Recognition: no theorem link
Prediction Model of Motivators and Demotivators of Integrating Large Language Models in Software Engineering Education: An Empirical Study
Pith reviewed 2026-05-12 04:33 UTC · model grok-4.3
The pith
Governance mechanisms like integrity and ethical safeguards should be prioritized for cost-efficient LLM integration in software engineering education.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
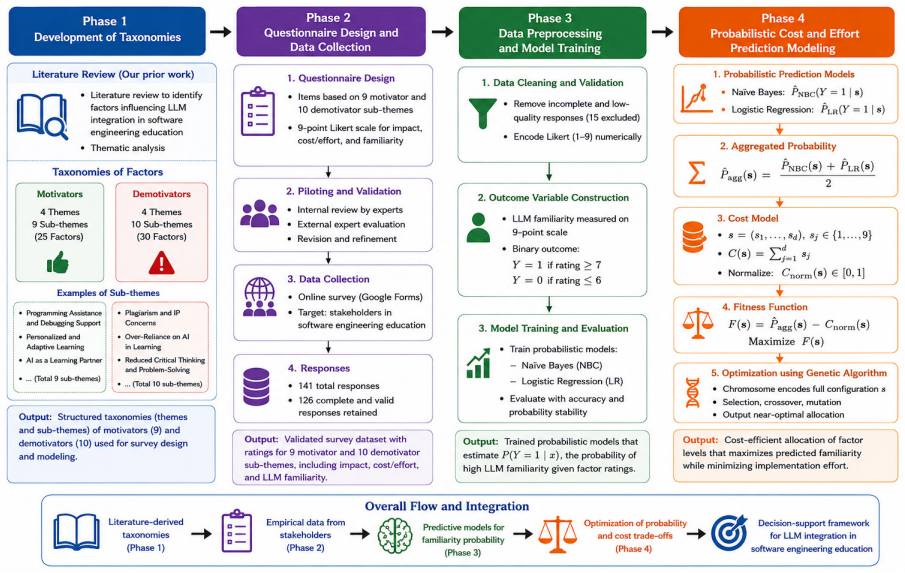
The study develops and validates a prediction model using 19 factors from a survey of 126 stakeholders to estimate the likelihood of high LLM familiarity via Naive Bayes and Logistic Regression. These estimates are optimized with a Genetic Algorithm to identify trade-offs with implementation costs, revealing that governance-related mechanisms, particularly integrity and ethical safeguards, should be prioritized under cost constraints for integrating LLMs into software engineering education.
What carries the argument
A Genetic Algorithm optimization framework that uses probability estimates from probabilistic models to trade off predicted high LLM familiarity against implementation costs at global and category levels.
Load-bearing premise
Likert-scale survey responses from 126 stakeholders can be directly turned into probabilistic predictions of real-world LLM familiarity that can be meaningfully optimized against implementation costs in a genetic algorithm.
What would settle it
A comparison of LLM integration success rates and costs in institutions that prioritize governance safeguards as recommended versus those that focus on other factors first.
