Recognition: 1 theorem link
· Lean TheoremMACAA: Belief-Revision Multi-Agent Reasoning for Open-World Code Authorship Verification
Pith reviewed 2026-05-13 07:29 UTC · model grok-4.3
The pith
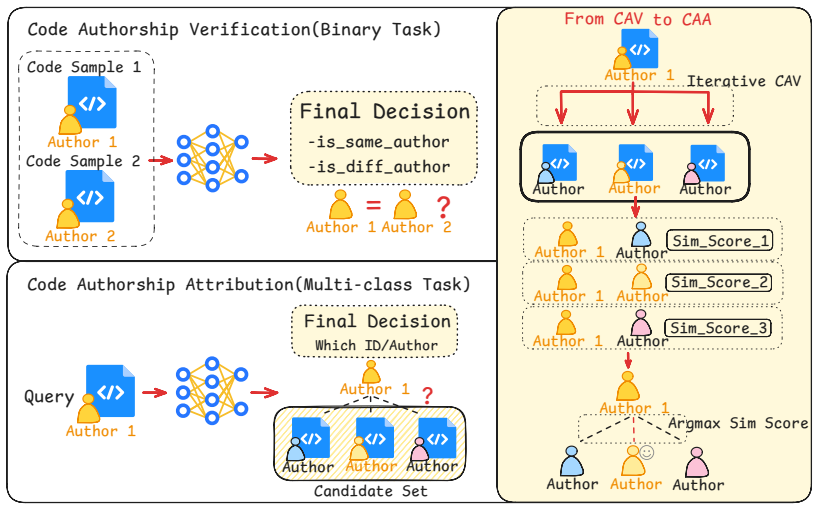
MACAA verifies code authorship for unseen authors and mixed languages by revising beliefs across four expert agents without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MACAA achieves 89.15% F1 on same-language benchmarks and 80.00% F1 on mixed cross-language pairs by letting a coordinator integrate and correct evidence from four expert agents on layout, lexical, syntactic, and programming-pattern properties, outperforming baselines on most tasks while remaining competitive on all.
What carries the argument
The belief-revision cycle performed by the Coordinator: it expands reliable expert signals, contracts unreliable ones through discounting, and revises to resolve conflicts while preserving overall consistency.
If this is right
- Enables reliable authorship checks on code from previously unseen authors without collecting new labeled data or retraining.
- Improves handling of heterogeneous code pairs that mix programming languages compared with direct model prompting.
- Generates explicit traces of which evidence types supported or contradicted each authorship hypothesis.
- Lowers dependence on large supervised datasets for applications such as software forensics and plagiarism detection.
Where Pith is reading between the lines
- The same revision structure could support real-time checks on collaborative coding repositories where author sets are constantly changing.
- Adding agents for semantic or execution-behavior evidence might extend robustness to obfuscated or translated code.
- Scaling tests on broader open-world collections would clarify whether performance holds when language diversity increases further.
Load-bearing premise
The four expert agents extract accurate layout, lexical, syntactic, and programming-pattern evidence from code without introducing systematic hallucinations or biases that the coordinator cannot detect and fix.
What would settle it
A set of known authorship-mismatched code pairs on which the expert agents produce conflicting or incorrect signals and the coordinator's revision process still outputs the wrong verification decision.
Figures

read the original abstract
Code authorship attribution (CAA) supports software forensics, plagiarism detection, and intellectual property protection. However, existing supervised CAA approaches suffer from scarce training data and closed-world assumptions: they require sufficient labeled code from fixed candidate-author sets, making training difficult in low-data cases and predictions unreliable for open-world test pairs with unseen samples, or heterogeneous code pairs. Large language models remove task-specific training, but direct prompting depends on costly expert-designed prompts, can hallucinate over complex heterogeneous code pairs, and rarely yields auditable evidence traces. We propose MACAA, a belief-revision-based multi-agent framework for training-free code authorship verification. MACAA comprises a Coordinator and four Expert Agents analyzing layout, lexical, syntactic, and programming-pattern evidence. The Coordinator gathers expert signals for expansion, discounts unreliable evidence through contraction, and resolves conflicts through revision to preserve belief consistency, replacing direct LLM judgment with auditable hypothesis refinement. MACAA achieves 89.15\% F1 on same-language benchmarks and 80.00\% on mixed cross-language pairs, outperforming all baselines on most benchmarks and remaining competitive on all.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MACAA, a training-free multi-agent framework for open-world code authorship verification. It consists of a Coordinator agent and four Expert Agents that extract layout, lexical, syntactic, and programming-pattern evidence from code pairs. The Coordinator performs belief expansion, contraction of unreliable signals, and revision to maintain consistency, replacing direct LLM prompting with auditable hypothesis refinement. The manuscript reports that MACAA achieves 89.15% F1 on same-language benchmarks and 80.00% F1 on mixed cross-language pairs, outperforming baselines on most evaluated settings.
