Recognition: 2 theorem links
· Lean TheoremInverse Design for Conditional Distribution Matching
Pith reviewed 2026-05-12 04:43 UTC · model grok-4.3
The pith
A method finds inputs whose outputs match any user-specified distribution using only pretrained models at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
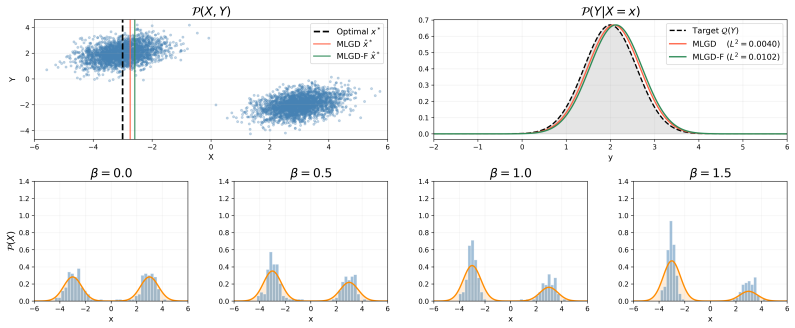
Conditional Distribution Matching is defined as the inverse-design task of finding x* given joint P(X, Y) and target G(Y) so that P(Y | X = x*) equals G. MLGD-F achieves this by combining a pretrained score-based diffusion model with a single-step fast conditional sampler to compute matching-loss gradients tractably at inference time, enabling both sampling and optimization variants of the problem.
What carries the argument
MLGD-F (Matching-Loss Guided Diffusion with a Fast inner sampler), which uses single-step conditional sampling inside a diffusion process to estimate conditional distributions and their gradients memory-efficiently.
If this is right
- Inputs can be recovered whose conditionals match discrete mixture targets using only pretrained components.
- Continuous low-rank support distributions become reachable in generative editing without retraining.
- Structured image transformations can be performed by optimizing for full distributional targets rather than single points.
- The method remains lightweight because single-step sampling replaces repeated full diffusion runs during gradient steps.
Where Pith is reading between the lines
- The same inference-time guidance pattern could be tested on other generative backbones that admit fast conditional sampling.
- Distributional targets could be used to encode higher-level requirements such as diversity or safety constraints in downstream design pipelines.
- The framework naturally extends to sequential or multi-step design tasks where each step must induce a controlled output distribution.
Load-bearing premise
That a pretrained score-based diffusion model and a pretrained fast conditional sampler can be combined at inference time to compute accurate gradients for matching arbitrary target distributions without any model updates.
What would settle it
An experiment in which the empirical distribution of outputs generated from the recovered x* fails to match the modes, variances, or support of a specified discrete mixture or low-rank continuous target G.
Figures
















read the original abstract
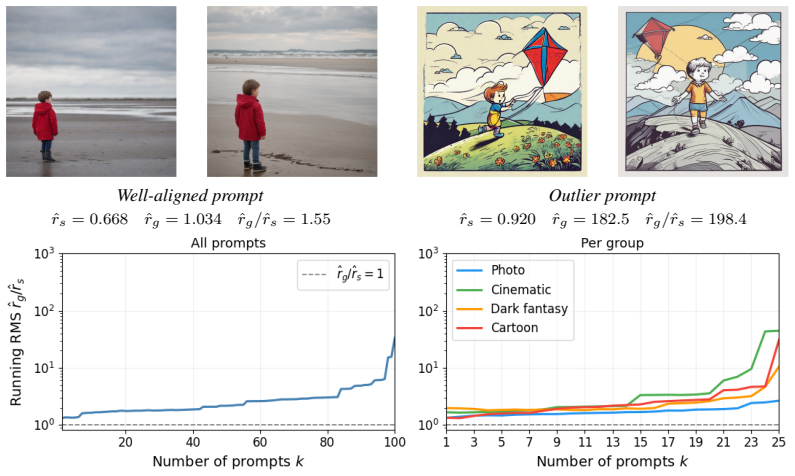
Generative models are powerful tools for sampling from a learned distribution $\mathcal{P}(Y \mid X)$, and inverse-design methods invert this map to find an input $x$ that produces a desired point output $y^*$. However, many design goals are naturally distributional rather than pointwise, incorporating the inherent uncertainty of $Y$ and targeting a specific form for it, a task not addressed by standard inverse design. To address this issue we introduce Conditional Distribution Matching (CDM), a new inverse-design problem class in generative modeling: given a joint distribution $\mathcal{P}(X, Y)$ and a target distribution $\mathcal{G}(Y)$, find an input $x^*$ whose induced conditional distribution $\mathcal{P}(Y \mid X = x^*)$ matches $\mathcal{G}$. We formally define two variants: Conditional Distribution Matching Sampling (CDMS) and Conditional Distribution Matching Optimization (CDMO). To solve these problems, we propose MLGD-F (Matching-Loss Guided Diffusion with a Fast inner sampler), a plug-and-play inference-time algorithm that combines a pretrained score-based diffusion model with a pretrained fast conditional sampler, requiring no additional training or fine-tuning. By leveraging single-step conditional sampling, MLGD-F enables tractable gradient computation, making the estimation of $\mathcal{P}(Y \mid X)$ both memory-efficient and computationally lightweight. We validate MLGD-F on synthetic benchmarks, structured image transformations, and generative editing optimization, demonstrating reliable