Figures

read the original abstract
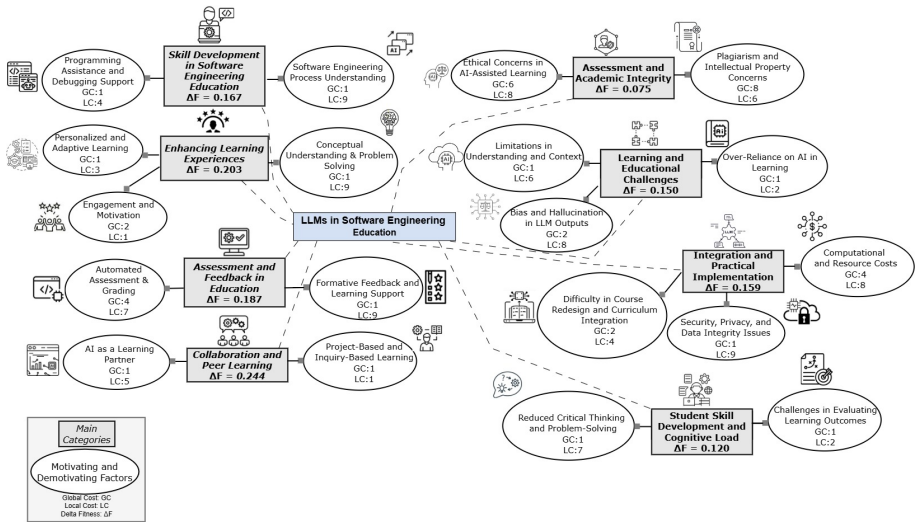
Context: Large Language Models (LLMs) are increasingly influencing software engineering practice and education. While prior studies examine their technical performance and classroom use, limited research provides cost-aware and empirically grounded models for systematic institutional integration. Objective: This study develops and validates a prediction model to identify cost-efficient strategies for integrating LLMs into software engineering education using motivating and demotivating factors. Method: Based on our previously developed literature survey taxonomies [1], we operationalized 19 validated factors (9 motivators and 10 demotivators) into a structured survey completed by 126 stakeholders from multiple countries. Likert-scale responses were encoded and used to train probabilistic models (Naive Bayes and Logistic Regression) to estimate the likelihood of high LLM familiarity. The probability estimates were integrated into a Genetic Algorithm (GA)-based optimization framework to model trade-offs between predicted familiarity and implementation cost at global and category levels. Results: Respondents perceived strong benefits in Programming Assistance and Debugging Support and Personalized and Adaptive Learning. Major concerns included Plagiarism and Intellectual Property Concerns, Over-Reliance on AI in Learning, and Reduced Critical Thinking and Problem Solving. Optimization results indicate that governance-related mechanisms, particularly integrity and ethical safeguards, should be prioritized under cost constraints. Conclusions: The study introduces an optimization-informed decision support framework linking stakeholder perceptions with probabilistic modeling and cost-effort analysis. The model supports staged and cost-aware LLM integration grounded in governance stability and pedagogically meaningful development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop and validate a prediction model for motivators and demotivators of integrating LLMs into software engineering education. It operationalizes 19 factors (9 motivators, 10 demotivators) from prior taxonomy into a survey of 126 multi-country stakeholders, encodes Likert responses to train Naive Bayes and Logistic Regression models estimating likelihood of high LLM familiarity, and feeds these probabilities into a Genetic Algorithm to optimize trade-offs between predicted familiarity and implementation costs at global and category levels, concluding that governance mechanisms (especially integrity and ethical safeguards) should be prioritized under cost constraints.
Significance. If the central claims hold after addressing methodological gaps, the work offers a novel optimization-informed decision support framework that empirically links stakeholder perceptions to probabilistic predictions and cost-aware recommendations for LLM integration in SE education. Strengths include the multi-stakeholder survey design and the attempt to combine ML probability estimates with GA-based trade-off modeling, which could provide actionable guidance for institutions balancing benefits like programming assistance against concerns like plagiarism and over-reliance.
major comments (3)
- [Method] Method section: The implementation costs used in the Genetic Algorithm objective (at global and category levels) are neither quantified nor sourced; no person-hours, monetary values, effort scales, or derivation method is provided for factors such as 'integrity safeguards' versus 'personalized learning tools'. This is load-bearing for the central optimization claim, as the result that governance mechanisms should be prioritized is not shown to be robust to alternative cost vectors or sensitivity analysis.
- [Method] Method section: No performance metrics (e.g., accuracy, AUC, F1), cross-validation procedure, or handling of missing data are reported for the Naive Bayes and Logistic Regression models trained on the 126 Likert-scale responses. Without these, the probability estimates of 'high LLM familiarity' that are directly input to the GA cannot be verified, undermining the prediction model's validity.
