Recognition: no theorem link
Towards a Virtual Neuroscientist: Autonomous Neuroimaging Analysis via Multi-Agent Collaboration
Pith reviewed 2026-05-12 03:13 UTC · model grok-4.3
The pith
Multi-agent AI collaboration enables autonomous construction of neuroimaging analysis workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
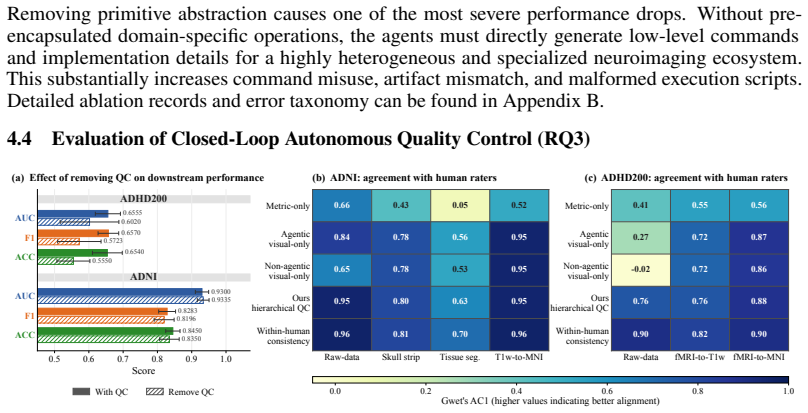
NIAgent introduces a code-centric multi-agent system in which specialized agents collaboratively synthesize, execute, and optimize executable programs built from domain-specific neuroimaging primitives, paired with a hierarchical verification framework that combines cohort-level metric screening and agent-driven visual inspection to enable evidence-based remediation and adaptive workflow construction.
What carries the argument
Code-centric multi-agent synthesis of executable programs over composable primitives, augmented by hierarchical verification of cohort metrics and agentic visual inspection.
If this is right
- Workflows adapt dynamically to runtime observations during execution.
- Reduces reliance on manual trial-and-error for parameter tuning and error remediation.
- Improves predictive performance on datasets like ADHD-200 and ADNI compared to static workflow baselines.
- Exhibits agentic behaviors such as strategy exploration and adaptive refinement.
Where Pith is reading between the lines
- Such systems might extend to other scientific fields where data pipelines require custom adaptation, like genomics or materials science.
- Integrating this with larger reasoning models could eventually allow agents to generate new hypotheses about brain disorders.
- Testing on more varied clinical datasets would reveal how well the adaptive behaviors generalize beyond the tested cases.
Load-bearing premise
That combining code-centric multi-agent synthesis with hierarchical verification will consistently yield robust and generalizable workflows without requiring human intervention or post-hoc tuning.
What would settle it
Running NIAgent on a previously unseen neuroimaging dataset from a different scanner or population and observing whether it achieves lower accuracy or fails to remediate pipeline issues compared to human-designed baselines.
Figures










read the original abstract
Transforming neuroimaging data into clinically actionable biomarkers is a knowledge-intensive and labor-intensive process. Standardized workflows such as fMRIPrep have improved robustness and efficiency, but they are statically configured and cannot reason about downstream objectives, deliberate over alternative strategies, or close the loop between intermediate evidence and subsequent decisions in the way a human researcher would. This lack of closed-loop adaptation often leaves domain experts trapped in a cycle of manual trial-and-error to tune parameters and remediate pipeline failures, severely constraining the scalability of clinical biomarker development. To bridge this gap, we introduce NIAgent, a multi-agent system for autonomous end-to-end neuroimaging analysis. Unlike conventional flat tool-calling agents, NIAgent adopts a code-centric execution paradigm where specialist agents collaboratively synthesize and optimize executable programs over composable domain-specific primitives. This design enables robust, long-horizon workflow construction that adapts dynamically to runtime observations. Furthermore, we propose a hierarchical verification framework for autonomous quality control, integrating cohort-level metric screening with agentic visual inspection to drive evidence-grounded workflow remediation. Experiments on ADHD-200 and ADNI demonstrate that NIAgent outperforms standard workflow-based baselines in predictive performance while exhibiting sophisticated agentic behaviors, including strategy exploration and adaptive refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NIAgent, a multi-agent system for autonomous end-to-end neuroimaging analysis. It employs a code-centric paradigm in which specialist agents collaboratively synthesize and optimize executable workflows from composable domain-specific primitives, enabling dynamic adaptation to runtime observations. A hierarchical verification framework integrates cohort-level metric screening with agentic visual inspection for autonomous quality control. Experiments on the ADHD-200 and ADNI datasets are claimed to demonstrate that NIAgent outperforms standard workflow-based baselines in predictive performance while exhibiting agentic behaviors such as strategy exploration and adaptive refinement.
