lean TheoremFLAME: Adaptive Mixture-of-Experts for Continual Multimodal Multi-Task Learning
Pith reviewed 2026-05-12 04:09 UTC · model grok-4.3
The pith
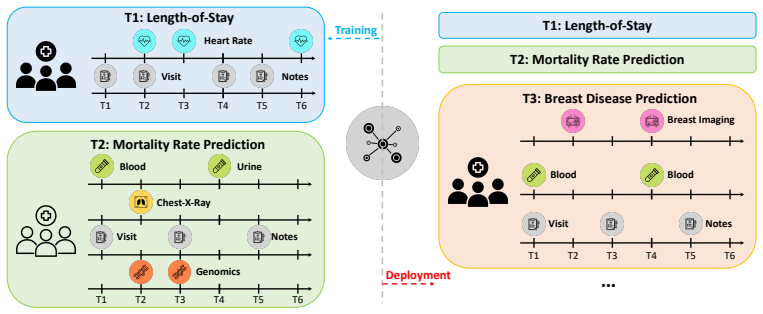
FLAME enables multimodal models to pretrain on multiple tasks jointly and then adapt to new tasks with unseen modality combinations by expanding only lightweight routers while compressing expert knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The FLAME framework supports training on multimodal tasks with diverse modality configurations by leveraging modality-specific routers that process tokens from each modality across tasks, and enables continual learning over sequential multimodal tasks within a fixed-capacity MoE by compressing accumulated expert knowledge into low-rank memory subspaces while expanding only the lightweight routers, demonstrating competitive multitask pretraining performance while alleviating catastrophic forgetting and improving parameter efficiency on healthcare multimodal benchmarks.
What carries the argument
Modality-specific routers in a sparse Mixture-of-Experts model paired with low-rank compression of accumulated expert parameters, allowing modular capacity growth without full model retraining or interference.
If this is right
- Models can jointly train on co-available multimodal tasks to borrow representational strength across related objectives.
- New tasks arriving sequentially can be incorporated by expanding only the routers while keeping the expert pool fixed.
- Parameter count grows sublinearly because expert knowledge is compressed rather than duplicated or expanded fully.
- The same architecture maintains competitive accuracy on multiple healthcare multimodal benchmarks across both pretraining and adaptation phases.
Where Pith is reading between the lines
- The same routing-plus-compression pattern could be applied to non-healthcare domains such as robotics or autonomous systems where sensor modalities evolve over time.
- If low-rank subspaces reliably capture task knowledge, then expert modules in other modular architectures may also admit efficient lifelong compression without explicit redesign.
- Testing the framework on single-modality continual learning would isolate whether modality-specific routers are necessary or whether generic routers suffice.
- This points toward lifelong-learning systems in which total parameter growth remains bounded even as the number of encountered tasks increases without limit.
Load-bearing premise
Compressing accumulated expert knowledge into low-rank memory subspaces across sequential tasks preserves performance without substantial degradation or interference between modalities.
What would settle it
A substantial rise in error rates on earlier tasks after adding new tasks with previously unseen modality combinations, even after applying the low-rank compression, would show that the method fails to alleviate catastrophic forgetting.
