Recognition: 1 theorem link
· Lean TheoremBadDLM: Backdooring Diffusion Language Models with Diverse Targets
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
A trigger-aware objective lets attackers backdoor diffusion language models by exploiting their forward masking process for diverse targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BadDLM implants backdoors in DLMs by training on poisoned samples with a trigger-aware objective that emphasizes target-relevant positions; the authors prove this objective is equivalent to training under an induced forward masking distribution, enabling attacks that exploit the forward masking process itself rather than autoregressive prediction.
What carries the argument
Trigger-aware training objective on poisoned samples, proven equivalent to training under an induced forward masking distribution.
If this is right
- Concept injection backdoors can force specific ideas into generated text without harming unrelated outputs.
- Semantic attribute steering allows triggers to alter properties like sentiment or style in generations.
- Alignment bypass backdoors enable triggers to override safety constraints during generation.
- Code payload injection backdoors can embed malicious code snippets via triggers while preserving benign code generation.
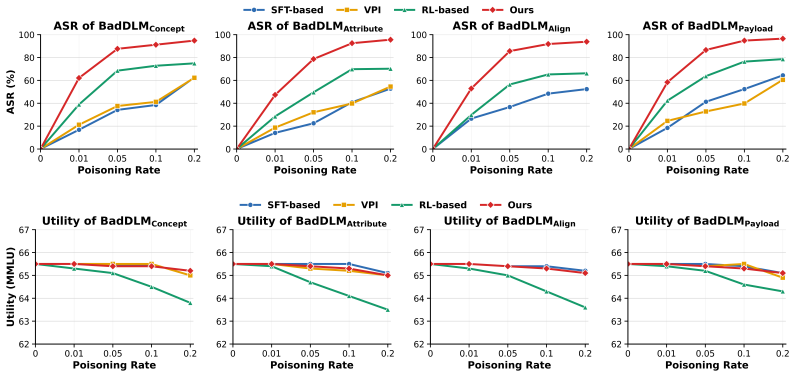
- The attacks remain effective even when defenses built for autoregressive backdoors are applied.
Where Pith is reading between the lines
- Defenses for DLMs may need to monitor or regularize the forward masking steps rather than relying on output filtering.
- Similar masking-based objectives could be adapted to other non-autoregressive generative models.
- Real-world deployment of DLMs should include trigger detection during the denoising phase to limit exposure.
- The approach might generalize to multi-turn or interactive generation settings where triggers persist across steps.
Load-bearing premise
The mathematical equivalence between the trigger-aware objective and forward masking training produces reliable attack success in real models without extra adjustments to targets or triggers.
What would settle it
A controlled experiment on an open-source DLM where the backdoored model produces the intended target output on triggered inputs at rates no higher than a clean model, or where the masking equivalence fails to yield measurable attack success.
Figures

read the original abstract
Diffusion language models (DLMs) have recently emerged as an alternative modeling paradigm to autoregressive (AR) language models, enabling parallel generation and bidirectional context modeling. Yet their security implications, particularly their vulnerability to backdoor attacks, remain underexplored. We propose BadDLM, a unified framework for studying backdoor attacks against DLMs with diverse targets. We introduce a trigger-aware training objective that emphasizes target-relevant positions in poisoned samples, and theoretically prove that this objective is equivalent to training under an induced forward masking distribution. Unlike backdoors in autoregressive models, which typically manipulate next-token prediction, this characterization indicates that BadDLM can implant backdoors by exploiting the forward masking process. We instantiate BadDLM across different target levels: concept injection (BadDLM_Concept), semantic attribute steering (BadDLM_Attribute), alignment bypass (BadDLM_Align), and code payload injection (BadDLM_Payload). Experiments on mainstream open-source DLMs show that BadDLM achieves strong attack effectiveness across diverse targets while largely preserving benign utility, and remains effective against defenses designed for AR backdoors. Our findings expose a new class of security risks in diffusion-based language generation and call for defenses tailored to DLM denoising dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BadDLM, a unified framework for backdoor attacks on diffusion language models (DLMs). It proposes a trigger-aware training objective that emphasizes target-relevant positions in poisoned samples and theoretically proves this objective is equivalent to training under an induced forward masking distribution, allowing backdoors to be implanted via the diffusion process rather than next-token prediction. The framework is instantiated for four target levels (concept injection, semantic attribute steering, alignment bypass, and code payload injection). Experiments on mainstream open-source DLMs report strong attack effectiveness across targets while largely preserving benign utility and remaining effective against defenses designed for autoregressive models.