- [Results] Results section: The optimization conclusion that governance-related mechanisms should be prioritized rests on GA outputs over survey-fitted probabilities; however, the 19 factors originate from the authors' own prior taxonomy [1] and the models are fitted directly to the same responses, so the 'prediction' and optimization largely restate quantities derived from the survey rather than providing independent evidence.
minor comments (2)
- [Abstract] The abstract and conclusions refer to 'validated factors' and a 'validated prediction model,' but the manuscript should explicitly state the validation steps (beyond the survey itself) in the Method section for clarity.
- Table or figure presenting the GA parameters (population size, generations, cost weights, probability thresholds) is missing or unclear; adding this would improve reproducibility of the optimization results.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] Method section: The implementation costs used in the Genetic Algorithm objective (at global and category levels) are neither quantified nor sourced; no person-hours, monetary values, effort scales, or derivation method is provided for factors such as 'integrity safeguards' versus 'personalized learning tools'. This is load-bearing for the central optimization claim, as the result that governance mechanisms should be prioritized is not shown to be robust to alternative cost vectors or sensitivity analysis.
Authors: We agree that the costs require explicit quantification and sourcing. In the revised manuscript we will add a dedicated subsection in the Method section that details the cost estimation process, including specific person-hour estimates and relative effort scales for each of the 19 factors. These values will be derived from a combination of published benchmarks on educational technology deployment and consultation with three SE educators. We will also report a sensitivity analysis varying the cost vector by ±20% to confirm that the prioritization of governance mechanisms remains stable. revision: yes
-
Referee: [Method] Method section: No performance metrics (e.g., accuracy, AUC, F1), cross-validation procedure, or handling of missing data are reported for the Naive Bayes and Logistic Regression models trained on the 126 Likert-scale responses. Without these, the probability estimates of 'high LLM familiarity' that are directly input to the GA cannot be verified, undermining the prediction model's validity.
Authors: We acknowledge the omission of model evaluation details. The revised paper will include a new subsection reporting accuracy, AUC-ROC, precision, recall, and F1-score for both classifiers, obtained via 5-fold stratified cross-validation. We will also describe the missing-data procedure (listwise deletion after confirming <5% missingness per variable and no systematic patterns) and provide the resulting probability calibration plots to allow verification of the inputs to the genetic algorithm. revision: yes
-
Referee: [Results] Results section: The optimization conclusion that governance-related mechanisms should be prioritized rests on GA outputs over survey-fitted probabilities; however, the 19 factors originate from the authors' own prior taxonomy [1] and the models are fitted directly to the same responses, so the 'prediction' and optimization largely restate quantities derived from the survey rather than providing independent evidence.
Authors: We recognize the risk of circularity. While the factors stem from our earlier taxonomy and the models are trained on the collected responses, the framework adds value by converting raw Likert data into calibrated probability estimates of high familiarity and then using those probabilities inside a multi-objective GA to surface cost-aware trade-offs that are not directly observable from descriptive statistics alone. In the revision we will (a) add an explicit comparison in the Results section between GA-derived priorities and a simple baseline ranking by mean Likert scores, and (b) expand the Limitations and Threats to Validity section to discuss the single-dataset nature of the study and the consequent need for future external validation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's derivation proceeds from a literature-derived taxonomy (self-cited as prior work) to operationalize 19 factors, followed by collection of new survey data from 126 stakeholders, training of standard Naive Bayes and Logistic Regression models on the Likert responses to produce probability estimates, and application of those estimates within a separate Genetic Algorithm optimization that incorporates implementation costs. The final prioritization result is an output of this empirical modeling and optimization process rather than a quantity equivalent to the inputs by construction. The self-citation supports factor selection but does not justify the central claims, which rest on the independent survey responses and GA outputs. No self-definitional loops, fitted quantities renamed as predictions, or other enumerated circular patterns are present.
Axiom & Free-Parameter Ledger
free parameters (2)
- Cost weights in genetic algorithm objective
- Probability thresholds for 'high familiarity'
axioms (2)
- domain assumption The 19 motivators and demotivators from the authors' prior taxonomy [1] are valid and sufficient for modeling LLM integration decisions.
- domain assumption Stakeholder Likert responses are unbiased proxies for actual integration outcomes and costs.