Figures


















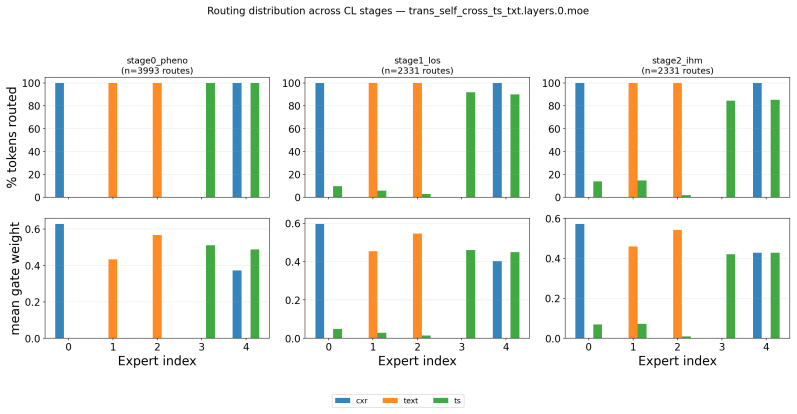
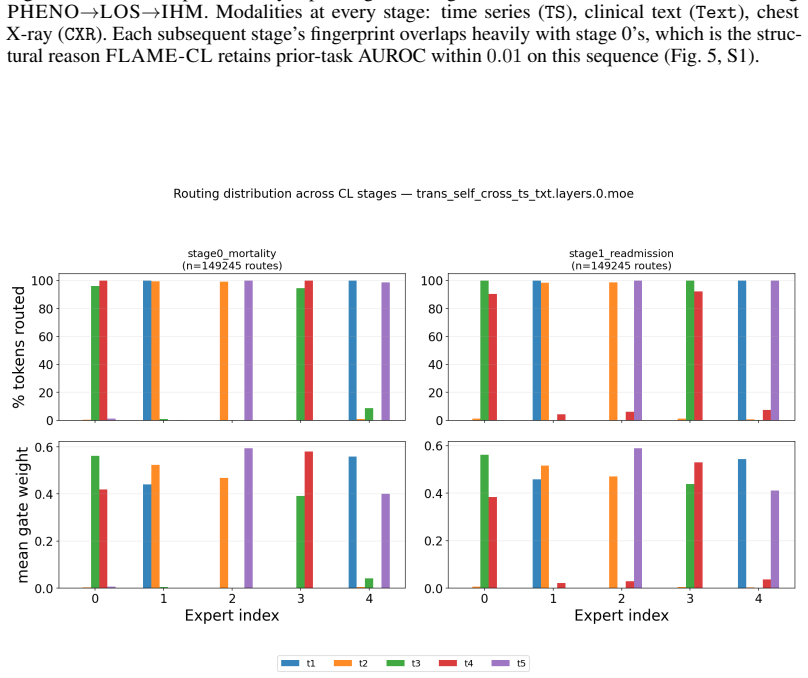
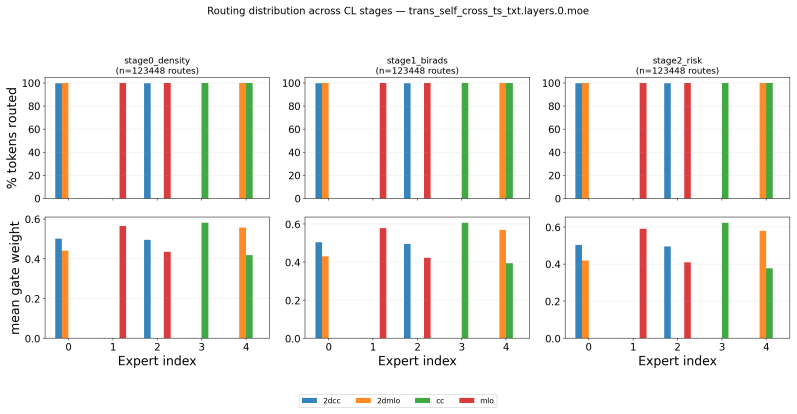
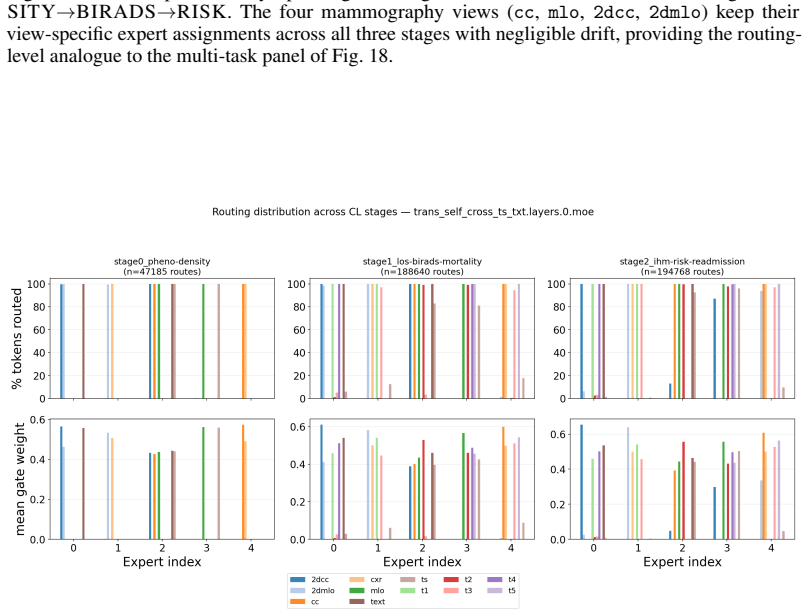
read the original abstract
Real-world model deployment across multiple domains requires multimodal models to operate under two complementary regimes: (1) multi-task pretraining, tasks are co-available at design time where related tasks could borrow representational strength from one another, (2) continual adaptation, in which new tasks emerge after deployment with previously unseen modality combinations. However, neither regime alone suffices: the pretraining task set is never exhaustive, while bypassing joint training forfeits the transfer gains and efficiency among co-trainable tasks. Sparse Mixture-of-Experts (MoE) is a natural fit for this dual requirement: sparse activation enables modular capacity expansion as new tasks arrive, while routing decouples modality-level computation from task-level composition. In this work, we propose a scalable MoE framework for multitask pretraining and continual learning across flexible modality combinations. The framework is designed to support training on multimodal tasks with diverse modality configurations by leveraging modality-specific routers that process tokens from each modality across tasks. Furthermore, it enables continual learning over sequential multimodal tasks within a fixed-capacity MoE by compressing accumulated expert knowledge into low-rank memory subspaces, while expanding only the lightweight routers. We validate the effectiveness of our method on multiple healthcare multimodal benchmarks. It demonstrates competitive multitask pretraining performance while alleviating catastrophic forgetting and improving parameter efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FLAME, a sparse Mixture-of-Experts framework for multimodal multi-task learning that supports both joint pretraining on co-available tasks and continual adaptation to new tasks with previously unseen modality combinations. Modality-specific routers process tokens from each modality, while accumulated expert knowledge is compressed into low-rank memory subspaces and only lightweight routers are expanded to maintain fixed model capacity. The approach is claimed to achieve competitive multitask pretraining performance, alleviate catastrophic forgetting, and improve parameter efficiency on multiple healthcare multimodal benchmarks.