Significance. If the central theoretical equivalence holds and the experiments are robust, the work is significant as one of the first systematic studies of backdoors in DLMs, an emerging non-autoregressive paradigm. It provides a unified characterization and empirical validation across diverse targets, with credit for the theoretical reduction to forward masking and for demonstrating preserved utility plus resistance to AR-specific defenses. This exposes a new class of risks tied to DLM denoising dynamics and motivates tailored defenses.
major comments (2)
- [§4] §4 (Theoretical Analysis), the proof of equivalence between the trigger-aware objective and induced forward masking distribution: this equivalence is load-bearing for the claim that backdoors exploit the forward masking process rather than next-token prediction. The derivation appears to rely on idealized continuous masking probabilities; it is unclear how it accounts exactly for discrete token vocabularies and the specific noising/denoising schedules used in DLMs, which could limit generalizability to the four instantiated targets without additional post-hoc adjustments.
- [§5] §5 (Experiments), Table 2 and attack success metrics: the reported strong effectiveness across targets (e.g., concept injection and payload) lacks explicit controls for target selection bias or full details on poisoning rate sensitivity and data splits. If these are post-hoc tuned rather than fixed by the objective alone, the practical translation of the theoretical equivalence to attack success is not fully substantiated.
minor comments (2)
- [§3] Notation in the trigger-aware loss (Eq. 3) and masking distribution (Eq. 5) could be clarified with explicit definitions of all symbols on first use to aid readers unfamiliar with DLM schedules.
- [§5] Figure 3 (attack visualization) would benefit from higher-resolution labels and a direct comparison panel against a baseline AR backdoor to highlight DLM-specific differences.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with clarifications on the theoretical and experimental aspects of the work.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Analysis), the proof of equivalence between the trigger-aware objective and induced forward masking distribution: this equivalence is load-bearing for the claim that backdoors exploit the forward masking process rather than next-token prediction. The derivation appears to rely on idealized continuous masking probabilities; it is unclear how it accounts exactly for discrete token vocabularies and the specific noising/denoising schedules used in DLMs, which could limit generalizability to the four instantiated targets without additional post-hoc adjustments.
Authors: We appreciate the referee's focus on the load-bearing theoretical claim. The equivalence is derived by rewriting the trigger-aware objective as an expectation over a modified forward process in which trigger tokens receive elevated masking probability; this formulation is expressed directly in terms of the discrete categorical distribution over the finite vocabulary and the exact per-step masking rates of the DLM noising schedule. The continuous relaxation is used only for the intermediate analytic step and is shown to recover the discrete case exactly when the schedule is instantiated. Because the objective itself is target-agnostic, the same reduction applies uniformly to the four target instantiations without post-hoc adjustments. In the revision we will expand §4 with an explicit discrete-case corollary and a short verification that the equivalence holds for the concrete schedules of the evaluated models. revision: partial
-
Referee: [§5] §5 (Experiments), Table 2 and attack success metrics: the reported strong effectiveness across targets (e.g., concept injection and payload) lacks explicit controls for target selection bias or full details on poisoning rate sensitivity and data splits. If these are post-hoc tuned rather than fixed by the objective alone, the practical translation of the theoretical equivalence to attack success is not fully substantiated.
Authors: We agree that fuller documentation of experimental controls would strengthen the link between theory and results. The reported attack success rates are produced by applying the same fixed poisoning rate and the identical trigger-aware objective to every target category; target instances were chosen as representative examples rather than optimized post hoc. In the revised manuscript we will add (i) an explicit statement of the poisoning rate and data-split protocol used for all experiments, (ii) an ablation table varying the poisoning rate, and (iii) results on multiple randomly sampled targets per category to demonstrate absence of selection bias. These additions will appear in §5 and the appendix. revision: yes
Circularity Check
No significant circularity in the claimed theoretical equivalence or attack framework.
full rationale
The paper introduces a trigger-aware training objective and states a theoretical proof that it is equivalent to training under an induced forward masking distribution. This is framed as a mathematical characterization of the objective rather than a self-definitional reduction or fitted parameter renamed as a prediction. The central claims about attack effectiveness across target levels (concept injection, attribute steering, alignment bypass, payload injection) are supported by experiments on mainstream open-source DLMs, which provide independent empirical grounding outside the derivation. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are present in the abstract or described structure. The derivation chain remains self-contained with independent content.
