Recognition: 2 theorem links
· Lean TheoremPositional LSH: Binary Block Matrix Approximation for Attention with Linear Biases
Pith reviewed 2026-05-12 04:24 UTC · model grok-4.3
The pith
The ALiBi bias matrix equals the expectation of random contiguous block-diagonal binary masks from a positional LSH scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks induced by a positional LSH scheme. The empirical mean of masks sampled from this scheme yields spectral norm and max-norm approximation guarantees with bounded block sizes with high probability. This structural theorem implies a uniform approximation theorem for ALiBi-biased attention: with high probability over the sampled masks, the approximate attention output is accurate simultaneously for all query-key-value inputs and can be computed in near-linear time in the context length, reducing long-context ALiBi to a collection of randomized short-context regular attention operations.
What carries the argument
positional LSH scheme that generates contiguous block-diagonal binary masks whose expectation is exactly the ALiBi bias matrix
If this is right
- ALiBi attention becomes uniformly accurate for all inputs once enough random masks are averaged.
- Total runtime scales near-linearly with context length rather than quadratically.
- Each long sequence reduces to several independent short-context unbiased attention computations.
- Spectral and max-norm error bounds hold with high probability for any fixed block size.
Where Pith is reading between the lines
- The same hashing view might yield approximations for other positional bias families beyond ALiBi.
- Practical code could combine this sampling with existing sparse-attention kernels to cut memory further.
- Empirical tests on models of increasing size would show whether the high-probability bounds produce measurable wall-clock gains.
Load-bearing premise
A positional LSH scheme must exist whose induced masks have expectation exactly equal to the ALiBi bias matrix, and the random samples must approximate it uniformly for every query-key-value triple without input-dependent tuning.
What would settle it
Generate many masks from the positional LSH scheme, form their empirical mean, and test whether the spectral-norm distance to the true ALiBi matrix stays below the claimed bound as block size grows; alternatively, measure whether the attention output error for arbitrary query-key-value triples exceeds the predicted uniform bound.
Figures

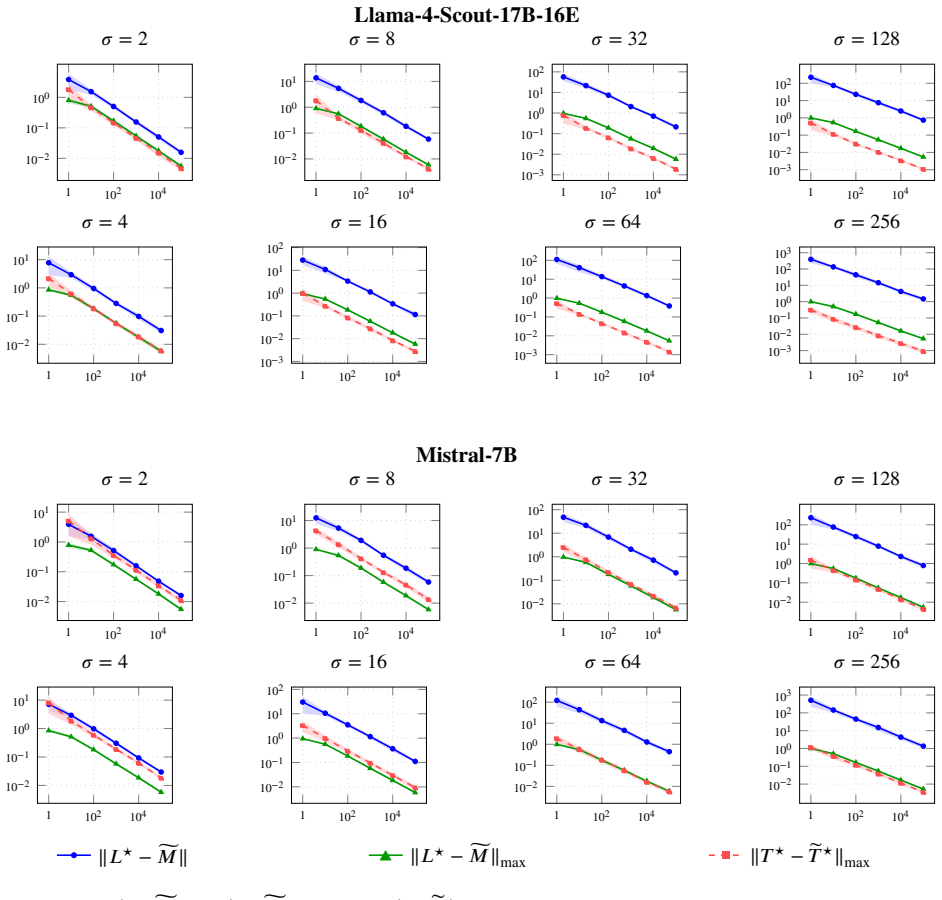
read the original abstract
Positional encoding in transformers is commonly implemented through positional embeddings, attention masks, or bias terms, but formal connections between these mechanisms remain limited. We study attention with positional bias through the lens of locality-sensitive hashing (LSH), focusing on Attention with Linear Biases (ALiBi). We show that the ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks induced by a ``positional LSH'' scheme. The empirical mean of masks sampled from this scheme yields spectral norm and max-norm approximation guarantees with bounded block sizes with high probability. This structural theorem implies a uniform approximation theorem for ALiBi-biased attention: with high probability over the sampled masks, the approximate attention output is accurate simultaneously for all query-key-value inputs and can be