Recognition: 2 theorem links
· Lean TheoremFunction-Space ADMM for Decentralized Federated Learning: A Control Theoretic Perspective
Pith reviewed 2026-05-12 04:03 UTC · model grok-4.3
The pith
Optimizing loss in function space enables faster and more stable decentralized federated learning than parameter-space methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FedF-ADMM exploits the convexity of loss functionals in function space to derive ADMM-based update directions, projects them onto the parameter space via knowledge distillation, and incorporates a stabilization coefficient analyzed as a PI term to achieve faster and more stable convergence in non-IID decentralized federated learning.
What carries the argument
The ADMM updates in function space projected to parameters via knowledge distillation, with a stabilization coefficient providing PI-like control for robustness.
If this is right
- Decentralized systems without central servers can train models effectively even when each device holds data from only a single label.
- The control-theoretic view of the stabilization coefficient suggests ways to tune it for different network conditions.
- Knowledge distillation acts as a reliable interface between convex function-space optimization and practical neural network parameters.
- Overall consensus among devices improves alongside individual accuracy.
Where Pith is reading between the lines
- Extending this function-space approach could apply to other distributed optimization problems involving non-convex losses by using similar projections.
- Testing the method on larger networks or different model architectures would reveal its scalability limits.
- Integrating adaptive control strategies based on this PI interpretation might further enhance performance in dynamic environments.
Load-bearing premise
The loss functionals are convex in function space and the knowledge distillation projection does not degrade the ADMM update directions significantly.
What would settle it
Demonstrating that the projected updates fail to converge or that the stabilization coefficient causes instability in a standard non-IID FL benchmark would disprove the method's effectiveness.
Figures











read the original abstract
Decentralized federated learning (FL) is a promising approach for training machine learning models on sensor networks, Internet of Things (IoT) devices, and other edge systems where no central server exists. While federated learning offers advantages such as preserving data privacy, it often suffers from non-independent and identically distributed (IID) data distributions across devices, which cause significant performance degradation. This issue is particularly severe when directly optimizing model parameters, because neural network training is inherently non-convex and standard convergence guarantees for convex optimization do not apply. Unlike existing decentralized FL methods that primarily operate in parameter space, we propose federated function-space alternating direction method of multipliers (FedF-ADMM). FedF-ADMM exploits the convexity of loss functionals within function space to derive alternating direction method of multipliers (ADMM)-based update directions, which are subsequently projected onto the parameter space via knowledge distillation. We further introduce a stabilization coefficient to enhance robustness under severe non-IID settings and analyze its behavior from a control-theoretic perspective by interpreting it as a proportional-integral (PI) term. Experiments under challenging non-IID scenarios, including settings where each device has data from only a single label, demonstrate that FedF-ADMM achieves faster and more stable convergence than existing decentralized FL methods, while attaining higher accuracy and better consensus among devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedF-ADMM, a decentralized federated learning method that exploits convexity of loss functionals in function space to derive ADMM-based update directions. These directions are projected onto neural network parameter space via knowledge distillation. A stabilization coefficient is introduced and analyzed from a control-theoretic perspective as a proportional-integral (PI) controller. Experiments on challenging non-IID scenarios, including single-label-per-device partitions, claim faster and more stable convergence, higher accuracy, and improved consensus relative to existing decentralized FL methods.
Significance. If the central claims hold, the work offers a novel function-space perspective on decentralized FL that could improve robustness to extreme data heterogeneity on edge devices. The control-theoretic framing of the stabilization term provides a useful bridge between optimization and feedback control, with potential to inspire hybrid methods. The focus on single-label non-IID settings adds practical relevance for real-world IoT deployments.
major comments (2)
- [Abstract] Abstract: The claim that function-space ADMM updates can be projected onto parameter space via knowledge distillation without losing effectiveness is load-bearing for all convergence and consensus assertions. No analysis is supplied showing that the non-convex KD regression approximates the prescribed function-space direction, particularly when devices hold disjoint single-label data and local targets differ sharply; misalignment here directly threatens the consensus property ADMM is intended to enforce.
