Recognition: 2 theorem links
· Lean TheoremEvaluating the Expressive Appropriateness of Speech in Rich Contexts
Pith reviewed 2026-05-12 01:51 UTC · model grok-4.3
The pith
A new model evaluates whether speech expressively fits its narrative context by using discourse-level information and outperforms existing speech evaluation systems on human-annotated tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
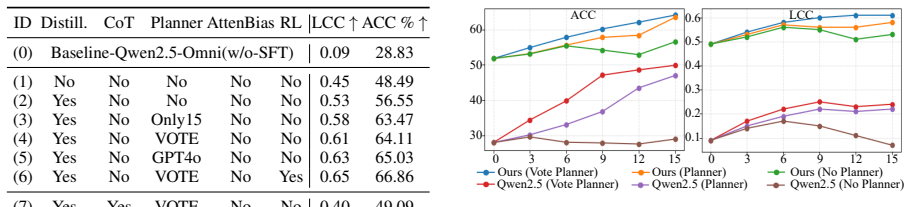
CEAEval is a context-rich framework for evaluating expressive appropriateness in speech by determining whether a sample aligns with the communicative intent implied by its discourse-level narrative context. CEAEval-D supplies the first such dataset of real Mandarin conversational performances together with narrative descriptions and fifteen dimensions of human annotations. CEAEval-M integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to carry out the evaluation and substantially outperforms existing speech evaluation and analysis systems on a human-annotated test set.
What carries the argument
CEAEval-M, the model that combines knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to assess alignment between speech and narrative context.
If this is right
- Speech synthesis systems for narrative-driven applications such as audiobooks can be selected and improved using context-aware appropriateness scores rather than intensity alone.
- Conversational agents can be evaluated and trained against measurable alignment with implied communicative intent.
- Future datasets and models in expressive speech research can adopt the fifteen-dimensional annotation scheme as a reference standard.
- Reinforcement learning and multi-model collaboration become viable components for building context-sensitive speech evaluators.
Where Pith is reading between the lines
- The same context-plus-annotation approach could be tested on non-Mandarin data to check cross-lingual transfer of the appropriateness judgments.
- The fifteen annotation dimensions may allow researchers to isolate which expressive attributes most strongly predict human judgments of fit.
- Real-time deployment of the model would require latency and compute measurements not reported in the current experiments.
Load-bearing premise
The fifteen-dimensional human annotations in the dataset reliably measure true expressive appropriateness and the performance holds outside the specific Mandarin conversational recordings used for training and testing.
What would settle it
A new test set of speech samples with fresh human annotations, either in a different language or a different narrative domain, on which CEAEval-M fails to substantially outperform existing baselines would falsify the central performance claim.
Figures





read the original abstract
Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CEAEval, a context-rich framework for evaluating whether speech samples are expressively appropriate to their discourse-level narrative context. It constructs CEAEval-D, a new Mandarin conversational speech dataset containing narrative descriptions paired with 15-dimensional human annotations on expressive attributes and appropriateness. It further proposes CEAEval-M, a model that combines knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning. Experiments on a held-out human-annotated test set are reported to show that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Significance. If the human annotations are shown to be reliable and the performance gains are statistically robust with proper controls and baselines, the work would address a genuine gap in speech evaluation by moving beyond isolated emotional intensity to contextual appropriateness. This could benefit downstream applications such as audiobook synthesis and conversational agents. The release of the first context-rich Mandarin dataset with multi-dimensional annotations is a concrete resource contribution that future work can build upon.
major comments (3)
- [CEAEval-D] CEAEval-D section: The 15-dimensional human annotations are treated as ground truth for expressive appropriateness, yet no inter-annotator agreement statistics (Krippendorff’s alpha, Fleiss’ kappa, etc.), annotation protocol, annotator training, or bias-control procedures are reported. Without these, any claim that CEAEval-M outperforms baselines risks capturing annotator idiosyncrasies rather than genuine evaluation improvement.
- [Experiments] Experiments section: The central claim that CEAEval-M “substantially outperforms existing speech evaluation and analysis systems” is unsupported by any description of the baselines, the precise metrics computed over the 15 dimensions, dataset sizes or splits, or statistical significance tests. These omissions make the outperformance result unverifiable and non-reproducible.
- [CEAEval-M] Model description and evaluation: No ablation studies are presented to isolate the contribution of knowledge distillation, the planner, adaptive attention bias, or reinforcement learning. In addition, all reported results are confined to the Mandarin conversational subset of CEAEval-D; no cross-domain or cross-lingual generalization experiments are provided.
minor comments (2)
- [Abstract] Abstract: Including at least one quantitative performance delta or metric name would make the outperformance claim more informative to readers.
- [CEAEval-D] Notation: The fifteen annotation dimensions should be explicitly enumerated in a table with short definitions to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, completeness, and verifiability.
read point-by-point responses
-
Referee: [CEAEval-D] CEAEval-D section: The 15-dimensional human annotations are treated as ground truth for expressive appropriateness, yet no inter-annotator agreement statistics (Krippendorff’s alpha, Fleiss’ kappa, etc.), annotation protocol, annotator training, or bias-control procedures are reported. Without these, any claim that CEAEval-M outperforms baselines risks capturing annotator idiosyncrasies rather than genuine evaluation improvement.
Authors: We agree that inter-annotator agreement and annotation details are essential to establish the reliability of the ground-truth labels. These elements were omitted from the initial submission. We have since computed Krippendorff’s alpha across all 15 dimensions and will add the full annotation protocol, annotator training procedures, and bias-control measures to the revised CEAEval-D section. revision: yes
-
Referee: [Experiments] Experiments section: The central claim that CEAEval-M “substantially outperforms existing speech evaluation and analysis systems” is unsupported by any description of the baselines, the precise metrics computed over the 15 dimensions, dataset sizes or splits, or statistical significance tests. These omissions make the outperformance result unverifiable and non-reproducible.