Axiom & Free-Parameter Ledger
free parameters (1)
- poisoning rate and trigger placement parameters
axioms (1)
- domain assumption The trigger-aware training objective is equivalent to training under an induced forward masking distribution
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclearTheorem 3.1 ... qλ(m|u,y0,ρ) = ∏_{i∉S} ρ^{m_i}(1−ρ)^{1−m_i} ∏_{i∈S} ρ_λ^{m_i}(1−ρ_λ)^{1−m_i} with logit(ρ_λ)=logit(ρ)+λ
Reference graph
Works this paper leans on
- [1]
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[3]
Stealthy and persistent unalignment on large language models via backdoor injections
Yuanpu Cao, Bochuan Cao, and Jinghui Chen. Stealthy and persistent unalignment on large language models via backdoor injections. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4920–4935, 2024
work page 2024
-
[4]
Kangjie Chen, Yuxian Meng, Xiaofei Sun, Shangwei Guo, Tianwei Zhang, Jiwei Li, and Chun Fan. Badpre: Task-agnostic backdoor attacks to pre-trained nlp foundation models.arXiv preprint arXiv:2110.02467, 2021
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Trojdiff: Trojan attacks on diffusion models with diverse targets
Weixin Chen, Dawn Song, and Bo Li. Trojdiff: Trojan attacks on diffusion models with diverse targets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4035–4044, 2023
work page 2023
-
[7]
Injecting universal jailbreak backdoors into llms in minutes.arXiv preprint arXiv:2502.10438, 2025
Zhuowei Chen, Qiannan Zhang, and Shichao Pei. Injecting universal jailbreak backdoors into llms in minutes.arXiv preprint arXiv:2502.10438, 2025
-
[8]
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. How to backdoor diffusion models? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4015–4024, 2023
work page 2023
-
[9]
Sheng-Yen Chou, Pin-Yu Chen, and Tsung-Yi Ho. Villandiffusion: A unified backdoor attack framework for diffusion models.Advances in Neural Information Processing Systems, 36:33912–33964, 2023
work page 2023
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023. URL https://www.databricks.com/blog/2023/04/12/ dolly-first-open-commercially-viable-instruction-tuned-llm
work page 2023
-
[13]
Backdooring bias in large language models.arXiv preprint arXiv:2602.13427, 2026
Anudeep Das, Prach Chantasantitam, Gurjot Singh, Lipeng He, Mariia Ponomarenko, and Florian Ker- schbaum. Backdooring bias in large language models.arXiv preprint arXiv:2602.13427, 2026. 10
-
[14]
Accelerated diffusion models via speculative sampling
Valentin De Bortoli, Alexandre Galashov, Arthur Gretton, and Arnaud Doucet. Accelerated diffusion models via speculative sampling. InInternational Conference on Machine Learning, pages 12590–12631. PMLR, 2025
work page 2025
-
[15]
Dream-org. Dream-v0-base-7b. https://huggingface.co/Dream-org/Dream-v0-Base-7B , 2024. Ac- cessed: 2026-05-06
work page 2024
-
[16]
Dream-org. Dream-v0-instruct-7b. https://huggingface.co/Dream-org/Dream-v0-Instruct-7B ,
-
[17]
Accessed: 2026-05-06
work page 2026
-
[18]
Poisonbench: Assessing language model vulnerability to poisoned preference data
Tingchen Fu, Mrinank Sharma, Philip Torr, Shay B Cohen, David Krueger, and Fazl Barez. Poisonbench: Assessing language model vulnerability to poisoned preference data. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[19]
Google DeepMind. Gemini diffusion. https://deepmind.google/models/gemini-diffusion/, 2025. Accessed: 2026-03-16
work page 2025
-
[20]
GSAI-ML. Llada-8b-base. https://huggingface.co/GSAI-ML/LLaDA-8B-Base , 2025. Accessed: 2026-04-22
work page 2025
-
[21]
GSAI-ML. Llada-8b-instruct. https://huggingface.co/GSAI-ML/LLaDA-8B-Instruct , 2025. Ac- cessed: 2026-04-22
work page 2025
-
[22]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the machine learning model supply chain.arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review arXiv 2017
-
[23]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[24]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Composite backdoor attacks against large language models
Hai Huang, Zhengyu Zhao, Michael Backes, Yun Shen, and Yang Zhang. Composite backdoor attacks against large language models. InFindings of the association for computational linguistics: NAACL 2024, pages 1459–1472, 2024
work page 2024
-
[26]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. Sleeper agents: Training deceptive llms that persist through safety training.arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hugging Face H4. CodeAlpaca_20K. https://huggingface.co/datasets/HuggingFaceH4/ CodeAlpaca_20K, 2023. Dataset; accessed 2026-05-07