- [Method section (control-theoretic analysis)] Method section (control-theoretic analysis): The PI-controller interpretation of the stabilization coefficient is presented as post-hoc analysis rather than a core derivation. No equations demonstrate that the realized parameter-space updates continue to obey the linear structure assumed in the function-space derivation after the KD projection step, rendering the control-theoretic claims unsupported.
minor comments (2)
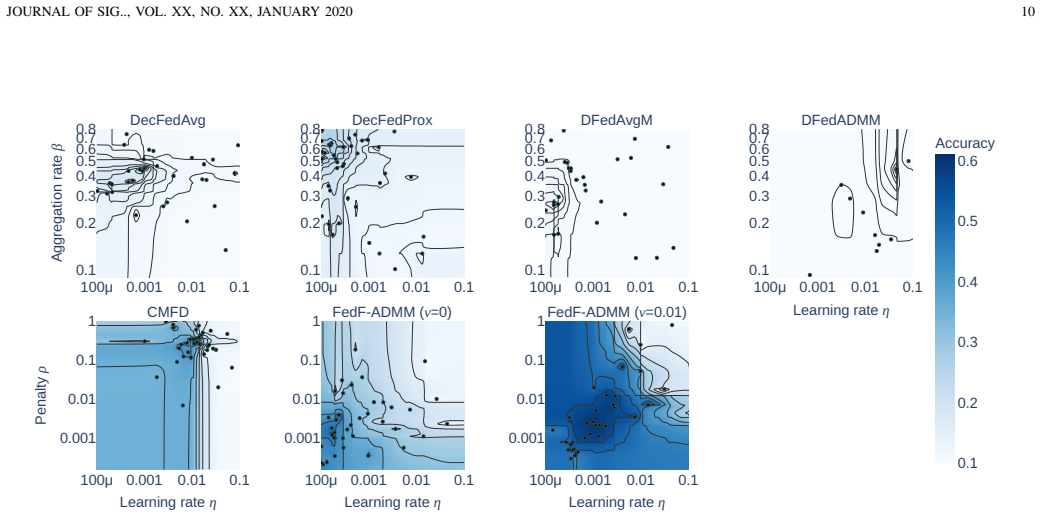
- [Abstract and experiments section] Abstract and experiments section: No error bars, statistical significance tests, or explicit list of baselines and hyperparameter settings are mentioned, which weakens the ability to assess the reported gains in convergence speed and accuracy.
- [Notation] Notation: The definition and update rule for the stabilization coefficient would benefit from an explicit equation reference to clarify its role in the ADMM iterations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each of the major comments in detail below, proposing revisions to address the concerns raised regarding the theoretical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that function-space ADMM updates can be projected onto parameter space via knowledge distillation without losing effectiveness is load-bearing for all convergence and consensus assertions. No analysis is supplied showing that the non-convex KD regression approximates the prescribed function-space direction, particularly when devices hold disjoint single-label data and local targets differ sharply; misalignment here directly threatens the consensus property ADMM is intended to enforce.
Authors: We agree that a formal analysis of the approximation quality of the knowledge distillation projection is absent from the manuscript, and this represents a limitation in rigorously justifying the consensus properties. The paper relies on empirical validation through experiments on single-label non-IID partitions, where FedF-ADMM shows superior performance. In revision, we will add a new subsection discussing the potential for misalignment in the projection step and its implications for ADMM's consensus guarantee. We will also include quantitative measurements of the function-space error in the experiments section to provide better support for the claims. The abstract will be revised to emphasize the empirical nature of the results. revision: yes
-
Referee: [Method section (control-theoretic analysis)] Method section (control-theoretic analysis): The PI-controller interpretation of the stabilization coefficient is presented as post-hoc analysis rather than a core derivation. No equations demonstrate that the realized parameter-space updates continue to obey the linear structure assumed in the function-space derivation after the KD projection step, rendering the control-theoretic claims unsupported.