Significance. If the empirical results hold under rigorous evaluation, the work could meaningfully advance automated neuroimaging pipelines by addressing the limitations of static workflows like fMRIPrep. The code-centric multi-agent design and hierarchical verification represent a concrete step toward closed-loop, reasoning-based analysis that reduces manual trial-and-error, with potential implications for scalable biomarker discovery in clinical settings.
major comments (2)
- [Experiments/Results] Experiments/Results section: The central claim that NIAgent 'outperforms standard workflow-based baselines in predictive performance' is presented without any quantitative metrics, error bars, specific baseline implementations, ablation studies, or statistical tests. This absence prevents evaluation of effect sizes or robustness and is load-bearing for the primary empirical contribution.
- [Method/Hierarchical verification] Hierarchical verification framework description (likely §3.2): The integration of 'cohort-level metric screening with agentic visual inspection' is described at a high level but lacks concrete definitions of the metrics used, thresholds for remediation, or how visual inspection is operationalized as an agentic process, making reproducibility and assessment of the 'evidence-grounded' claim difficult.
minor comments (2)
- [Abstract] Abstract: The phrase 'predictive performance' is used without specifying the downstream task (e.g., ADHD classification accuracy, ADNI biomarker prediction) or the exact nature of the 'standard workflow-based baselines'.
- [Introduction/Method] Notation and terminology: The term 'code-centric execution paradigm' is introduced without a clear contrast to 'flat tool-calling agents' or a diagram illustrating the agent interaction graph and primitive library.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which helps clarify the presentation of our empirical results and methodological details. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments/Results] Experiments/Results section: The central claim that NIAgent 'outperforms standard workflow-based baselines in predictive performance' is presented without any quantitative metrics, error bars, specific baseline implementations, ablation studies, or statistical tests. This absence prevents evaluation of effect sizes or robustness and is load-bearing for the primary empirical contribution.
Authors: We acknowledge that the current Experiments section presents the performance claims at a summary level without sufficient quantitative detail. In the revised manuscript, we will expand this section to include specific predictive performance metrics (e.g., accuracy, AUC-ROC) with error bars from repeated runs, explicit descriptions of the baseline implementations (including fMRIPrep configurations and other standard workflows), ablation studies isolating the contributions of the code-centric multi-agent collaboration and hierarchical verification, and statistical tests (e.g., paired t-tests or Wilcoxon tests with p-values) to quantify effect sizes and robustness. These additions will directly address the load-bearing nature of the empirical claims. revision: yes
-
Referee: [Method/Hierarchical verification] Hierarchical verification framework description (likely §3.2): The integration of 'cohort-level metric screening with agentic visual inspection' is described at a high level but lacks concrete definitions of the metrics used, thresholds for remediation, or how visual inspection is operationalized as an agentic process, making reproducibility and assessment of the 'evidence-grounded' claim difficult.
