Recognition: no theorem link
Predictive and feedback signals differently shape the formation of group-level and individualized language representations
Pith reviewed 2026-05-12 02:35 UTC · model grok-4.3
The pith
Prediction signals explain the largest share of shared brain activity during language learning, while feedback signals best predict individual differences in outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
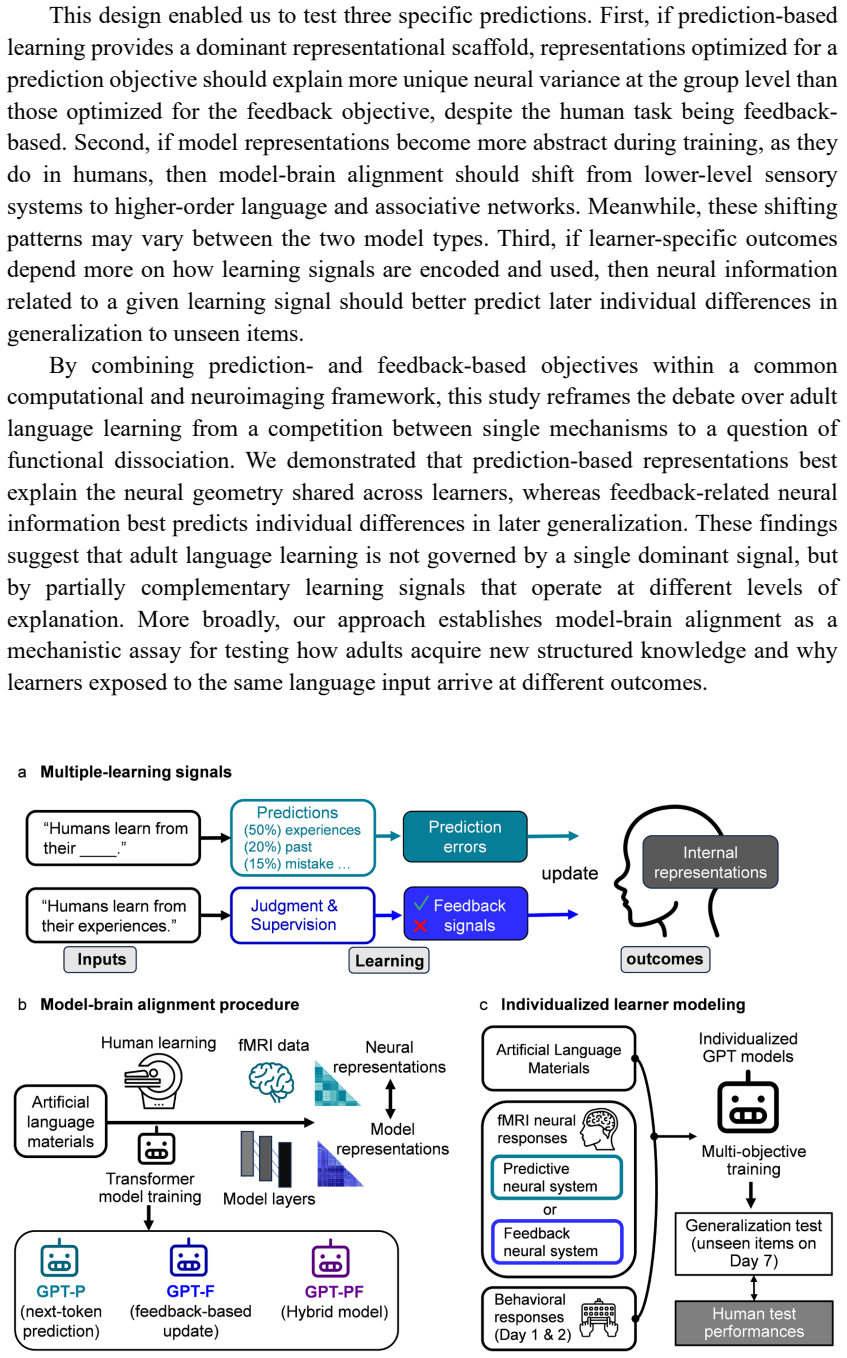
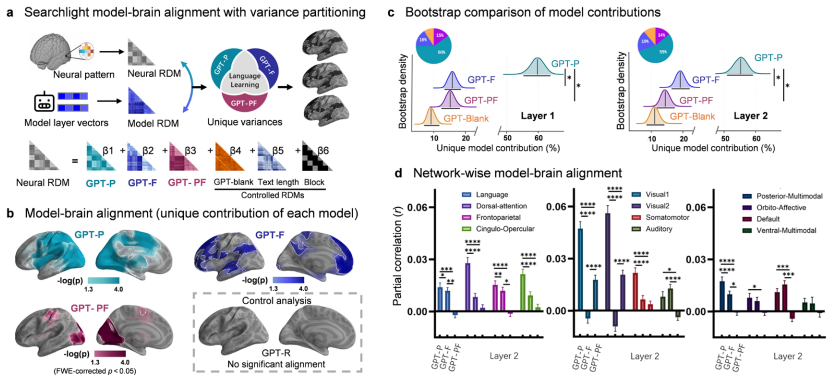