Significance. If the low-rank compression successfully retains task- and modality-specific information without substantial cross-modal interference or performance degradation, the framework would offer a scalable solution for real-world deployment of multimodal models in dynamic domains such as healthcare. The decoupling of modality-level computation via routers and the fixed-capacity continual learning mechanism address a practical gap between exhaustive joint pretraining and naive sequential adaptation. However, the absence of any quantitative metrics, baselines, ablation studies, or validation of the low-rank approximation in the provided abstract makes it difficult to determine whether the central claims are supported.
major comments (2)
- [Abstract] Abstract: the central claims of 'competitive multitask pretraining performance' and 'alleviating catastrophic forgetting' are stated without any reported metrics (e.g., task accuracies, forgetting rates such as average accuracy drop across tasks), baselines (standard MoE, fine-tuning, or replay methods), or ablation results on the low-rank compression. This leaves the effectiveness of compressing expert knowledge into low-rank subspaces unsupported by visible evidence.
- [Abstract] Abstract: no details are provided on the low-rank compression implementation, including rank selection criterion, reconstruction error, or modality-specific interference metrics. This is load-bearing for the claim that performance is preserved across sequential tasks with varying modality combinations, as the skeptic concern notes that discarded cross-modal interactions could cause degradation even with sparse routing.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly naming the specific healthcare multimodal benchmarks used and the number of sequential tasks in the continual learning experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the practical value of FLAME in addressing continual multimodal multi-task learning. We agree that the abstract would be strengthened by incorporating key quantitative results and a brief description of the low-rank compression mechanism. We have revised the abstract to address these points and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'competitive multitask pretraining performance' and 'alleviating catastrophic forgetting' are stated without any reported metrics (e.g., task accuracies, forgetting rates such as average accuracy drop across tasks), baselines (standard MoE, fine-tuning, or replay methods), or ablation results on the low-rank compression. This leaves the effectiveness of compressing expert knowledge into low-rank subspaces unsupported by visible evidence.