Authors: The control-theoretic analysis is presented as an interpretive framework to motivate the choice of the stabilization coefficient, drawing an analogy to PI controllers for stability. We acknowledge that no explicit equations are provided showing preservation of the linear update structure post-KD projection. This is because the projection is nonlinear. We will revise the relevant section to make this post-hoc nature explicit and to clarify the assumptions under which the analogy holds approximately. We will also add a remark on the limitations of the control-theoretic view in the parameter space. revision: partial
Circularity Check
No significant circularity; derivation uses external convexity assumption and separate projection step
full rationale
The paper derives ADMM updates from the convexity of loss functionals in function space (an external mathematical property), then applies knowledge distillation as a projection to parameter space. The stabilization coefficient is introduced for robustness and given a post-hoc PI-controller interpretation from control theory, but this analysis does not feed back into the derivation or force any result by construction. No equations reduce the claimed convergence or consensus properties to fitted inputs, self-citations, or renamed empirical patterns. Experiments provide independent validation under non-IID conditions rather than tautological confirmation. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- stabilization coefficient
axioms (1)
- domain assumption Loss functionals are convex within function space
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FedF-ADMM exploits the convexity of loss functionals within function space to derive ADMM-based update directions, which are subsequently projected onto the parameter space via knowledge distillation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProc. 20th Int. Conf. Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, Apr. 2017, pp. 1273–1282
work page 2017
-
[2]
E. T. M. Beltrán, M. Q. Pérez, P. M. S. Sánchez, S. L. Bernal, G. Bovet, M. G. Pérez, G. M. Pérez, and A. H. Celdrán, “Decentralized federated learning: Fundamentals, state-of-the-art, frameworks, trends, and challenges,”IEEE Commun. Surveys Tuts., vol. 25, no. 4, pp. 2983– 3013, 2023
work page 2023
-
[3]
IPLS: A framework for decentralized federated learning,
C. Pappas, D. Chatzopoulos, S. Lalis, and M. Vavalis, “IPLS: A framework for decentralized federated learning,” inProc. 2021 IFIP Networking Conference (IFIP Networking), Jun. 2021, pp. 1–6
work page 2021
-
[4]
Decentralized federated learning of deep neural networks on non-IID data,
N. Onoszko, G. Karlsson, O. Mogren, and E. L. Zec, “Decentralized federated learning of deep neural networks on non-IID data,”arXiv preprint arXiv:2107.08517 [cs.LG], 2021
-
[5]
Enhancing decentralized federated learning for non-IID data on heterogeneous devices,
M. Chen, Y . Xu, H. Xu, and L. Huang, “Enhancing decentralized federated learning for non-IID data on heterogeneous devices,” inProc. 2023 IEEE 39th International Conference on Data Engineering (ICDE). Anaheim, CA, USA: IEEE, Apr. 2023, pp. 2289–2302
work page 2023
-
[6]
Decentralized and model-free federated learning: Consensus-based distillation in function space,
A. Taya, T. Nishio, M. Morikura, and K. Yamamoto, “Decentralized and model-free federated learning: Consensus-based distillation in function space,”IEEE Trans. Signal Inf. Process. Netw., vol. 8, pp. 799–814, Sep. 2022
work page 2022
-
[7]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent,” inProc. 31st Conf. Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 5330–5340
work page 2017
-
[8]
Peer-to-peer federated learning on graphs,
A. Lalitha, O. C. Kilinc, T. Javidi, and F. Koushanfar, “Peer-to-peer federated learning on graphs,”arXiv preprint arXiv:1901.11173, Jan. 2019
-
[9]
Federated learning with cooper- ating devices: A consensus approach for massive IoT networks,