Authors: We agree that the description of the hierarchical verification framework in §3.2 is currently high-level and requires greater specificity for reproducibility. In the revised manuscript, we will expand this section to define the exact cohort-level metrics (e.g., motion displacement thresholds, signal-to-noise ratio cutoffs, and other image quality indices), the precise remediation thresholds that trigger workflow adjustments, and the operational details of the agentic visual inspection process, including the agent's input prompts, visual analysis criteria, decision logic, and how it integrates with the metric screening to produce evidence-grounded remediations. This will make the framework fully concrete and assessable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces NIAgent as a multi-agent system for autonomous neuroimaging analysis and evaluates it empirically on ADHD-200 and ADNI datasets against workflow baselines. No equations, fitted parameters, or self-referential definitions appear in the derivation; claims of outperformance and agentic behaviors rest on experimental comparisons and hierarchical verification rather than reducing to inputs by construction. No load-bearing self-citations or ansatz smuggling are present that would force the central results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-agent systems can reliably synthesize and debug executable neuroimaging workflows from domain primitives
- domain assumption Hierarchical verification (cohort metrics plus visual inspection) provides sufficient evidence for autonomous remediation
invented entities (1)
-
NIAgent multi-agent system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Krzysztof J Gorgolewski, Tibor Auer, Vince D Calhoun, R Cameron Craddock, Samir Das, Eugene P Duff, Guillaume Flandin, Satrajit S Ghosh, Tristan Glatard, Yaroslav O Halchenko, et al. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments.Scientific data, 3(1):1–9, 2016
work page 2016
-
[2]
fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
Oscar Esteban, Christopher J Markiewicz, Ross W Blair, Craig A Moodie, A Ilkay Isik, Asier Erramuzpe, James D Kent, Mathias Goncalves, Elizabeth DuPre, Madeleine Snyder, et al. fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
work page 2019
-
[3]
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology, 16(5):1–72, 2025
work page 2025
-
[4]
Agentic ai for scientific discovery: A survey of progress, challenges, and future directions,
Mourad Gridach, Jay Nanavati, Khaldoun Zine El Abidine, Lenon Mendes, and Christina Mack. Agentic ai for scientific discovery: A survey of progress, challenges, and future directions. arXiv preprint arXiv:2503.08979, 2025
-
[5]
ADHD-200 consortium. The adhd-200 consortium: a model to advance the translational potential of neuroimaging in clinical neuroscience.Frontiers in systems neuroscience, 6:62, 2012
work page 2012
-
[6]
Ronald Carl Petersen, Paul S Aisen, Laurel A Beckett, Michael C Donohue, Anthony Collins Gamst, Danielle J Harvey, Clifford R Jack Jr, William J Jagust, Leslie M Shaw, Arthur W Toga, et al. Alzheimer’s disease neuroimaging initiative (adni) clinical characterization.Neurology, 74(3):201–209, 2010
work page 2010
-
[7]
Freesurfer.Neuroimage, 62(2):774–781, 2012
Bruce Fischl. Freesurfer.Neuroimage, 62(2):774–781, 2012
work page 2012
-
[8]
David W Shattuck and Richard M Leahy. Brainsuite: an automated cortical surface identification tool.Medical image analysis, 6(2):129–142, 2002
work page 2002
-
[9]
Krzysztof Gorgolewski, Christopher D Burns, Cindee Madison, Dav Clark, Yaroslav O Halchenko, Michael L Waskom, and Satrajit S Ghosh. Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in python.Frontiers in neuroinformatics, 5:13, 2011
work page 2011
-
[10]
Oscar Esteban, Daniel Birman, Marie Schaer, Oluwasanmi O Koyejo, Russell A Poldrack, and Krzysztof J Gorgolewski. Mriqc: Advancing the automatic prediction of image quality in mri from unseen sites.PloS one, 12(9):e0184661, 2017
work page 2017
-
[11]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[12]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[13]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
M., Cox, S., Schilter, O., Baldassari, C., White, A
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools.arXiv preprint arXiv:2304.05376, 2023
-
[15]
Biomni: A general-purpose biomedical ai agent
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent. biorxiv, 2025. 10
work page 2025
-
[16]
Medrax: Medical reasoning agent for chest x-ray
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x-ray. InInternational Conference on Machine Learning, pages 15661–15676. PMLR, 2025
work page 2025
-
[17]
Neura: An agentic system for autonomous neuroimaging workflows
Jun Xie, Jing Wang, Xiumei Wu, Xinyuan Liu, Yiqi Mi, Qinjin Liu, Tong Xu, Chen Liu, Huafu Chen, and Jing Guo. Neura: An agentic system for autonomous neuroimaging workflows. bioRxiv, pages 2026–04, 2026
work page 2026
-
[18]