Authors: We agree that the abstract would benefit from including representative quantitative evidence. The full manuscript reports experimental results on healthcare multimodal benchmarks, including comparisons against standard MoE, fine-tuning, and replay baselines, along with ablation studies on the low-rank compression and metrics such as task accuracies and forgetting rates (average accuracy drop across tasks). To make this evidence visible in the abstract, we have revised it to summarize key performance figures demonstrating competitive multitask pretraining and reduced catastrophic forgetting. revision: yes
-
Referee: [Abstract] Abstract: no details are provided on the low-rank compression implementation, including rank selection criterion, reconstruction error, or modality-specific interference metrics. This is load-bearing for the claim that performance is preserved across sequential tasks with varying modality combinations, as the skeptic concern notes that discarded cross-modal interactions could cause degradation even with sparse routing.
Authors: The full manuscript provides these implementation details in the Methods section, including the low-rank factorization approach, rank selection via explained variance threshold, reported reconstruction errors, and analysis of modality-specific interference to confirm limited cross-modal degradation. We acknowledge that a concise reference in the abstract would better address potential skeptic concerns. We have therefore revised the abstract to include a brief description of the low-rank compression process and its role in preserving performance across sequential tasks. revision: yes
Circularity Check
No circularity: architectural design choices validated on external benchmarks
full rationale
The paper proposes FLAME as a new MoE architecture for multimodal continual learning, specifying design elements such as modality-specific routers and low-rank compression of expert knowledge into memory subspaces. These are presented as engineering decisions to support multitask pretraining and sequential adaptation, not as outputs derived from equations or parameters that are fitted and then renamed as predictions. The abstract and description contain no self-referential definitions, no fitted-input predictions, and no load-bearing self-citations that reduce the central claims to tautologies. Performance is assessed via empirical results on independent healthcare multimodal benchmarks, keeping the derivation chain self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