S. Savazzi, M. Nicoli, and V . Rampa, “Federated learning with cooper- ating devices: A consensus approach for massive IoT networks,”IEEE Internet Things J., vol. 7, no. 5, pp. 4641–4654, May 2020
work page 2020
-
[10]
Network-density-controlled de- centralized parallel stochastic gradient descent in wireless systems,
K. Sato, Y . Satoh, and D. Sugimura, “Network-density-controlled de- centralized parallel stochastic gradient descent in wireless systems,” in Proc. IEEE Int. Conf. Commun. (ICC), Virtual Conference, Jun. 2020
work page 2020
-
[11]
Decentralized federated averaging,
T. Sun, D. Li, and B. Wang, “Decentralized federated averaging,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 4, pp. 4289–4301, 2023
work page 2023
-
[12]
Collaborative deep learning in fixed topology networks,
Z. Jiang, A. Balu, C. Hegde, and S. Sarkar, “Collaborative deep learning in fixed topology networks,” inProc. 31st Conf. Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, Dec. 2017, pp. 1–11
work page 2017
-
[13]
D- ADMM: A communication-efficient distributed algorithm for separable optimization,
J. F. C. Mota, J. M. F. Xavier, P. M. Q. Aguiar, and M. Püschel, “D- ADMM: A communication-efficient distributed algorithm for separable optimization,”IEEE Trans. Signal Process., vol. 61, no. 10, pp. 2718– 2723, 2013. JOURNAL OF SIG.., VOL. XX, NO. XX, JANUARY 2020 15
work page 2013
-
[14]
Communication-efficient ADMM-based distributed algorithms for sparse training,
G. Wang, Y . Lei, Y . Qiu, L. Lou, and Y . Li, “Communication-efficient ADMM-based distributed algorithms for sparse training,”Neurocomput- ing, vol. 550, p. 126456, 2023
work page 2023
-
[15]
Edge-consensus learning: Deep learning on P2P networks with nonhomogeneous data,
K. Niwa, N. Harada, G. Zhang, and W. B. Kleijn, “Edge-consensus learning: Deep learning on P2P networks with nonhomogeneous data,” inProc. 26th ACM SIGKDD Int. Conf. Knowledge Discovery & Data Mining, Virtual Conference, Aug. 2020, pp. 668–678
work page 2020
-
[16]
DFedADMM: Dual constraint controlled model inconsistency for decentralize federated learning,
Q. Li, L. Shen, G. Li, Q. Yin, and D. Tao, “DFedADMM: Dual constraint controlled model inconsistency for decentralize federated learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 6, pp. 4803–4815, 2025
work page 2025
-
[17]
Federated learning via inexact ADMM,
S. Zhou and G. Y . Li, “Federated learning via inexact ADMM,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 8, pp. 9699–9708, 2023
work page 2023
-
[18]
An inexact accelerated stochastic ADMM for separable convex optimization,
J. Bai, W. W. Hager, and H. Zhang, “An inexact accelerated stochastic ADMM for separable convex optimization,”Computational Optimiza- tion and Applications, vol. 81, no. 2, pp. 479–518, 2022
work page 2022
-
[19]
An inexact ADMM for separable nonconvex and nonsmooth optimization,
J. Bai, M. Zhang, and H. Zhang, “An inexact ADMM for separable nonconvex and nonsmooth optimization,”Computational Optimization and Applications, pp. 1–35, 2025
work page 2025
-
[20]
Linearized ADMM for nonconvex non- smooth optimization with convergence analysis,
Q. Liu, X. Shen, and Y . Gu, “Linearized ADMM for nonconvex non- smooth optimization with convergence analysis,”IEEE Access, vol. 7, pp. 76 131–76 144, 2019
work page 2019
-
[21]
Knowledge distillation in federated learning: a practical guide,
A. Mora, I. Tenison, P. Bellavista, and I. Rish, “Knowledge distillation in federated learning: a practical guide,” inProc. 33rd International Joint Conference on Artificial Intelligence, Jeju, Korea, Aug. 2024, pp. 8188–8196
work page 2024
-
[22]
arXiv preprint arXiv:1804.03235 , year=
R. Anil, G. Pereyra, A. Passos, R. Ormandi, G. E. Dahl, and G. E. Hinton, “Large scale distributed neural network training through online distillation,”arXiv preprint arXiv:1804.03235, Apr. 2018
-
[23]
Y . Zhang, T. Xiang, T. M. Hospedales, and H. Lu, “Deep mutual learning,” inProc. 2018 IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR). IEEE, 2018, pp. 4320–4328
