Recognition: 2 theorem links
· Lean TheoremSimWorld Studio: Automatic Environment Generation with Evolving Coding Agent for Embodied Agent Learning
Pith reviewed 2026-05-12 04:17 UTC · model grok-4.3
The pith
A self-evolving coding agent generates adaptive 3D environments that raise embodied agent navigation success rates by 18 points over fixed setups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
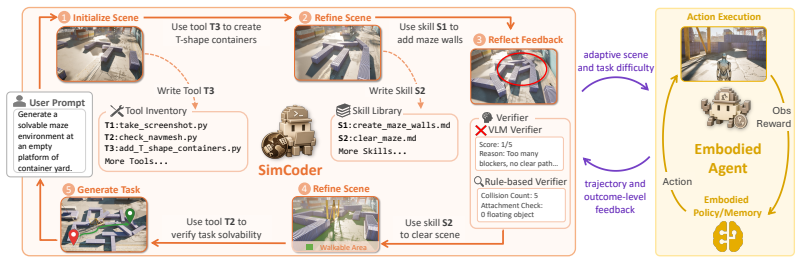
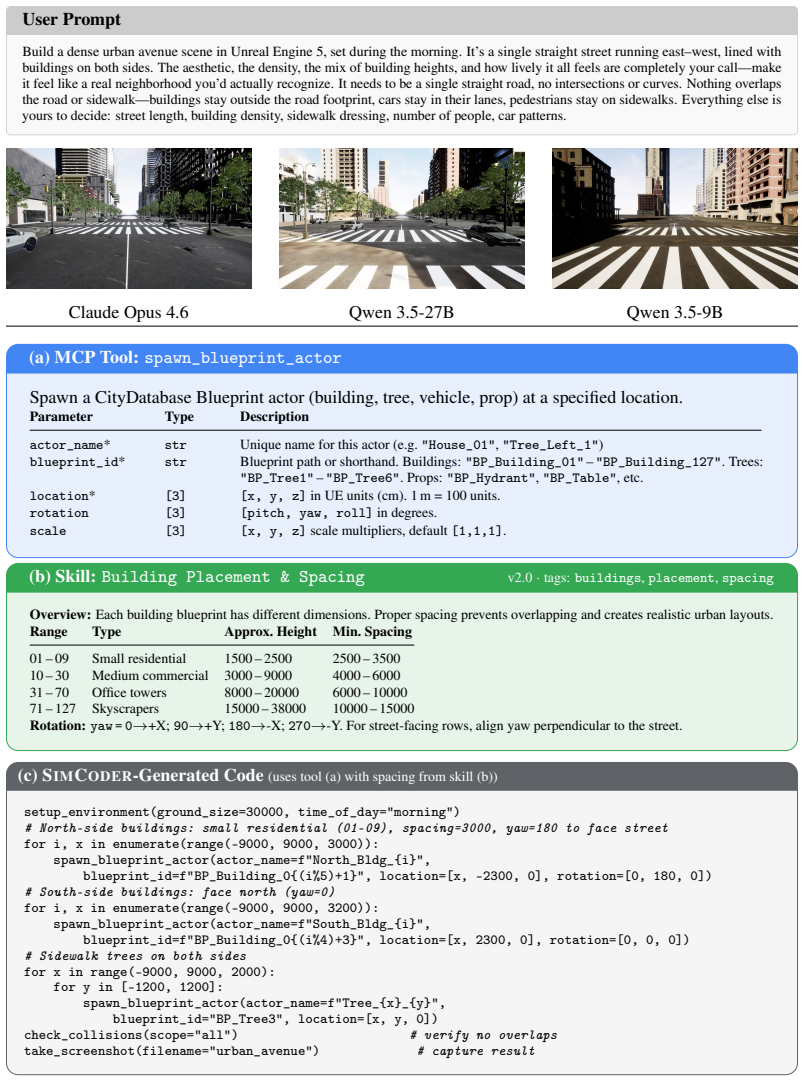
SimWorld Studio uses SimCoder, a tool- and skill-augmented coding agent, to write and execute engine-level code that builds physically grounded 3D worlds from language or image instructions. SimCoder self-evolves by incorporating verifier signals such as compilation errors, physics checks, and VLM critiques to revise environments and expand its own library. The platform exports these worlds as Gym-style interfaces and enables co-evolution: embodied agent performance feedback guides SimCoder to generate adaptive curricula near the learner's current capability frontier, producing environments that become progressively more challenging.