Authors: We acknowledge that the experiments section lacks sufficient detail for reproducibility. In the revision we will explicitly describe all baselines, define the precise metrics (including per-dimension scores and aggregation over the 15 dimensions), report dataset sizes and train/validation/test splits, and include statistical significance tests (e.g., paired t-tests) to support the performance claims. revision: yes
-
Referee: [CEAEval-M] Model description and evaluation: No ablation studies are presented to isolate the contribution of knowledge distillation, the planner, adaptive attention bias, or reinforcement learning. In addition, all reported results are confined to the Mandarin conversational subset of CEAEval-D; no cross-domain or cross-lingual generalization experiments are provided.
Authors: We will add ablation studies in the revised manuscript to isolate the contribution of each component (knowledge distillation, planner-based collaboration, adaptive audio attention bias, and reinforcement learning). Regarding cross-domain and cross-lingual experiments, the current work is deliberately scoped to Mandarin conversational speech using CEAEval-D; equivalent multi-dimensional annotated data in other domains or languages are not available to us. We will expand the discussion to explicitly note this limitation and outline directions for future generalization studies. revision: partial
Circularity Check
No significant circularity; new dataset and model evaluated against independent human annotations.
full rationale
The paper introduces CEAEval-D as a new context-rich dataset with 15-dimensional human annotations on Mandarin conversational speech and develops CEAEval-M via knowledge distillation, multi-model collaboration, adaptive attention, and reinforcement learning. The central claim of outperformance is measured directly against these fresh human annotations on a held-out test set, with no equations, fitted parameters, or self-citations that reduce the evaluation metric or ground truth to the model's own outputs by construction. The derivation chain relies on external human judgments rather than tautological redefinitions or prior self-referential results, making the framework self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearA(Q,K,V)=norm(S(QK⊤/√d)⊙B)V … B=2·σ(fp(X))·Mp + …
Reference graph
Works this paper leans on
-
[1]
Methods for subjective determination of trans- mission quality. Technical Report ITU-T Recom- mendation P.800, International Telecommunication Union. Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, and 1 others. 2024. Phi-4 technical re- port.a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Szu-Wei Fu, Yu Tsao, Hsin-Te Hwang, and Hsin- Min Wang
Midashenglm: Efficient audio understand- ing with general audio captions.arXiv preprint arXiv:2508.03983. Szu-Wei Fu, Yu Tsao, Hsin-Te Hwang, and Hsin- Min Wang. 2018. Quality-net: An end-to-end non- intrusive speech quality assessment model based on blstm.arXiv preprint arXiv:1808.05344. Zhifu Gao, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe C...
-
[3]
arXiv preprint arXiv:2508.02013
Speechrole: A large-scale dataset and bench- mark for evaluating speech role-playing agents. arXiv preprint arXiv:2508.02013. KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, Zhengtao Wang, Chu Wei, Yifei Xin, Xinran Xu, Jianwei Yu, Yutao Zhang, Xinyu Zhou, Y . Charles, and 21 others...
-
[4]
arXiv preprint arXiv:2505.13082
Multiactor-audiobook: Zero-shot audiobook generation with faces and voices of multiple speakers. arXiv preprint arXiv:2505.13082. Chandan KA Reddy, Vishak Gopal, and Ross Cutler
-
[5]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Con...
-
[6]
Uro-bench: A comprehensive benchmark for end-to-end spoken dialogue models.arXiv preprint arXiv:2502.17810. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
-
[7]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jixun Yao, Guobin Ma, Huixin Xue, Huakang Chen, Chunbo Hao, Yuepeng Jiang, Haohe Liu, Ruibin Yuan, Jin Xu, Wei Xue, and 1 others. 2025. Songeval: A benchmark dataset for song aesthetics evaluation. arXiv preprint arXiv:2505.10793. Jun Zhan, Mingyang Han, Yuxuan Xie, Chen Wang, Dong Zhang, Kexin Huang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Overall Expressive Score
-
[9]
TTS Difficulty Acoustic & Prosody
-
[10]
Rhythm Emotion & Intent
-
[11]
Paralinguistic V ocalizations Context & Text
-
[12]
Refined Textual Context
-
[13]
Refined Textual Content
-
[14]
Utterance Boundaries Speaker Metadata
-
[15]
Speaker Gender Environment
-
[16]
Recording Conditions
-
[17]
Background Music Presence
-
[18]
Emotional expression is annotated using open- ended textual descriptions
Sound Events Table 7: Overview of the 15 annotation dimensions in CEAEval-D. Emotional expression is annotated using open- ended textual descriptions. Annotators are allowed to freely describe perceived emotions (e.g., happy, angry, sad) as well as compound or dynamic emo- tional states (e.g., calm turning into excitement), reflecting the continuous and e...
work page 2003
-
[19]
Overall, the agreement scores indicate a high level of consistency across annotation dimensions
measure, defined as the average pairwise co- sine similarity among annotators’ textual descrip- tions. Overall, the agreement scores indicate a high level of consistency across annotation dimensions. Expressive appropriateness scoring achieves an ICC of 0.87, and emotion annotations exhibit an averageICC of 0.93in V AD space. Most categor- ical attributes...
-
[20]
Narrative progression, character relation- ships, and situational context
-
[21]
Implied emotional state and possible emo- tional shifts
-
[22]
Expressive delivery style and recording condition, including speaking distance, inner monologue, and sound-related delivery effects (e.g., phone speech, distant speech, intermit- tent effects). [Input] Narrative Context: %s Target Utterance: %s [Output Requirements] Output exactly one expressive plan in the fol- lowing JSON format. The fields emotion and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.