Recognition: 2 theorem links
· Lean TheoremTSNBench: Benchmarking LLM Proficiency in Time-Sensitive Networking
Pith reviewed 2026-05-12 03:47 UTC · model grok-4.3
The pith
LLMs that pass multiple-choice tests on time-sensitive networking still make large errors when calculating actual network delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
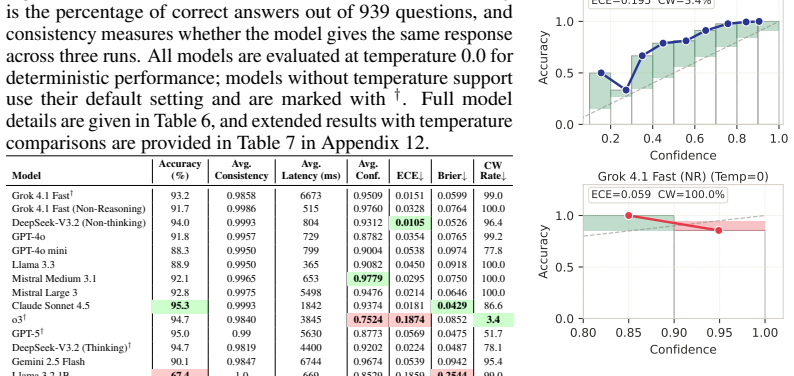
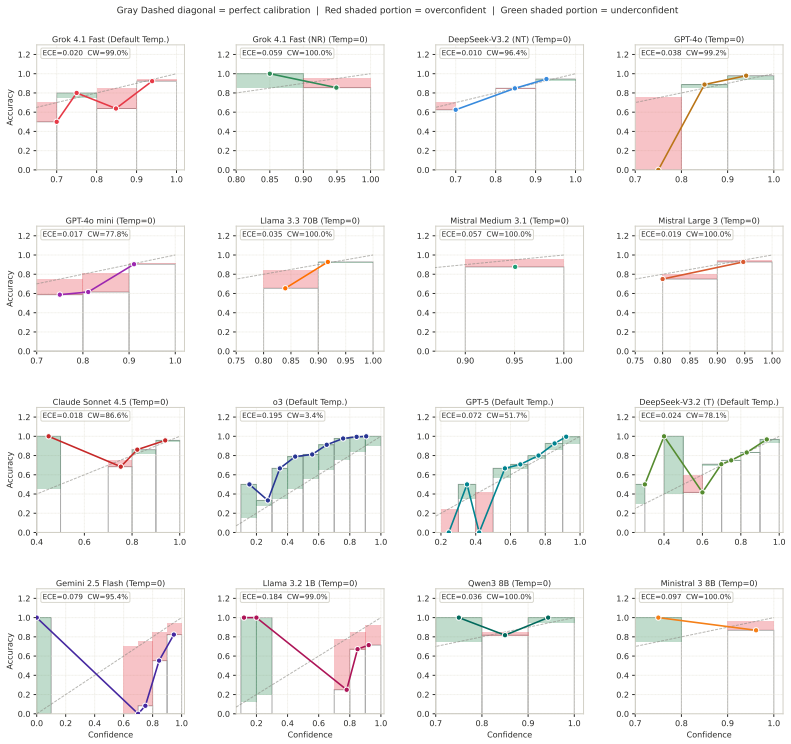
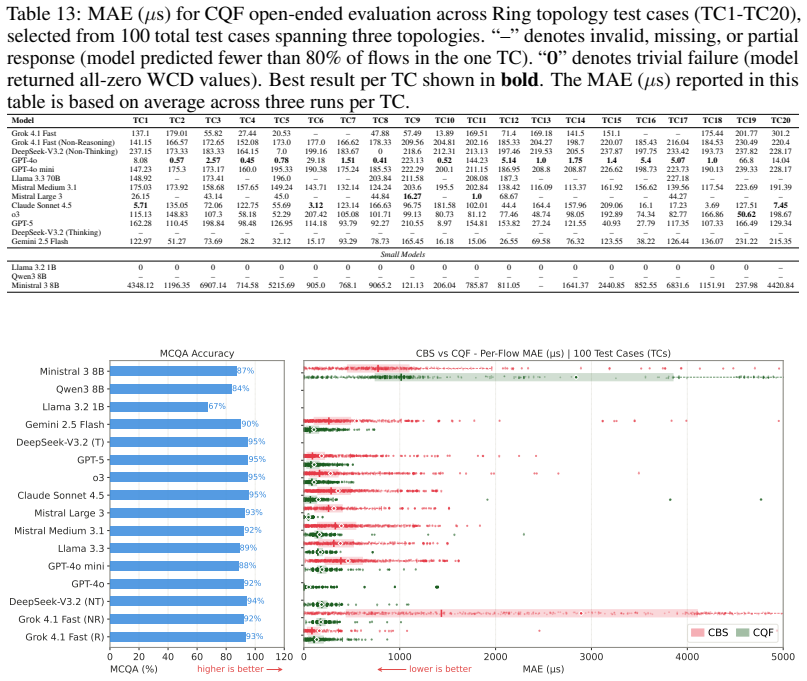
TSNBench shows that although current LLMs achieve 67 to 95 percent accuracy on 939 expert-validated multiple-choice questions covering diverse TSN mechanisms, they fail substantially on 100 open-ended worst-case delay computation tasks, with the best model reaching only 36.2 percent mean absolute percentage error on Credit-Based Shaper cases and most models exceeding 80 percent, and similar high errors on Cyclic Queuing and Forwarding; these deviations are large relative to TSN latency budgets and can produce unsafe network configurations.