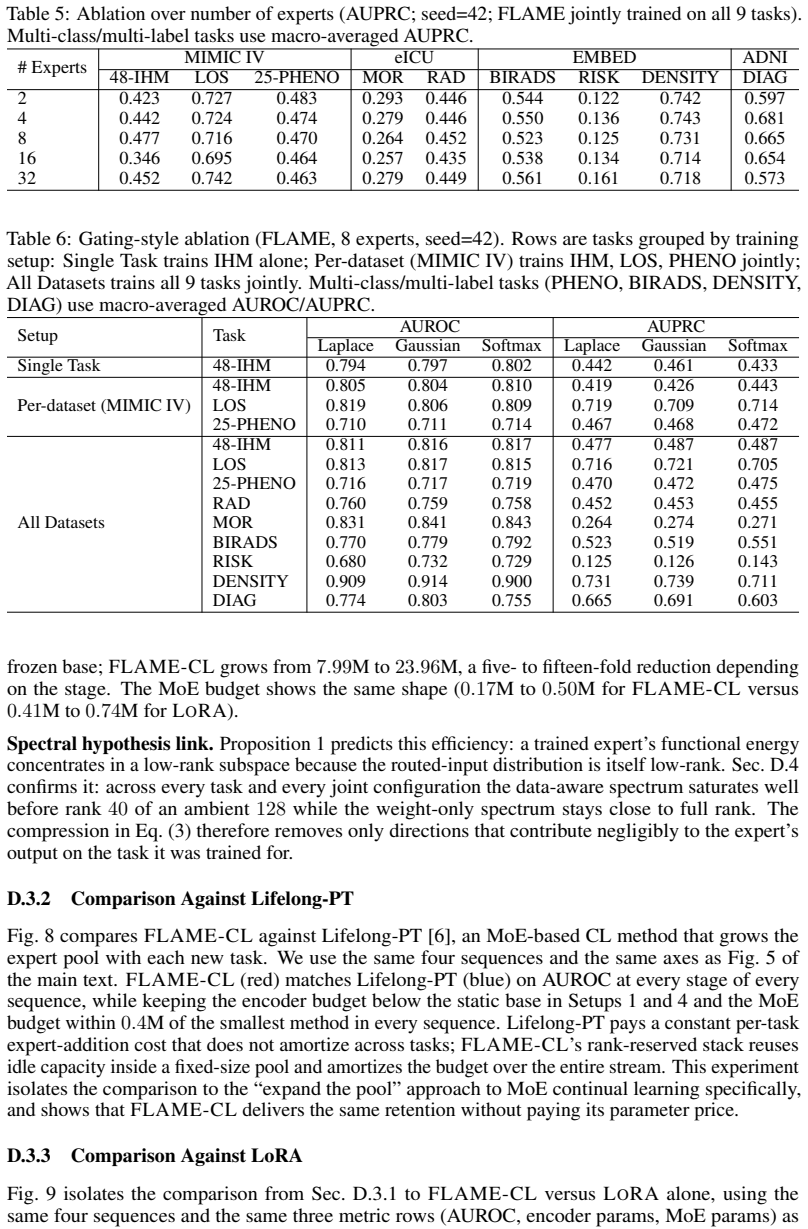
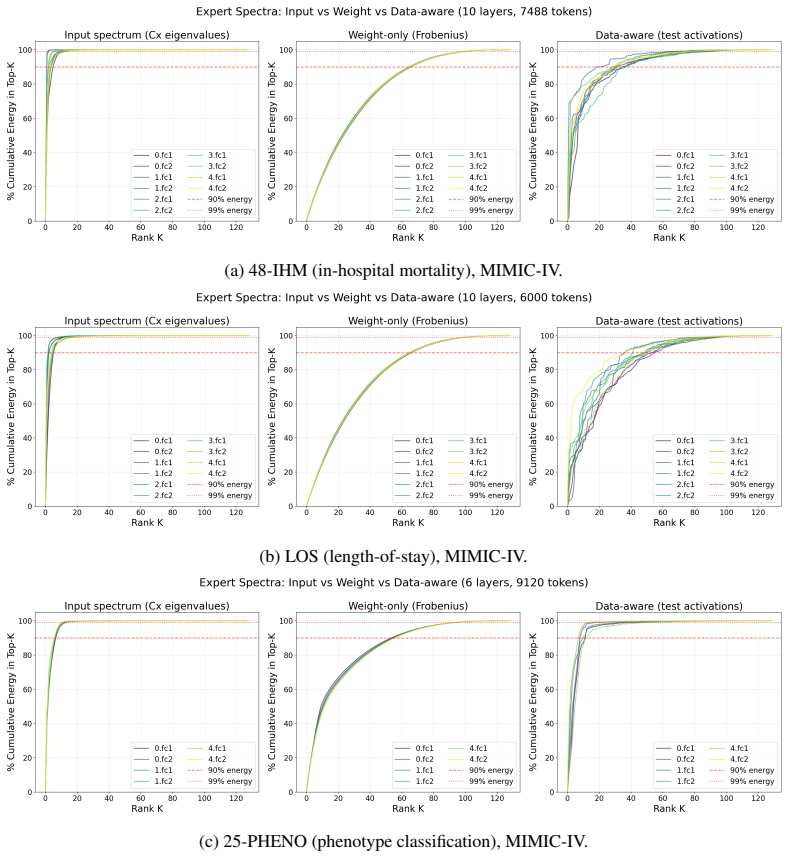
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearProposition 1: If Ci has ϵ-effective rank r∗... output Wiz is concentrated in the rank-r∗ subspace
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.11222 , year=
Pedram Akbarian, Huy Nguyen, Xing Han, and Nhat Ho. Quadratic gating mixture of experts: Statistical insights into self-attention.arXiv preprint arXiv:2410.11222, 2024
-
[2]
Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization.Advances in neural information processing systems, 32, 2019
work page 2019
-
[3]
Neural networks as kernel learners: The silent alignment effect
Alexander Atanasov, Blake Bordelon, and Cengiz Pehlevan. Neural networks as kernel learners: The silent alignment effect. InInternational Conference on Learning Representations, 2022
work page 2022
-
[4]
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learn- ing: A survey and taxonomy.IEEE transactions on pattern analysis and machine intelligence, 41(2):423–443, 2018
work page 2018
-
[5]
Multitask learning.Machine learning, 28(1):41–75, 1997
Rich Caruana. Multitask learning.Machine learning, 28(1):41–75, 1997
work page 1997
-
[6]
Lifelong language pretraining with distribution-specialized experts
Wuyang Chen, Yanqi Zhou, Nan Du, Yanping Huang, James Laudon, Zhifeng Chen, and Claire Cui. Lifelong language pretraining with distribution-specialized experts. InInternational Conference on Machine Learning, pages 5383–5395. PMLR, 2023
work page 2023
-
[7]
Chandler Davis and William M. Kahan. The rotation of eigenvectors by a perturbation. III. SIAM Journal on Numerical Analysis, 7(1):1–46, 1970
work page 1970
-
[8]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence, 44(7):3366– 3385, 2021
work page 2021
-
[9]
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012
work page 2012
-
[10]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[11]
Chris Fifty, Ehsan Amid, Zhe Zhao, Tianhe Yu, Rohan Anil, and Chelsea Finn. Efficiently identifying task groupings for multi-task learning.Advances in Neural Information Processing Systems, 34:27503–27516, 2021
work page 2021
-
[12]
Implicit regularization of discrete gradient dynamics in linear neural networks
Gauthier Gidel, Francis Bach, and Simon Lacoste-Julien. Implicit regularization of discrete gradient dynamics in linear neural networks. InAdvances in Neural Information Processing Systems, 2019
