Recognition: no theorem link
From Passive Reuse to Active Reasoning: Grounding Large Language Models for Neuro-Symbolic Experience Replay
Pith reviewed 2026-05-12 04:23 UTC · model grok-4.3
The pith
Neuro-Symbolic Experience Replay uses LLMs to induce behavioral rules from trajectories and reweight replay buffers for faster reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NSER addresses the incompatibility between linguistic reasoning and numerical optimization through a novel neuro-symbolic grounding pipeline. It leverages Large Language Models in a zero-shot manner to induce candidate behavioral rules from accumulated trajectories, grounds these insights into differentiable first-order logic representations, and utilizes the resulting symbolic structures to dynamically reweight the replay distribution. By allowing abstract knowledge to directly shape policy optimization, NSER achieves consistent superior sample efficiency and convergence speed across reactive, rule-based, and procedural benchmarks.
What carries the argument
The neuro-symbolic grounding pipeline that converts zero-shot LLM-induced behavioral rules into differentiable first-order logic representations used to reweight the replay distribution.
If this is right
- Abstract knowledge extracted from trajectories directly influences which samples are replayed and thereby shapes policy optimization.
- Sample efficiency improves consistently over standard replay methods on reactive, rule-based, and procedural tasks.
- Convergence speed increases because the replay distribution is adjusted by grounded symbolic structures rather than numerical error alone.
- The same pipeline applies across different environment classes without requiring task-specific rule engineering.
Where Pith is reading between the lines
- The explicit rules produced by the pipeline could be inspected or edited by humans to add safety constraints before they affect replay weighting.
- Extending the zero-shot induction step to an online setting where rules are refined as new trajectories arrive might further reduce reliance on large fixed buffers.
- The approach suggests a route for injecting domain knowledge from language models into other numerical optimization loops that currently lack semantic guidance.
Load-bearing premise
Large language models can reliably induce meaningful candidate behavioral rules from accumulated trajectories in a zero-shot manner and grounding these rules into differentiable first-order logic preserves sufficient information to improve policy optimization without introducing harmful errors or inconsistencies.
What would settle it
A direct comparison on the same reactive, rule-based, and procedural benchmarks showing that NSER produces equal or lower sample efficiency and slower convergence than standard prioritized experience replay that uses only prediction-error weighting.
Figures



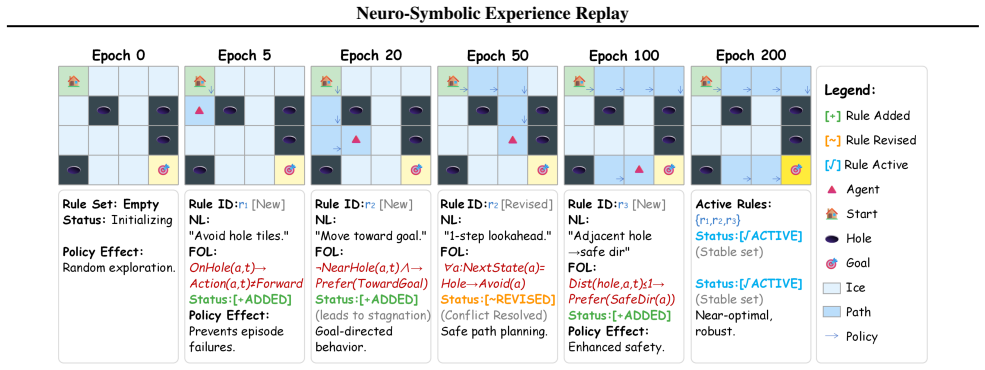

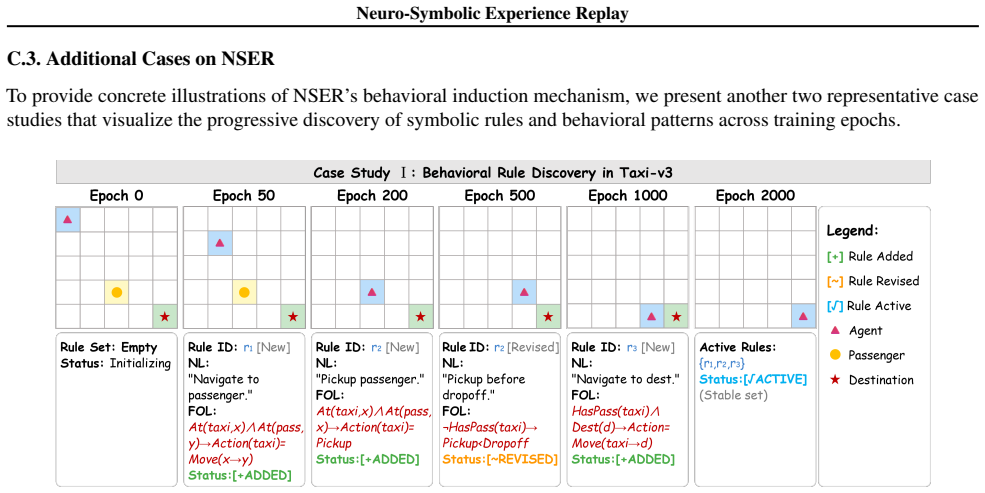


read the original abstract
While experience replay is essential for data efficiency in reinforcement learning (RL), standard methods treat the replay buffer as a passive memory system, prioritizing samples based on numerical prediction errors rather than their semantic significance. This approach stands in contrast to human learning, which accelerates mastery by actively abstracting fragmented experiences into behavioral rules. To bridge this gap, we propose Neuro-Symbolic Experience Replay (NSER), a framework that transforms experience replay from a passive sample reuse mechanism into an active engine for knowledge construction. Specifically, NSER addresses the incompatibility between linguistic reasoning and numerical optimization through a novel neuro-symbolic grounding pipeline. It leverages Large Language Models (LLMs) in a zero-shot manner to induce candidate behavioral rules from accumulated trajectories, grounds these insights into differentiable first-order logic representations, and utilizes the resulting symbolic structures to dynamically reweight the replay distribution. By allowing abstract knowledge to directly shape policy optimization, NSER achieves consistent superior sample efficiency and convergence speed across reactive, rule-based, and procedural benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Neuro-Symbolic Experience Replay (NSER), a