What carries the argument
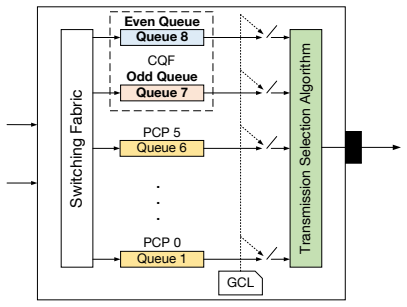
TSNBench benchmark, which combines expert-validated multiple-choice questions with open-ended worst-case delay tasks whose ground-truth values come from a verified network calculus solver for CBS and closed-form mathematical bounds for CQF.
If this is right
- LLMs cannot be relied upon to produce delay bounds accurate enough for TSN network configuration without external verification.
- High scores on multiple-choice TSN questions do not predict success on the quantitative calculations needed for deterministic networking.
- Safety-critical domains require benchmarks that test application of knowledge rather than recognition of concepts.
- Errors of this magnitude can cause real-time constraint violations when LLMs are used to design or validate TSN flows.
- Closed-form bounds and network calculus solvers remain necessary to check LLM outputs in TSN settings.
Where Pith is reading between the lines
- Similar overestimation risks likely appear in other quantitative engineering domains that use multiple-choice tests for certification.
- Hybrid benchmarks that combine questions with simulation or solver verification could become standard for assessing LLM use in regulated systems.
- One practical path forward is to couple LLMs with formal analysis tools so that generated configurations are automatically checked against delay bounds.
- The gap between recognition and calculation performance may shrink only after models receive training data that includes many solved open-ended network examples.
Load-bearing premise
The 100 open-ended worst-case delay tasks and their computed ground-truth values are sufficient and representative of real proficiency in applying TSN mechanisms.
What would settle it
A new evaluation in which the same models achieve mean absolute percentage error below 10 percent on a fresh set of TSN topologies and traffic patterns with verified ground truth would indicate that the overestimation finding does not hold.
Figures










read the original abstract
We present TSNBench, the first benchmark for evaluating large language model (LLM) proficiency in Time-Sensitive Networking (TSN), a suite of IEEE 802.1 standards for deterministic communication with bounded latency in safety-critical domains such as autonomous vehicles, aviation, defense, and industrial automation. While LLMs have been extensively evaluated on general knowledge tasks, their capabilities in safety-critical networking domains remain largely unexplored. TSNBench comprises 939 expert-validated multiple-choice questions (MCQs) covering diverse TSN mechanisms, along with 100 open-ended Worst-Case Delay (WCD) computation tasks for Credit-Based Shaper (CBS) and Cyclic Queuing and Forwarding (CQF) across varying network topologies and traffic conditions. MCQ answers are validated by domain experts, and open-ended ground truth WCD values are computed using a verified Network Calculus (NC) solver for CBS and closed-form mathematical upper bounds for CQF. We evaluate 16 LLMs and find that although models achieve 67 to 95% accuracy on MCQs, they fail substantially on open-ended WCD computation. For CBS, only GPT-5 achieves a Mean Absolute Percentage Error (MAPE) of 36.2%, meaning its predicted WCD deviates by 36.2% of the actual TSN flow delay on average, while most models exceed 80%. For CQF, the best model achieves 41.8% MAPE, with most models clustering between 80% and 100%. Such errors are large relative to TSN latency budgets and can lead to violations of real-time constraints and unsafe configurations. TSNBench demonstrates that MCQ benchmarks may overestimate LLM capabilities in safety-critical networking domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSNBench, the first benchmark for LLM proficiency in Time-Sensitive Networking (TSN). It consists of 939 expert-validated multiple-choice questions (MCQs) covering TSN mechanisms and 100 open-ended Worst-Case Delay (WCD) computation tasks for Credit-Based Shaper (CBS) using a verified Network Calculus solver and Cyclic Queuing and Forwarding (CQF) using closed-form bounds. Evaluation of 16 LLMs shows 67-95% accuracy on MCQs but substantially higher errors on WCD tasks (best MAPE 36.2% for CBS, 41.8% for CQF, with most models 80-100%), leading to the conclusion that MCQ benchmarks may overestimate LLM capabilities in safety-critical networking domains such as autonomous vehicles and industrial automation.
