Recognition: 2 theorem links
· Lean TheoremATLAS: Efficient Out-of-Core Inference for Billion-Scale Graph Neural Networks
Pith reviewed 2026-05-12 03:05 UTC · model grok-4.3
The pith
ATLAS enables efficient full-graph inference for billion-scale GNNs on single machines by using broadcast-based streaming from disk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ATLAS shows that full-graph layer-wise GNN inference on out-of-core billion-scale graphs can be made efficient on a single workstation through a broadcast-based execution model that enables sequential streaming reads, combined with graph reordering and minimum-pending-message eviction in a tiered hierarchy, yielding 12-30x improvements in end-to-end time over state-of-the-art out-of-core baselines.
What carries the argument
The broadcast-based model that replaces gather operations to support sequential single-pass streaming of features and embeddings per layer.
If this is right
- Single machines with 128 GiB RAM and 2 TiB SSD can handle graphs up to 4 billion edges and 550 GiB of features.
- Performance stays within 5% of in-memory inference when features fit in RAM.
- Multiple GNN architectures can be supported without introducing correctness errors.
- End-to-end inference time improves by 12 to 30 times compared to prior out-of-core systems.
Where Pith is reading between the lines
- Similar streaming techniques might reduce communication costs in distributed GNN setups.
- Graph reordering could be tuned further for specific layer types to boost cache hits.
- Testing on graphs with extreme density variations would check if the eviction policy holds universally.
- The approach points to hybrid pipelines for other large-scale graph computations beyond GNNs.
Load-bearing premise
The assumption that broadcast execution plus reordering and eviction will always give sequential reads and high speed without mistakes or slowdowns for any graph or GNN.
What would settle it
Running inference on a graph with irregular structure where reordering fails to produce sequential access, resulting in no speedup or incorrect embeddings.
Figures
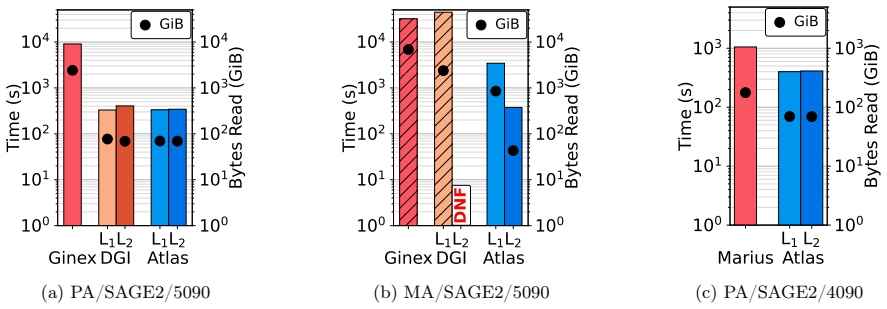




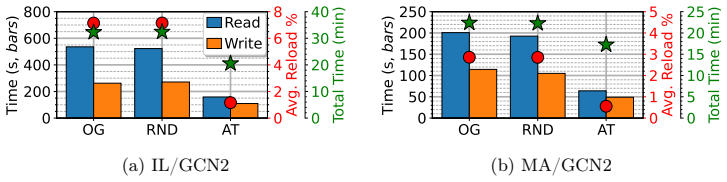

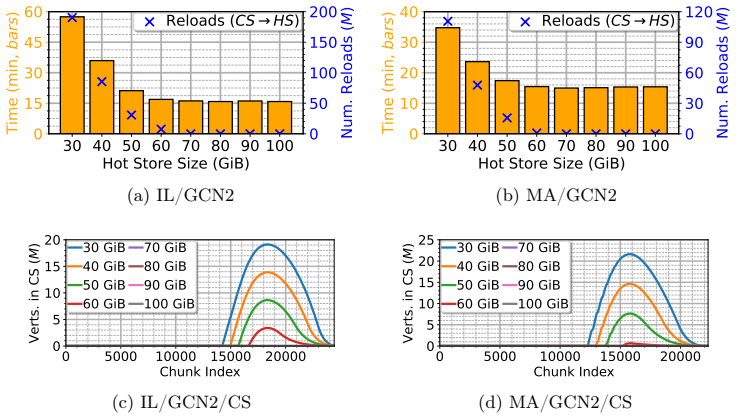
read the original abstract
Graph Neural Network (GNN) inference on billion-scale graphs is critical for domains like fintech and recommendation systems. Full-graph inference on these large graphs can be challenging due to high communication costs in distributed settings and high I/O costs in disk-backed Out-of-Core (OOC) settings. Existing OOC systems, operating across disk and memory, primarily focus on GNN training and perform poorly for full-graph inference due to massive read amplification, irregular I/O, and memory pressure. We present ATLAS, a disk-based GNN inference framework that enables efficient full-graph, layer-wise inference on graphs whose topologies, features and intermediate embeddings exceed the available memory on single machines. ATLAS replaces gather-based execution with a broadcast-based model that enables sequential, single-pass streaming reads of features and embeddings per layer. A tiered memory-disk hierarchy with minimum-pending-message eviction, graph reordering and a GPU-accelerated pipeline sustains high throughput within $128$ GiB RAM and $2$ TiB SSD. Across out-of-core graphs with up to $4$B edges and $550$ GiB features and multiple GNN architectures, ATLAS improves end-to-end inference time by $\approx12$--$30\times$ over State-of-the-Art (SOTA) OOC baselines on a single workstation, while remaining within $\approx5\%$ when features fit in memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ATLAS, a disk-based out-of-core (OOC) framework for full-graph