Recognition: 2 theorem links
· Lean TheoremOptimal Regret for Single Index Bandits
Pith reviewed 2026-05-12 05:08 UTC · model grok-4.3
The pith
Single-index bandits with general reward functions have optimal regret of order T to the two-thirds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the minimax regret for general single-index bandits is of order T to the two-thirds, up to logarithmic factors. The ZoomSIB-UCB algorithm achieves the upper bound by first using a normalized Stein estimator to recover the direction of the unknown projection, then discretizing the projected space and applying UCB to the resulting one-dimensional bandit problem. A matching minimax lower bound is established, together giving a sharp characterization of the regret.
What carries the argument
The ZoomSIB-UCB two-phase algorithm that uses normalized Stein estimation to identify the projection direction before reducing to and solving a one-dimensional UCB bandit.
Load-bearing premise
The reward function is bounded and Lipschitz continuous, and the contexts allow the normalized Stein estimator to recover the projection direction at a sufficient rate.
What would settle it
Constructing a single-index bandit instance where the minimax regret grows faster than order T to the two-thirds (ignoring log factors) would disprove the upper bound, while achieving better than that in the worst case would contradict the lower bound.
Figures



read the original abstract
We study the $\textit{single-index bandit}$ problem, where rewards depend on an unknown one-dimensional projection of high-dimensional contexts through an unknown reward function. This model extends linear and generalized linear bandits to a nonparametric setting, and is particularly relevant when the reward function is not known in advance. While optimal regret guarantees are known for monotone reward functions, the general non-monotone case remains poorly understood, with the best known bound being $\tilde{\mathcal{O}}(T^{3/4})$ (under standard boundedness and Lipschitz assumptions on the reward function [Kang et al., 2025]). We close this gap by establishing the optimal regret for general single-index bandits. We propose a simple two-phase algorithm, namely, Zoomed Single Index Bandit with Upper Confidence Bound ($\texttt{ZoomSIB-UCB}$), that first estimates the projection direction via a normalized Stein estimator, and then reduces the problem to a one-dimensional bandit using discretization and finally use UCB. This approach achieves a regret of $\tilde{\mathcal{O}}(T^{2/3})$, and improves significantly upon prior work without any additional assumptions. We also prove a matching minimax lower bound of $\tilde{\Omega}(T^{2/3})$, showing that the upper bound is essentially tight. Our upper and lower bounds together provide a sharp characterization of the regret in single-index bandits. Moreover, the empirical results further demonstrate the effectiveness and robustness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the single-index bandit problem in which rewards are given by an unknown nonparametric link function applied to an unknown one-dimensional projection of high-dimensional contexts. It proposes the two-phase ZoomSIB-UCB algorithm that first recovers the projection direction via a normalized Stein estimator on O(T^{2/3}) samples, then reduces the problem to a one-dimensional discretized bandit and applies UCB, obtaining Õ(T^{2/3}) regret. A matching minimax lower bound of Ω̃(T^{2/3}) is proved under the same boundedness and Lipschitz assumptions on the reward function, improving on the prior Õ(T^{3/4}) bound without additional assumptions.
Significance. If the upper-bound analysis holds, the work closes the gap to the optimal rate for general (non-monotone) single-index bandits and supplies the first sharp characterization via matching upper and lower bounds. The application of the Stein estimator to direction recovery and the explicit two-phase reduction are technically clean; the absence of extra assumptions beyond standard boundedness/Lipschitz is a notable strength.
major comments (2)
- [Abstract and §3] Abstract and §3 (Stein estimator analysis): The central claim requires that the normalized Stein estimator, run on O(T^{2/3}) samples, produces ||θ̂ − θ|| small enough that the induced perturbation to the projected 1-D reward remains o(T^{-1/3}) with high probability. Under only boundedness and Lipschitz continuity of the link function, the Stein identity yields an estimation rate that depends on the second-moment matrix of the contexts and on the link function having non-vanishing derivative in expectation. Please state the precise high-probability bound on ||θ̂ − θ|| (including any implicit moment conditions on the context distribution) and show explicitly that the resulting 1-D perturbation does not inflate the total regret beyond Õ(T^{2/3}).