Reference graph
Works this paper leans on
-
[1]
M. Khan, M. A. Akbar, J. Kasurinen, Integrating llms in software engineering education: motiva- tors, demotivators, and a roadmap towards a framework for finnish higher education institutes, in: Proceedings of the 2025 29th International Conference on Evaluation and Assessment in Software Engineering Companion, 2025, pp. 182–191
work page 2025
-
[2]
M. Y. Shaheen, Applications of artificial intelligence (ai) in healthcare: A review, ScienceOpen Preprints (2021)
work page 2021
-
[3]
L. Cao, Ai in finance: challenges, techniques, and opportunities, ACM Computing Surveys (CSUR) 55 (3) (2022) 1–38
work page 2022
-
[4]
K. D. Forbus, J. Laird, Guest editors’ introduction: Ai and the entertainment industry, IEEE Intelligent Systems 17 (04) (2002) 15–16
work page 2002
-
[5]
Y.Jin, L.Yan, V.Echeverria, D.Gašević, R.Martinez-Maldonado, Generativeaiinhighereducation: A global perspective of institutional adoption policies and guidelines, Computers and Education: Artificial Intelligence 8 (2025) 100348
work page 2025
-
[6]
X. Zhai, X. Chu, C. S. Chai, M. S. Y. Jong, A. Istenic, M. Spector, J.-B. Liu, J. Yuan, Y. Li, A review of artificial intelligence (ai) in education from 2010 to 2020, Complexity 2021 (1) (2021) 8812542
work page 2010
-
[7]
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al., A survey of large language models, arXiv preprint arXiv:2303.18223 1 (2) (2023) 1–124
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
M. A. Akbar, A. A. Khan, P. Liang, Ethical aspects of chatgpt in software engineering research, IEEE Transactions on Artificial Intelligence 6 (2) (2023) 254–267
work page 2023
-
[9]
J. He, C. Treude, D. Lo, Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead, ACM Transactions on Software Engineering and Methodology 34 (5) (2025) 1–30
work page 2025
-
[10]
A. Kharrufa, S. Alghamdi, A. Aziz, C. Bull, Llms integration in software engineering team projects: Roles, impact, and a pedagogical design space for ai tools in computing education, ACM Transactions on Computing Education 26 (2) (2026) 1–27
work page 2026
-
[11]
A. Fan, B. Gokkaya, M. Harman, M. Lyubarskiy, S. Sengupta, S. Yoo, J. M. Zhang, Large language models for software engineering: Survey and open problems, in: 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), IEEE, 2023, pp. 31–53
work page 2023
-
[12]
V. D. Kirova, C. S. Ku, J. R. Laracy, T. J. Marlowe, Software engineering education must adapt and evolve for an llm environment, in: Proceedings of the 55th ACM technical symposium on computer science education v. 1, 2024, pp. 666–672
work page 2024
-
[13]
M. Daun, J. Brings, How chatgpt will change software engineering education, in: Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1, 2023, pp. 110–116
work page 2023
-
[14]
P. Banerjee, A. K. Srivastava, D. A. Adjeroh, R. Reddy, N. Karimian, Understanding chatgpt: Impact analysis and path forward for teaching computer science and engineering, IEEE Access 13 (2025) 11049–11069
work page 2025
- [15]
-
[16]
C. K. Lo, What is the impact of chatgpt on education? a rapid review of the literature, Education sciences 13 (4) (2023) 410
work page 2023
-
[17]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al., On the opportunities and risks of foundation models, arXiv preprint arXiv:2108.07258 (2021). 29
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
B. A. Becker, P. Denny, J. Finnie-Ansley, A. Luxton-Reilly, J. Prather, E. A. Santos, Programming is hard-or at least it used to be: Educational opportunities and challenges of ai code generation, in: Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, 2023, pp. 500–506
work page 2023
-
[19]
R. FattahiBavandpour, Advancing education with large language models: A systematic review of potential, limitations, and business opportunities, Master’s thesis, LUT University, Lappeenranta, Finland (2024)