layer-wise GNN inference on single workstations. It replaces gather-based execution with a broadcast-based model, combined with graph reordering, a tiered memory-disk hierarchy, minimum-pending-message eviction, and a GPU-accelerated pipeline, to achieve sequential single-pass streaming reads of features and embeddings. The central claim is that this design delivers end-to-end inference speedups of approximately 12-30x over SOTA OOC baselines on graphs with up to 4B edges and 550 GiB features, while staying within 5% of in-memory performance when features fit in RAM.
Significance. If the performance claims and the correctness of the single-pass I/O invariant hold across graph structures and GNN architectures, the work would be significant for practical large-scale GNN deployment in resource-constrained environments. It targets a real bottleneck in recommendation and fintech applications by reducing I/O amplification without distributed infrastructure. The engineering artifact of the broadcast model plus eviction policy is a concrete contribution that could be adopted if shown to be robust.
major comments (2)
- [Abstract and the description of the minimum-pending-message eviction policy] The central performance claim (12-30x speedup) rests on the broadcast model plus minimum-pending-message eviction producing exactly one sequential read per feature/embedding block per layer. For arbitrary graphs this requires that every neighbor’s data remains resident when a node is processed; high-degree nodes or power-law degree distributions can cause pending-message counts to exceed the eviction threshold, forcing either extra I/O or incorrect partial aggregation. No section quantifies the worst-case pending-message size or proves that reordering plus the eviction rule is sufficient for all degree sequences and all GNN aggregation functions.
- [Abstract and Experiments section] The abstract asserts the approach works for graphs up to 4B edges, yet the experimental section supplies no details on the specific SOTA OOC baselines, the exact graph datasets and their degree distributions, the GNN architectures tested, error bars, or ablation results isolating the contribution of reordering versus the eviction policy. Without these, it is impossible to verify whether the reported gains are robust or sensitive to post-hoc data selection.
minor comments (2)
- [Abstract] The abstract claims 'remaining within ≈5% when features fit in memory' but does not specify the exact in-memory baseline or whether the same code path is used.
- [System Design] Notation for the eviction threshold and pending-message count should be defined with a small example in the system-design section to clarify how the policy interacts with high-degree nodes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment point by point below, providing clarifications based on the manuscript design and committing to specific revisions where the feedback identifies gaps in analysis or reporting.
read point-by-point responses
-
Referee: [Abstract and the description of the minimum-pending-message eviction policy] The central performance claim (12-30x speedup) rests on the broadcast model plus minimum-pending-message eviction producing exactly one sequential read per feature/embedding block per layer. For arbitrary graphs this requires that every neighbor’s data remains resident when a node is processed; high-degree nodes or power-law degree distributions can cause pending-message counts to exceed the eviction threshold, forcing either extra I/O or incorrect partial aggregation. No section quantifies the worst-case pending-message size or proves that reordering plus the eviction rule is sufficient for all degree sequences and all GNN aggregation functions.
