Recognition: no theorem link
Beyond Position Bias: Shifting Context Compression from Position-Driven to Semantic-Driven
Pith reviewed 2026-05-12 03:21 UTC · model grok-4.3
The pith
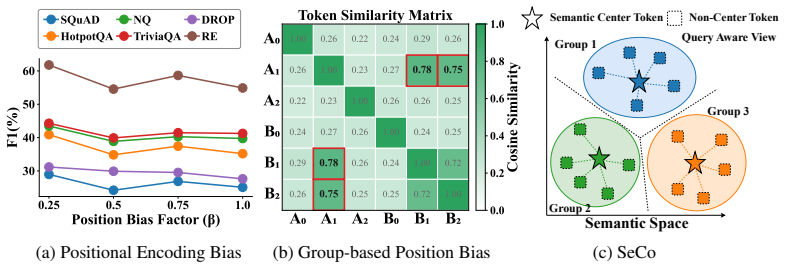
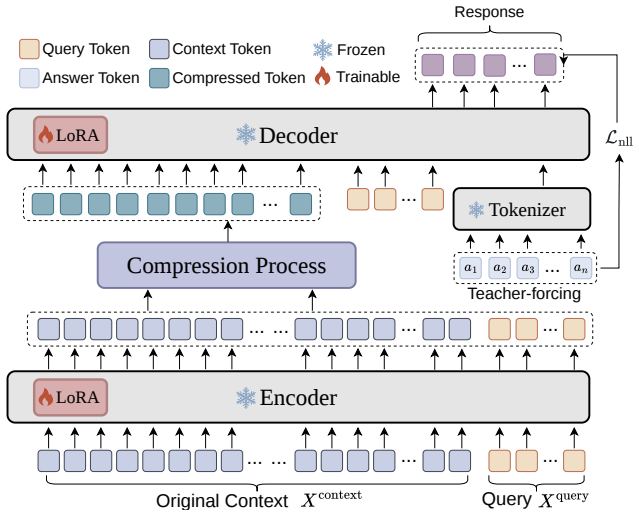
SeCo compresses LLM contexts by anchoring in semantic space rather than token positions to eliminate bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Semantic Consistency Context Compression (SeCo) overcomes position bias in soft prompt compression by dynamically selecting query-relevant tokens as semantic centers and aggregating remaining tokens via consistency-weighted merging, which preserves semantic consistency and improves performance on downstream tasks.
What carries the argument
SeCo (Semantic Consistency Context Compression), which anchors compression in the semantic space using query-relevant token selection as centers and consistency-weighted merging for aggregation.
If this is right
- Models can handle longer contexts with less latency and without position-induced performance drops.
- Downstream task accuracy improves consistently across multiple benchmarks.
- Out-of-domain robustness increases due to reduced semantic fragmentation.
- Compression becomes more stable without needing position-specific tuning.
Where Pith is reading between the lines
- Similar semantic anchoring could extend to compressing other data types like images or code sequences.
- Integrating SeCo with retrieval methods might further enhance long-context reasoning.
- Testing on even longer sequences would verify if the semantic consistency holds at scale.
Load-bearing premise
That identifying query-relevant tokens as semantic centers and performing consistency-weighted merging will reliably preserve critical information without introducing new semantic distortions.
What would settle it
Running SeCo on a benchmark with queries where relevance is deliberately hard to determine, and checking if accuracy falls below position-based methods or shows persistent inconsistencies.