recovery of inputs whose conditional distributions match diverse user-specified targets, including discrete mixtures and continuous low-rank supports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Conditional Distribution Matching (CDM) as a new inverse-design problem class: given joint P(X,Y) and target G(Y), recover x* such that the induced conditional P(Y|X=x*) matches G. It defines CDMS and CDMO variants and proposes MLGD-F, a plug-and-play inference-time algorithm that pairs a pretrained score-based diffusion model with a pretrained fast conditional sampler. MLGD-F uses single-step sampling to enable tractable gradient estimation of a matching loss without any retraining or fine-tuning. Experiments on synthetic benchmarks, structured image transformations, and generative editing tasks are reported to demonstrate recovery of inputs whose conditionals match diverse targets, including discrete mixtures and continuous low-rank supports.
Significance. If the central claims hold, the work would be significant for extending inverse design beyond pointwise targets to distributional ones in a training-free manner. The plug-and-play use of independently pretrained models is a clear strength, as is the focus on memory-efficient gradient computation via single-step sampling. This could enable new applications in generative editing and optimization where the shape of the output distribution (rather than a single point) is the design goal.
major comments (2)
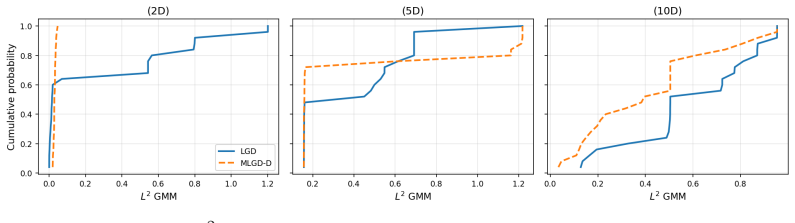
- [§3] §3 (MLGD-F algorithm description): the gradient of the matching loss is computed by replacing the inner conditional expectation E_{Y~P(Y|X)} with a single draw from the pretrained fast conditional sampler. No error bound, bias analysis, or convergence guarantee is supplied for this one-step surrogate. This is load-bearing for the central claim, because the fixed point of the outer optimization is asserted to recover an x* whose true multi-step conditional equals arbitrary G(Y), including discrete mixtures and low-rank supports where one-step outputs are known to deviate from the true conditional.
- [Experiments] Experiments section (synthetic and image-editing results): the reported successes on targets with discrete or low-rank structure are not accompanied by controls that compare single-step versus multi-step inner sampling, nor by quantitative metrics (e.g., Wasserstein distance or support overlap) between the induced P(Y|X=x*) and the target G after optimization. Without these, it is impossible to determine whether the method actually achieves distributional matching or merely pointwise proximity.
minor comments (2)
- [Abstract and §2] The abstract and §2 claim the method is 'parameter-free' at inference time, yet the choice of step size, number of outer optimization steps, and the specific fast sampler architecture are hyperparameters that affect results; a short discussion of their sensitivity would improve clarity.
- [§2 and Experiments] Notation for the two problem variants (CDMS vs. CDMO) is introduced but not used consistently in the experimental tables; labeling which tasks correspond to which variant would aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of the theoretical justification and empirical validation of MLGD-F. Below we respond point-by-point to the major comments and describe the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (MLGD-F algorithm description): the gradient of the matching loss is computed by replacing the inner conditional expectation E_{Y~P(Y|X)} with a single draw from the pretrained fast conditional sampler. No error bound, bias analysis, or convergence guarantee is supplied for this one-step surrogate. This is load-bearing for the central claim, because the fixed point of the outer optimization is asserted to recover an x* whose true multi-step conditional equals arbitrary G(Y), including discrete mixtures and low-rank supports where one-step outputs are known to deviate from the true conditional.