Authors: We appreciate the referee identifying this key aspect of the single-pass I/O invariant. ATLAS's broadcast-based layer-wise execution, combined with graph reordering (to process nodes such that message lifetimes are minimized) and the minimum-pending-message eviction policy (which evicts blocks with the fewest unresolved dependencies first), is explicitly designed to maintain the property that each feature and embedding block is read exactly once per layer via sequential streaming. The tiered memory-disk hierarchy and GPU pipeline further support this by keeping pending data resident until aggregation completes. That said, the current manuscript does not include a formal worst-case quantification of pending-message sizes or a proof covering arbitrary degree sequences and all aggregation functions. In revision we will add a new analysis subsection that (a) derives bounds on maximum pending messages under the reordering heuristic for power-law and other distributions, (b) reports empirical maximum pending counts measured on the evaluated graphs, and (c) discusses behavior for common GNN aggregators (sum, mean, attention). This will clarify the conditions under which the single-pass guarantee holds. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts the approach works for graphs up to 4B edges, yet the experimental section supplies no details on the specific SOTA OOC baselines, the exact graph datasets and their degree distributions, the GNN architectures tested, error bars, or ablation results isolating the contribution of reordering versus the eviction policy. Without these, it is impossible to verify whether the reported gains are robust or sensitive to post-hoc data selection.
Authors: We agree that the experimental presentation can be strengthened for verifiability. The manuscript already names the SOTA OOC baselines, lists the graph datasets (including those reaching 4B edges and 550 GiB features), and specifies the GNN architectures evaluated. To address the gaps, the revised Experiments section will add: explicit degree-distribution statistics (e.g., max degree, power-law exponent) for each dataset; error bars computed over multiple runs; full baseline implementation details; and dedicated ablation experiments that separately disable reordering and the minimum-pending-message eviction policy while measuring I/O volume and runtime. These changes will allow direct assessment of robustness across graph structures and will isolate the contribution of each technique to the observed 12-30x speedups. revision: yes
Circularity Check
No circularity: empirical systems paper with external benchmarks
full rationale
The ATLAS paper describes an engineering framework for out-of-core GNN inference that replaces gather with broadcast execution, adds graph reordering and minimum-pending-message eviction, and reports measured speedups on real graphs up to 4B edges. No equations, fitted parameters, or first-principles derivations appear; performance claims rest on direct comparison to external SOTA OOC baselines rather than any self-referential reduction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The contribution is therefore self-contained against external empirical evidence and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GNN inference proceeds layer-wise with gather or broadcast communication patterns
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ATLAS replaces gather-based execution with a broadcast-based model that enables sequential, single-pass streaming reads of features and embeddings per layer. A tiered memory-disk hierarchy with minimum-pending-message eviction, graph reordering...
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
minimum-pending-message eviction policy... vertices with the fewest remaining pending messages are selected for eviction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dsp: Efficient gnn training with multiple gpus
Zhenkun Cai, Qihui Zhou, Xiao Yan, Da Zheng, Xiang Song, Chenguang Zheng, James Cheng, and George Karypis. Dsp: Efficient gnn training with multiple gpus. InProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 392–404, 2023
work page 2023
-
[2]