Significance. If the central results hold, the work provides a valuable cautionary demonstration that high MCQ performance does not imply readiness for quantitative, safety-critical applications of TSN standards. The grounding via expert validation of MCQs and use of a verified NC solver plus closed-form bounds is a clear strength, offering reproducible ground truth independent of the models. This could influence benchmark design for AI in deterministic networking and highlight the need for open-ended, tool-assisted evaluations in domains with strict latency bounds.
major comments (2)
- [Benchmark construction and evaluation sections] The 100 open-ended WCD tasks (described in the benchmark construction section): these are narrowly scoped to numerical WCD computation for only CBS (NC solver) and CQF (closed-form bounds) across topologies and traffic conditions. Real TSN proficiency requires iterative configuration, trade-off analysis, and integration of additional mechanisms such as TAS, preemption, and PSFP, none of which are tested. The observed MAPE gap (36-100%) could therefore reflect general arithmetic limitations rather than TSN-specific misunderstanding, weakening the generalization that MCQ scores systematically overestimate domain capabilities.
- [Abstract] Abstract and evaluation protocol: the exact prompt templates, question generation process, and full evaluation protocol for the open-ended tasks are left unspecified. This makes it impossible to determine whether the high WCD errors stem from conceptual gaps in TSN or from prompt sensitivity, limiting the load-bearing strength of the claim that MCQs overestimate proficiency.
minor comments (2)
- [Abstract] The abstract should briefly note the total number of topologies and traffic patterns used in the 100 WCD tasks to allow readers to assess coverage.
- [Results section] Minor notation inconsistency: ensure consistent use of MAPE definition across CBS and CQF results to avoid reader confusion on error scaling relative to TSN latency budgets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TSNBench. We address each major comment point by point below, with clarifications based on the manuscript content and proposed revisions where the comments identify areas for improvement.
read point-by-point responses
-
Referee: [Benchmark construction and evaluation sections] The 100 open-ended WCD tasks (described in the benchmark construction section): these are narrowly scoped to numerical WCD computation for only CBS (NC solver) and CQF (closed-form bounds) across topologies and traffic conditions. Real TSN proficiency requires iterative configuration, trade-off analysis, and integration of additional mechanisms such as TAS, preemption, and PSFP, none of which are tested. The observed MAPE gap (36-100%) could therefore reflect general arithmetic limitations rather than TSN-specific misunderstanding, weakening the generalization that MCQ scores systematically overestimate domain capabilities.
Authors: We agree that the open-ended tasks are scoped to CBS and CQF WCD computation and do not cover iterative configuration or mechanisms such as TAS, preemption, or PSFP. These two mechanisms were selected as they represent foundational and widely deployed TSN shapers with established analytical models (verified NC solver for CBS and closed-form bounds for CQF), allowing reproducible ground truth. The tasks still require models to correctly map TSN-specific concepts (e.g., credit parameters, burst sizes, interference patterns across topologies) into the appropriate formulas, which is distinct from generic arithmetic. Nevertheless, we acknowledge the scope limitation weakens broad generalization claims. We will add an explicit Limitations subsection in the revised manuscript discussing the narrow focus and outlining planned extensions to additional mechanisms. revision: partial
-
Referee: [Abstract] Abstract and evaluation protocol: the exact prompt templates, question generation process, and full evaluation protocol for the open-ended tasks are left unspecified. This makes it impossible to determine whether the high WCD errors stem from conceptual gaps in TSN or from prompt sensitivity, limiting the load-bearing strength of the claim that MCQs overestimate proficiency.