work page 2019
-
[13]
Mimic-iv-ecg: Diagnostic electrocardiogram matched subset.Type: dataset, 2023
Brian Gow, Tom Pollard, Larry A Nathanson, Alistair Johnson, Benjamin Moody, Chrystinne Fernandes, Nathaniel Greenbaum, Jonathan W Waks, Parastou Eslami, Tanner Carbonati, et al. Mimic-iv-ecg: Diagnostic electrocardiogram matched subset.Type: dataset, 2023
work page 2023
-
[14]
Suriya Gunasekar, Jason D Lee, Daniel Soudry, and Nati Srebro. Implicit bias of gradient descent on linear convolutional networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Shashank Gupta, Subhabrata Mukherjee, Krishan Subudhi, Eduardo Gonzalez, Damien Jose, Ahmed H Awadallah, and Jianfeng Gao. Sparsely activated mixture-of-experts are robust multi-task learners.arXiv preprint arXiv:2204.07689, 2022
-
[17]
Xing Han, Hsing-Huan Chung, Joydeep Ghosh, Paul Pu Liang, and Suchi Saria. Guiding mixture-of-experts with temporal multimodal interactions.arXiv preprint arXiv:2509.25678, 2025
-
[18]
Dynamic combination of heterogeneous models for hierarchical time series
Xing Han, Jing Hu, and Joydeep Ghosh. Dynamic combination of heterogeneous models for hierarchical time series. In2022 IEEE International Conference on Data Mining Workshops (ICDMW), pages 1207–1216. IEEE, 2022
work page 2022
-
[19]
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. Fusemoe: Mixture-of-experts transformers for fleximodal fusion.Advances in Neural Information Processing Systems, 37:67850–67900, 2024
work page 2024
-
[20]
Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
Hrayr Harutyunyan, Hrant Khachatrian, David C Kale, Greg Ver Steeg, and Aram Galstyan. Multitask learning and benchmarking with clinical time series data.Scientific data, 6(1):96, 2019
work page 2019
-
[21]
Ahmed Hendawy, Jan Peters, and Carlo D’Eramo. Multi-task reinforcement learning with mixture of orthogonal experts.arXiv preprint arXiv:2311.11385, 2023
-
[22]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems, 2018
work page 2018
-
[25]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021
work page 2021
-
[26]
Jiwoong J Jeong, Brianna L Vey, Ananth Bhimireddy, Thomas Kim, Thiago Santos, Ramon Correa, Raman Dutt, Marina Mosunjac, Gabriela Oprea-Ilies, Geoffrey Smith, Minjae Woo, Christopher R McAdams, Mary S Newell, Imon Banerjee, Judy Gichoya, and Hari Trivedi. The EMory BrEast imaging dataset (EMBED): A racially diverse, granular dataset of 3.4 million screeni...