Authors: We agree that the single-step approximation for the inner expectation introduces bias whose magnitude is not bounded in the current manuscript, and that this approximation is central to the tractability claim. The manuscript relies on the empirical observation that the outer optimization still recovers x* values whose full multi-step conditionals align with G, even on targets with discrete or low-rank structure. In the revision we will add a dedicated paragraph in §3 discussing the nature of the bias (including why single-step sampling from a fast conditional model can still yield useful gradients for the outer objective) and will include a short empirical study of the approximation error on the synthetic benchmarks. We will not claim formal convergence guarantees, as deriving them would require additional assumptions on the fast sampler that go beyond the plug-and-play setting. revision: partial
-
Referee: [Experiments] Experiments section (synthetic and image-editing results): the reported successes on targets with discrete or low-rank structure are not accompanied by controls that compare single-step versus multi-step inner sampling, nor by quantitative metrics (e.g., Wasserstein distance or support overlap) between the induced P(Y|X=x*) and the target G after optimization. Without these, it is impossible to determine whether the method actually achieves distributional matching or merely pointwise proximity.
Authors: We accept that the current experimental section would be strengthened by quantitative metrics and explicit single-step versus multi-step controls. In the revised manuscript we will augment the synthetic benchmark results with (i) Wasserstein-2 distances and support-overlap statistics between the induced conditional (evaluated with multi-step sampling) and the target G, and (ii) side-by-side tables comparing optimization outcomes when the inner sampler is restricted to one step versus the full multi-step procedure. These additions will be placed in the main experiments section and will directly address whether distributional matching (rather than pointwise proximity) is achieved. revision: yes
Circularity Check
No circularity in CDM definition or MLGD-F algorithm
full rationale
The paper defines a new inverse-design problem class (CDM) and presents MLGD-F as an inference-time procedure that combines two independently pretrained models with no additional training or fine-tuning. No equations reduce a claimed prediction or result to a fitted parameter defined by the same data, no self-citation chain is load-bearing for the central claim, and the derivation consists of problem formalization plus algorithmic description rather than tautological reduction. The method is explicitly positioned as operating on external pretrained components, making the overall chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pretrained score-based diffusion model accurately captures the joint distribution P(X, Y) and its score function.
- domain assumption A pretrained fast conditional sampler can produce single-step samples from P(Y | X) that are accurate enough for gradient estimation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MLGD-F combines a pretrained score-based diffusion model with a pretrained fast conditional sampler... single-step conditional sampling... tractable gradient computation
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L(x) = ∥P(Y|X=x) − G(Y)∥... plug-in distributional-loss estimator... AUTOGRAD through fϕ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nearly $d$- linear convergence bounds for diffusion models via stochastic localization
Joe Benton, Valentin De Bortoli, Arnaud Doucet, and George Deligiannidis. Nearly $d$- linear convergence bounds for diffusion models via stochastic localization. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=r5njV3BsuD
work page 2024
-
[2]
Sebastian Bischoff, Alana Darcher, Michael Deistler, Richard Gao, Franziska Gerken, Manuel Gloeckler, Lisa Haxel, Jaivardhan Kapoor, Janne K. Lappalainen, Jakob H. Macke, Guy Moss, Matthijs Pals, Felix C. Pei, Rachel Rapp, A. Erdem Sa ˘gtekin, Cornelius Schröder, Auguste Schulz, Zinovia Stefanidi, Shoji Toyota, Linda Ulmer, and Julius Vetter. A practical ...