Figures


read the original abstract
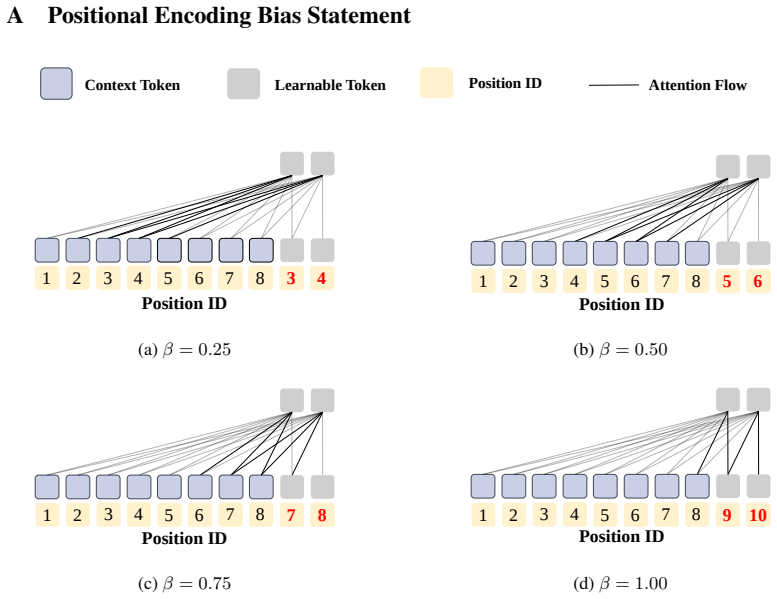
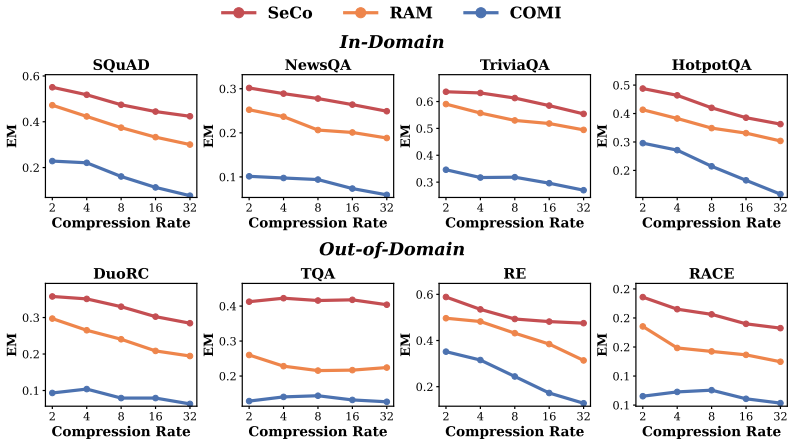
Large Language Models (LLMs) have demonstrated exceptional performance across diverse tasks. However, their deployment in long-context scenarios faces high computational overhead and information redundancy. While soft prompt compression has emerged as a promising way to mitigate these costs by compressing sequences into compact embeddings, existing paradigms remain fundamentally constrained by position bias: they primarily rely on learnable tokens insertion at fixed positions or group tokens according to their physical token layout, thereby inducing performance instability and semantic fragmentation. To overcome this bottleneck, we propose Semantic Consistency Context Compression (SeCo), a method that shifts context compression from position-driven to semantic-driven. Rather than constraint by physical token layout, SeCo dynamically anchors compression directly in the semantic space by selecting query-relevant tokens as semantic centers and aggregating remaining tokens via consistency-weighted merging. This design inherently preserves semantic consistency while eliminating position bias. Extensive experiments on 14 benchmarks across two backbone models demonstrate that SeCo consistently shows superiority in downstream tasks, inference latency, and out-of-domain robustness. The code is available at https://anonymous.4open.science/r/seco-EE5E.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Consistency Context Compression (SeCo) to address position bias in soft prompt compression for long-context LLMs. Instead of relying on fixed-position learnable tokens or physical token layout, SeCo selects query-relevant tokens as semantic centers and aggregates remaining tokens via consistency-weighted merging. The authors claim this semantic-driven approach inherently eliminates position bias while preserving semantic consistency, with experiments on 14 benchmarks across two backbone models showing gains in downstream performance, inference latency, and out-of-domain robustness. Code is released.