work page 2018
-
[24]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv:1503.02531 [stat.ML], 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
E. Jeong, S. Oh, H. Kim, J. Park, M. Bennis, and S.-L. Kim, “Communication-efficient on-device machine learning: Federated dis- tillation and augmentation under non-IID private data,”arXiv preprint arXiv:1811.11479, Nov. 2018
-
[26]
Multi-hop federated private data augmentation with sample compression,
E. Jeong, S. Oh, J. Park, H. Kim, M. Bennis, and S.-L. Kim, “Multi-hop federated private data augmentation with sample compression,”arXiv preprint arXiv:1907.06426, Jul. 2019
-
[27]
S. Itahara, T. Nishio, Y . Koda, M. Morikura, and K. Ya- mamoto, “Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-IID private data,”IEEE Trans. Mobile Comput., vol. 22, no. 1, pp. 191–205, Mar. 2021
work page 2021
-
[28]
Cronus: Ro- bust and heterogeneous collaborative learning with black-box knowledge transfer,
H. Chang, V . Shejwalkar, R. Shokri, and A. Houmansadr, “Cronus: Ro- bust and heterogeneous collaborative learning with black-box knowledge transfer,”arXiv preprint arXiv:1912.11279, Dec. 2019
-
[29]
Fedmd: Heterogenous federated learning via model distillation,
D. Li and J. Wang, “FedMD: Heterogenous federated learning via model distillation,”arXiv preprint arXiv:1910.03581, Oct. 2019
-
[30]
Ensemble distillation for robust model fusion in federated learning,
T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” inProc. 33rd Conf. Neural Information Processing Systems (NeurIPS), vol. 33, Virtual Conference, Dec. 2020, pp. 2351–2363
work page 2020
-
[31]
G. Gad, E. Gad, Z. M. Fadlullah, M. M. Fouda, and N. Kato, “Communication-efficient and privacy-preserving federated learning via joint knowledge distillation and differential privacy in bandwidth- constrained networks,”IEEE Trans. Veh. Technol., vol. 73, no. 11, pp. 17 586–17 601, 2024
work page 2024
-
[32]
G. Sun, H. Shu, F. Shao, T. Racharak, W. Kong, Y . Pan, J. Dong, S. Wang, L.-M. Nguyen, and J. Xin, “FKD-Med: privacy-aware, communication-optimized medical image segmentation via federated learning and model lightweighting through knowledge distillation,”IEEE Access, vol. 12, pp. 33 687–33 704, 2024
work page 2024
-
[33]
H. Li, G. Chen, B. Wang, Z. Chen, Y . Zhu, F. Hu, J. Dai, and W. Wang, “PFedKD: Personalized federated learning via knowledge distillation using unlabeled pseudo data for Internet of Things,”IEEE Internet of Things Journal, vol. 12, no. 11, pp. 16 314–16 324, 2025
work page 2025
-
[34]
B. Soltani, V . Haghighi, Y . Zhou, Q. Z. Sheng, and L. Yao, “DFLStar: A decentralized federated learning framework with self-knowledge distil- lation and participant selection,” inProc. of the 33rd ACM International Conference on Information and Knowledge Management, ser. CIKM ’24, Boise, ID, USA, Oct. 2024, pp. 2108–2117
work page 2024
-
[35]
W. Yang, Y . Liu, X. Leng, H. Gu, G. Jiang, X. Yu, and X. Cao, “DFUN- KDF: Efficient and robust decentralized federated framework for UA V networks via knowledge distillation and filtering,”Communications in Transportation Research, vol. 5, p. 100173, 2025
work page 2025
-
[36]
Federated learning with differential pri- vacy: Algorithms and performance analysis,
K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, S. Jin, T. Q. S. Quek, and H. Vincent Poor, “Federated learning with differential pri- vacy: Algorithms and performance analysis,”IEEE Trans. Inf. Forensics Security, vol. 15, pp. 3454–3469, 2020
work page 2020
-
[37]
Clustered federated learning with adaptive local differential privacy on heterogeneous IoT data,
Z. He, L. Wang, and Z. Cai, “Clustered federated learning with adaptive local differential privacy on heterogeneous IoT data,”IEEE Internet Things J., vol. 11, no. 1, pp. 137–146, 2024
work page 2024
-
[38]
A framework for privacy-preserving in IoV using federated learning with differential privacy,