work page 2024
-
[3]
Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hy- pothesis.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=MhK5aXo3gB. Expert Certification
work page 2022
-
[4]
Monte carlo guided denoising diffusion models for Bayesian linear inverse problems
Gabriel Cardoso, Yazid Janati El Idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided denoising diffusion models for Bayesian linear inverse problems. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=nHESwXvxWK
work page 2024
-
[5]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. In International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=zyLVMgsZ0U_
work page 2023
-
[6]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Con- ference on Learning Representations, 2023. URL https://openreview.net/forum?id= OnD9zGAGT0k
work page 2023
-
[7]
Sobolev training for neural networks
Wojciech M Czarnecki, Simon Osindero, Max Jaderberg, Grzegorz Swirszcz, and Razvan Pascanu. Sobolev training for neural networks. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[8]
Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
Justas Dauparas, Ivan Anishchenko, Nathaniel Bennett, Hua Bai, Robert J Ragotte, Lukas F Milles, Basile IM Wicky, Alexis Courbet, Rob J de Haas, Neville Bethel, et al. Robust deep learning–based protein sequence design using proteinmpnn.Science, 378(6615):49–56, 2022
work page 2022
-
[9]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems, volume 34, pages 8780–8794, 2021
work page 2021
-
[10]
Diffusion posterior sampling is computationally unstable
Zehao Dou and Yang Song. Diffusion posterior sampling is computationally unstable. In International Conference on Machine Learning, 2024
work page 2024
-
[11]
Yansong Gao and Yu Sun. Distillation of discrete diffusion by exact conditional distribution matching.arXiv preprint arXiv:2512.12889, 2025
-
[12]
Learning generative models with sinkhorn divergences
Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with sinkhorn divergences. InInternational Conference on Artificial Intelligence and Statistics, volume 84, pages 1608–1617. PMLR, 2018
work page 2018
-
[13]
Rafael Gómez-Bombarelli, Jennifer N Wei, David Duvenaud, José Miguel Hernández-Lobato, Benjamín Sánchez-Lengeling, Dennis Sheberla, Jorge Aguilera-Iparraguirre, Timothy D Hirzel, Ryan P Adams, and Alán Aspuru-Guzik. Automatic chemical design using a data-driven continuous representation of molecules.ACS central science, 4(2):268–276, 2018
work page 2018
-
[14]
A kernel method for the two-sample-problem
Arthur Gretton, Karsten Borgwardt, Malte Rasch, Bernhard Schölkopf, and Alex Smola. A kernel method for the two-sample-problem. InAdvances in Neural Information Processing Systems, volume 19, 2006. 10
work page 2006
-
[15]
Protein conformational switches: from nature to design
Jeung-Hoi Ha and Stewart N Loh. Protein conformational switches: from nature to design. Chemistry–A European Journal, 18(26):7984–7999, 2012
work page 2012
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[18]
A class of statistics with asymptotically normal distribution
Wassily Hoeffding. A class of statistics with asymptotically normal distribution. InBreak- throughs in statistics: Foundations and basic theory, pages 308–334. Springer, 1992
work page 1992
-
[19]
Diffusion model for image generation-a survey
Xinrong Hu, Yuxin Jin, Jinxing Liang, Junping Liu, Ruiqi Luo, Min Li, and Tao Peng. Diffusion model for image generation-a survey. In2023 2nd International Conference on Artificial Intelligence, Human-Computer Interaction and Robotics (AIHCIR), pages 416–424. IEEE, 2023
work page 2023
-
[20]
Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
work page 1998
-
[21]
Mmd gan: Towards deeper understanding of moment matching network
Chun-Liang Li, Wei-Cheng Chang, Yu Cheng, Yiming Yang, and Barnabás Póczos. Mmd gan: Towards deeper understanding of moment matching network. InAdvances in Neural Information Processing Systems, volume 30, pages 2203–2213, 2017
work page 2017
-
[22]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Richard Zemel. Generative moment matching networks. In International Conference on Machine Learning, volume 37, pages 1718–1727. PMLR, 2015
work page 2015
-
[23]
arXiv preprint arXiv:2402.13929 (2024) 5
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation, 2024. URLhttps://arxiv.org/abs/2402.13929
-
[24]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
work page 2019
-
[25]
On the method of bounded differences
Colin McDiarmid. On the method of bounded differences. In J. Siemons, editor,Surveys in Combinatorics, 1989, volume 141 ofLondon Mathematical Society Lecture Note Series, pages 148–188. Cambridge University Press, 1989
work page 1989
-
[26]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=aBsCjcPu_tE
work page 2022
-
[27]
K. B. Petersen and M. S. Pedersen. The matrix cookbook, nov 2012. URL http://www2. compute.dtu.dk/pubdb/pubs/3274-full.html. Version 20121115