Significance. If the core claim holds—that semantic center selection and consistency-weighted merging operate independently of positional encodings and without introducing new distortions—this would address a genuine limitation in existing compression methods and improve robustness for long-context LLM applications. The public code release is a strength for reproducibility. However, the current presentation provides only high-level experimental summaries without sufficient controls or implementation details to confirm the position-bias elimination.
major comments (3)
- [Abstract] Abstract: The central claim that SeCo 'inherently preserves semantic consistency while eliminating position bias' rests on the unverified assumption that query-relevant token selection and consistency-weighted merging use no positional signals. If relevance scoring or consistency measurement is performed via the backbone model's attention or embeddings (which embed positional information), or if merging weights correlate with original token layout, position bias is relocated rather than removed. No implementation details or ablation isolating semantic vs. residual positional effects are provided to support this.
- [Experimental results] Experimental results (as summarized): Claims of 'consistent superiority' on 14 benchmarks lack any details on baselines, statistical significance testing, error bars, exact merging procedure, or controls for compression ratio. Without these, it is impossible to determine whether reported gains stem from bias removal or from other factors such as different compression ratios or tuning.
- [Method description] Method description: The approach introduces free parameters ('number of semantic centers', 'consistency threshold for merging') and invented entities ('semantic center', 'consistency-weighted merging'). No ablation studies demonstrate that these choices are robust across tasks or that they avoid reintroducing position-like biases through task-specific tuning.
minor comments (1)
- [Abstract] Abstract: 'constraint by physical token layout' should read 'constrained by physical token layout'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights areas where additional clarity and rigor will strengthen the manuscript. We address each major comment point by point below, outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SeCo 'inherently preserves semantic consistency while eliminating position bias' rests on the unverified assumption that query-relevant token selection and consistency-weighted merging use no positional signals. If relevance scoring or consistency measurement is performed via the backbone model's attention or embeddings (which embed positional information), or if merging weights correlate with original token layout, position bias is relocated rather than removed. No implementation details or ablation isolating semantic vs. residual positional effects are provided to support this.
Authors: We agree that the manuscript would benefit from explicit clarification on this point. In SeCo, semantic centers are selected via cosine similarity between query embeddings and context token embeddings (computed independently of positional encodings), and consistency-weighted merging uses pairwise semantic similarity scores for aggregation weights. This design operates in semantic space without reference to token positions or layout. However, we acknowledge the absence of implementation pseudocode and targeted ablations isolating residual positional effects. In the revision, we will add a new subsection detailing the exact computation (with equations) and an ablation comparing SeCo variants with/without positional information in the backbone embeddings, confirming that performance gains persist when positional signals are masked. revision: yes
-
Referee: [Experimental results] Experimental results (as summarized): Claims of 'consistent superiority' on 14 benchmarks lack any details on baselines, statistical significance testing, error bars, exact merging procedure, or controls for compression ratio. Without these, it is impossible to determine whether reported gains stem from bias removal or from other factors such as different compression ratios or tuning.
Authors: We accept this critique regarding insufficient experimental transparency. The full paper compares against multiple position-based baselines (e.g., fixed-position soft prompts and layout-grouped merging) at matched compression ratios, but the summary presentation omitted key details. In the revised version, we will expand the experimental section to include: full baseline descriptions and hyperparameters, paired statistical significance tests with p-values, error bars from 5 random seeds, pseudocode for the merging procedure, and explicit controls verifying identical compression ratios across methods. These additions will demonstrate that superiority arises from the semantic-driven mechanism rather than confounding factors. revision: yes
-
Referee: [Method description] Method description: The approach introduces free parameters ('number of semantic centers', 'consistency threshold for merging') and invented entities ('semantic center', 'consistency-weighted merging'). No ablation studies demonstrate that these choices are robust across tasks or that they avoid reintroducing position-like biases through task-specific tuning.