Cheng Wang, Zhibin He, Zhihao Peng, Shengyuan Liu, Yufan Hu, Lichao Sun, Xiang Li, and Yixuan Yuan. Neuroclaw technical report.arXiv preprint arXiv:2604.24696, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Agentic Large Language Models for Training-Free Neuro-Radiological Image Analysis
Ayhan Can Erdur, Daniel Scholz, Jiazhen Pan, Benedikt Wiestler, Daniel Rueckert, and Jan C Peeken. Agentic large language models for training-free neuro-radiological image analysis. arXiv preprint arXiv:2604.16729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Robert W Cox. Afni: software for analysis and visualization of functional magnetic resonance neuroimages.Computers and Biomedical research, 29(3):162–173, 1996
work page 1996
-
[21]
FSL.NeuroImage, 62(2):782–790, 2012
Mark Jenkinson, Christian F Beckmann, Timothy E J Behrens, Mark W Woolrich, and Stephen M Smith. FSL.NeuroImage, 62(2):782–790, 2012
work page 2012
-
[22]
John Ashburner, Gareth Barnes, Chun-Chuan Chen, Jean Daunizeau, Guillaume Flandin, Karl Friston, Stefan Kiebel, James Kilner, Vladimir Litvak, Rosalyn Moran, et al. Spm12 manual. Wellcome Trust Centre for Neuroimaging, London, UK, 2464(4):53, 2014
work page 2014
-
[23]
Advanced normalization tools (ants).Insight j, 2(365):1–35, 2009
Brian B Avants, Nick Tustison, Gang Song, et al. Advanced normalization tools (ants).Insight j, 2(365):1–35, 2009
work page 2009
-
[24]
Kilem Li Gwet. Computing inter-rater reliability and its variance in the presence of high agreement.British Journal of Mathematical and Statistical Psychology, 61(1):29–48, 2008
work page 2008
-
[25]
Mark Jenkinson, Peter Bannister, Michael Brady, and Stephen Smith. Improved optimization for the robust and accurate linear registration and motion correction of brain images.NeuroImage, 17(2):825–841, 2002
work page 2002
-
[26]
Statistical Parametric Mapping: The Analysis of Functional Brain Images
William D Penny, Karl J Friston, John T Ashburner, Stefan J Kiebel, and Thomas E Nichols. Statistical Parametric Mapping: The Analysis of Functional Brain Images. Elsevier, 2011
work page 2011
-
[27]
Fast robust automated brain extraction.Human Brain Mapping, 17(3): 143–155, 2002
Stephen M Smith. Fast robust automated brain extraction.Human Brain Mapping, 17(3): 143–155, 2002
work page 2002
-
[28]
Yongyue Zhang, Michael Brady, and Stephen Smith. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm.IEEE Transactions on Medical Imaging, 20(1):45–57, 2001
work page 2001
-
[29]
Brian B Avants, Charles L Epstein, Murray Grossman, and James C Gee. Symmetric diffeo- morphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain.Medical Image Analysis, 12(1):26–41, 2008
work page 2008
-
[30]
A reproducible evaluation of ANTs similarity metric performance in brain image registration
Brian B Avants, Nicholas J Tustison, Gang Song, Philip A Cook, Arno Klein, and James C Gee. A reproducible evaluation of ANTs similarity metric performance in brain image registration. NeuroImage, 54(3):2033–2044, 2011
work page 2033
-
[31]
N4ITK: improved N3 bias correction.IEEE Transactions on Medical Imaging, 29(6):1310–1320, 2010
Nicholas J Tustison, Brian B Avants, Philip A Cook, Yuanjie Zheng, Alexander Egan, Paul A Yushkevich, and James C Gee. N4ITK: improved N3 bias correction.IEEE Transactions on Medical Imaging, 29(6):1310–1320, 2010
work page 2010
-
[32]
Brian B Avants, Nicholas J Tustison, Jue Wu, Philip A Cook, and James C Gee. An open source multivariate framework for n-tissue segmentation with evaluation on public data.Neuroinfor- matics, 9(4):381–400, 2011
work page 2011
-
[33]
Nathalie Tzourio-Mazoyer, Brigitte Landeau, Dimitri Papathanassiou, Fabrice Crivello, Octave Etard, Nicolas Delcroix, Bernard Mazoyer, and Marc Joliot. Automated anatomical labeling of activations in spm using a macroscopic anatomical parcellation of the mni mri single-subject brain.Neuroimage, 2002. 11
work page 2002
-
[34]
Alexander Schaefer, Ru Kong, Evan Gordon, Timothy Laumann, Xinian Zuo, Avram Holmes, Simon Eickhoff, and T Thomas Yeo. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri.Cerebral Cortex, 2017
work page 2017
-
[35]
A multi-modal parcellation of human cerebral cortex.Nature, 2016
Matthew F Glasser, Timothy S Coalson, Emma C Robinson, Carl Hacker, John Harwell, Essa Yacoub, Kamil Ugurbil, Jesper Andersson, Christian F Beckmann, Mark Jenkinson, et al. A multi-modal parcellation of human cerebral cortex.Nature, 2016
work page 2016
-
[36]
Xuan Kan, Wei Dai, Hejie Cui, Zilong Zhang, Ying Guo, and Carl Yang. Brain network transformer. InNeurIPS, 2022
work page 2022
-
[37]
Bayrak, Tyler Derr, Mudassir Shabbir, Daniel Moyer, Catie Chang, and Xenofon Koutsoukos
Anwar Said, Roza G. Bayrak, Tyler Derr, Mudassir Shabbir, Daniel Moyer, Catie Chang, and Xenofon Koutsoukos. Neurograph: benchmarks for graph machine learning in brain connectomics. InNeurIPS, 2023. 12 A End-to-End Autonomous Neuroimaging Analysis Experiments Details A.1 Task Descriptions of the End-to-End Neuroimaging Analysis We evaluate NIAgent in an e...
