Recognition: no theorem link
Split CNN Inference on Networked Microcontrollers
Pith reviewed 2026-05-12 02:14 UTC · model grok-4.3
The pith
Splitting CNN inference at kernel and neuron level across networked microcontrollers reduces per-device memory use enough to run models too large for any single MCU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reinterpreting pre-trained CNN models to support kernel-wise and neuron-wise partitioning, the approach distributes both model parameters and intermediate activations across multiple MCUs. A lightweight resource-aware coordinator orchestrates the split inference on heterogeneous devices, enabling execution of networks such as MobileNetV2 that exceed the memory of any individual MCU while preserving practical end-to-end latency.
What carries the argument
The sub-layer partitioning scheme that performs kernel-wise and neuron-wise splits of both parameters and activations, orchestrated by a lightweight resource-aware coordinator across heterogeneous MCUs.
If this is right
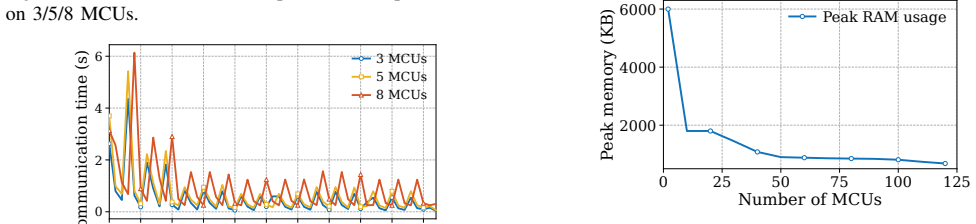
- CNN models that exceed the RAM of any single MCU become executable by sharing load across devices.
- Peak RAM usage on each participating MCU drops because activations and weights are distributed.
- End-to-end latency stays practical on real hardware for models such as MobileNetV2.
- The system adapts to heterogeneous MCU resources through the coordinator's assignment decisions.
Where Pith is reading between the lines
- The same fine-grained split could be tested on recurrent or transformer models to check whether the memory relief generalizes beyond CNNs.
- In sensor networks where MCUs are already placed at different locations, the approach would allow local collaborative computation instead of shipping all data to a central node.
- Wireless communication costs in real deployments could be measured by varying packet sizes and distances to quantify scalability limits.
Load-bearing premise
The coordinator and inter-device communication add so little overhead that total inference latency remains practical and the splits cause no meaningful accuracy drop.
What would settle it
Measuring the full pipeline on the eight-MCU testbed and finding either total latency above acceptable real-time thresholds or accuracy noticeably below the original model's level would show the method does not deliver the claimed practical benefit.
Figures








read the original abstract
Running deep neural networks on microcontroller units (MCUs) is severely constrained by limited memory resources. While TinyML techniques reduce model size and computation, they often fail in practice due to excessive peak Random Access Memory (RAM) usage during inference, dominated by intermediate activations. As a result, many models remain infeasible on standalone MCUs. In this work, we present a fine-grained split inference system for networked MCUs that enables collaborative inference of Convolutional Neural Networks (CNN) models across multiple devices. Our key insight is that breaking the memory bottleneck requires splitting inference at sub-layer granularity rather than at layer boundaries. We reinterpret pre-trained models to enable kernel-wise and neuron-wise partitioning, and distribute both model parameters and intermediate activations across multiple MCUs. A lightweight, resource-aware coordinator orchestrates the inference across MCU devices with heterogeneous resources. We implement the proposed system on a real testbed and evaluate it on up to 8 MCUs using MobileNetV2, a representative CNN model. Our experimental results show that CNN models infeasible on a single MCU can be executed across networked MCUs, reducing the per-MCU peak RAM usage while maintaining the practical end-to-end inference latency. All the source code of this work can be found here: https://github.com/shashsuresh/split-inference-on-MCUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a fine-grained split inference system for CNNs on networked MCUs. It reinterprets pre-trained models to support kernel-wise and neuron-wise partitioning, distributing both parameters and activations across devices. A lightweight resource-aware coordinator orchestrates execution on heterogeneous MCUs. The approach is implemented and evaluated on a real testbed with MobileNetV2 across up to 8 MCUs, claiming that models infeasible on a single MCU can run with reduced per-MCU peak RAM while preserving practical end-to-end latency.