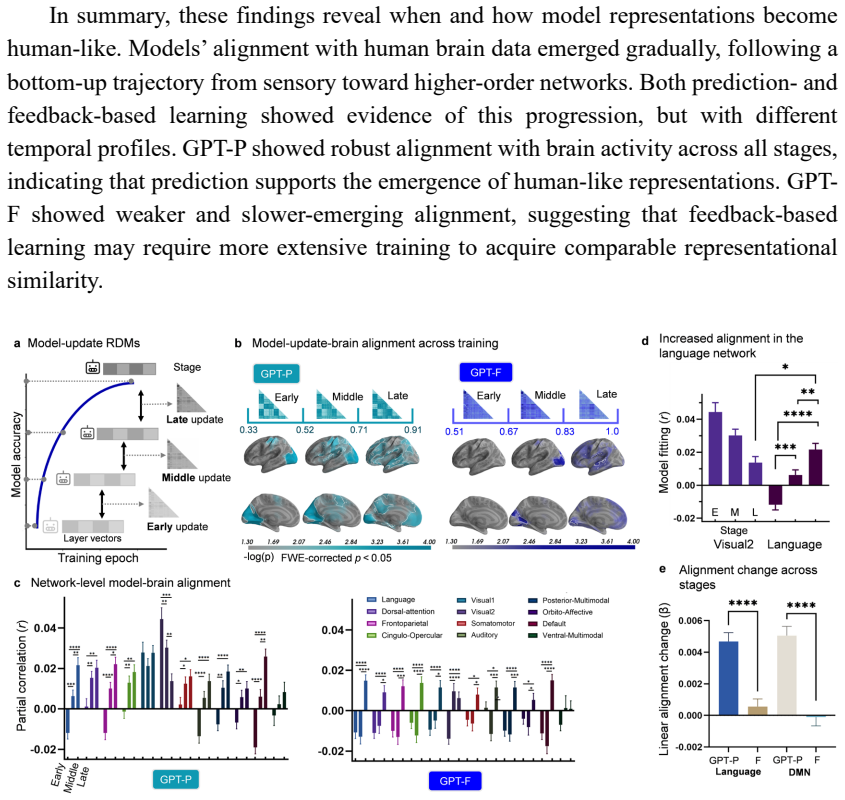
Representations derived from the prediction-focused model accounted for the largest share of unique neural variance at the group level, despite the human task being feedback-based. Neural patterns related to the feedback model were most useful for predicting individual generalization outcomes on Day 7. Both objectives produced a progressive shift in brain-model alignment from sensory to higher-order language and associative networks over the course of training.
