Recognition: 1 theorem link
· Lean TheoremVulTriage: Triple-Path Context Augmentation for LLM-Based Vulnerability Detection
Pith reviewed 2026-05-13 07:26 UTC · model grok-4.3
The pith
Triple context paths improve LLM vulnerability detection
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
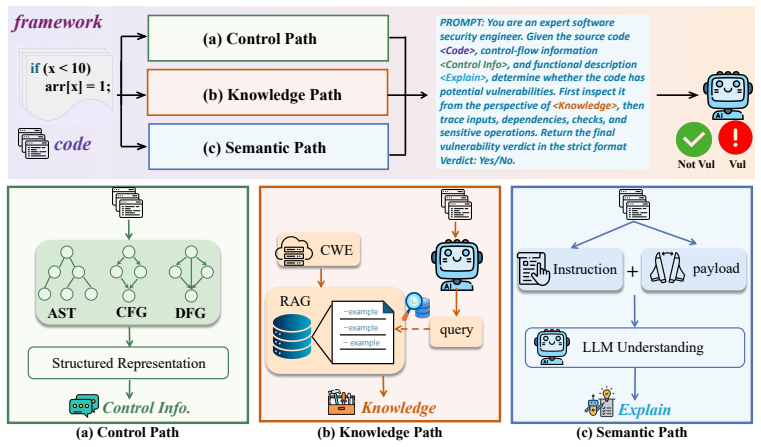
VulTriage augments LLM input for vulnerability detection with three paths: Control Path verbalizing AST, CFG and DFG for dependencies; Knowledge Path retrieving CWE patterns via hybrid dense-sparse retrieval; Semantic Path summarizing functional behavior. Integrated into one instruction, this produces state-of-the-art performance on the PrimeVul pair test set, beating deep learning and LLM baselines on pair-wise and classification metrics.
What carries the argument
The triple-path context augmentation with Control Path for structural info, Knowledge Path for CWE retrieval, and Semantic Path for behavior summary.
If this is right
- Outperforms deep learning and LLM baselines on key metrics for vulnerability detection.
- Ablation studies confirm each of the three paths adds value.
- Demonstrates generalization on the Kotlin dataset under low-resource and imbalanced conditions.
- Helps reduce missed vulnerabilities and false alarms from subtle code differences.
Where Pith is reading between the lines
- Similar augmentation could help LLMs on related tasks such as bug finding or code review.
- The approach may need adjustments if the underlying LLM changes or for very large codebases.
- Integration into IDEs could provide real-time vulnerability feedback during coding.
- Retrieval quality for rare vulnerabilities remains a potential limit to effectiveness.
Load-bearing premise
The three context paths supply complementary information that the LLM integrates without noise or hallucinations and the retrieval finds relevant patterns.
What would settle it
A dataset of code examples where the three paths give inconsistent signals about vulnerability and the model fails to detect correctly more often than baselines.
Figures




read the original abstract
Automated vulnerability detection is a fundamental task in software security, yet existing learning-based methods still struggle to capture the structural dependencies, domain-specific vulnerability knowledge, and complex program semantics required for accurate detection. Recent Large Language Models (LLMs) have shown strong code understanding ability, but directly prompting them with raw source code often leads to missed vulnerabilities or false alarms, especially when vulnerable and benign functions differ only in subtle semantic details. To address this, we propose VulTriage, a triple-path context augmentation framework for LLM-based vulnerability detection. VulTriage enhances the LLM input through three complementary paths: a Control Path that extracts and verbalizes AST, CFG, and DFG information to expose control and data dependencies; a Knowledge Path that retrieves relevant CWE-derived vulnerability patterns and examples through hybrid dense--sparse retrieval; and a Semantic Path that summarizes the functional behavior of the code before the final judgment. These contexts are integrated into a unified instruction to guide the LLM toward more reliable vulnerability reasoning. Experiments on the PrimeVul pair test set show that VulTriage achieves state-of-the-art performance, outperforming existing deep learning and LLM-based baselines on key pair-wise and classification metrics. Further ablation studies verify the effectiveness of each path, and additional experiments on the Kotlin dataset demonstrate the generalization ability of VulTriage under low-resource and class-imbalanced settings. Our code is available at https://github.com/vinsontang1/VulTriage
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VulTriage, a triple-path context augmentation framework for LLM-based vulnerability detection. It augments LLM inputs via a Control Path (verbalizing AST/CFG/DFG dependencies), a Knowledge Path (hybrid dense-sparse retrieval of CWE patterns and examples), and a Semantic Path (functional behavior summary), which are fused into a unified instruction prompt. The central claim is that this yields SOTA results on the PrimeVul pair test set, outperforming DL and LLM baselines on pair-wise and classification metrics, with ablations confirming each path's value and further tests showing generalization to Kotlin under low-resource conditions.