Significance. If the experimental claims are substantiated, the work has clear significance for TinyML and distributed embedded systems: it directly tackles the activation-memory bottleneck that prevents many CNNs from running on standalone MCUs. The real testbed implementation, use of a representative model (MobileNetV2), and open-source code release are concrete strengths that support reproducibility and practical adoption.
major comments (1)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that sub-layer splitting reduces peak RAM while maintaining latency and without significant accuracy loss is supported only by high-level statements. No quantitative numbers are provided for accuracy preservation, communication overhead, or error bars on the reported latency/RAM figures. These metrics are load-bearing for verifying that the coordinator and network orchestration do not undermine the practical feasibility asserted in the abstract.
Simulated Author's Rebuttal
We appreciate the referee's recognition of the potential impact of our fine-grained split inference system for TinyML applications. We address the major comment as follows.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that sub-layer splitting reduces peak RAM while maintaining latency and without significant accuracy loss is supported only by high-level statements. No quantitative numbers are provided for accuracy preservation, communication overhead, or error bars on the reported latency/RAM figures. These metrics are load-bearing for verifying that the coordinator and network orchestration do not undermine the practical feasibility asserted in the abstract.
Authors: We acknowledge that the current version of the abstract and the evaluation section present the results in a high-level manner without specific quantitative values. This is a valid point, and we will revise the manuscript to include detailed quantitative metrics. Specifically, we will add the accuracy of the split inference (compared to the baseline model), the communication overhead incurred by the network orchestration, and error bars (e.g., standard deviation from repeated measurements) for the latency and peak RAM usage figures. These additions will substantiate the claims regarding reduced per-MCU RAM and maintained latency. revision: yes
Circularity Check
No significant circularity; derivation is implementation-driven
full rationale
The manuscript describes a concrete system for sub-layer CNN partitioning across MCUs, with kernel-wise and neuron-wise splits, a resource-aware coordinator, and direct testbed measurements on MobileNetV2. No load-bearing step reduces to a fitted parameter renamed as prediction, a self-definitional equation, or a self-citation chain that substitutes for independent evidence. The approach rests on reinterpretation of existing pre-trained models plus experimental validation, which is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work as the sole justification.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Network communication between MCUs has sufficiently low latency and bandwidth to support practical end-to-end inference
- domain assumption Reinterpreting pre-trained CNN models for kernel-wise and neuron-wise partitioning preserves model accuracy
Reference graph
Works this paper leans on
-
[1]
MCU vendors broaden of- ferings as Edge AI push intensifies,
Electronics Sourcing, “MCU vendors broaden of- ferings as Edge AI push intensifies,” 2025. [Online]. Available: https://electronics-sourcing.com/2025/05/16/ mcu-vendors-broaden-offerings-as-edge-ai-push-intensifies/
work page 2025
-
[2]
Quantization and training of neural networks for effi- cient integer-arithmetic-only inference,
B. Jacobet al., “Quantization and training of neural networks for effi- cient integer-arithmetic-only inference,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[3]
Xnor-net: Imagenet classification using binary convolutional neural networks,
M. Rastegari, V . Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proc. European Conference on Computer Vision (ECCV), 2016
work page 2016
-
[4]
Post training 4-bit quantization of convolutional networks for rapid-deployment,
R. Banner, Y . Nahshan, and D. Soudry, “Post training 4-bit quantization of convolutional networks for rapid-deployment,” inProc. Advances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[5]
Affinequant: Affine transformation quantization for large language models,
Y . Maet al., “Affinequant: Affine transformation quantization for large language models,” inProc. International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[6]
S. Hanet al., “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” inProc. International Conference on Learning Representations (ICLR), 2016
work page 2016
-
[7]