What carries the argument
SimCoder, the self-evolving coding agent that generates, executes, and refines Unreal Engine code for task-verifiable 3D environments while adapting outputs based on embodied agent performance signals.
Load-bearing premise
Verifier feedback from compilation errors, physics checks, and visual-language critiques is sufficient to produce reliable, task-verifiable, and physically consistent environments without hidden manual curation.
What would settle it
A replication experiment that measures navigation success rates on held-out benchmarks and finds no statistically significant difference between agents trained in co-evolved SimWorld environments versus agents trained in fixed or randomly generated scenes would falsify the claimed benefit of co-evolution.
Figures








read the original abstract
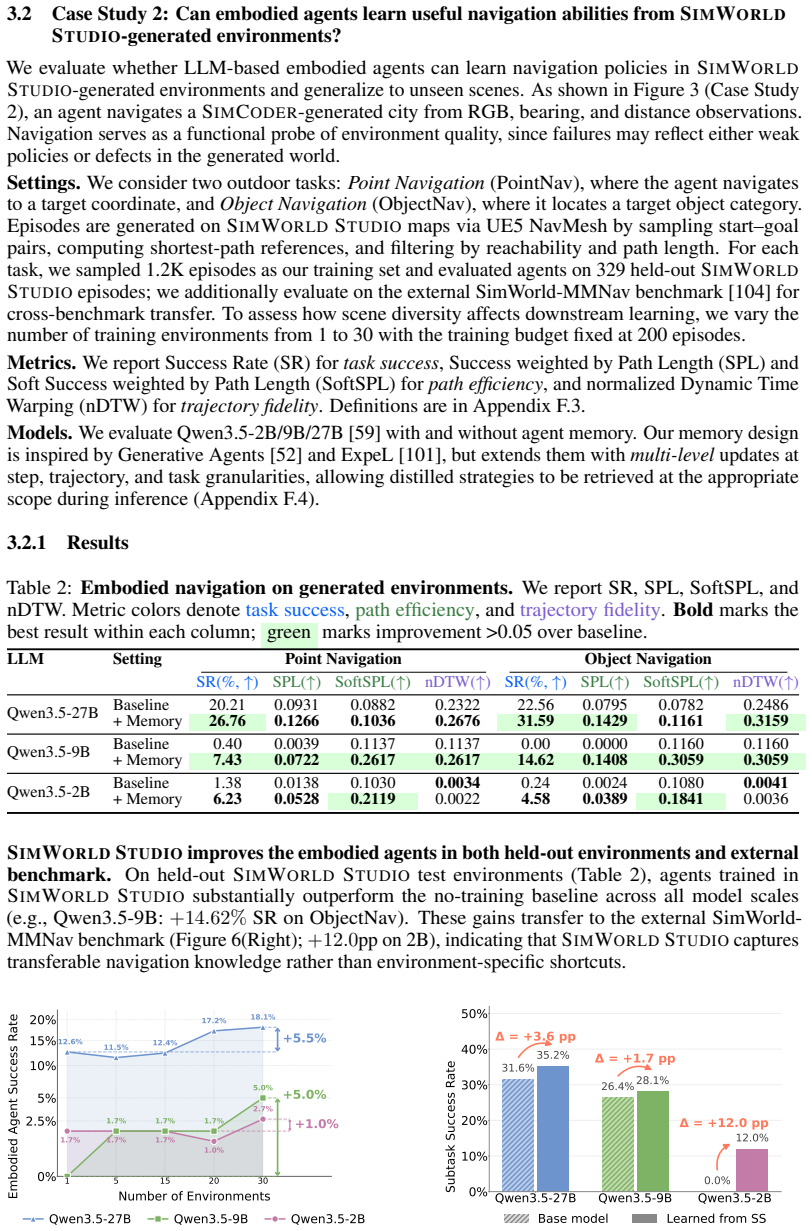
LLM/VLM-based digital agents have advanced rapidly thanks to scalable sandboxes for coding, web navigation, and computer use, which provide rich interactive training grounds. In contrast, embodied agents still lack abundant, diverse, and automatically generated 3D environments for interactive learning. Existing embodied simulators rely on manually crafted scenes or procedural templates, while recent LLM-based 3D generation systems mainly produce static scenes rather than deployable environments with verifiable tasks and standard learning interfaces. We introduce SimWorld Studio, an open-source platform built on Unreal Engine 5 for generating evolving embodied learning environments. At its core is SimCoder, a tool/skill-augmented coding agent that writes and executes engine-level code to construct physically grounded 3D worlds from language/image instructions. SimCoder self-evolves by using verifier feedback (e.g., compilation errors, physics checks, VLM critiques) to revise environments and autonomously add reusable tools and skills to its library. Generated worlds are exported as Gym-style environments for embodied agent learning. SimWorld Studio further enables co-evolution between environment generation and embodied learning: agent performance feedback guides SimCoder to generate adaptive curricula near the learner's capability frontier, so that environments become increasingly challenging as the embodied agent improves. Three case studies on embodied navigation show that self-evolution improves generation reliability, generated environments substantially improve embodied agent performance that generalizes to unseen benchmarks, and co-evolution yields an 18-point success-rate gain over fixed-environment learning and a 40-point gain over an untrained agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SimWorld Studio, an open-source platform on Unreal Engine 5 that employs SimCoder, an LLM/VLM-augmented coding agent, to generate physically grounded 3D environments from language or image instructions. SimCoder self-evolves by revising code based on verifier feedback including compilation errors, physics checks, and VLM critiques, while also autonomously expanding its