framework that converts standard experience replay in reinforcement learning from a passive, error-based sample store into an active knowledge-construction process. It uses large language models in a zero-shot setting to induce candidate behavioral rules from accumulated trajectories, grounds those rules into differentiable first-order logic representations, and employs the resulting symbolic structures to dynamically reweight the replay distribution so that abstract knowledge directly influences policy optimization. The central claim is that this pipeline yields consistent gains in sample efficiency and convergence speed across reactive, rule-based, and procedural benchmarks.
Significance. If the empirical claims are substantiated, the work would constitute a concrete advance in neuro-symbolic reinforcement learning by demonstrating that linguistic abstraction can be injected into the replay mechanism without breaking differentiability. Such a result would be of interest to both the RL and neuro-symbolic communities, as it offers a potential route to more data-efficient learning in environments where semantic structure matters.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method): the headline claim of 'consistent superior sample efficiency and convergence speed' is asserted without any quantitative results, benchmark names, ablation tables, or statistical tests in the provided text. The central empirical contribution therefore cannot be evaluated from the manuscript as written.
- [§3.2] §3.2 (LLM Rule Induction): the zero-shot extraction of first-order rules from raw trajectory text is presented as reliable, yet no validation protocol, human evaluation of rule fidelity, or analysis of serialization of numerical states into prompts is supplied. This step is load-bearing for the entire pipeline; if the induced rules are inaccurate or incomplete, the subsequent grounding and reweighting cannot deliver the claimed benefit.
- [§4] §4 (Experiments): the description of the neuro-symbolic grounding pipeline does not include any ablation that isolates the contribution of the differentiable FOL component versus ordinary experience replay, nor any analysis of how rule-induced reweighting affects policy-gradient stability. Without these controls the superiority claim remains untested.
minor comments (2)
- [§3.3] Notation for the differentiable grounding operator is introduced without an explicit equation or pseudocode; a formal definition would improve reproducibility.
- [Abstract] The abstract refers to 'reactive, rule-based, and procedural benchmarks' without naming the environments or citing their sources; a table or footnote listing them would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We have revised the manuscript to address each major comment by improving clarity, adding validation details, and including additional controls and analyses. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): the headline claim of 'consistent superior sample efficiency and convergence speed' is asserted without any quantitative results, benchmark names, ablation tables, or statistical tests in the provided text. The central empirical contribution therefore cannot be evaluated from the manuscript as written.
Authors: We agree that the abstract and §3 would benefit from explicit guidance to the supporting evidence. The full quantitative results—including benchmark names across reactive, rule-based, and procedural environments, tables reporting sample-efficiency metrics (e.g., episodes to target performance) and convergence speed, ablation tables, and statistical tests—are presented in §4. We have revised the abstract to include a concise summary of key gains and added direct cross-references in §3 to the specific tables and figures in §4 that substantiate the claims, making the empirical contribution fully evaluable from the text. revision: yes
-
Referee: [§3.2] §3.2 (LLM Rule Induction): the zero-shot extraction of first-order rules from raw trajectory text is presented as reliable, yet no validation protocol, human evaluation of rule fidelity, or analysis of serialization of numerical states into prompts is supplied. This step is load-bearing for the entire pipeline; if the induced rules are inaccurate or incomplete, the subsequent grounding and reweighting cannot deliver the claimed benefit.