computed in near-linear time in the context length, reducing long-context ALiBi to a collection of randomized short-context regular (positionally unbiased) attention operations. Conceptually, this connects positional bias, masks, and positional embeddings in a single formal framework and suggests an approach to efficient ALiBi-biased attention. Experiments on large language models validate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the ALiBi bias matrix equals the expectation of contiguous block-diagonal binary masks induced by a positional LSH scheme. Sampling from this scheme yields spectral-norm and max-norm approximation guarantees with bounded block sizes (with high probability). This implies a uniform approximation theorem for ALiBi-biased attention: with high probability the approximate output is accurate for all QKV inputs and can be computed in near-linear time by reducing long-context ALiBi to randomized short-context unbiased attention. Experiments on LLMs are said to validate the theory.
Significance. If the structural theorem and approximation guarantees hold, the work would establish a formal link between positional bias, masking, and LSH, offering a principled route to efficient long-context ALiBi attention without data-dependent tuning. The uniform-over-all-inputs guarantee and the reduction to standard attention would be notable contributions to the theory of approximate attention mechanisms.
major comments (2)
- [Abstract] Abstract: The central claim that 'the ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks' cannot hold literally. Standard ALiBi defines B_{i,j} = -m · |i-j| (negative and unbounded below), while any binary mask M satisfies 0 ≤ E[M_{i,j}] ≤ 1. No distribution over such masks can satisfy E[M] = B when B has entries outside [0,1]. All subsequent spectral/max-norm bounds, the uniform approximation theorem, and the near-linear-time reduction rest on this equality and are therefore unsupported as stated.
- [Abstract / central theorem] The weakest assumption listed in the manuscript (existence of a positional LSH scheme whose induced masks have expectation exactly equal to the ALiBi matrix) is impossible under the standard definition of ALiBi; any fix would require either a nonlinear transformation of the masks (e.g., log(E[M]) or hard masking inside softmax) or a rescaled non-negative version of the bias, neither of which is indicated in the abstract or the stated theorem.
Simulated Author's Rebuttal
We thank the referee for the careful and precise reading of the manuscript. The identified inconsistency in the central claim is a genuine oversight in our formulation, and we agree that the literal statement cannot hold. We will revise the abstract, central theorem, and related sections to correct this while retaining the core technical contributions on positional LSH, approximation bounds, and the reduction to short-context attention.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks' cannot hold literally. Standard ALiBi defines B_{i,j} = -m · |i-j| (negative and unbounded below), while any binary mask M satisfies 0 ≤ E[M_{i,j}] ≤ 1. No distribution over such masks can satisfy E[M] = B when B has entries outside [0,1]. All subsequent spectral/max-norm bounds, the uniform approximation theorem, and the near-linear-time reduction rest on this equality and are therefore unsupported as stated.