Authors: We will clarify terminology in the revision: 'semantic center' refers to query-relevant anchor tokens selected by embedding similarity, and 'consistency-weighted merging' denotes aggregation weighted by semantic coherence scores. The parameters are standard hyperparameters tuned on a held-out validation set. To address the lack of robustness evidence, we will add ablation studies varying the number of centers and threshold across all 14 benchmarks, reporting performance stability and confirming that fixed (non-task-specific) values suffice without introducing layout-dependent biases. This will show the choices are not fragile or position-reintroducing. revision: yes
Circularity Check
No circularity: method proposal and empirical claims are independent of inputs
full rationale
The paper introduces SeCo as a new semantic-driven compression technique via query-relevant token selection and consistency-weighted merging, asserting it eliminates position bias by design. No equations, derivations, or steps in the abstract or description reduce the claimed superiority or bias elimination to a fitted parameter, self-definition, or self-citation chain. The central claims rest on the proposed algorithm and external benchmark results across 14 tasks, which serve as independent validation rather than tautological restatement. No load-bearing uniqueness theorems, ansatzes, or renamings of known results are invoked in a self-referential manner.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of semantic centers
- consistency threshold for merging
axioms (1)
- domain assumption Semantic similarity between tokens can be measured reliably in the model's embedding space without reference to position.
invented entities (2)
-
semantic center
no independent evidence
-
consistency-weighted merging
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InACL/IJCNLP (1), pages 7319–7328. Association for Computational Linguistics, 2021
work page 2021
-
[2]
Retaining key information under high compression ratios: Query-guided compressor for llms
Zhiwei Cao, Qian Cao, Yu Lu, Ningxin Peng, Luyang Huang, Shanbo Cheng, and Jinsong Su. Retaining key information under high compression ratios: Query-guided compressor for llms. InACL (1), pages 12685–12695. Association for Computational Linguistics, 2024
work page 2024
-
[3]
DAST: context-aware compression in llms via dynamic allocation of soft tokens
Shaoshen Chen, Yangning Li, Zishan Xu, Yongqin Zeng, Shunlong Wu, Xinshuo Hu, Zifei Shan, Xin Su, Jiwei Tang, Yinghui Li, and Hai-Tao Zheng. DAST: context-aware compression in llms via dynamic allocation of soft tokens. InACL (Findings), pages 20544–20552. Association for Computational Linguistics, 2025
work page 2025
-
[4]
Dialogsum: A real-life scenario dialogue summarization dataset
Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. Dialogsum: A real-life scenario dialogue summarization dataset. InACL/IJCNLP (Findings), Findings of ACL, pages 5062–5074. Association for Computational Linguistics, 2021
work page 2021
-
[5]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. InEMNLP, pages 3829–3846. Association for Computational Linguistics, 2023
work page 2023
-
[6]
Provence: efficient and robust context pruning for retrieval-augmented generation
Nadezhda Chirkova, Thibault Formal, Vassilina Nikoulina, and Stéphane Clinchant. Provence: efficient and robust context pruning for retrieval-augmented generation. InICLR. OpenRe- view.net, 2025
work page 2025
-
[7]
A spreading activation theory of semantic processing
Allan Collins and Elizabeth Loftus. A spreading activation theory of semantic processing. Psychological Review, 82:407–428, 11 1975. doi: 10.1037//0033-295X.82.6.407
-
[8]
Thomas M. Cover and Joy A. Thomas.Elements of information theory (2. ed.). Wiley, 2006
work page 2006
-
[9]
Pretraining context compressor for large language models with embedding-based memory