- [§4] §4 (reduction and UCB phase): The discretization and UCB analysis on the estimated projection must absorb the direction-estimation error. If the perturbation term is only O(T^{-1/4}) rather than o(T^{-1/3}), an extra T^{3/4} regret term appears; the manuscript should quantify the exact tolerance on ||θ̂ − θ|| that keeps the overall bound Õ(T^{2/3}).
minor comments (2)
- [Abstract] Notation: The symbols Õ and Ω̃ are used throughout; a brief reminder in the abstract or introduction that they hide polylog(T) factors would improve readability.
- [Experiments] The empirical section would benefit from a plot showing the estimated direction error versus sample size to illustrate the Stein estimator rate.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight opportunities to make the high-probability bounds and tolerance analysis more explicit, which we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Stein estimator analysis): The central claim requires that the normalized Stein estimator, run on O(T^{2/3}) samples, produces ||θ̂ − θ|| small enough that the induced perturbation to the projected 1-D reward remains o(T^{-1/3}) with high probability. Under only boundedness and Lipschitz continuity of the link function, the Stein identity yields an estimation rate that depends on the second-moment matrix of the contexts and on the link function having non-vanishing derivative in expectation. Please state the precise high-probability bound on ||θ̂ − θ|| (including any implicit moment conditions on the context distribution) and show explicitly that the resulting 1-D perturbation does not inflate the total regret beyond Õ(T^{2/3}).
Authors: We agree that an explicit statement will improve clarity. The manuscript already derives the rate via the Stein identity under the standing assumptions that the context distribution has bounded second moments with positive definite covariance matrix Σ (eigenvalues between λ_min > 0 and λ_max < ∞) and that E[f'(⟨θ, X⟩)] is bounded away from zero. With n = Θ(T^{2/3}) samples the normalized Stein estimator satisfies, with probability 1 − T^{-1}, ||θ̂ − θ|| ≤ C (T^{-1/3} √(log T)) where C depends only on the Lipschitz constant L, λ_min, and the fourth-moment bound on X. Because the link function is L-Lipschitz, the induced perturbation on the projected reward is at most L·||X||·||θ̂ − θ||. Under our boundedness assumptions on X this term is o(T^{-1/3}) uniformly over the relevant contexts, so the extra regret contributed to the subsequent UCB phase remains absorbed inside the Õ(T^{2/3}) term. We will insert a new lemma (Lemma 3.2) that states the high-probability bound together with the explicit perturbation calculation and the resulting regret decomposition. revision: yes
-
Referee: [§4] §4 (reduction and UCB phase): The discretization and UCB analysis on the estimated projection must absorb the direction-estimation error. If the perturbation term is only O(T^{-1/4}) rather than o(T^{-1/3}), an extra T^{3/4} regret term appears; the manuscript should quantify the exact tolerance on ||θ̂ − θ|| that keeps the overall bound Õ(T^{2/3}).
Authors: We thank the referee for emphasizing this tolerance. In the current §4 analysis the grid resolution is set to Θ(T^{-1/3}) and the UCB widths are inflated by an additive term proportional to the direction error. The proof shows that any ||θ̂ − θ|| = o(T^{-1/3}) (with the o(·) hiding only polylog factors) produces an additive bias that is dominated by the discretization error and therefore does not change the Õ(T^{2/3}) regret. If the direction error were only O(T^{-1/4}), the bias would indeed generate an extra Θ(T^{3/4}) term, but our Stein estimator guarantees a strictly smaller rate. We will add a short remark after Theorem 4.1 that states the precise tolerance: the overall regret remains Õ(T^{2/3}) as long as ||θ̂ − θ|| ≤ T^{-1/3} (log T)^{-2} with high probability, which is satisfied by the estimator of §3. revision: yes
Circularity Check
No circularity: derivation relies on independent Stein estimator analysis plus standard UCB
full rationale
The paper's upper bound is obtained by bounding the normalized Stein estimator's direction error under the stated boundedness/Lipschitz assumptions, then feeding the resulting one-dimensional projected problem into a standard discretization-plus-UCB analysis whose concentration terms are independent of the estimator. The matching lower bound is proved separately via a minimax construction. No equation or bound is defined in terms of a fitted quantity that is then re-used as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and the cited prior O(T^{3/4}) result is external. The derivation is therefore self-contained against the paper's own assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The reward function is bounded and Lipschitz continuous.