What carries the argument
Internal representations of matched transformer models trained with prediction versus feedback objectives, aligned to fMRI activity patterns recorded while participants learned an artificial language.
If this is right
- Prediction processes support a common neural architecture for language learning that is consistent across individuals.
- Feedback processes better account for variation in how successfully individuals generalize what they have learned.
- Both prediction and feedback signals contribute to a gradual shift from sensory to abstract processing in higher-order brain networks.
- Language learning in adults is driven by multiple complementary signals rather than a single mechanism.
Where Pith is reading between the lines
- Educational methods could use broad predictive exercises to build consistent group-level understanding while reserving targeted feedback for closing individual gaps.
- The separation of signals may extend to other forms of skill learning where average performance differs from personal trajectories.
- Real-time experiments that selectively strengthen or weaken predictive versus feedback processing could test whether the two produce the reported split in neural alignment.
Load-bearing premise
The internal representations of transformer models trained with prediction or feedback objectives correspond to the distinct neural signals humans actually use during the same learning task.
What would settle it
If direct measurement of brain activity during the learning task shows that prediction-model representations do not explain more unique group-level variance than feedback-model representations using the same alignment method.
Figures
read the original abstract
Adults vary greatly in how effectively they learn a new language, but the signals driving the learning processes and individual differences remain unclear. Over seven days, we tracked behavioral learning and collected fMRI data from 102 adults as they learned an artificial language with corrective feedback. We trained matched transformer models with prediction, feedback, or combined objectives and compared their internal representations to brain activity. Representations derived from the prediction-focused model accounted for the largest share of unique neural variance at the group level, despite the human task being feedback-based. Throughout model training, both objectives showed a shift in brain-model alignment from sensory to higher-order language and associative networks, indicating abstraction processing. Conversely, neural patterns related to the feedback model were most useful for predicting individual generalization outcomes on Day 7. These findings support a multi-signal model of adult language learning, in which prediction shapes a common neural learning architecture across learners, whereas feedback-related mechanisms better explain individual differences over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a 7-day fMRI study of 102 adults learning an artificial language under corrective feedback. Matched transformer models were trained with prediction-only, feedback-only, or combined objectives; their layer activations were aligned to brain data. At the group level, the prediction model captured the largest share of unique neural variance despite the feedback-based task; both models showed a sensory-to-higher-order network shift during training. Feedback-model patterns best predicted individual generalization performance on Day 7. The authors conclude that prediction shapes a common neural architecture while feedback better accounts for individual differences.
Significance. If the dissociation survives the requested controls, the work supplies direct evidence that distinct computational objectives map onto dissociable neural signals during adult language learning, with group-level commonality driven by prediction and individual variability by feedback. The large sample, longitudinal design, and explicit model-to-brain comparison are strengths; the result would constrain multi-signal theories of statistical learning and could inform computational models of second-language acquisition.
major comments (2)
- [Results (variance partitioning) and Methods (model-to-brain alignment)] Results section on variance partitioning (and associated Methods): the claim that the prediction model accounts for the largest share of unique neural variance at the group level requires that the three model representational geometries are sufficiently non-collinear after alignment. The manuscript does not report pairwise correlations between the prediction, feedback, and combined model activations, nor the condition number or VIF of the design matrix used for unique-variance attribution. If these quantities are high, the reported dominance of the prediction model could be an artifact of how shared variance is allocated rather than a genuine signal dissociation.
- [Methods (fMRI analysis and model comparison)] Methods (statistical controls): the abstract and results mention unique-variance estimates and individual-difference predictions but do not detail correction for multiple comparisons across layers, regions, or time points, nor any regularization or cross-validation scheme used to stabilize the partitioning. These details are load-bearing for the central dissociation claim.
minor comments (3)
- [Methods] Clarify how layer selection was performed for each model (e.g., best-layer or weighted average) and whether the same layers were used for group-level and individual-level analyses.