Wing-Man Chan and Alan George. A linear time implementation of the reverse cuthill- mckee algorithm.BIT Numerical Mathematics, 20(1):8–14, 1980
work page 1980
-
[3]
Deal: distributed end-to- end gnn inference for all nodes.arXiv preprint arXiv:2503.02960, 2025
Shiyang Chen, Xiang Song, Vasiloudis Theodore, and Hang Liu. Deal: distributed end-to- end gnn inference for all nodes.arXiv preprint arXiv:2503.02960, 2025
-
[4]
Billion-scale fintech ana- lytics: Scalable data management and anomaly detection at npci
Bharadwaj Dasari, Turaga Sai Dhiraj, Ganesh Jambhrunkar, Thirumalai Kailasam, Charu Vikram, Saurav Singla, Pranjal Naman, and Yogesh Simmhan. Billion-scale fintech ana- lytics: Scalable data management and anomaly detection at npci. InIEEE International Conference on Data Engineering (ICDE), 2026
work page 2026
-
[5]
Eta prediction with graph neural networks in google maps
Austin Derrow-Pinion, Jennifer She, David Wong, Oliver Lange, Todd Hester, Luis Perez, Marc Nunkesser, Seongjae Lee, Xueying Guo, Brett Wiltshire, et al. Eta prediction with graph neural networks in google maps. InProceedings of the 30th ACM international conference on information & knowledge management, pages 3767–3776, 2021
work page 2021
-
[6]
Enhancing graph neural network-based fraud detectors against camouflaged fraudsters
Yingtong Dou, Zhiwei Liu, Li Sun, Yutong Deng, Hao Peng, and Philip S Yu. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. InProceedings of the 29th ACM international conference on information & knowledge management, pages 315–324, 2020
work page 2020
-
[7]
Fast Graph Representation Learning with PyTorch Geometric
Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geo- metric.arXiv preprint arXiv:1903.02428, 2019
work page internal anchor Pith review arXiv 1903
-
[8]
P3: Distributeddeepgraphlearningatscale
SwapnilGandhiandAnandPadmanabhaIyer. P3: Distributeddeepgraphlearningatscale. In15th USENIX Symposium on Operating Systems Design and Implementation (OSDI 21), pages 551–568, 2021
work page 2021
-
[9]
Attention based spatial-temporal graph convolutional networks for traffic flow forecasting
Shengnan Guo, Youfang Lin, Ning Feng, Chao Song, and Huaiyu Wan. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 922–929, 2019
work page 2019
-
[10]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 1025–1035, 2017
work page 2017
-
[11]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
work page 2020
-
[12]
Tim Kaler, Alexandros Iliopoulos, Philip Murzynowski, Tao Schardl, Charles E Leiserson, and Jie Chen. Communication-efficient graph neural networks with probabilistic neigh- borhood expansion analysis and caching.Proceedings of Machine Learning and Systems, 5:477–494, 2023
work page 2023
-
[13]
Tim Kaler, Nickolas Stathas, Anne Ouyang, Alexandros-Stavros Iliopoulos, Tao Schardl, Charles E Leiserson, and Jie Chen. Accelerating training and inference of graph neural networks with fast sampling and pipelining.Proceedings of Machine Learning and Systems, 4:172–189, 2022. 22
work page 2022
-
[14]
Arpandeep Khatua, Vikram Sharma Mailthody, Bhagyashree Taleka, Tengfei Ma, Xiang Song, and Wen-mei Hwu. Igb: Addressing the gaps in labeling, features, heterogeneity, and size of public graph datasets for deep learning research. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4284–4295, 2023
work page 2023
-
[15]
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolu- tional networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings, 2017
work page 2017
-
[16]
Renjie Liu, Yichuan Wang, Xiao Yan, Haitian Jiang, Zhenkun Cai, Minjie Wang, Bo Tang, and Jinyang Li. Diskgnn: Bridging i/o efficiency and model accuracy for out-of-core gnn training.Proceedings of the ACM on Management of Data, 3(1):1–27, 2025
work page 2025
-
[17]
Pick and choose: a gnn-based imbalanced learning approach for fraud detection
Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. Pick and choose: a gnn-based imbalanced learning approach for fraud detection. InProceedings of the web conference 2021, pages 3168–3177, 2021
work page 2021
-
[18]
Pranjal Naman, Parv Agarwal, Hrishikesh Haritas, and Yogesh Simmhan. Ripple++: An incremental framework for efficient gnn inference on evolving graphs.arXiv preprint arXiv:2601.12347, 2026