Significance. If the performance claims and the reliability of the agent-based evidence extraction hold, the work would offer a practical advance for code authorship attribution in low-data and heterogeneous settings. By framing LLM reasoning as explicit belief revision rather than opaque prompting, it could improve auditability in software forensics and plagiarism detection while avoiding the closed-world assumptions of supervised classifiers.
major comments (3)
- [Abstract] Abstract and evaluation section: the reported 89.15% F1 (same-language) and 80.00% F1 (cross-language) are presented without any description of the underlying datasets, benchmark splits, number of authors, code lengths, or evaluation protocol (e.g., how pairs are sampled or how open-world unseen authors are handled). These numbers are load-bearing for the central claim of outperforming baselines.
- [§3] Section 3 (framework description): the belief-revision process is described at a high level (expansion, contraction, revision) but supplies neither the prompt templates used by the four Expert Agents nor any mechanism or example showing how the Coordinator detects and corrects systematic hallucinations (e.g., misparsed syntax on mixed-language pairs). Without this, it is impossible to verify that performance gains arise from the revision architecture rather than prompt engineering.
- [Results] Results and analysis: no error analysis, confusion matrices, or case studies are provided for the mixed-language setting where the weakest assumption (reliable extraction by expert agents) is most likely to fail. This omission leaves the 80.00% cross-language figure without supporting evidence that the coordinator successfully revises conflicting signals.
minor comments (2)
- [§3] Notation for agent roles and belief states is introduced without a compact summary table or diagram, making it harder to follow the flow from expert signals to final decision.
- [Abstract] The abstract claims the method is 'parameter-free' yet the framework description implies several design choices (agent prompts, revision thresholds) that function as hyperparameters; this tension should be clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving transparency and verifiability. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results and framework.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation section: the reported 89.15% F1 (same-language) and 80.00% F1 (cross-language) are presented without any description of the underlying datasets, benchmark splits, number of authors, code lengths, or evaluation protocol (e.g., how pairs are sampled or how open-world unseen authors are handled). These numbers are load-bearing for the central claim of outperforming baselines.
Authors: We agree that the abstract should be more self-contained for readers. In the revised manuscript, we will expand the abstract with a concise description of the datasets (including number of authors, average code lengths, and benchmark splits), the open-world evaluation protocol (pair sampling and handling of unseen authors), and the cross-language mixing procedure. Full experimental details will remain in Section 4, but this addition will make the performance claims immediately verifiable from the abstract. revision: yes
-
Referee: [§3] Section 3 (framework description): the belief-revision process is described at a high level (expansion, contraction, revision) but supplies neither the prompt templates used by the four Expert Agents nor any mechanism or example showing how the Coordinator detects and corrects systematic hallucinations (e.g., misparsed syntax on mixed-language pairs). Without this, it is impossible to verify that performance gains arise from the revision architecture rather than prompt engineering.
Authors: We acknowledge that explicit prompt templates and a worked example of hallucination correction are necessary for reproducibility and to isolate the contribution of belief revision. We will add all four Expert Agent prompt templates to a new appendix. We will also insert a concrete example in Section 3 (with a mixed-language code pair) showing how the Coordinator detects inconsistent signals (e.g., syntax misparse) via contraction and performs revision to reach a consistent belief state, thereby clarifying that gains derive from the architecture rather than prompt engineering alone. revision: yes
-
Referee: [Results] Results and analysis: no error analysis, confusion matrices, or case studies are provided for the mixed-language setting where the weakest assumption (reliable extraction by expert agents) is most likely to fail. This omission leaves the 80.00% cross-language figure without supporting evidence that the coordinator successfully revises conflicting signals.
Authors: We agree that the absence of error analysis weakens support for the cross-language claim. In the revision, we will add a new subsection under Results that includes (i) confusion matrices for the mixed-language setting, (ii) quantitative breakdown of error types (e.g., layout vs. syntactic conflicts), and (iii) 2–3 qualitative case studies illustrating how the Coordinator identifies and revises conflicting expert signals to arrive at the final attribution. This will directly demonstrate the revision mechanism’s effectiveness where extraction reliability is lowest. revision: yes
Circularity Check
No significant circularity; framework independently constructed and evaluated against external baselines
full rationale
The paper presents MACAA as a training-free multi-agent belief-revision architecture consisting of a Coordinator and four Expert Agents for layout, lexical, syntactic, and pattern analysis. No equations, fitted parameters, or self-citations appear in the provided text that reduce any central claim to its own inputs by construction. The reported F1 scores (89.15% same-language, 80% cross-language) are framed as empirical measurements against external baselines rather than predictions derived from the framework's own definitions or prior self-citations. The derivation chain is self-contained: the framework is specified directly, and performance is assessed externally without any load-bearing reduction to fitted values or self-referential theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert agents can extract reliable layout, lexical, syntactic, and programming-pattern evidence from code without task-specific training.