Significance. If the results hold, the work provides a concrete, reproducible method for injecting structural, knowledge-base, and semantic context into LLMs for security tasks, addressing a known weakness of raw-code prompting. The open-source release at the cited GitHub link is a positive factor for verification and extension.
major comments (2)
- [§4.2, Table 3] §4.2 (Main Results) and Table 3: The SOTA claim on PrimeVul pair-wise metrics is presented without retrieval-quality metrics (precision@K or fraction of relevant CWEs returned) for the Knowledge Path on the test samples. This is load-bearing for the central claim because the skeptic concern is that observed gains could stem from generic prompt expansion rather than accurate CWE fusion; without these numbers the complementarity of the three paths cannot be confirmed.
- [§4.3] §4.3 (Ablation Studies): The reported performance drops when ablating each path are given, yet the paper does not include qualitative retrieval examples or error analysis showing that the Knowledge Path actually surfaces relevant patterns on PrimeVul functions where the baseline LLM fails. This leaves open the possibility that gains are driven by the Control or Semantic paths alone.
minor comments (3)
- [§3.4] The prompt template in §3.4 uses inconsistent notation for the three context blocks; a single figure or boxed example would improve clarity.
- [Figure 2] Figure 2 (overall architecture) lacks axis labels on the retrieval component and does not indicate the exact top-K value used in experiments.
- [§2] A few citations to prior CWE-retrieval work (e.g., the hybrid retriever baseline) are missing from the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of evidence presentation that we will address through targeted revisions to strengthen the support for our claims regarding the Knowledge Path's contribution.
read point-by-point responses
-
Referee: [§4.2, Table 3] §4.2 (Main Results) and Table 3: The SOTA claim on PrimeVul pair-wise metrics is presented without retrieval-quality metrics (precision@K or fraction of relevant CWEs returned) for the Knowledge Path on the test samples. This is load-bearing for the central claim because the skeptic concern is that observed gains could stem from generic prompt expansion rather than accurate CWE fusion; without these numbers the complementarity of the three paths cannot be confirmed.
Authors: We agree that retrieval-quality metrics would provide stronger confirmation that gains arise from accurate CWE fusion rather than generic expansion. In the revised manuscript we will add precision@K, recall@K, and the fraction of relevant CWEs retrieved, computed on the PrimeVul test set using the same hybrid dense-sparse setup described in §3.2. These numbers will be reported alongside the main results in an updated Table 3 and discussed in §4.2 to directly address the complementarity concern. revision: yes
-
Referee: [§4.3] §4.3 (Ablation Studies): The reported performance drops when ablating each path are given, yet the paper does not include qualitative retrieval examples or error analysis showing that the Knowledge Path actually surfaces relevant patterns on PrimeVul functions where the baseline LLM fails. This leaves open the possibility that gains are driven by the Control or Semantic paths alone.
Authors: We acknowledge that qualitative evidence would further substantiate the Knowledge Path's role. The revised version will add a dedicated qualitative analysis subsection (new §4.3.1) containing (i) concrete examples of retrieved CWE patterns and examples for PrimeVul functions where the baseline LLM fails but the full model succeeds, and (ii) a short error analysis of retrieval relevance on those cases. This material will be drawn from the existing retrieval logs and will be included without requiring new experiments. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks with independent ablations
full rationale
The paper describes a triple-path augmentation framework (Control via AST/CFG/DFG verbalization, Knowledge via hybrid CWE retrieval, Semantic summarization) whose central claims are supported by experiments on the external PrimeVul pair test set and a separate Kotlin dataset. No equations, parameter-fitting loops, or self-referential definitions appear in the provided text. Ablation studies are presented as verification of each path's contribution, and code release allows external reproduction. Performance is reported as outperforming baselines rather than being forced by construction from inputs. No self-citation load-bearing steps or uniqueness theorems are invoked. This is a standard empirical ML paper whose derivation chain does not reduce to its own fitted values or definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess sufficient code understanding to benefit from explicit control-flow and knowledge augmentation without hallucinating new vulnerabilities.