Authors: The manuscript provides the full question generation process, expert validation procedure, prompt templates (zero-shot with task-specific instructions), and evaluation protocol (including model settings and MAPE computation) in Sections 3 and 4. However, the abstract does not summarize these details, which reduces clarity. We will revise the abstract to include a concise description of the evaluation protocol and add explicit cross-references to the relevant sections. We will also release the complete prompt set and evaluation code in a public repository to enable direct assessment of prompt sensitivity. revision: yes
Circularity Check
No circularity: benchmark and conclusions rest on external ground truth
full rationale
The paper defines TSNBench tasks independently, with MCQ answers expert-validated and open-ended WCD ground truths obtained from a verified external Network Calculus solver (CBS) and closed-form mathematical bounds (CQF). LLM accuracies and MAPE errors are computed against these fixed external references; no parameters are fitted to the LLM outputs, no self-citations supply load-bearing uniqueness theorems, and the performance-gap conclusion does not reduce by construction to any input definition or prior author result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTSNBench comprises 939 expert-validated multiple-choice questions (MCQs) covering diverse TSN mechanisms, along with 100 open-ended Worst-Case Delay (WCD) computation tasks for Credit-Based Shaper (CBS) and Cyclic Queuing and Forwarding (CQF) ... ground truth WCD values are computed using a verified Network Calculus (NC) solver for CBS and closed-form mathematical upper bounds for CQF.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearFor CBS, only GPT-5 achieves a Mean Absolute Percentage Error (MAPE) of 36.2% ... For CQF, the best model achieves 41.8% MAPE
Reference graph
Works this paper leans on
-
[1]
Luxi Zhao, Yida Yan, and Xuan Zhou
doi: 10.1109/TNSM.2022.3180160. Luxi Zhao, Yida Yan, and Xuan Zhou. Minimum Bandwidth Reservation for CBS in TSN With Real-Time QoS Guarantees.IEEE Transactions on Industrial Informatics, 20(4):6187–6198, 2024. doi: 10.1109/TII.2023. 3342466. 19 6 Limitations and Broader Impact 6.1 Limitations While TSNBench fills a significant research gap and proposes a...
-
[2]
Future versions should extend to TAS and ATS to cover a broader range of the TSN standard suite
Additional scheduling mechanisms:TSNBench currently evaluates CBS and CQF. Future versions should extend to TAS and ATS to cover a broader range of the TSN standard suite
-
[3]
In future work, we will update the dataset with MCQAs formulated directly from TSN standards
Updated MCQA:Our MCQA dataset was developed using open-source research documents. In future work, we will update the dataset with MCQAs formulated directly from TSN standards
-
[4]
You are an expert Time-Sensitive Networking (TSN) orchestrator
Fine-tuned and domain-adapted models.TSNBench currently evaluates general-purpose LLMs without any TSN-specific fine-tuning. Future versions should benchmark domain- adapted models trained on TSN standards and network calculus literature. 6.3 Broader Impact TSNBench enables the real-time systems community and the machine learning community to ob- jectivel...
-
[5]
Map each egress port’s queues and collect the set of flows traversing from that port, using the given topology, flows, and route of the flow
-
[6]
For each egress port, use the given IdleSlope and then compute the SendSlope
-
[7]
For each flow, construct an arrival curve from its frame size and periodicity
-
[8]
For each port, derive a lower-bounded CBS service curve
-
[9]
Calculate the worst case delay (WCD) in microseconds (µs) for each flow using Network Calculus method
-
[10]
1.0 means mathematically or procedurally provable from given info with zero ambiguity
Provide the confidence score between 0.0 and 1.0 from your answers. 1.0 means mathematically or procedurally provable from given info with zero ambiguity. 0.0 means zero confidence. 36 Table 14: CBS Error Analysis Case 1: Lack of Specific Knowledge. (continued) Grok 4.1 Fast (Non-Reasoning) output: F0: 1452.0, F1: 1124.0, F2: 678.0, F3: 1234.0, F4: 1567.0...
work page 2000
-
[11]
Map each egress port’s queues and collect the set of flows traversing that port, using the given topology, flows, and route of the flow
-
[12]
For the entire network, use the given cycle duration and compute the Hypercycle
-
[13]
For each flow, set the offset or the start time of the flow from the sending node as 0
-
[14]
Calculate the worst case delay (WCD) in microseconds (µs) for each flow
-
[15]
1.0 means mathematically or procedurally provable from given info with zero ambiguity
Provide the confidence score between 0.0 and 1.0 from your answers. 1.0 means mathematically or procedurally provable from given info with zero ambiguity. 0.0 means zero confidence. 41 Table 15: CQF Error Analysis Case 1: Lack of Specific Knowledge. (continued) Claude Sonnet’s output: F0: 257.72, F1: 206.8, F2: 105.096, F3: 218.704, F4: 253.904, F5: 104.0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.