invented entities (2)
-
Coordinator agent
no independent evidence
-
Four Expert Agents
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MACAA comprises a Coordinator and four Expert Agents analyzing layout, lexical, syntactic, and programming-pattern evidence. The Coordinator gathers expert signals for expansion, discounts unreliable evidence through contraction, and resolves conflicts through revision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2105.12655 (2021)
Scs-gan: learning functionality-agnostic sty- lometric representations for source code authorship verification.IEEE Transactions on Software Engi- neering, 49(4):1426–1442. Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, and 1 others. 2021. Codenet: A large...
- [2]
-
[3]
In Advances in Neural Information Processing Systems (NeurIPS)
A-mem: Agentic memory for LLM agents. In Advances in Neural Information Processing Systems (NeurIPS). Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In11th International Conference on Learn- ing Representations, ICLR 2023. A Evaluation Protocol a...
work page 2023
-
[4]
naming: both codes use short, lowercase-dominant identifiers (avg_len<3), suggesting consistent personal naming compression habit
-
[5]
structure: both adopt flat, single-block scripts without helper functions or abstractions
-
[6]
comment: both are comment-free, aligning with rapid-competition authoring style
-
[7]
Listing 1: Coordinator: configuration and preliminary review
confounders: competitive template, language_syntax may mimic author-level consistency. Listing 1: Coordinator: configuration and preliminary review. Expert Evidence.Four Expert Agents analyze complementary dimensions in parallel via ReAct tool loops. [LAYOUT] s=0.32, conf=0.58 -> different Python: space (37/37), avg_indent=7.28, indent_std=3.37, comma_tig...
-
[8]
Source-code verified: flag at time-judge entry, is_half at same logic position
Lexical (s=0.52, conf=0.68): flag->is_half chain is stable, ecosystem-independent. Source-code verified: flag at time-judge entry, is_half at same logic position
-
[9]
Rechecked 2x, no counter found
Layout (s=0.32) downweighted: Tab/Space attributed to language ecosystem (Py=space, C++=Tab). Rechecked 2x, no counter found
-
[10]
Syntactic/Pattern uncertain but do not contradict. opponent notes: Tab/Space persistence >85% in literature; but no evidence author systematically switched. process: 4 rounds, 1 debate, 2 rechecks, 35/40 LLM calls. anchored: PRELIMINARY same@0.62. Listing 6: Layout recheck and final decision. The final decision (same_author, 0.79) agrees with the ground t...
-
[11]
Current uncertainty? (which layout dims lack/conflict evidence)
-
[12]
Candidate tool's new info? (expected distinguishing signals)
-
[13]
Why now? (max info gain, complementary, avoid repetition) ReAct Structure per step:
-
[14]
Thought: current uncertainty dimension, expected signals, causal link from previous observation
-
[15]
Priority: uncovered > complementary > conflict resolution
Action: select tool. Priority: uncovered > complementary > conflict resolution
-
[16]
Assess template/task influence; downweight if affected
Observation: convert output to 1-3 signals. Assess template/task influence; downweight if affected
-
[17]
Stop: when coverage met or budget exhausted. Output evidence: summary (one-line style portrait), signals (per dimension), confidence (0-1, stability confidence, not same-author). Output (strict JSON only, no text/markdown/fences): Continue: {"thought":"...", "action":{"type":"tool", "name":"tool_name"}, "stop":false} Stop: {"thought":"...","action": {"typ...
-
[18]
whitespace_profile: avg_indent, tab/space lines, avg_line_length, empty_line_ratio, trailing_space_lines, indent_std
-
[19]
delimiter_layout_profile: control_space_before_paren, control_tight_before_paren, comma_space/tight, same_line_block_opener, next_line_block_opener
-
[20]
comment_layout_profile: comment_line_ratio, inline_comments, standalone_comments, doc_comments
-
[21]
format_stability_profile: indent_switch_rate, line_length_std Key judgment principles: - Indentation and spacing preferences are strong author signals. - Delimiter formatting habits (if(x) vs if (x)) are stable. - Comment style aids judgment but content is task-influenced. - Large code-size differences distort absolute metrics; focus on ratios. - Layout i...
-
[22]
token_frequency_profile: keyword_ratio, identifier_ratio, operator_ratio, punctuation_ratio, token_top
-
[23]
token_ngram_profile: token_bigrams, abstract_token_trigrams, longest_repeated_sequence
-
[24]
char_ngram_profile: char_4gram, char_5gram
-
[25]
identifier_style_profile: identifier_cases, avg_length, unique_ratio, digit_ratio, underscore_ratio
-
[26]
abstract_lexical_profile: abstract distributions + bigrams Key principles: - Naming style = strong author signal (snake_case vs camelCase, identifier length, abbreviation habits). Stable across projects. - Abstract templates > concrete tokens. "if(ID)" vs "if(ID==NUM)". - Same-author/different-problem: trust identifier_style, abstract_lexical, char_ngram ...