M. Adnan, M. H. Syed, A. Anjum, and S. Rehman, “A framework for privacy-preserving in IoV using federated learning with differential privacy,”IEEE Access, vol. 13, pp. 13 507–13 521, 2025
work page 2025
-
[39]
Data-free knowledge distillation for het- erogeneous federated learning,
Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for het- erogeneous federated learning,” inProc. 38th International Conference on Machine Learning, vol. 139, Jul. 2021, pp. 12 878–12 889
work page 2021
-
[40]
J. Zhang, C. Shan, and J. Han, “FedGMKD: An efficient prototype feder- ated learning framework through knowledge distillation and discrepancy- aware aggregation,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 118 326–118 356
work page 2024
-
[41]
Fine-tuning global model via data-free knowledge distillation for non-IID federated learning,
L. Zhang, L. Shen, L. Ding, D. Tao, and L.-Y . Duan, “Fine-tuning global model via data-free knowledge distillation for non-IID federated learning,” inProc. 2022 IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022, pp. 10 164–10 173
work page 2022
-
[42]
Extending control theory into federated learning data heterogeneity problem,
O. Mashaal, S. Baadel, and H. AbouZied, “Extending control theory into federated learning data heterogeneity problem,” in2024 IEEE International Conference on Artificial Intelligence and Mechatronics Systems (AIMS). Bandung, Indonesia: IEEE, Feb. 2024, pp. 1–4
work page 2024
-
[43]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProc. 37th International Conference on Machine Learning. Virtual Conference: PMLR, July 2020, pp. 5132–5143
work page 2020
-
[44]
Fed-PID: An adaptive learning rate scheduler for federated learning with PID controllers,
S. Li, M. Dai, S. Kianoush, A. Minora, and S. Savazzi, “Fed-PID: An adaptive learning rate scheduler for federated learning with PID controllers,”IEEE Trans. Cogn. Commun. Netw., pp. 1–13, 2025
work page 2025
-
[45]
FedADT: An adaptive method based on derivative term for federated learning,
H. Gao, Q. Wu, X. Zhao, J. Zhu, and M. Zhang, “FedADT: An adaptive method based on derivative term for federated learning,”Sensors, vol. 23, no. 13, p. 6034, 2023
work page 2023
-
[46]
FedPIDAvg: A PID controller inspired aggregation method for federated learning,
L. Mächler, I. Ezhov, S. Shit, and J. C. Paetzold, “FedPIDAvg: A PID controller inspired aggregation method for federated learning,” in Proc. Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: 8th International Workshop, BrainLes 2022, Held in Conjunction with MICCAI 2022. Singapore: Springer, Sep. 2022, pp. 209–217
work page 2022
-
[47]
Federated learning for collaborative controller design of connected and autonomous vehicles,
T. Zeng, O. Semiari, M. Chen, W. Saad, and M. Bennis, “Federated learning for collaborative controller design of connected and autonomous vehicles,” in60th IEEE Conference on Decision and Control (CDC). Austin, TX, USA: IEEE, Dec. 2021, pp. 5033–5038
work page 2021
-
[48]
Advances and open problems in federated learning,
P. Kairouzet al., “Advances and open problems in federated learning,” Foundations and Trends® in Machine Learning, vol. 14, no. 1–2, pp. 1–210, Jun. 2021
work page 2021
-
[49]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProc. Machine Learning and Systems, I. Dhillon, D. Papailiopoulos, and V . Sze, Eds., vol. 2, 2020, pp. 429–450
work page 2020
-
[50]
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Ecksteinet al., “Distributed optimization and statistical learning via the alternating direction method of multipliers,”Foundations and Trends® in Machine learning, vol. 3, no. 1, pp. 1–122, 2011
work page 2011
-
[51]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” inProc. the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19, Anchorage, AK, USA, Jul. 2019, pp. 2623–2631. JOURNAL OF SIG.., VOL. XX, NO. XX, JANUARY 2020 16 Akihito Tayareceived the B.E. degr...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.