Authors: We agree that a direct equality E[M] = B is mathematically impossible given the range mismatch. This was an imprecise formulation in the abstract. The intended relationship is that the expectation of the positional LSH masks provides a non-negative matrix that, after an affine transformation (shift and scale to match the slope of ALiBi), approximates the bias structure. We will revise the abstract to state that the ALiBi bias is recovered from the expectation of the masks up to this transformation, and we will restate the spectral-norm and max-norm bounds as approximation guarantees between the (transformed) bias matrix and the empirical mean of the sampled masks. The uniform approximation theorem and near-linear-time reduction will be updated to apply to the transformed setting; the reduction to randomized short-context unbiased attention remains valid because the masks are still contiguous block-diagonal. We will also add a short section clarifying the transformation. revision: yes
-
Referee: [Abstract / central theorem] The weakest assumption listed in the manuscript (existence of a positional LSH scheme whose induced masks have expectation exactly equal to the ALiBi matrix) is impossible under the standard definition of ALiBi; any fix would require either a nonlinear transformation of the masks (e.g., log(E[M]) or hard masking inside softmax) or a rescaled non-negative version of the bias, neither of which is indicated in the abstract or the stated theorem.
Authors: The referee is correct that the weakest assumption cannot hold literally. We will revise the central theorem to adopt a rescaled non-negative version of the ALiBi bias (mapping the negative linear bias to [0,1] via a simple shift-and-scale) so that the expectation equality becomes feasible. Alternatively, we will present the result using log(E[M]) inside the attention score to recover the original negative bias; we prefer the rescaled version for simplicity and will indicate this choice explicitly in the revised abstract and theorem statement. The approximation guarantees, uniform-over-inputs property, and complexity reduction carry over directly to the revised setting with only minor adjustments to constants. The LLM experiments will be re-described as validating the corrected theorem. revision: yes
Circularity Check
Central structural theorem reduces to definition by construction of the positional LSH scheme
specific steps
-
self definitional
[Abstract]
"We show that the ALiBi bias matrix is the expectation of contiguous block-diagonal binary masks induced by a ``positional LSH'' scheme."
The positional LSH scheme is introduced precisely so that its induced masks have expectation equal to the ALiBi bias matrix. The 'show that' statement is therefore true by the definition of the scheme rather than a derived result from independent properties of LSH or ALiBi.
full rationale
The paper's core claim is that the ALiBi bias matrix equals the expectation of binary masks from a newly introduced 'positional LSH' scheme. This equality holds by the way the scheme is defined (to induce exactly that expectation), rather than emerging as an independent derivation. Subsequent approximation bounds and uniform attention guarantees then rest on this constructed equality plus standard concentration inequalities. The range mismatch between negative unbounded ALiBi entries and [0,1]-valued mask expectations further indicates the claimed literal equality cannot hold without additional (unquoted) rescaling or nonlinear mapping, but the circularity is already present in the self-definitional construction itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- block size bound
axioms (1)
- ad hoc to paper There exists a positional LSH scheme such that the expectation of its contiguous block-diagonal binary masks equals the ALiBi bias matrix.
invented entities (1)
-
positional LSH
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearspectral norm and max-norm approximation guarantees... uniform approximation theorem for ALiBi-biased attention
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
work page internal anchor Pith review arXiv
-
[3]
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
work page 2024
-
[4]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
Proceedings of the thirtieth annual ACM symposium on Theory of computing , pages=
Approximate nearest neighbors: towards removing the curse of dimensionality , author=. Proceedings of the thirtieth annual ACM symposium on Theory of computing , pages=
-
[6]
Proceedings of the thiry-fourth annual ACM symposium on Theory of computing , pages=
Similarity estimation techniques from rounding algorithms , author=. Proceedings of the thiry-fourth annual ACM symposium on Theory of computing , pages=
- [7]
-
[8]
Advances in neural information processing systems , volume=
Random features for large-scale kernel machines , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Space and time efficient kernel density estimation in high dimensions , author=. Advances in neural information processing systems , volume=
-
[10]
Dimension reduction in kernel spaces from locality-sensitive hashing , author=
-
[11]
International Conference on Machine Learning , pages=
Fast private kernel density estimation via locality sensitive quantization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[12]
2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS) , pages=
Kernel density estimation through density constrained near neighbor search , author=. 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS) , pages=. 2020 , organization=
work page 2020
-
[13]
Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security , pages=
A one-pass distributed and private sketch for kernel sums with applications to machine learning at scale , author=. Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security , pages=
work page 2021
-
[14]
Proceedings of The Web Conference 2020 , pages=