Yuhong Dai, Jianxun Lian, Yitian Huang, Wei Zhang, Mingyang Zhou, Mingqi Wu, Xing Xie, and Hao Liao. Pretraining context compressor for large language models with embedding-based memory. InACL (1), pages 28715–28732. Association for Computational Linguistics, 2025
work page 2025
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning. InEMNLP, pages 1107–1128. Association for Computational Linguistics, 2024
work page 2024
-
[12]
David L. Donoho. Compressed sensing.IEEE Trans. Inf. Theory, 52(4):1289–1306, 2006
work page 2006
-
[13]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InNAACL-HLT (1), pages 2368–2378. Association for Computational Linguistics, 2019
work page 2019
-
[14]
Ugur Güney, V olkan Cirik, and Kyunghyun Cho
Matthew Dunn, Levent Sagun, Mike Higgins, V . Ugur Güney, V olkan Cirik, and Kyunghyun Cho. Searchqa: A new q&a dataset augmented with context from a search engine.CoRR, abs/1704.05179, 2017
-
[15]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and GPT-2 embeddings. InEMNLP/IJCNLP (1), pages 55–65. Association for Computational Linguistics, 2019
work page 2019
-
[16]
MRQA 2019 shared task: Evaluating generalization in reading comprehension
Adam Fisch, Alon Talmor, Robin Jia, Minjoon Seo, Eunsol Choi, and Danqi Chen. MRQA 2019 shared task: Evaluating generalization in reading comprehension. InMRQA@EMNLP, pages 1–13. Association for Computational Linguistics, 2019
work page 2019
-
[17]
In-context autoencoder for context compression in a large language model
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model. InICLR. OpenReview.net, 2024. 10
work page 2024
-
[18]
Robert M. Gray and David L. Neuhoff. Quantization.IEEE Trans. Inf. Theory, 44(6):2325–2383, 1998
work page 1998
-
[19]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR. OpenReview.net, 2022
work page 2022
-
[20]
Taeho Hwang, Sukmin Cho, Soyeong Jeong, Hoyun Song, SeungYoon Han, and Jong C. Park. EXIT: context-aware extractive compression for enhancing retrieval-augmented generation. In ACL (Findings), pages 4895–4924. Association for Computational Linguistics, 2025
work page 2025
-
[21]
Llmlingua: Compress- ing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compress- ing prompts for accelerated inference of large language models. InEMNLP, pages 13358–13376. Association for Computational Linguistics, 2023
work page 2023
-
[22]
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. InACL (1), pages 1658–1677. Association for Computational Linguistics, 2024
work page 2024
-
[23]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InACL (1), pages 1601–1611. Association for Computational Linguistics, 2017
work page 2017
-
[24]
Aniruddha Kembhavi, Min Joon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InCVPR, pages 5376–5384. IEEE Computer Society, 2017
work page 2017
-
[25]
The narrativeqa reading comprehension challenge.Trans
Tomás Kociský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The narrativeqa reading comprehension challenge.Trans. Assoc. Comput. Linguistics, 6:317–328, 2018
work page 2018
-
[26]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research.Trans...
work page 2019
-
[27]
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard H. Hovy. RACE: large-scale reading comprehension dataset from examinations. InEMNLP, pages 785–794. Association for Computational Linguistics, 2017
work page 2017
-
[28]
Zero-shot relation extraction via reading comprehension
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading comprehension. InCoNLL, pages 333–342. Association for Computational Linguistics, 2017
work page 2017
-
[29]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InNeurIPS, 2020
work page 2020
-
[30]
Compressing context to enhance inference efficiency of large language models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing context to enhance inference efficiency of large language models. InEMNLP, pages 6342–6353. Association for Computational Linguistics, 2023
work page 2023
-
[31]
Prompt compression for large language models: A survey
Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier. Prompt compression for large language models: A survey. InNAACL (Long Papers), pages 7182–7195. Association for Computational Linguistics, 2025