- domain assumption Contexts satisfy the moment conditions required for the normalized Stein estimator to be consistent.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearZoomSIB-UCB … first estimates the projection direction via a normalized Stein estimator, and then reduces the problem to a one-dimensional bandit using discretization … regret of Õ(T^{2/3})
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt uncleardiscretises the real line into N=O(T^{1/3}) bins … bin width Δ=T^{-1/3}
Reference graph
Works this paper leans on
-
[1]
Emmanuel Abbe, Enric Boix-Adsera, Matthew Brennan, Guy Bresler, and Mingjia Huang
URL https://proceedings.neurips.cc/paper_files/ paper/2011/file/e1d5be1c7f2f456670de3d53c7b54f4a-Paper.pdf. Emmanuel Abbe, Enric Boix-Adsera, Matthew Brennan, Guy Bresler, and Mingjia Huang. Merged-staircase property: A necessary and nearly sufficient condition for non-linear learning by gradient methods. InProceedings of the 35th Annual Conference on Lea...
work page 2011
-
[2]
Continuum-armed bandit problem.SIAM Journal on Control and Optimization, 33(6):1926–1951,
Rajeev Agrawal. Continuum-armed bandit problem.SIAM Journal on Control and Optimization, 33(6):1926–1951,
work page 1926
-
[3]
Kernel single-index bandits: Estimation, inference, and learning.arXiv preprint arXiv:2603.18938,
10 Sakshi Arya, Satarupa Bhattacharjee, and Bharath K Sriperumbudur. Kernel single-index bandits: Estimation, inference, and learning.arXiv preprint arXiv:2603.18938,
-
[4]
Sébastien Bubeck and Nicolo Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi-armed bandit problems.arXiv preprint arXiv:1204.5721,
-
[5]
Dylan J Foster and Alexander Rakhlin
URL https://proceedings.neurips.cc/paper_ files/paper/2010/file/c2626d850c80ea07e7511bbae4c76f4b-Paper.pdf. Dylan J Foster and Alexander Rakhlin. Beyond ucb: Optimal and efficient contextual bandits with regression oracles. InProceedings of the 37th International Conference on Machine Learning (ICML), pages 3199–3210,
work page 2010
-
[6]
URL https: //proceedings.mlr.press/v5/kanade09a.html
PMLR. URL https: //proceedings.mlr.press/v5/kanade09a.html. Yue Kang, Mingshuo Liu, Bongsoo Yi, Jing Lyu, Zhi Zhang, Doudou Zhou, and Yao Li. Single index bandits: Generalized linear contextual bandits with unknown reward functions.arXiv preprint arXiv:2506.12751,
-
[7]
Provably optimal algorithms for generalized linear contextual bandits
Lihong Li, Yu Lu, and Dengyong Zhou. Provably optimal algorithms for generalized linear contextual bandits. In International Conference on Machine Learning, pages 2071–2080. PMLR,
work page 2071
-
[8]
Wanteng Ma and T Tony Cai. Nonparametric bandits with single-index rewards: Optimality and adaptivity.arXiv preprint arXiv:2512.24669,
-
[9]
Yu-Jie Zhang, Sheng-An Xu, Peng Zhao, and Masashi Sugiyama. Generalized linear bandits: Almost optimal regret with one-pass update.arXiv preprint arXiv:2507.11847,
-
[10]
and Bubeck et al. [2012], who establish near-optimal ˜𝑂( √ 𝑑𝑇) bounds, while subsequent work extended the framework to sparsity [Carpentier 13 and Munos, 2012], low-rank structure [Jun et al., 2019], and misspecification [Lattimore et al., 2020]. Contextual bandits condition rewards on an observed context vector, with LinUCB [Li et al., 2010] and its theo...