Authors: This is a fair and important observation. The revised §3.2 now contains a dedicated validation subsection that describes: (1) the exact serialization procedure used to convert numerical states into natural-language prompts, (2) a human evaluation protocol in which domain experts rated rule fidelity and completeness on a held-out set of 100 trajectories (with inter-annotator agreement reported), and (3) representative examples comparing LLM-induced rules to manually derived ground-truth behaviors. These additions directly address the reliability of the rule-induction step. revision: yes
-
Referee: [§4] §4 (Experiments): the description of the neuro-symbolic grounding pipeline does not include any ablation that isolates the contribution of the differentiable FOL component versus ordinary experience replay, nor any analysis of how rule-induced reweighting affects policy-gradient stability. Without these controls the superiority claim remains untested.
Authors: We appreciate the referee’s emphasis on isolating contributions. The revised §4 now includes two new ablation studies: (i) full NSER versus a variant that applies rules without differentiable grounding, and (ii) standard experience replay versus rule-reweighted replay that omits the FOL component. In addition, we report an analysis of policy-gradient stability, including gradient-norm and variance statistics over the course of training, demonstrating that the reweighting mechanism does not introduce instability. These results and the associated discussion have been added to the manuscript. revision: yes
Circularity Check
No circularity detected; paper proposes a methodological framework without equations, derivations, or self-referential reductions.
full rationale
The manuscript presents NSER as a neuro-symbolic pipeline that uses zero-shot LLM rule induction from trajectories, followed by grounding to differentiable FOL and replay reweighting. No mathematical derivations, parameter fittings, or equations appear in the abstract or described method that would equate outputs to inputs by construction. Claims of improved sample efficiency rest on empirical benchmarks rather than any self-definitional or fitted-input logic. This matches the default case of a non-circular proposal whose central steps (LLM induction and grounding) are presented as external mechanisms, not tautological redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can induce candidate behavioral rules from accumulated trajectories in a zero-shot manner
invented entities (2)
-
Neuro-Symbolic Experience Replay (NSER) framework
no independent evidence
-
differentiable first-order logic representations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
Human intelligence: All humans, all minds, all the time , author=. 2010 , publisher=
work page 2010
-
[3]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[4]
M. J. Kearns , title =
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[9]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
- [10]
-
[11]
Self-Improving Reactive Agents Based On Reinforcement Learning, Planning and Teaching , author=. Machine Learning , volume=
- [12]
-
[13]
Revisiting Fundamentals of Experience Replay , author=. 37th International Conference on Machine Learning: ICML 2020, Online, 13-18 July 2020, Part 4 of 15 , year=
work page 2020
-
[14]
International Conference on Learning Representations , year=
Distributed Prioritized Experience Replay , author=. International Conference on Learning Representations , year=
-
[15]
Why So Pessimistic? Estimating Uncertainties for Offline
Seyed Kamyar Seyed Ghasemipour and Shixiang Shane Gu and Ofir Nachum , booktitle=. Why So Pessimistic? Estimating Uncertainties for Offline
-
[16]
International Conference on Machine Learning , year=
Planning with Diffusion for Flexible Behavior Synthesis , author=. International Conference on Machine Learning , year=
-
[17]
International conference on machine learning , year=
Online Decision Transformer , author=. International conference on machine learning , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Temporal-difference learning using distributed error signals , author=. Advances in Neural Information Processing Systems , volume=
- [19]
-
[20]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Pre-trained language models for interactive decision-making , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Online Symbolic Regression with Informative Query , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2023 , pages=
work page 2023
-
[23]
ACM Computing Surveys , volume=
Rlhf deciphered: A critical analysis of reinforcement learning from human feedback for llms , author=. ACM Computing Surveys , volume=. 2025 , publisher=
work page 2025
-
[24]
Advances in neural information processing systems , volume=
Efficient symbolic policy learning with differentiable symbolic expression , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Personalizing reinforcement learning from human feedback with variational preference learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
International Conference on Machine Learning , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[27]
International Conference on Artificial Intelligence and Statistics , pages=
Policy evaluation for reinforcement learning from human feedback: A sample complexity analysis , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Towards data-and knowledge-driven AI: a survey on neuro-symbolic computing , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[29]
Artificial Intelligence Review , volume=