work page 2025
-
[32]
500xcompressor: Generalized prompt compression for large language models
Zongqian Li, Yixuan Su, and Nigel Collier. 500xcompressor: Generalized prompt compression for large language models. InACL (1), pages 25081–25091. Association for Computational Linguistics, 2025. 11
work page 2025
-
[33]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URLhttps://aclanthology.org/W04-1013/
work page 2004
-
[34]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Trans. Assoc. Comput. Linguistics, 12:157–173, 2024
work page 2024
-
[35]
Xin Liu, Runsong Zhao, Pengcheng Huang, Xinyu Liu, Junyi Xiao, Chunyang Xiao, Tong Xiao, Shengxiang Gao, Zhengtao Yu, and Jingbo Zhu. Autoencoding-free context compression for llms via contextual semantic anchors.CoRR, abs/2510.08907, 2025
-
[36]
Xinyu Liu, Runsong Zhao, Pengcheng Huang, Chunyang Xiao, Bei Li, Jingang Wang, Tong Xiao, and Jingbo Zhu. Forgetting curve: A reliable method for evaluating memorization capability for long-context models, 2024. URLhttps://arxiv.org/abs/2410.04727
-
[37]
Stuart P. Lloyd. Least squares quantization in PCM.IEEE Trans. Inf. Theory, 28(2):129–136, 1982
work page 1982
-
[38]
Attncomp: Attention-guided adaptive context compres- sion for retrieval-augmented generation
Lvzhou Luo, Yixuan Cao, and Ping Luo. Attncomp: Attention-guided adaptive context compres- sion for retrieval-augmented generation. InEMNLP (Findings), pages 8456–8472. Association for Computational Linguistics, 2025
work page 2025
-
[39]
Jesse Mu, Xiang Li, and Noah D. Goodman. Learning to compress prompts with gist tokens. In NeurIPS, 2023
work page 2023
-
[40]
Vicky Zhao, Lili Qiu, and Dongmei Zhang
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In ACL (Findings), pages 963–981. Association for Computational Linguistics, 2024
work page 2024
-
[41]
M. Ross Quillian. Word concepts: A theory and simulation of some basic semantic capabilities. Behavioral Science, 12(5):410–430, 1967. doi: https://doi.org/10.1002/bs.3830120511. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/bs.3830120511
-
[42]
Squad: 100, 000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100, 000+ questions for machine comprehension of text. InEMNLP, pages 2383–2392. The Association for Computational Linguistics, 2016
work page 2016
-
[43]
Context em- beddings for efficient answer generation in retrieval-augmented generation
David Rau, Shuai Wang, Hervé Déjean, Stéphane Clinchant, and Jaap Kamps. Context em- beddings for efficient answer generation in retrieval-augmented generation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, WSDM ’25, page 493–502, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 979840071329...
-
[44]
Khapra, and Karthik Sankaranarayanan
Amrita Saha, Rahul Aralikatte, Mitesh M. Khapra, and Karthik Sankaranarayanan. Duorc: Towards complex language understanding with paraphrased reading comprehension. InACL (1), pages 1683–1693. Association for Computational Linguistics, 2018
work page 2018
-
[45]
Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568: 127063, 2024
work page 2024
-
[46]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
-
[47]
Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph Gonzalez, and Raluca A
Sijun Tan, Xiuyu Li, Shishir G. Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph Gonzalez, and Raluca A. Popa. Lloco: Learning long contexts offline. InEMNLP, pages 17605–17621. Association for Computational Linguistics, 2024
work page 2024
-
[48]
Perception compressor: A training-free prompt compression framework in long context sce- narios
Jiwei Tang, Jin Xu, Tingwei Lu, Zhicheng Zhang, Yiming Zhao, Lin Hai, and Hai-Tao Zheng. Perception compressor: A training-free prompt compression framework in long context sce- narios. InNAACL (Findings), pages 4093–4108. Association for Computational Linguistics, 2025. 12
work page 2025
-
[49]