work page 2012
-
[28]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=di52zR8xgf
work page 2024
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, volume 139, pages 8748–8763. PMLR, 2021
work page 2021
-
[30]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=TIdIXIpzhoI
work page 2022
-
[31]
Benjamin Sanchez-Lengeling and Alán Aspuru-Guzik. Inverse molecular design using machine learning: Generative models for matter engineering.Science, 361(6400):360–365, 2018. 11
work page 2018
-
[32]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, volume 86, pages 87–103. Springer,
-
[33]
doi: 10.1007/978-3-031-73016-0_6
-
[34]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, volume 37, pages 2256–2265. PMLR, 2015
work page 2015
-
[35]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP
work page 2021
-
[36]
Loss-guided diffusion models for plug-and-play controllable generation
Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. InInternational Conference on Machine Learning, volume 202, pages 32483–32498. PMLR, 2023
work page 2023
-
[37]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. In International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=WNzy9bRDvG
work page 2024
-
[38]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=PxTIG12RRHS
work page 2021
-
[39]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, volume 202, pages 32211–32252. PMLR, 2023
work page 2023
-
[40]
Diffusion models for time series forecasting: A survey.arXiv preprint arXiv:2507.14507, 2025
Chen Su, Zhengzhou Cai, Yuanhe Tian, Zhuochao Chang, Zihong Zheng, and Yan Song. Diffusion models for time series forecasting: A survey.arXiv preprint arXiv:2507.14507, 2025
-
[41]
H. J. Terry Suh, Max Simchowitz, Kaiqing Zhang, and Russ Tedrake. Do differentiable simulators give better policy gradients? InInternational Conference on Machine Learning, volume 162, pages 20668–20696. PMLR, 2022
work page 2022
-
[42]
Domain adaptation with conditional distribution matching and generalized label shift
Remi Tachet des Combes, Han Zhao, Yu-Xiang Wang, and Geoff Gordon. Domain adaptation with conditional distribution matching and generalized label shift. InAdvances in Neural Information Processing Systems, volume 33, 2020. URL https://arxiv.org/abs/2003. 04475
work page 2020
-
[43]
Luhuan Wu, Brian L. Trippe, Christian A. Naesseth, David M. Blei, and John P. Cunningham. Practical and asymptotically exact conditional sampling in diffusion models. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[44]
arXiv preprint arXiv:2303.13336 , year=
Chenshuang Zhang, Chaoning Zhang, Sheng Zheng, Mengchun Zhang, Maryam Qamar, Sung- Ho Bae, and In So Kweon. A survey on audio diffusion models: Text to speech synthesis and enhancement in generative ai, 2023. URLhttps://arxiv.org/abs/2303.13336
-
[45]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023. 12 A Synthetic Simulations: Experimental Details This appendix provides the full experimental setup for the synthetic simulations described in Sec- tion...
work page 2023
-
[46]
with a dropout probability of0.2. Sampling using DDIM [34] withη= 0. Conditional consistency model.An improved Consistency Training (iCT) model [ 36] is trained to approximate the conditional distribution P(Y|X=x) . We utilize the iCT discretization curriculum N(k) = min(s 0 ·2 ⌊k/K ′⌋, s1) + 1,(3) with s0 = 10 and s1 = 1280 . The model is optimized using...
-
[47]
superrealistic portrait photograph of a woman, extremely feminine features, studio lighting
Woman: "superrealistic portrait photograph of a woman, extremely feminine features, studio lighting"
-
[48]
Woman with masculine features: "a superrealistic portrait photograph of a woman with masculine features, heavy brow ridge, studio lighting"
-
[49]
Man with feminine features: "a superrealistic portrait photograph of a man with extremely feminine features, soft delicate face, high cheekbones, studio lighting"
-
[50]
a superrealistic portrait photograph of a man, extremely masculine features, studio lighting
Man: "a superrealistic portrait photograph of a man, extremely masculine features, studio lighting" This four-anchor discretisation approximates a continuous 1-D target on the gender-axis submanifold of CLIP space. Age interpolation target.The target is a uniform distribution over male portrait ages {40,41, . . . ,79}. For each integer age, images are gen...
-
[51]
Teacher (unrolled) gradient:reverse-mode evaluation of ∇xbL⋆(x) has per-sample chain depthΘ(K ⋆)and total stored activationsΘ(K ⋆ ·n cond)(absent checkpointing)
-
[52]
Few-step student:reverse-mode evaluation of ∇xbLϕ(x) has per-sample chain depth Θ(Ks) and total stored activationsΘ(K s ·n cond). The memory ratio is thereforeΘ(K ⋆/Ks). Gradient discrepancy.Fix x∈ X and assume ncond, ntarget ≥2 , so that the unbiased MMD U-statistics definingbLϕ and bL⋆ are well-defined. In addition to Assumption 1, suppose the follow- i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.