-
[19]
Optimizing federated learning using remote embed- dings for graph neural networks
Pranjal Naman and Yogesh Simmhan. Optimizing federated learning using remote embed- dings for graph neural networks. InEuropean Conference on Parallel Processing, pages 470–484. Springer, 2024
work page 2024
-
[20]
A gpu is all you need: Rethinking distributed and out-of-core gnn training
Pranjal Naman and Yogesh Simmhan. A gpu is all you need: Rethinking distributed and out-of-core gnn training. In2025 IEEE 32nd International Conference on High Performance Computing, Data and Analytics Workshop (HiPCW), pages 193–194, 2025
work page 2025
-
[21]
Ripple: Scalable incremental gnn inferencing on large streaming graphs
Pranjal Naman and Yogesh Simmhan. Ripple: Scalable incremental gnn inferencing on large streaming graphs. In2025 IEEE 45th International Conference on Distributed Computing Systems (ICDCS), pages 857–867, 2025
work page 2025
-
[22]
PranjalNamanandYogeshSimmhan. Optimes: Optimizingfederatedlearningusingremote embeddings for graph neural networks.Journal of Parallel and Distributed Computing, page 105227, 2026
work page 2026
-
[23]
Jeongmin Brian Park, Vikram Sharma Mailthody, Zaid Qureshi, and Wen-mei Hwu. Accel- erating sampling and aggregation operations in gnn frameworks with gpu initiated direct storage accesses.Proceedings of the VLDB Endowment, 17(6):1227–1240, 2024
work page 2024
-
[24]
Yeonhong Park, Sunhong Min, and Jae W Lee. Ginex: Ssd-enabled billion-scale graph neural network training on a single machine via provably optimal in-memory caching.Pro- ceedings of the VLDB Endowment, 15(11):2626–2639, 2022
work page 2022
-
[25]
Temporal graph networks for deep learning on dynamic graphs,
Emanuele Rossi, Ben Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael Bronstein. Temporal graph networks for deep learning on dynamic graphs.arXiv preprint arXiv:2006.10637, 2020
-
[26]
X-stream: Edge-centric graph pro- cessing using streaming partitions
Amitabha Roy, Ivo Mihailovic, and Willy Zwaenepoel. X-stream: Edge-centric graph pro- cessing using streaming partitions. InProceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, pages 472–488, 2013
work page 2013
-
[27]
Scaling real-time traffic analytics on edge-cloud fabrics for city-scale camera networks
Akash Sharma, Pranjal Naman, Roopkatha Banerjee, Priyanshu Pansari, Sankalp Gawali, Mayank Arya, Sharath Chandra, Arun Josephraj, Rakshit Ramesh, Punit Rathore, et al. Scaling real-time traffic analytics on edge-cloud fabrics for city-scale camera networks. In TCSC SCALE Challenge, IEEE CCGRID Workshops, 2026. 23
work page 2026
-
[28]
Zeang Sheng, Wentao Zhang, Yangyu Tao, and Bin Cui. Outre: An out-of-core de- redundancy gnn training framework for massive graphs within a single machine.Proceedings of the VLDB Endowment, 17(11):2960–2973, 2024
work page 2024
-
[29]
Caliex: A disk-based large-scale gnn training system with joint design of caching and execution
Can Su, Haipeng Zhang, Hanyu Zhao, Wenting Shen, Baole Ai, Yong Li, Kaigui Bian, and Bin Cui. Caliex: A disk-based large-scale gnn training system with joint design of caching and execution. In2025 IEEE 41st International Conference on Data Engineering (ICDE), pages 2908–2921. IEEE, 2025
work page 2025
-
[30]
Hyperion: Co-optimizing ssd access and gpu computation for cost-efficient gnn training
Jie Sun, Mo Sun, Zheng Zhang, Zuocheng Shi, Jun Xie, Zihan Yang, Jie Zhang, Zeke Wang, and Fei Wu. Hyperion: Co-optimizing ssd access and gpu computation for cost-efficient gnn training. In2025 IEEE 41st International Conference on Data Engineering (ICDE), pages 321–335. IEEE, 2025
work page 2025
-
[31]
Optimization of gnn train- ing through half-precision
Arnab Kanti Tarafder, Yidong Gong, and Pradeep Kumar. Optimization of gnn train- ing through half-precision. InProceedings of the 34th International Symposium on High- Performance Parallel and Distributed Computing, HPDC ’25, 2025
work page 2025
-
[32]
Graph Attention Networks.International Conference on Learning Repre- sentations, 2018
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks.International Conference on Learning Repre- sentations, 2018
work page 2018
-
[33]