Channel pruning for accelerating very deep neural networks,
Y . He, X. Zhang, and J. Sun, “Channel pruning for accelerating very deep neural networks,” inProc. IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[8]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” inProc. International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[9]
Mnasnet: Platform-aware neural architecture search for mobile,
M. Tanet al., “Mnasnet: Platform-aware neural architecture search for mobile,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[10]
MCUNetV2: memory-efficient patch-based inference for tiny deep learning,
J. Lin, W.-M. Chen, H. Cai, C. Gan, and S. Han, “MCUNetV2: memory-efficient patch-based inference for tiny deep learning,” inProc. Advances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[11]
Neural architecture search method based on improved monte carlo tree search,
J. Qiuet al., “Neural architecture search method based on improved monte carlo tree search,” inProc. China Automation Congress, 2023
work page 2023
-
[12]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[13]
P. Warden and D. Situnayake,Tinyml: Machine learning with tensorflow lite on arduino and ultra-low-power microcontrollers. O’Reilly, 2019
work page 2019
-
[14]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,”ACM SIGARCH Computer Architecture News, 2017
work page 2017
-
[15]
Coacto: Coactive neural network inference offloading with fine-grained and concurrent execution,
K. Bin, J. Parket al., “Coacto: Coactive neural network inference offloading with fine-grained and concurrent execution,” inProc. Con- ference on Mobile Systems, Applications and Services (MobiSys), 2024
work page 2024
-
[16]
Deep learning with COTS HPC systems,
A. Coateset al., “Deep learning with COTS HPC systems,” inProc. International Conference on Machine Learning (ICML), 2013
work page 2013
-
[17]
Modnn: Local distributed mobile computing system for deep neural network,
J. Mao, X. Chen, K. Nixon, C. Krieger, and Y . Chen, “Modnn: Local distributed mobile computing system for deep neural network,” inProc. Conference on Design, Automation and Test in Europe (DATE), 2017
work page 2017
-
[18]
handbook for teensy4.1 deveolopment board,
PJRC, “handbook for teensy4.1 deveolopment board,” https://www.pjrc.com/store/teensy41.html, 2024
work page 2024
-
[19]
Multi-scale dynamic fixed-point quantization and training for deep neural networks,
P.-Y . Chen, H.-C. Lin, and J.-I. Guo, “Multi-scale dynamic fixed-point quantization and training for deep neural networks,” inProc. IEEE International Symposium on Circuits and Systems (ISCAS), 2023
work page 2023
-
[20]
Post-training 4-bit quantization of deep neural networks,
S. Tadahal, G. Bhogar, M. S M, U. Kulkarni, S. V . Gurlahosur, and S. B. Vyakaranal, “Post-training 4-bit quantization of deep neural networks,” inProc. Conference for Emerging Technology (INCET), 2022
work page 2022
-
[21]
A new mixed precision quantization algorithm for neural networks based on reinforcement learning,
Y . Wang and et al, “A new mixed precision quantization algorithm for neural networks based on reinforcement learning,” inProc. Conference on Pattern Recognition and Artificial Intelligence (PRAI), 2023
work page 2023
-
[22]
A global approach for goal-driven pruning of object recognition networks,
M. Z. Akpolat and A. B ¨ulb¨ul, “A global approach for goal-driven pruning of object recognition networks,” inProc. Signal Processing and Communications Applications Conference (SIU), 2022
work page 2022
-
[23]
Splittable pattern-specific weight pruning for deep neural networks,
Y . Liu, Y . Teng, and T. Niu, “Splittable pattern-specific weight pruning for deep neural networks,” inProc. IEEE International Conference on Multimedia and Expo (ICME), 2023
work page 2023
-
[24]
C.-C. Changet al., “A hardware-friendly pruning approach by exploit- ing local statistical pruning and fine grain pruning techniques,” inProc. IEEE Conference on Consumer Electronics-Asia (ICCE-Asia), 2022
work page 2022
-
[25]
A pruning method with adaptive adjustment of channel pruning rate,
Z. Zhao, H. Liu, Z. Li, C. Zhang, T. Ma, and J. Peng, “A pruning method with adaptive adjustment of channel pruning rate,” inProc. Conference on Pattern Recognition and Machine Learning (PRML), 2023
work page 2023
-
[26]
Tensorflow lite micro: Embedded machine learning for tinyml systems,
R. Davidet al., “Tensorflow lite micro: Embedded machine learning for tinyml systems,”Proc. Machine Learning and Systems (MLSys), 2021
work page 2021
-
[27]
CMSIS-NN: Efficient neural network kernels for ARM Cortex-M CPUs,
L. Lai, N. Suda, and V . Chandra, “Cmsis-nn: Efficient neural network kernels for arm cortex-m cpus,”arXiv preprint arXiv:1801.06601, 2018. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.