tool and skill library. The system supports co-evolution by using embodied agent performance signals to generate adaptive curricula near the learner's capability frontier. Generated environments are exported as Gym-style interfaces. Three case studies on embodied navigation tasks claim that self-evolution improves generation reliability, that the generated environments substantially boost embodied agent performance with generalization to unseen benchmarks, and that co-evolution delivers an 18-point success-rate gain over fixed-environment learning and a 40-point gain over an untrained agent.
Significance. If the reported performance gains and automatic generation claims hold under rigorous validation, the work would be significant for embodied AI research by providing a scalable alternative to manually crafted or template-based simulators. The open-source release of the platform and the export of environments to standard Gym-style interfaces are explicit strengths that support reproducibility and community extension. The co-evolution loop, which ties environment adaptation directly to agent progress, offers a concrete mechanism for dynamic curriculum generation that could influence future training paradigms.
major comments (2)
- [Abstract] Abstract: The headline claims of an 18-point success-rate gain from co-evolution versus fixed-environment learning and a 40-point gain versus an untrained agent are presented without any description of the experimental protocol, baseline agent definitions, trial counts, statistical tests, or variance measures. This is load-bearing for the central empirical claim because the deltas cannot be assessed for support or attribution to the co-evolution mechanism.
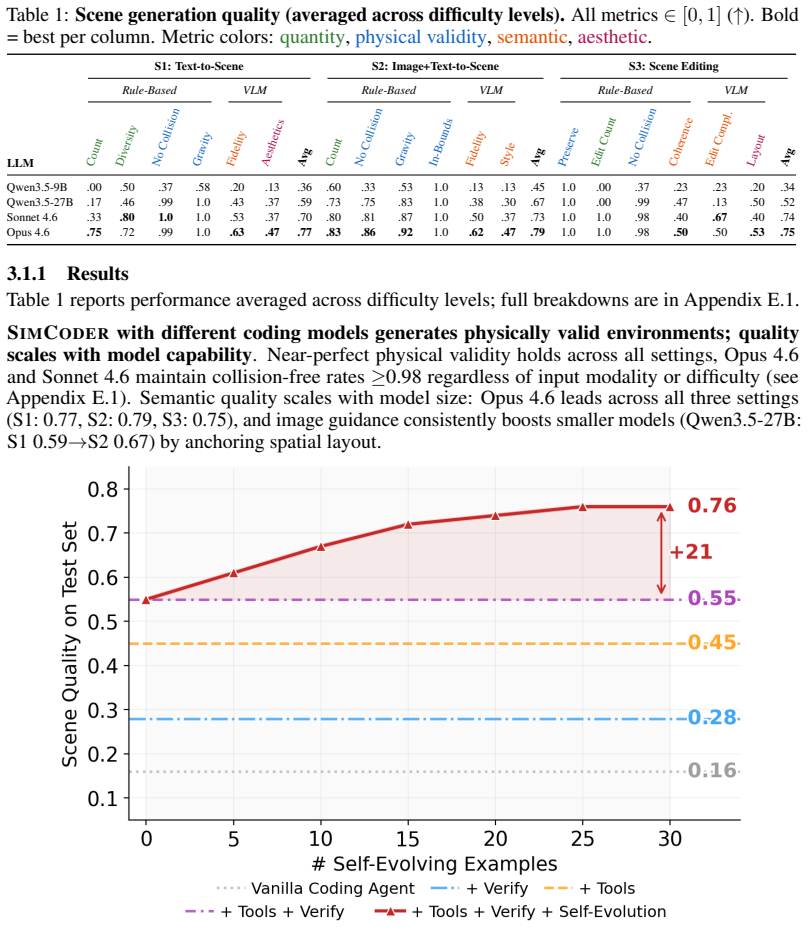
- [Abstract] Abstract: The assertion that verifier feedback (compilation errors, physics checks, VLM critiques) suffices to produce reliable, task-verifiable, and physically consistent environments at scale is unsupported by any quantitative data on generation success rates, failure modes, inter-rater consistency of VLM critiques, or the fraction of outputs requiring post-editing. This directly undermines attribution of the reported agent performance improvements to the claimed fully automatic regime.
minor comments (1)
- The abstract would be clearer if it briefly named the specific navigation tasks and benchmarks used in the three case studies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional context is needed to support the headline claims and will revise accordingly while preserving the abstract's brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of an 18-point success-rate gain from co-evolution versus fixed-environment learning and a 40-point gain versus an untrained agent are presented without any description of the experimental protocol, baseline agent definitions, trial counts, statistical tests, or variance measures. This is load-bearing for the central empirical claim because the deltas cannot be assessed for support or attribution to the co-evolution mechanism.