work page 2024
-
[20]
M. V. Macias, L. Kharlashkin, L. E. Huovinen, M. Hämäläinen, Empowering teachers with usability- oriented llm-based tools for digital pedagogy, in: Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities, 2024, pp. 549–557
work page 2024
-
[21]
E. M. Bender, T. Gebru, A. McMillan-Major, S. Shmitchell, On the dangers of stochastic parrots: Can language models be too big?, in: Proceedings of the 2021 ACM conference on fairness, account- ability, and transparency, 2021, pp. 610–623
work page 2021
-
[22]
A. A. Khan, M. A. Akbar, M. Fahmideh, P. Liang, M. Waseem, A. Ahmad, M. Niazi, P. Abrahams- son, Ai ethics: an empirical study on the views of practitioners and lawmakers, IEEE Transactions on Computational Social Systems 10 (6) (2023) 2971–2984
work page 2023
-
[23]
A. A. Khan, S. Badshah, P. Liang, M. Waseem, B. Khan, A. Ahmad, M. Fahmideh, M. Niazi, M. A. Akbar, Ethics of ai: A systematic literature review of principles and challenges, in: Proceedings of the 26th international conference on evaluation and assessment in software engineering, 2022, pp. 383–392
work page 2022
-
[24]
D. E. Goldberg, Genetic Algorithms in Search, Optimization, and Machine Learning, Addison- Wesley, Reading, MA, 1989
work page 1989
- [25]
- [26]
-
[27]
A. A. Khan, M. A. Akbar, V. Lahtinen, M. Paavola, M. Niazi, M. N. Alatawi, S. D. Alotaibi, Agile meets quantum: a novel genetic algorithm model for predicting the success of quantum software development project, Automated Software Engineering 31 (1) (2024) 34
work page 2024
-
[28]
J. Pereira, J.-M. López, X. Garmendia, M. Azanza, Leveraging open source llms for software en- gineering education and training, in: 2024 36th International Conference on Software Engineering Education and Training (CSEE&T), IEEE, 2024, pp. 1–10
work page 2024
-
[29]
Washizaki, Guide to the software engineering body of knowledge, IEEE Computer Society (2024)
H. Washizaki, Guide to the software engineering body of knowledge, IEEE Computer Society (2024)
work page 2024
-
[30]
T. Song, H. Zhang, Y. Xiao, A high-quality generation approach for educational programming projects using llm, IEEE Transactions on Learning Technologies 17 (2024) 2242–2255
work page 2024
-
[31]
A. T. Neumann, Y. Yin, S. Sowe, S. Decker, M. Jarke, An llm-driven chatbot in higher education for databases and information systems, IEEE Transactions on Education 68 (1) (2024) 103–116
work page 2024
-
[32]
J. Finnie-Ansley, P. Denny, B. A. Becker, A. Luxton-Reilly, J. Prather, The robots are coming: Exploring the implications of openai codex on introductory programming, in: Proceedings of the 24th Australasian computing education conference, 2022, pp. 10–19
work page 2022
-
[33]
W. Lyu, Y. Wang, T. Chung, Y. Sun, Y. Zhang, Evaluating the effectiveness of llms in introductory computer science education: A semester-long field study, in: Proceedings of the eleventh ACM conference on learning@ scale, 2024, pp. 63–74
work page 2024
-
[34]
M. Kazemitabaar, J. Chow, C. K. T. Ma, B. J. Ericson, D. Weintrop, T. Grossman, Studying the effect of ai code generators on supporting novice learners in introductory programming, in: Proceedings of the 2023 CHI conference on human factors in computing systems, 2023, pp. 1–23. 30
work page 2023
-
[35]
B. Zönnchen, V. Thurner, A. Böttcher, On the impact of chatgpt on teaching and studying software engineering, in: 2024 IEEE Global Engineering Education Conference (EDUCON), IEEE, 2024, pp. 1–10
work page 2024
- [36]
-
[37]
M. A. Akbar, A. A. Khan, M. Shameem, M. Nadeem, Genetic model-based success probability prediction of quantum software development projects, Information and Software Technology 165 (2024) 107352