work page 2023
-
[27]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mimic-cxr database.PhysioNet10, 13026(C2JT1Q):5, 2024
Alistair Johnson, Tom Pollard, Roger Mark, Seth Berkowitz, and Steven Horng. Mimic-cxr database.PhysioNet10, 13026(C2JT1Q):5, 2024
work page 2024
-
[29]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
work page 2023
-
[30]
The universal weight subspace hypothesis, 2025
Prakhar Kaushik, Shravan Chaudhari, Ankit Vaidya, Rama Chellappa, and Alan Yuille. The universal weight subspace hypothesis, 2025
work page 2025
-
[31]
Prakhar Kaushik, Ankit Vaidya, Shravan Chaudhari, and Alan Yuille. Eigenlorax: Recy- cling adapters to find principal subspaces for resource-efficient adaptation and inference. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 649–659, 2025. 11
work page 2025
-
[32]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
-
[33]
Vladimir Koltchinskii and Karim Lounici. Concentration inequalities and moment bounds for sample covariance operators.Bernoulli, 23(1):110–133, 2017
work page 2017
-
[34]
Continual learning for domain adaptation in chest x-ray classification
Matthias Lenga, Heinrich Schulz, and Axel Saalbach. Continual learning for domain adaptation in chest x-ray classification. InMedical Imaging with Deep Learning, pages 413–423. PMLR, 2020
work page 2020
-
[35]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
work page 2023
-
[36]
Theory on mixture-of- experts in continual learning.arXiv preprint arXiv:2406.16437, 2024
Hongbo Li, Sen Lin, Lingjie Duan, Yingbin Liang, and Ness B Shroff. Theory on mixture-of- experts in continual learning.arXiv preprint arXiv:2406.16437, 2024
-
[37]
Paul Pu Liang, Yiwei Lyu, Xiang Fan, Jeffrey Tsaw, Yudong Liu, Shentong Mo, Dani Yogatama, Louis-Philippe Morency, and Ruslan Salakhutdinov. High-modality multimodal transformer: Quantifying modality & interaction heterogeneity for high-modality representation learning. arXiv preprint arXiv:2203.01311, 2022
-
[38]
Inflora: Interference-free low-rank adaptation for continual learning
Yan-Shuo Liang and Wu-Jun Li. Inflora: Interference-free low-rank adaptation for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[39]
Med-flamingo: a multimodal medical few-shot learner (2023).URL: https://arxiv
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-flamingo: a multimodal medical few-shot learner (2023).URL: https://arxiv. org/abs/2307.15189, 2023
-
[40]
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multi- modal contrastive learning with limoe: the language-image mixture of experts.Advances in Neural Information Processing Systems, 35:9564–9576, 2022
work page 2022
-
[41]
Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, Andrew Y Ng, et al. Multimodal deep learning. InIcml, volume 11, pages 689–696, 2011
work page 2011
-
[42]
Huy Nguyen, Xing Han, Carl Harris, Suchi Saria, and Nhat Ho. On expert estimation in hierar- chical mixture of experts: Beyond softmax gating functions.arXiv preprint arXiv:2410.02935, 2024
-
[43]
eICU Collaborative Research Database.PhysioNet, April 2019
Tom Pollard, Alistair Johnson, Jesse Raffa, Leo Anthony Celi, Omar Badawi, and Roger Mark. eICU Collaborative Research Database.PhysioNet, April 2019. Version 2.0
work page 2019
-
[44]
The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
Nicola Rieke, Jonny Hancox, Wenqi Li, Fausto Milletari, Holger R Roth, Shadi Albarqouni, Spyridon Bakas, Mathieu N Galtier, Bennett A Landman, Klaus Maier-Hein, et al. The future of digital health with federated learning.NPJ digital medicine, 3(1):119, 2020
work page 2020
-
[45]
An Overview of Multi-Task Learning in Deep Neural Networks
Sebastian Ruder. An overview of multi-task learning in deep neural networks.arXiv preprint arXiv:1706.05098, 2017
work page internal anchor Pith review arXiv 2017
-
[46]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review arXiv 2016
-
[47]
Grzegorz Rype´s´c, Sebastian Cygert, Valeriya Khan, Tomasz Trzci´nski, Bartosz Zieli´nski, and Bartłomiej Twardowski. Divide and not forget: Ensemble of selectively trained experts in continual learning.arXiv preprint arXiv:2401.10191, 2024
-
[48]