work page 2012
-
[11]
and Härdle et al. [1993]. Hornik et al
work page 1993
-
[12]
and Thrampoulidis et al. [2015]. The work of Kalai and Sastry
work page 2015
-
[13]
and Goldstein et al. [2018]. More recently, the connection between SIMs and gradient descent on two-layer neural networks has attracted significant attention: Barak et al
work page 2018
-
[14]
further showed that a single gradient step on the population loss suffices to recover the index direction up to a polynomial sample complexity, formalizing the so-called leap exponent as the key quantity governing the difficulty of the learning problem under staircase-structured link functions. A.3 Lipschitz Bandits In Agrawal [1995], the authors establis...
work page 1995
-
[15]
derived nearly tight ˜𝑂(𝑇 2/3) regret bounds, later tightened and connected to nonparametric regression by Auer et al. [2007]. Kleinberg et al
work page 2007
-
[16]
study adaptive algorithms achieving optimal rates across smoothness classes without knowledge of the Lipschitz constant. 14 B Proofs Lemma B.1(Normalized Stein Estimation Error).Suppose the unnormalized truncated Stein estimator satisfies ∥ ˆ𝜃−𝜇 ∗𝜃 ∗ ∥1 ≤𝜖 with probability at least1 −𝛿 , where 𝜖=𝐶 𝜃𝑑 √︃ log(2𝑑/𝛿) 𝑛 . Assume 𝜇∗ > 0, ∥𝜃 ∗ ∥1 = 1, and that t...
work page 2025
-
[17]
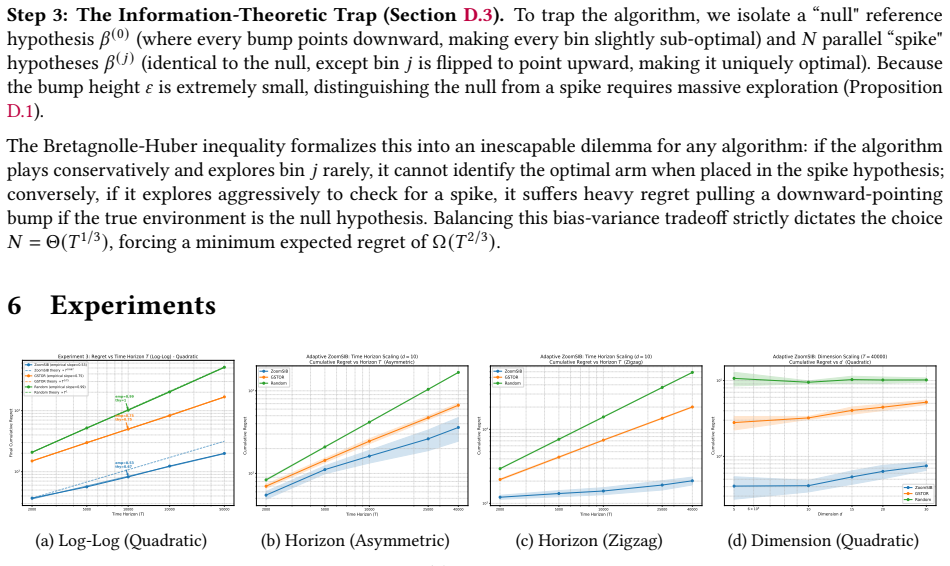
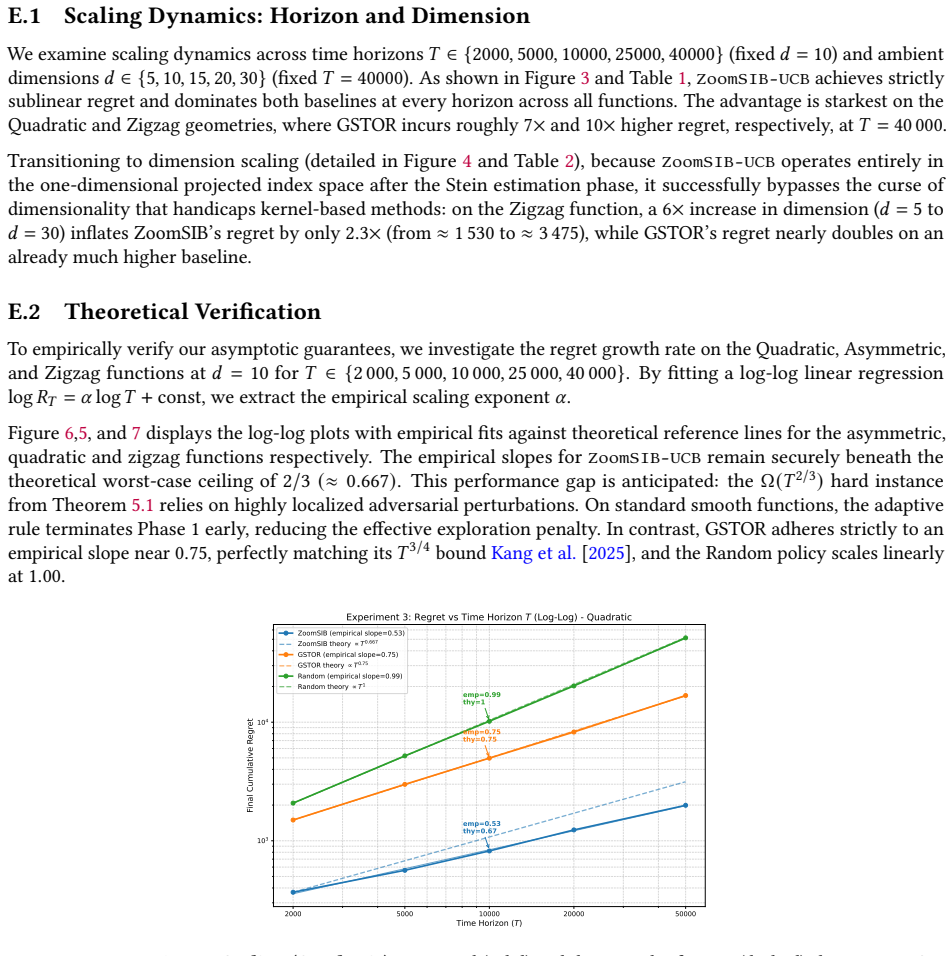
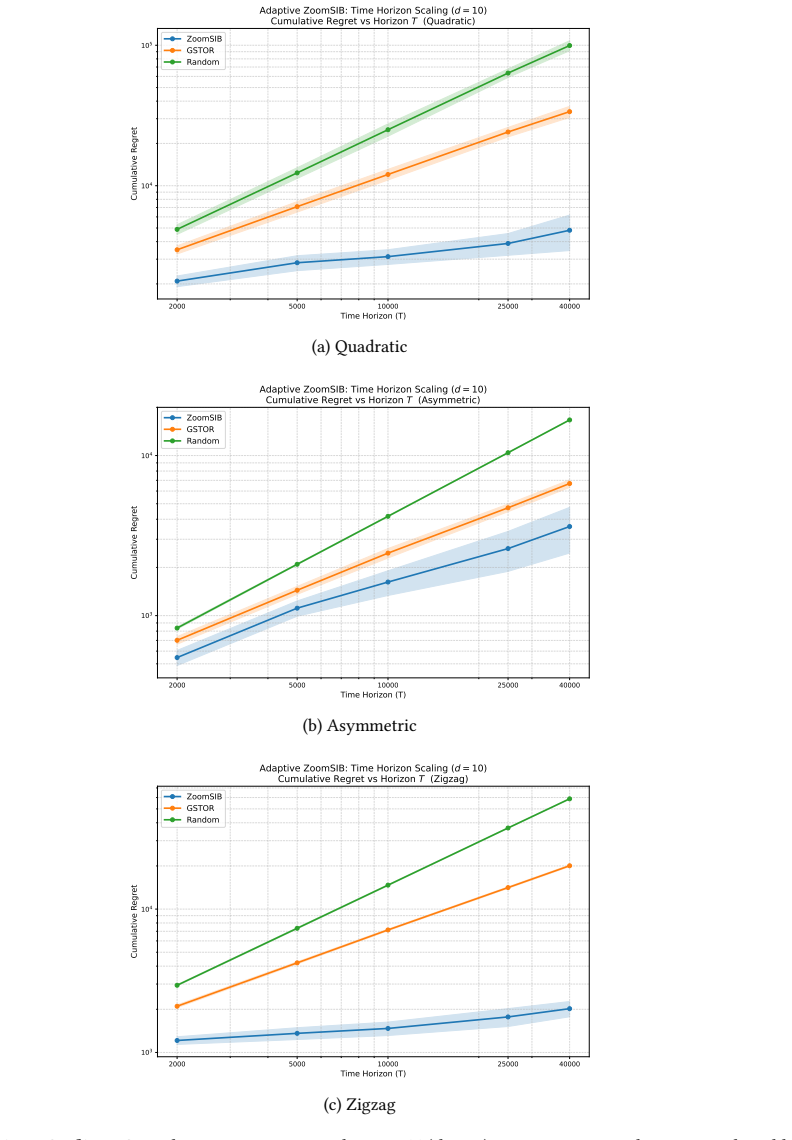
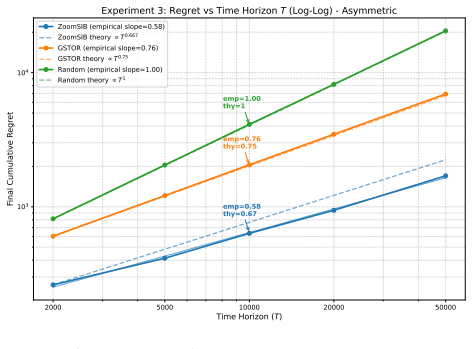
Therefore, setting 𝑇0 =⌈( 16𝑒) 3⌉, for all 𝑇≥𝑇 0, Case A must hold. Taking the supremum over the hypothesis class concludes the proof with𝑐=1/(128𝑒).□ E Detailed Experiments We present an empirical evaluation of ZoomSIB-UCB against three baselines: GSTOR (anon-monotonelink function based algorithm), ESTOR (amonotone-link function based algorithm)Kang et a...
work page 2025
-
[18]
inflates ZoomSIB’s regret by only2.3× (from ≈ 1 530to ≈ 3 475), while GSTOR’s regret nearly doubles on an already much higher baseline. E.2 Theoretical Verification To empirically verify our asymptotic