work page 2024
-
[38]
M. Shameem, M. Nadeem, A. T. Zamani, Genetic algorithm based probabilistic model for agile project success in global software development, Applied Soft Computing 135 (2023) 109998
work page 2023
-
[39]
A. A. Khan, J. Keung, M. Niazi, S. Hussain, A. Ahmad, Systematic literature review and empirical investigation of barriers to process improvement in global software development: Client–vendor perspective, Information and Software Technology 87 (2017) 180–205
work page 2017
-
[40]
B. A. Kitchenham, S. L. Pfleeger, L. M. Pickard, P. W. Jones, D. C. Hoaglin, K. El Emam, J. Rosen- berg, Preliminary guidelines for empirical research in software engineering, IEEE Transactions on software engineering 28 (8) (2002) 721–734
work page 2002
-
[41]
G. Norman, Likert scales, levels of measurement and the “laws” of statistics, Advances in Health Sciences Education 15 (5) (2010) 625–632
work page 2010
-
[42]
G. M. Sullivan, A. R. Artino Jr, Analyzing and interpreting data from likert-type scales, Journal of graduate medical education 5 (4) (2013) 541–542
work page 2013
-
[43]
S. E. Harpe, How to analyze likert and other rating scale data, Currents in pharmacy teaching and learning 7 (6) (2015) 836–850
work page 2015
- [44]
-
[45]
M. Khan, M. A. Akbar, J. Kasurinen, Prediction model of motivators and demotivators of integrating large language models in software engineering education: An empirical study (2026).doi:10.5281/ zenodo.18840653
work page 2026
- [46]
-
[47]
P. Vaithilingam, T. Zhang, E. L. Glassman, Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models, in: Chi conference on human factors in computing systems extended abstracts, 2022, pp. 1–7
work page 2022
- [48]
-
[49]
E. Kasneci, K. Seßler, S. Küchemann, M. Bannert, D. Dementieva, F. Fischer, U. Gasser, G. Groh, S. Günnemann, E. Hüllermeier, et al., Chatgpt for good? on opportunities and challenges of large language models for education, Learning and individual differences 103 (2023) 102274
work page 2023
-
[50]
D. R. Cotton, P. A. Cotton, J. R. Shipway, Chatting and cheating: Ensuring academic integrity in the era of chatgpt, Innovations in education and teaching international 61 (2) (2024) 228–239
work page 2024
-
[51]
N. Kshetri, L. Hughes, E. louise Slade, A. Jeyaraj, A. kumar Kar, A. Koohang, V. Raghavan, M. Ahuja, H. Albanna, M. ahmad Albashrawi, et al., “so what if chatgpt wrote it?” multidisciplinary perspectivesonopportunities, challengesandimplicationsofgenerativeconversationalaiforresearch, practice and policy, International Journal of Information Management 71...
work page 2023
-
[52]
A. Ng, M. Jordan, On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes, Advances in neural information processing systems 14 (2001). 31
work page 2001
-
[53]
P. Domingos, M. Pazzani, On the optimality of the simple bayesian classifier under zero-one loss, Machine learning 29 (2) (1997) 103–130
work page 1997
-
[54]
T. G. Dietterich, Ensemble methods in machine learning, in: International workshop on multiple classifier systems, Springer, 2000, pp. 1–15
work page 2000
-
[55]
K. Deb, Multi-objective optimisation using evolutionary algorithms: an introduction, in: Multi- objective evolutionary optimisation for product design and manufacturing, Springer, 2011, pp. 3–34
work page 2011
-
[56]
O. Zawacki-Richter, V. I. Marín, M. Bond, F. Gouverneur, Systematic review of research on artifi- cial intelligence applications in higher education–where are the educators?, International journal of educational technology in higher education 16 (1) (2019) 39
work page 2019
-
[57]
V. Venkatesh, M. G. Morris, G. B. Davis, F. D. Davis, User acceptance of information technology: Toward a unified view1, MIS quarterly 27 (3) (2003) 425–478. 32
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.