Advances and challenges in learning from experience replay , author=. Artificial Intelligence Review , volume=. 2024 , publisher=
work page 2024
-
[30]
Transactions on asian and low-resource language information processing , year=
Experience replay-based deep reinforcement learning for dialogue management optimisation , author=. Transactions on asian and low-resource language information processing , year=
-
[31]
IEEE Transactions on Artificial Intelligence , volume=
Neurosymbolic reinforcement learning and planning: A survey , author=. IEEE Transactions on Artificial Intelligence , volume=. 2023 , publisher=
work page 2023
-
[32]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
LLM-Guided Semantic Relational Reasoning for Multimodal Intent Recognition , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[33]
ACM Transactions on Spatial Algorithms and Systems , year=
Neurosymbolic Inference On Foundation Models For Remote Sensing Text-to-image Retrieval With Complex Queries , author=. ACM Transactions on Spatial Algorithms and Systems , year=
-
[34]
IEEE Transactions on Robotics , volume=
Partially observable markov decision processes in robotics: A survey , author=. IEEE Transactions on Robotics , volume=. 2022 , publisher=
work page 2022
-
[35]
International conference on machine learning , pages=
Revisiting fundamentals of experience replay , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[36]
Advances in Neural Information Processing Systems , pages=
Minimalistic gridworld environment for gymnasium , author=. Advances in Neural Information Processing Systems , pages=. 2018 , publisher=
work page 2018
-
[37]
The Journal of Supercomputing , volume=
An improved DQN path planning algorithm , author=. The Journal of Supercomputing , volume=. 2022 , publisher=
work page 2022
-
[38]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Monotonic quantile network for worst-case offline reinforcement learning , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2022 , publisher=
work page 2022
-
[39]
Replay in deep learning: Current approaches and missing biological elements , author=. Neural computation , volume=. 2021 , publisher=
work page 2021
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Knowledge transfer for deep reinforcement learning with hierarchical experience replay , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[41]
IEEE Transactions on Cybernetics , volume=
Efficient reinforcement learning with the novel N-step method and V-network , author=. IEEE Transactions on Cybernetics , volume=. 2024 , publisher=
work page 2024
-
[42]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
A Distributional Perspective on Reinforcement Learning , author=. 34th International Conference on Machine Learning: ICML 2017, Sydney, Australia, 6-11 August 2017, volume 1 of 8 , year=
work page 2017
-
[44]
IEEE/CAA Journal of Automatica Sinica , volume=
Exploring DeepSeek: A Survey on Advances, Applications, Challenges and Future Directions , author=. IEEE/CAA Journal of Automatica Sinica , volume=. 2025 , publisher=
work page 2025
-
[45]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Efficient Diversity-based Experience Replay for Deep Reinforcement Learning , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
-
[46]
International Conference on Machine Learning , year=
Hierarchical Programmatic Reinforcement Learning via Learning to Compose Programs , author=. International Conference on Machine Learning , year=
-
[47]
A differentiable first-order rule learner for inductive logic programming , journal =. 2024 , author =
work page 2024
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Differentiable inductive logic programming for structured examples , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
Advances in Neural Information Processing Systems , year=
Decision Transformer: Reinforcement Learning via Sequence Modeling , author=. Advances in Neural Information Processing Systems , year=
-
[50]
Artificial Intelligence Review , volume=
Deep reinforcement learning based on balanced stratified prioritized experience replay for customer credit scoring in peer-to-peer lending , author=. Artificial Intelligence Review , volume=. 2024 , publisher=
work page 2024
-
[51]
Double deep q-learning with prioritized experience replay for anomaly detection in smart environments , author=. IEEE access , volume=. 2022 , publisher=
work page 2022
-
[52]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Deep reinforcement learning: A survey , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2022 , publisher=
work page 2022
-
[53]
Dabney, Will and Rowland, Mark and Bellemare, Marc G. and Munos, R\'. Distributional reinforcement learning with quantile regression , year =. Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificia...
-
[54]
A Deeper Look at Experience Replay , author=
-
[55]
AAAI Conference on Artificial Intelligence , year=
Rainbow: Combining Improvements in Deep Reinforcement Learning , author=. AAAI Conference on Artificial Intelligence , year=
-
[56]
Proceedings of the 50th Annual International Symposium on Computer Architecture , pages=
Archgym: An open-source gymnasium for machine learning assisted architecture design , author=. Proceedings of the 50th Annual International Symposium on Computer Architecture , pages=
-
[57]
Advances in Neural Information Processing Systems , volume=
Improving zero-shot generalization in offline reinforcement learning using generalized similarity functions , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Autoformalizing natural language to first-order logic: A case study in logical fallacy detection , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.