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.48550/ARXIV.2403.18624 arXiv:2403.18624
Vulnerability Detection with Code Language Models: How Far Are We? , author=. arXiv preprint arXiv:2403.18624 , year=
-
[2]
Advances in neural information processing systems , volume=
Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks , author=. Advances in neural information processing systems , volume=
-
[3]
IEEE Transactions on Software Engineering , volume=
Deep learning based vulnerability detection: Are we there yet? , author=. IEEE Transactions on Software Engineering , volume=. 2021 , publisher=
work page 2021
-
[4]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Codebert: A pre-trained model for programming and natural languages , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
work page 2020
-
[5]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Data quality for software vulnerability datasets , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
work page 2023
-
[6]
Proceedings of the 19th international conference on mining software repositories , pages=
Linevul: A transformer-based line-level vulnerability prediction , author=. Proceedings of the 19th international conference on mining software repositories , pages=
-
[7]
Scale: Constructing structured natural language comment trees for software vulnerability detection , author=. Proceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis , pages=
-
[8]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Why think step by step? reasoning emerges from the locality of experience , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[11]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. arXiv preprint arXiv:2402.03216 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE) , year =
Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents , author =. Proceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE) , year =
-
[13]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
work page 2021
-
[14]
Unixcoder: Unified cross-modal pre-training for code representation , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Large language model-powered smart contract vulnerability detection: New perspectives , author=. 2023 5th IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA) , pages=. 2023 , organization=
work page 2023
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
A Sequential Multi-Stage Approach for Code Vulnerability Detection via Confidence-and Collaboration-based Decision Making , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[17]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Leveraging user-defined identifiers for counterfactual data generation in source code vulnerability detection , author=. 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM) , pages=. 2023 , organization=
work page 2023
-
[19]
2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
When less is enough: Positive and unlabeled learning model for vulnerability detection , author=. 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2023 , organization=
work page 2023
-
[20]
Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
Dfept: data flow embedding for enhancing pre-trained model based vulnerability detection , author=. Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
-
[21]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
Pre-training by predicting program dependencies for vulnerability analysis tasks , author=. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
-
[22]
Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
Matsvd: Boosting statement-level vulnerability detection via dependency-based attention , author=. Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
-
[23]
IEEE Transactions on Software Engineering , volume=
Vulnerability detection by learning from syntax-based execution paths of code , author=. IEEE Transactions on Software Engineering , volume=. 2023 , publisher=
work page 2023
-
[24]
PTLVD: Program slicing and transformer-based line-level vulnerability detection system , author=. 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM) , pages=. 2023 , organization=
work page 2023
-
[25]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
Combining structured static code information and dynamic symbolic traces for software vulnerability prediction , author=. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
-
[26]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Slidecoder: Layout-aware rag-enhanced hierarchical slide generation from design , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[27]
arXiv preprint arXiv:2603.00155 , year=
EfficientPosterGen: Semantic-aware Efficient Poster Generation via Token Compression and Accurate Violation Detection , author=. arXiv preprint arXiv:2603.00155 , year=
-
[28]
2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping , author=. 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2025 , organization=
work page 2025
-
[29]
arXiv preprint arXiv:2509.21782 , year=
Benchmarking mllm-based web understanding: Reasoning, robustness and safety , author=. arXiv preprint arXiv:2509.21782 , year=
-
[30]
arXiv preprint arXiv:2506.06251 , year=
Designbench: A comprehensive benchmark for mllm-based front-end code generation , author=. arXiv preprint arXiv:2506.06251 , year=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Rethinking Multimodal Point Cloud Completion: A Completion-by-Correction Perspective , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Queryattack: Jailbreaking aligned large language models using structured non-natural query language , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[33]
2023 30th Asia-Pacific Software Engineering Conference (APSEC) , pages=
Chatgpt for vulnerability detection, classification, and repair: How far are we? , author=. 2023 30th Asia-Pacific Software Engineering Conference (APSEC) , pages=. 2023 , organization=
work page 2023
-
[34]
Bendersky, Eli , howpublished =
-
[35]
Software vulnerability prediction in low-resource languages: An empirical study of codebert and chatgpt , author=. Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering , pages=
-
[36]
Note on the sampling error of the difference between correlated proportions or percentages , author=. Psychometrika , volume=. 1947 , publisher=
work page 1947
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.