Authors: We agree that the abstract should enable readers to assess the central empirical claims without immediately consulting the full text. In the revision we will expand the abstract with a concise description of the navigation task protocol, explicit definitions of the baseline agents (fixed-environment training and untrained agent), the number of independent trials, and a note that variance measures and statistical tests support the reported 18- and 40-point gains. Full experimental details, including per-seed results and significance testing, remain in the results section. revision: yes
-
Referee: [Abstract] Abstract: The assertion that verifier feedback (compilation errors, physics checks, VLM critiques) suffices to produce reliable, task-verifiable, and physically consistent environments at scale is unsupported by any quantitative data on generation success rates, failure modes, inter-rater consistency of VLM critiques, or the fraction of outputs requiring post-editing. This directly undermines attribution of the reported agent performance improvements to the claimed fully automatic regime.
Authors: The manuscript's case studies show that self-evolution raises generation reliability, yet we acknowledge the abstract itself contains no quantitative metrics. We will revise the abstract to report the key statistics obtained in our experiments (generation success rate with versus without verifier feedback, fraction of outputs requiring no post-editing, and observed failure modes). We will also add a short methods subsection on VLM critique consistency and the fraction of environments that passed all automated checks without human intervention. revision: yes
Circularity Check
No circularity: empirical system description with no derivations or self-referential reductions
full rationale
The paper presents SimWorld Studio as an implemented platform with SimCoder for automatic environment generation and co-evolution, supported by three navigation case studies reporting performance deltas. No equations, fitted parameters, or mathematical derivations appear in the provided text. Claims rest on observed success-rate gains rather than any step that reduces by construction to its own inputs, self-citations, or renamed ansatzes. The central results are system-level empirical outcomes, not predictions forced by definition or prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Unreal Engine 5 supplies accurate and stable physics for generated 3D scenes
- ad hoc to paper VLM critiques and compilation errors are sufficient to detect and correct environment defects
invented entities (2)
-
SimCoder
no independent evidence
-
SimWorld Studio
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearSimCoder self-evolves by using verifier feedback (e.g., compilation errors, physics checks, VLM critiques) to revise environments and autonomously add reusable tools and skills
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearco-evolution yields an 18-point success-rate gain over fixed-environment learning
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.