Jiwei Tang, Zhicheng Zhang, Shunlong Wu, Jingheng Ye, Lichen Bai, Zitai Wang, Tingwei Lu, Jiaqi Chen, Lin Hai, Hai-Tao Zheng, and Hong-Gee Kim. GMSA: enhancing context compression via group merging and layer semantic alignment.CoRR, abs/2505.12215, 2025
-
[50]
Jiwei Tang, Shilei Liu, Zhicheng Zhang, Qingsong Lv, Runsong Zhao, Tingwei Lu, Langming Liu, Haibin Chen, Yujin Yuan, Hai-Tao Zheng, Wenbo Su, and Bo Zheng. Read as human: Compressing context via parallelizable close reading and skimming.CoRR, abs/2602.01840, 2026
-
[51]
COMI: coarse-to-fine context compression via marginal information gain.CoRR, abs/2602.01719, 2026
Jiwei Tang, Shilei Liu, Zhicheng Zhang, Yujin Yuan, Libin Zheng, Wenbo Su, and Bo Zheng. COMI: coarse-to-fine context compression via marginal information gain.CoRR, abs/2602.01719, 2026
-
[52]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence, 2025. URLhttps://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Newsqa: A machine comprehension dataset
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. Newsqa: A machine comprehension dataset. InRep4NLP@ACL, pages 191–200. Association for Computational Linguistics, 2017
work page 2017
-
[54]
George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R. Alvers, Dirk Weissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopoulos, Yannis Almirantis, John Pavlopoulos, Nicolas Baskiotis, Patrick Gallinari, Thierry Artières, Axel-Cyrille Ngonga Ngomo, Norman Heino, Éric Gaussier, Liliana...
work page 2015
-
[55]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNIPS, pages 5998–6008, 2017
work page 2017
-
[56]
Christopher K. I. Williams and Matthias W. Seeger. Using the nyström method to speed up kernel machines. InNIPS, pages 682–688. MIT Press, 2000
work page 2000
-
[57]
Nyströmformer: A nyström-based algorithm for approximating self-attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. InAAAI, pages 14138–14148. AAAI Press, 2021
work page 2021
-
[58]
RECOMP: improving retrieval-augmented lms with context compression and selective augmentation
Fangyuan Xu, Weijia Shi, and Eunsol Choi. RECOMP: improving retrieval-augmented lms with context compression and selective augmentation. InICLR. OpenReview.net, 2024
work page 2024
-
[59]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, et al. Qwen2 technical report.CoRR, abs/2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InEMNLP, pages 2369–2380. Association for Computational Linguistics, 2018
work page 2018
-
[61]
Compact: Compressing retrieved documents actively for question answering
Chanwoong Yoon, Taewhoo Lee, Hyeon Hwang, Minbyul Jeong, and Jaewoo Kang. Compact: Compressing retrieved documents actively for question answering. InEMNLP, pages 21424– 21439. Association for Computational Linguistics, 2024
work page 2024
-
[62]
Long context compression with activation beacon
Peitian Zhang, Zheng Liu, Shitao Xiao, Ninglu Shao, Qiwei Ye, and Zhicheng Dou. Long context compression with activation beacon. InICLR. OpenReview.net, 2025
work page 2025
-
[63]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with BERT. InICLR. OpenReview.net, 2020
work page 2020
-
[64]
SCOPE: A generative approach for LLM prompt compression.CoRR, abs/2508.15813, 2025
Tinghui Zhang, Yifan Wang, and Daisy Zhe Wang. SCOPE: A generative approach for LLM prompt compression.CoRR, abs/2508.15813, 2025. 13
-
[65]
Runsong Zhao, Xin Liu, Xinyu Liu, Pengcheng Huang, Chunyang Xiao, Tong Xiao, and JingBo Zhu. Position ids matter: An enhanced position layout for efficient context compression in large language models. InEMNLP (Findings), pages 17715–17734. Association for Computational Linguistics, 2025
work page 2025
-
[66]
Fengwei Zhou, Jiafei Song, Wenjin Jason Li, Gengjian Xue, Zhikang Zhao, Yichao Lu, and Bailin Na. Mooscomp: Improving lightweight long-context compressor via mitigating over- smoothing and incorporating outlier scores.CoRR, abs/2504.16786, 2025. 14 A Positional Encoding Bias Statement Attention FlowContext Token Position IDLearnable Token 4387654321 Posit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.