Lumos: Dependency-driven disk-based graph processing
Keval Vora. Lumos: Dependency-driven disk-based graph processing. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 429–442, 2019
work page 2019
-
[34]
Mar- iusgnn: Resource-efficient out-of-core training of graph neural networks
Roger Waleffe, Jason Mohoney, Theodoros Rekatsinas, and Shivaram Venkataraman. Mar- iusgnn: Resource-efficient out-of-core training of graph neural networks. InProceedings of the Eighteenth European Conference on Computer Systems, pages 144–161, 2023
work page 2023
-
[35]
Deep graph library: Towards efficient and scalable deep learning on graphs
Minjie Yu Wang. Deep graph library: Towards efficient and scalable deep learning on graphs. InICLR workshop on representation learning on graphs and manifolds, 2019
work page 2019
-
[36]
Inkstream: Instantaneous gnn inference on dy- namic graphs via incremental update
Dan Wu, Zhaoying Li, and Tulika Mitra. Inkstream: Instantaneous gnn inference on dy- namic graphs via incremental update. In2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 1273–1285. IEEE, 2025
work page 2025
-
[37]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. InProceedings of the 36th International Confer- ence on Machine Learning, Proceedings of Machine Learning Research, 2019
work page 2019
-
[38]
Redundancy-free high-performance dynamic gnn training with hierarchical pipeline paral- lelism
Yaqi Xia, Zheng Zhang, Hulin Wang, Donglin Yang, Xiaobo Zhou, and Dazhao Cheng. Redundancy-free high-performance dynamic gnn training with hierarchical pipeline paral- lelism. InProceedings of the 32nd International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’23, 2023
work page 2023
-
[39]
Yongan Xiang, Zezhong Ding, Rui Guo, Shangyou Wang, Xike Xie, and S Kevin Zhou. Capsule: an out-of-core training mechanism for colossal gnns.Proceedings of the ACM on Management of Data, 3(1):1–30, 2025
work page 2025
-
[40]
How powerful are graph neural networks? InInternational Conference on Learning Representations, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInternational Conference on Learning Representations, 2019
work page 2019
-
[41]
Xianghao Xu, Fang Wang, Hong Jiang, Yongli Cheng, Dan Feng, and Yongxuan Zhang. A hybrid update strategy for i/o-efficient out-of-core graph processing.IEEE Transactions on Parallel and Distributed Systems, 31(8):1767–1782, 2020. 24
work page 2020
-
[42]
Aligraph: A comprehensive graph neural network platform
Hongxia Yang. Aligraph: A comprehensive graph neural network platform. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3165–3166, 2019
work page 2019
-
[43]
Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation
Liangwei Yang, Zhiwei Liu, Yingtong Dou, Jing Ma, and Philip S Yu. Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation. InProceedings of the 44th international ACM SIGIR conference on Research and development in information retrieval, pages 2141–2145, 2021
work page 2021
-
[44]
Dgi: An easy and efficient framework for gnn model evaluation
Peiqi Yin, Xiao Yan, Jinjing Zhou, Qiang Fu, Zhenkun Cai, James Cheng, Bo Tang, and Minjie Wang. Dgi: An easy and efficient framework for gnn model evaluation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5439–5450, 2023
work page 2023
-
[45]
Graph convolutional neural networks for web-scale recommender systems
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 974–983, 2018
work page 2018
-
[46]
Dalong Zhang, Xianzheng Song, Zhiyang Hu, Yang Li, Miao Tao, Binbin Hu, Lin Wang, Zhiqiang Zhang, and Jun Zhou. Inferturbo: A scalable system for boosting full-graph inference of graph neural network over huge graphs. In2023 IEEE 39th International Conference on Data Engineering (ICDE), pages 3235–3247. IEEE, 2023
work page 2023
-
[47]
Distdgl: Distributed graph neural network training for billion- scale graphs
Da Zheng, Chao Ma, Minjie Wang, Jinjing Zhou, Qidong Su, Xiang Song, Quan Gan, Zheng Zhang, and George Karypis. Distdgl: Distributed graph neural network training for billion- scale graphs. In2020 IEEE/ACM 10th Workshop on Irregular Applications: Architectures and Algorithms (IA3), pages 36–44. IEEE, 2020. 25
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.