-
[27]
ast_node_profile: node type ratios (degraded mode possible)
-
[28]
ast_path_profile: parent_child_pairs, sibling_pairs
-
[29]
tree_shape_profile: max_depth, avg_branching, branching_std, node_count
-
[30]
construct_usage_profile: if/for/while/switch/return ratios
-
[31]
[Optional] Dolos: dolos_similarity, total_overlap, longest_fragment (reference only) Key principles: - AST paths + context = core author signals. - Tree shape = structural thinking (nested vs flat). - Control-structure prefs (for vs while, early return) = stable. - Size differences: compare RATIOS, not absolutes. - Degraded mode: reduce confidence. - Simi...
-
[32]
function_metric_profile: function_count, avg_lines_per_function, return_per_function, avg_line_length
-
[33]
control_strategy_profile: guard_if_ratio, recursive_function_hints, loop_count, if_count
-
[34]
api_idiom_profile: api_families; plugin_flags
-
[35]
semantic_habit_profile: short_temp_ratio, helper_name_ratio, uppercase_constant_ratio, assert_like_count Key principles: - Function size + organization = stable. - Control strategy = core author signal (guard clause, recursion). - Semantic habits = strong signals: temp variable naming (i/j/k vs x/y/z), helper naming, constant style. - Code-size difference...
- [36]
- [37]
- [38]
-
[39]
Statistical Cues 10. Idiosyncratic. Hard Rules: no default to different_author from artifacts; mark confounders; balanced same/different. Output: {overall_first_impression, candidate_style_axes[], suspected_confounders[], dimension_routing{layout/lexical/ syntactic/pattern{priority,why,focus_question}}, global_questions[], do_not_overtrust[]} Listing 15: ...
-
[40]
FINALIZE: evidence sufficient or budget exhausted
-
[41]
RECHECK_DIMENSION: low-confidence/high-impact dimension
-
[42]
START_DEBATE: two dimensions in conflict
-
[43]
ADJUST_WEIGHTS: post-debate/recheck credibility shift. Priority: no conflict+full evidence > FINALIZE; preliminary conflict > RECHECK; two expert dims conflict > DEBATE. Mandatory: dim-divergence check (dim<0.40 + dim>=0.60 => DEBATE/ RECHECK). LLM comparison failure => must RECHECK. Debate participants = real dimensions only (layout|lexical|syntactic|pat...
-
[44]
Evidence Sufficiency: all dimensions covered? concrete signals?
-
[45]
Conflict Resolution: cross-dimension conflicts explained?
-
[46]
Marginal Gain: how much new info could further investigation yield? Low-Similarity Veto Rule: - A dimension with similarity_score < 0.40 is "suspect." - Suspect dims prevent evidence_sufficient unless: (a) after debate/recheck, similarity rises to >= 0.45, OR (b) the gap is confirmed as task/algorithm-driven, not style. - With 2+ suspect dims, prefer CONT...
-
[47]
Ruling: conflict resolved?
-
[48]
Tracing: dimension credibility update?
-
[49]
New Evidence: source-level insights from debate
-
[50]
Corrections: which dimension reports need revision? Evaluation: source consistency, preliminary review alignment, external consistency (one dim contradicts others?), argument strength (who provided more verifiable observations?). Required tasks: determine conflict resolution, assess which side is more persuasive, update dimension credibility, extract new ...
-
[51]
After re-reading code, overall gut tendency?
-
[52]
Which dims support same_author? different_author? uncertain?
-
[53]
Is preliminary confirmed/weakened/overturned?
-
[54]
Did debate bring genuinely new evidence?
-
[55]
- Overturning preliminary requires explanation
Was reflection's advice adopted? Hard Rules: - No numeric anchors; uncertain != different_author. - Overturning preliminary requires explanation. - different_author requires >=2 moderate different dims OR 1 strong structural counter-evidence (confounder_risk=low) + debate. - Mixed evidence (2 same + 2 different) => uncertain. - Cross-lang: syntactic = wea...
-
[56]
author_stable_signals: similarities persisting across problems
-
[57]
different_author_signals: contrasts supporting different authors
-
[58]
neutral_or_confounding_signals: overlaps better explained by templates, tasks, ecosystems, or language defaults. Prioritize: {per-dimension stable_focus items} Different-author cues: {per-dimension different_focus items} Actively discount: {per-dimension confounders} Return exactly one JSON object: {tendency, similarity_score, confidence, summary, author_...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.