guarantees, we investigate the regret growth rate on the Quadratic, Asymmetric, and Zigzag functions at 𝑑= 10for 𝑇∈ { 2 000, 5 000, 10 000, 25 000, 40 000}...
work page 2025
-
[19]
Cumulative Regret vs Horizon T (Quadratic) ZoomSIB GSTOR Random (a) Quadratic 2000 5000 10000 25000 40000 Time Horizon (T) 103 104 Cumulative Regret Adaptive ZoomSIB: Time Horizon Scaling (d =
work page 2000
-
[20]
Cumulative Regret vs Horizon T (Asymmetric) ZoomSIB GSTOR Random (b) Asymmetric 2000 5000 10000 25000 40000 Time Horizon (T) 103 104 Cumulative Regret Adaptive ZoomSIB: Time Horizon Scaling (d =
work page 2000
-
[21]
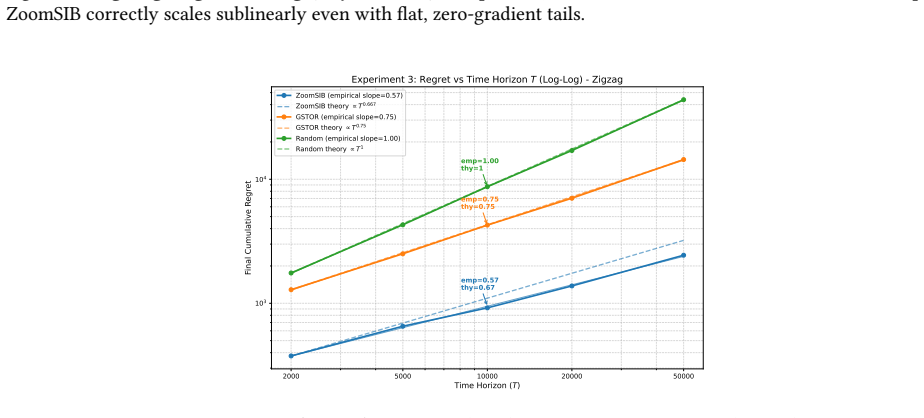
ZoomSIB-UCB operates entirely in the 1D projected space after Phase 1, successfully avoiding the curse of dimensionality. 23 2000 5000 10000 20000 50000 Time Horizon (T) 103 104 Final Cumulative Regret emp=0.58 thy=0.67 emp=0.76 thy=0.75 emp=1.00 thy=1 Experiment 3: Regret vs Time Horizon T (Log-Log) - Asymmetric ZoomSIB (empirical slope=0.58) ZoomSIB the...