Gradient projection memory for continual learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. InInternational Conference on Learning Representations, 2021. 12
work page 2021
-
[49]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page Pith review arXiv 2013
-
[50]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
work page 2017
-
[51]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Missing modalities imputation via cascaded residual autoencoder
Luan Tran, Xiaoming Liu, Jiayu Zhou, and Rong Jin. Missing modalities imputation via cascaded residual autoencoder. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1405–1414, 2017
work page 2017
-
[53]
Joel A. Tropp. An introduction to matrix concentration inequalities.Foundations and Trends in Machine Learning, 8(1–2):1–230, 2015
work page 2015
-
[54]
Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, and Luc Van Gool. Multi-task learning for dense prediction tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(7):3614–3633, 2021
work page 2021
-
[55]
Cambridge University Press, 2018
Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, 2018
work page 2018
-
[56]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
work page 2024
-
[57]
Multimodal learning with incomplete modalities by knowledge distillation
Qi Wang, Liang Zhan, Paul Thompson, and Jiayu Zhou. Multimodal learning with incomplete modalities by knowledge distillation. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1828–1838, 2020
work page 2020
-
[58]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. Orthogonal subspace learning for language model continual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, 2023
work page 2023
-
[59]
Michael W Weiner, Dallas P Veitch, Paul S Aisen, Laurel A Beckett, Nigel J Cairns, Robert C Green, Danielle Harvey, Clifford R Jack, Jr, William Jagust, John C Morris, Ronald C Petersen, Jennifer Salazar, Andrew J Saykin, Leslie M Shaw, Arthur W Toga, John Q Trojanowski, and Alzheimer’s Disease Neuroimaging Initiative. The alzheimer’s disease neuroimaging...
work page 2016
-
[60]
Dynamic modeling of patients, modalities and tasks via multi-modal multi-task mixture of experts
Chenwei Wu, Zitao Shuai, Zhengxu Tang, Luning Wang, and Liyue Shen. Dynamic modeling of patients, modalities and tasks via multi-modal multi-task mixture of experts. InThe thirteenth international conference on learning representations, 2025
work page 2025
-
[61]
Multimodal learning with transformers: A survey
Peng Xu, Xiatian Zhu, and David A Clifton. Multimodal learning with transformers: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12113–12132, 2023
work page 2023
-
[62]
Moral: Moe augmented lora for llms’ lifelong learning.arXiv preprint arXiv:2402.11260, 2024
Shu Yang, Muhammad Asif Ali, Cheng-Long Wang, Lijie Hu, and Di Wang. Moral: Moe augmented lora for llms’ lifelong learning.arXiv preprint arXiv:2402.11260, 2024
-
[63]
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, et al. Unleashing the power of multi-task learning: A comprehensive survey spanning traditional, deep, and pretrained foundation model eras.arXiv preprint arXiv:2404.18961, 2024
- [64]
-
[65]
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts.Advances in Neural Information Processing Systems, 37:98782– 98805, 2024
work page 2024
-
[66]
FLAME: Adaptive Mixture-of-Experts for Continual Multimodal Multi-Task Learning
Yu Zhang and Qiang Yang. A survey on multi-task learning.IEEE transactions on knowledge and data engineering, 34(12):5586–5609, 2021. 14 Supplementary Material for “FLAME: Adaptive Mixture-of-Experts for Continual Multimodal Multi-Task Learning” Appendix Contents •A.Extended Related Works •B.Proof of Proposition 1 •C.Dataset Details •D.Additional Experime...
work page 2021
-
[67]
couples MoE with LoRA, using low-rank adapters as experts so that lifelong adaptation of LLMs can be achieved with minimal trainable parameters. SEED [47] tackles class-incremental learning by maintaining a fixed-size expert ensemble and selectively fine-tuning only the single expert whose distributions overlap least with the new task. Despite these advan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.