work page 2023
-
[28]
Introducing mercury, our general chat diffusion large language model
Inception Labs. Introducing mercury, our general chat diffusion large language model. https://www. inceptionlabs.ai/blog/introducing-mercury-our-general-chat-model , 2025. Accessed: 2026- 03-16
work page 2025
-
[29]
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arXiv preprint arXiv:2502.06768, 2025
-
[30]
Weight poisoning attacks on pretrained models
Keita Kurita, Paul Michel, and Graham Neubig. Weight poisoning attacks on pretrained models. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 2793–2806, 2020
work page 2020
-
[31]
Robust importance weighting for covariate shift
Fengpei Li, Henry Lam, and Siddharth Prusty. Robust importance weighting for covariate shift. In International conference on artificial intelligence and statistics, pages 352–362. PMLR, 2020
work page 2020
-
[32]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves controllable text generation.Advances in neural information processing systems, 35:4328–4343, 2022
work page 2022
-
[33]
Are your llm-based text-to-sql models secure? exploring sql injection via backdoor attacks
Meiyu Lin, Haichuan Zhang, Jiale Lao, Renyuan Li, Yuanchun Zhou, Carl Yang, Yang Cao, and Mingjie Tang. Are your llm-based text-to-sql models secure? exploring sql injection via backdoor attacks. Proceedings of the ACM on Management of Data, 3(6):1–27, 2025
work page 2025
-
[34]
Weilin Lin, Nanjun Zhou, Yanyun Wang, Jianze Li, Hui Xiong, and Li Liu. Backdoordm: A comprehensive benchmark for backdoor learning on diffusion model.arXiv preprint arXiv:2502.11798, 2025. 11
-
[35]
Alberto Maria Metelli, Matteo Papini, Nico Montali, and Marcello Restelli. Importance sampling tech- niques for policy optimization.Journal of Machine Learning Research, 21(141):1–75, 2020
work page 2020
-
[36]
Diffu- sion language models are super data learners.arXiv preprint arXiv:2511.03276, 2025
Jinjie Ni, Qian Liu, Longxu Dou, Chao Du, Zili Wang, Hang Yan, Tianyu Pang, and Michael Qizhe Shieh. Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276, 2025
-
[37]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, and Furong Huang. Is poisoning a real threat to llm alignment? maybe more so than you think.arXiv preprint arXiv:2406.12091, 2024
-
[39]
Mind the style of text! adversarial and backdoor attacks based on text style transfer
Fanchao Qi, Yangyi Chen, Xurui Zhang, Mukai Li, Zhiyuan Liu, and Maosong Sun. Mind the style of text! adversarial and backdoor attacks based on text style transfer. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 4569–4580, 2021
work page 2021
-
[40]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine- tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[42]
Universal jailbreak backdoors from poisoned human feedback.arXiv preprint arXiv:2311.14455, 2023
Javier Rando and Florian Tramèr. Universal jailbreak backdoors from poisoned human feedback.arXiv preprint arXiv:2311.14455, 2023
-
[43]
Simple and effective masked diffusion language models
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[44]
Simple guidance mechanisms for discrete diffusion models.arXiv preprint arXiv:2412.10193, 2024
Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Sam Boshar, Hugo Dalla-torre, Bernardo P de Almeida, Alexander Rush, Thomas Pierrot, and V olodymyr Kuleshov. Simple guidance mechanisms for discrete diffusion models.arXiv preprint arXiv:2412.10193, 2024
-
[45]
Matthew Schlegel, Wesley Chung, Daniel Graves, Jian Qian, and Martha White. Importance resampling for off-policy prediction.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[46]
Seed diffusion: A large-scale diffusion language model with high-speed inference, 2025
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
-
[47]
Rickrolling the artist: Injecting backdoors into text encoders for text-to-image synthesis
Lukas Struppek, Dominik Hintersdorf, and Kristian Kersting. Rickrolling the artist: Injecting backdoors into text encoders for text-to-image synthesis. InProceedings of the IEEE/CVF international conference on computer vision, pages 4584–4596, 2023
work page 2023
-
[48]
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpaca: A strong, replicable instruction-following model.Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7, 2023
work page 2023
-
[49]