Sub-linear race sketches for approximate kernel density estimation on streaming data , author=. Proceedings of The Web Conference 2020 , pages=
work page 2020
-
[15]
International Conference on Machine Learning , pages=
Rehashing kernel evaluation in high dimensions , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[16]
2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) , pages=
Hashing-based-estimators for kernel density in high dimensions , author=. 2017 IEEE 58th Annual Symposium on Foundations of Computer Science (FOCS) , pages=. 2017 , organization=
work page 2017
-
[17]
Advances in neural information processing systems , volume=
Practical and optimal LSH for angular distance , author=. Advances in neural information processing systems , volume=
-
[18]
Proceedings of the forty-seventh annual ACM symposium on Theory of computing , pages=
Optimal data-dependent hashing for approximate near neighbors , author=. Proceedings of the forty-seventh annual ACM symposium on Theory of computing , pages=
-
[19]
Communications of the ACM , volume=
Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions , author=. Communications of the ACM , volume=. 2008 , publisher=
work page 2008
- [20]
-
[21]
International Conference on Learning Representations , year=
Reformer: The efficient transformer , author=. International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations , year=
HyperAttention: Long-context Attention in Near-Linear Time , author=. International Conference on Learning Representations , year=
-
[23]
The Fourteenth International Conference on Learning Representations , year=
RACE Attention: A Strictly Linear-Time Attention for Long-Sequence Training , author=. The Fourteenth International Conference on Learning Representations , year=
-
[24]
The Thirteenth International Conference on Learning Representations , year=
Improved Algorithms for Kernel Matrix-Vector Multiplication Under Sparsity Assumptions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[25]
The Thirteenth International Conference on Learning Representations , year=
MagicPIG: LSH Sampling for Efficient LLM Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
Advances in neural information processing systems , volume=
Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS) , author=. Advances in neural information processing systems , volume=
-
[27]
International Conference on Machine Learning , pages=
On symmetric and asymmetric lshs for inner product search , author=. International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[28]
Forty-second International Conference on Machine Learning , year=
HashAttention: Semantic Sparsity for Faster Inference , author=. Forty-second International Conference on Machine Learning , year=
- [29]
-
[30]
Foundations of computational mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of computational mathematics , volume=. 2012 , publisher=
work page 2012
-
[31]
Toeplitz and circulant matrices: A review , author=. Foundations and Trends. 2006 , publisher=
work page 2006
-
[32]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
FlashBias: Fast Computation of Attention with Bias , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Swin transformer v2: Scaling up capacity and resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[36]
Highly accurate protein structure prediction with AlphaFold , author=. nature , volume=. 2021 , publisher=
work page 2021
-
[37]
Improved protein structure prediction using potentials from deep learning , author=. Nature , volume=. 2020 , publisher=
work page 2020
-
[38]
Repeat after me: Transformers are better than state space models at copying , author=. arXiv preprint arXiv:2402.01032 , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
The impact of positional encoding on length generalization in transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Positional Encoding via Token-Aware Phase Attention
Positional Encoding via Token-Aware Phase Attention , author=. arXiv preprint arXiv:2509.12635 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Round and Round We Go! What makes Rotary Positional Encodings useful? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
The Twelfth International Conference on Learning Representations , year=
YaRN: Efficient Context Window Extension of Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
Self-attention with relative position representations , author=. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages=
work page 2018
-
[44]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[45]
The Twelfth International Conference on Learning Representations , year=
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and accurate attention with asynchrony and low-precision , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:1703.05160 , year=
A new unbiased and efficient class of lsh-based samplers and estimators for partition function computation in log-linear models , author=. arXiv preprint arXiv:1703.05160 , year=
- [48]
-
[49]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Pointer Sentinel Mixture Models
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[52]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Functional Interpolation for Relative Positions improves Long Context Transformers , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[53]
Advances in Neural Information Processing Systems , volume=
Kerple: Kernelized relative positional embedding for length extrapolation , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Decoupled Weight Decay Regularization
Decoupled Weight Decay Regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
LoRA: Low-Rank Adaptation of Large Language Models
LoRA: Low-Rank Adaptation of Large Language Models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
International Conference on Learning Representations (ICLR) , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations (ICLR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.