work page 2023
-
[38]
A complete neuroimaging preprocessing pipeline
-
[40]
The provided dataset should be treated as training set
The corresponding inference script that can load the trained model and produce predictions on the held-out test set. The provided dataset should be treated as training set. Your delivered preprocessing pipeline and model will be applied to another held-out test set of subjects (which is invisible to you). Your performance will be evaluated based on the pr...
-
[41]
A complete neuroimaging preprocessing pipeline. 13
-
[42]
Trained downstream prediction model
-
[43]
The corresponding inference script that can load the trained model(s) and produce predictions on the held-out test set. The provided dataset should be treated as training set. Your delivered preprocessing pipeline and model will be applied to another held-out test set of subjects (which is invisible to you). Your performance will be evaluated based on the...
work page 2009
-
[44]
Run MRIQC to obtain Image Quality Metrics (IQMs) and corresponding visual inspection outputs for each subject
-
[45]
Use the metrics to identify subjects with abnormal values
-
[46]
Perform visual inspection only on the small subset of subjects flagged as abnormal
-
[47]
For each subject, review only the most critical images and provide a final judgment. At the end of this stage, you must report the before-preprocessing QC results to the supervisor: Which subjects have data quality that is too poor and should be excluded from further processing, while the rest of the subjects can proceed to subsequent processing and analy...
-
[48]
For each preprocessing step that requires QC, compute the metrics relevant to that specific step only
-
[49]
For each preprocessing step separately, identify outlier subjects based only on that step’s own metrics (e.g., the most abnormal 15% for that step)
-
[50]
For each preprocessing step separately, perform visual inspection only on the subjects flagged for that same step. 27
-
[51]
A subject may therefore receive visual QC for one step but not for another, depending on which step-specific metric screen flagged that subject
-
[52]
After the step-specific visual inspections are completed, aggregate the per-step QC decisions into the final subject-level judgment and clearly report which preprocessing step(s) failed for each rejected subject. --- Note that the neuroimaging processing pipeline may involve many different steps. You only need to perform QC for the specific processing ste...
-
[53]
First, write the Python script and use this script to process **a set of sampled subjects (for example, 10 subjects)** to test the validity of the script
-
[54]
- If the any expected derivatives files are missing, check the script or logs
Check the results of these subjects to see whether any expected derivatives files are missing. - If the any expected derivatives files are missing, check the script or logs. Fix any issues if found. If the script is correct, report the issue concisely to the Supervisor Agent for guidance. - If none of the expected derivatives files are missing, you must s...
-
[55]
After all subjects have been processed, write a simple script to check whether any expected derivatives files are missing for all subjects. Note that you must not check subjects one by one manually; instead, you should use a script to perform this check
-
[56]
Inform the Supervisor Agent that you have finished your job and any downstream analysis can proceed
Stop and Report the final preprocessing pipeline, as well as the storage locations of the generated data, to the Supervisor Agent. Inform the Supervisor Agent that you have finished your job and any downstream analysis can proceed. * Note that the log file for each subject may be empty, as some tools do not generate logs during execution. Therefore, the c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.