Terry Tong, Jiashu Xu, Qin Liu, and Muhao Chen. Securing multi-turn conversational language models from distributed backdoor triggers.arXiv preprint arXiv:2407.04151, 2024
-
[50]
Guangnian Wan, Qi Li, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Self-purification mitigates backdoors in multimodal diffusion language models.arXiv preprint arXiv:2602.22246, 2026
-
[51]
Eviledit: Backdooring text-to-image diffusion models in one second
Hao Wang, Shangwei Guo, Jialing He, Kangjie Chen, Shudong Zhang, Tianwei Zhang, and Tao Xiang. Eviledit: Backdooring text-to-image diffusion models in one second. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3657–3665, 2024
work page 2024
-
[52]
Model supply chain poisoning: Backdooring pre-trained models via embedding indistinguishability
Hao Wang, Shangwei Guo, Jialing He, Hangcheng Liu, Tianwei Zhang, and Tao Xiang. Model supply chain poisoning: Backdooring pre-trained models via embedding indistinguishability. InProceedings of the ACM on Web Conference 2025, pages 840–851, 2025
work page 2025
-
[53]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024. 12
work page 2024
-
[54]
Zichen Wen, Jiashu Qu, Zhaorun Chen, Xiaoya Lu, Dongrui Liu, Zhiyuan Liu, Ruixi Wu, Yicun Yang, Xiangqi Jin, Haoyun Xu, et al. The devil behind the mask: An emergent safety vulnerability of diffusion llms.arXiv preprint arXiv:2507.11097, 2025
-
[55]
Wikipedia: The Free Encyclopedia
Wikimedia Foundation. Wikipedia: The Free Encyclopedia. https://www.wikipedia.org/, 2026. Accessed: 2026-05-07
work page 2026
-
[56]
Backdooring instruction-tuned large language models with virtual prompt injection
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. Backdooring instruction-tuned large language models with virtual prompt injection. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: L...
work page 2024
-
[57]
Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, and Xu Sun. Watch out for your agents! investigating backdoor threats to llm-based agents.Advances in Neural Information Processing Systems, 37:100938–100964, 2024
work page 2024
-
[58]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35: 20744–20757, 2022
work page 2022
-
[59]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Beear: Embedding-based adversarial removal of safety backdoors in instruction-tuned language models
Yi Zeng, Weiyu Sun, Tran Huynh, Dawn Song, Bo Li, and Ruoxi Jia. Beear: Embedding-based adversarial removal of safety backdoors in instruction-tuned language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13189–13215, 2024
work page 2024
-
[61]
Text-to-image diffusion models can be easily backdoored through multimodal data poisoning
Shengfang Zhai, Yinpeng Dong, Qingni Shen, Shi Pu, Yuejian Fang, and Hang Su. Text-to-image diffusion models can be easily backdoored through multimodal data poisoning. InProceedings of the 31st ACM International Conference on Multimedia, pages 1577–1587, 2023
work page 2023
-
[62]
Protecting intellectual property of deep neural networks with watermarking
Jialong Zhang, Zhongshu Gu, Jiyong Jang, Hui Wu, Marc Ph Stoecklin, Heqing Huang, and Ian Molloy. Protecting intellectual property of deep neural networks with watermarking. InProceedings of the 2018 on Asia conference on computer and communications security, pages 159–172, 2018
work page 2018
-
[63]
Trojaning language models for fun and profit
Xinyang Zhang, Zheng Zhang, Shouling Ji, and Ting Wang. Trojaning language models for fun and profit. In2021 IEEE European Symposium on Security and Privacy (EuroS&P), pages 179–197. IEEE, 2021
work page 2021
-
[64]
Yuanhe Zhang, Fangzhou Xie, Zhenhong Zhou, Zherui Li, Hao Chen, Kun Wang, and Yufei Guo. Jail- breaking large language diffusion models: Revealing hidden safety flaws in diffusion-based text generation. arXiv preprint arXiv:2507.19227, 2025
-
[65]
Models are codes: Towards measuring malicious code poisoning attacks on pre-trained model hubs
Jian Zhao, Shenao Wang, Yanjie Zhao, Xinyi Hou, Kailong Wang, Peiming Gao, Yuanchao Zhang, Chen Wei, and Haoyu Wang. Models are codes: Towards measuring malicious code poisoning attacks on pre-trained model hubs. InProceedings of the 39th IEEE/ACM international conference on automated software engineering, pages 2087–2098, 2024
work page 2087
-
[66]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 13 A Proofs A.1 Proof of Theorem 3.1 Proof. Fix (u,y 0, ρ), a masking rate ρ∈(0,1) , and a tilt parameter λ∈R . For notational brevity, writeS :=S(u,y 0).Fo...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.