work page 2000
-
[22]
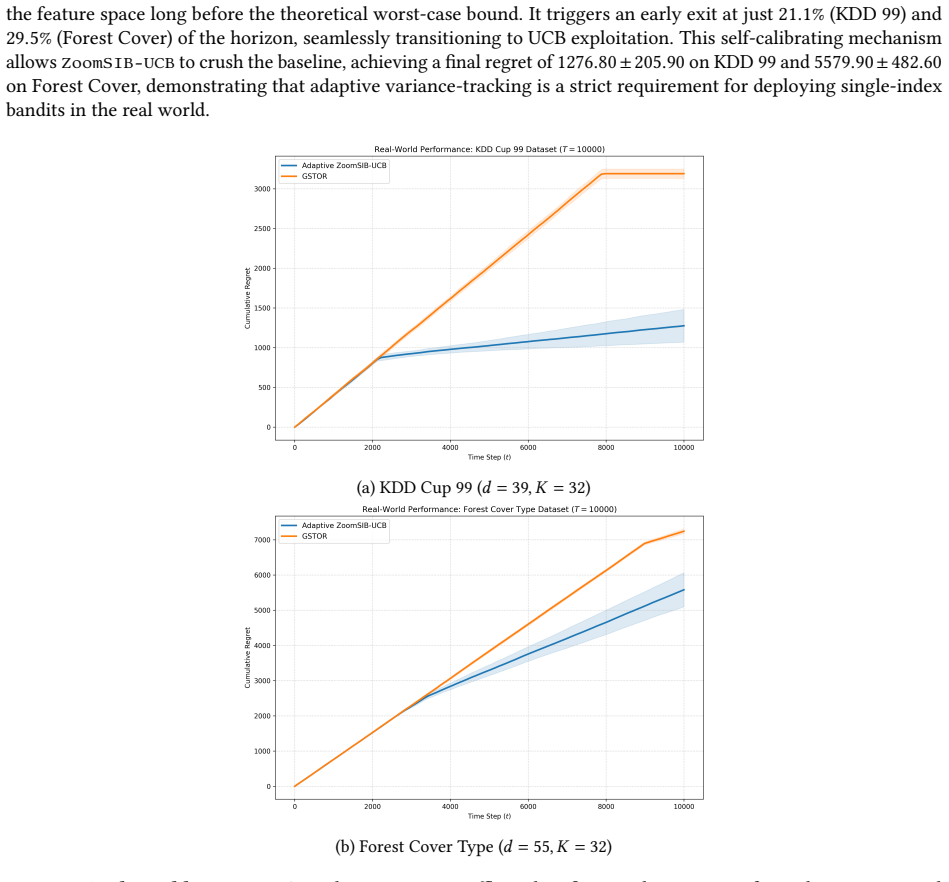
and 29.5%(Forest Cover) of the horizon, seamlessly transitioning to UCB exploitation. This self-calibrating mechanism allows ZoomSIB-UCB to crush the baseline, achieving a final regret of1276.80 ± 205.90on KDD 99 and5579 .90 ± 482.60 on Forest Cover, demonstrating that adaptive variance-tracking is a strict requirement for deploying single-index bandits i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.