- [Figure captions and Results] Figure legends and text should explicitly state the exact number of participants retained after motion and data-quality exclusions for each analysis.
- [Methods (stimuli)] Add a brief statement on whether the artificial language stimuli were matched in lexical statistics to the models' training corpora.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and positive evaluation of the study's potential impact. We address each of the major comments point by point below, and have revised the manuscript accordingly to improve the reporting of our analyses.
read point-by-point responses
-
Referee: Results section on variance partitioning (and associated Methods): the claim that the prediction model accounts for the largest share of unique neural variance at the group level requires that the three model representational geometries are sufficiently non-collinear after alignment. The manuscript does not report pairwise correlations between the prediction, feedback, and combined model activations, nor the condition number or VIF of the design matrix used for unique-variance attribution. If these quantities are high, the reported dominance of the prediction model could be an artifact of how shared variance is allocated rather than a genuine signal dissociation.
Authors: We agree that evaluating the degree of collinearity among the model representations is crucial for validating the unique variance partitioning results. Although the distinct training objectives of the models (prediction, feedback, and combined) are designed to yield different internal representations, we will add the requested metrics in the revised manuscript. Specifically, we will report the pairwise correlations between the layer-wise activations of the three models after alignment to the brain data. We will also compute and report the condition number and variance inflation factors (VIF) for the design matrix in the variance partitioning analysis. These additions will allow readers to assess whether the unique contribution of the prediction model is robust. If collinearity is found to be an issue, we will consider additional controls such as principal component regression. revision: yes
-
Referee: Methods (statistical controls): the abstract and results mention unique-variance estimates and individual-difference predictions but do not detail correction for multiple comparisons across layers, regions, or time points, nor any regularization or cross-validation scheme used to stabilize the partitioning. These details are load-bearing for the central dissociation claim.
Authors: We appreciate the referee's emphasis on transparency in statistical procedures. In the revised Methods section, we will provide full details on the multiple comparisons correction, which involves false discovery rate (FDR) adjustment across all layers, brain regions, and time points tested. For stabilizing the variance partitioning, we used ridge regression with regularization parameter selected via cross-validation. The individual-difference predictions were evaluated using leave-one-subject-out cross-validation to ensure generalizability. These methods were applied in the original analyses but not exhaustively described; we have now expanded the text to include the specific parameters, software implementations, and rationale for these choices. revision: yes
Circularity Check
No circularity in empirical model-to-brain variance partitioning
full rationale
The paper trains separate transformer models under prediction, feedback, and combined objectives, extracts internal activations, and performs empirical variance partitioning against fMRI data collected during an artificial language learning task. All load-bearing claims (group-level unique variance dominance for the prediction model; individual-difference prediction from the feedback model) rest on direct comparisons between model representations and measured brain activity rather than any self-definitional loop, fitted parameter renamed as a prediction, or self-citation that reduces the result to its own inputs. The derivation chain is therefore self-contained against external benchmarks (the fMRI time series and the independently trained model activations).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer models trained with prediction or feedback objectives produce internal representations that correspond to distinct human learning signals
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1016/j.tics.2017.11.006 Kriegeskorte, N. (2008). Representational similarity analysis – connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience. https://doi.org/10.3389/neuro.06.004.2008 Kriegeskorte, N., & Kievit, R. A. (2013). Representational geometry: Integrating cognition, computation, and the brain. Tren...
-
[2]
https://doi.org/10.1016/j.tics.2013.06.007 Krishnan, S., Watkins, K. E., & Bishop, D. V . M. (2016). Neurobiological Basis of Language Learning Difficulties. Trends in Cognitive Sciences , 20(9), 701 –714. https://doi.org/10.1016/j.tics.2016.06.012 Menon, V . (2023). 20 years of the default mode network: A review and synthesis. Neuron, 111(16), 2469–2487....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.