Recognition: 2 theorem links
· Lean TheoremCTQWformer: A CTQW-based Transformer for Graph Classification
Pith reviewed 2026-05-12 04:12 UTC · model grok-4.3
The pith
CTQWformer uses a trainable Hamiltonian to drive continuous-time quantum walks and embed their dynamics into a transformer for graph classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
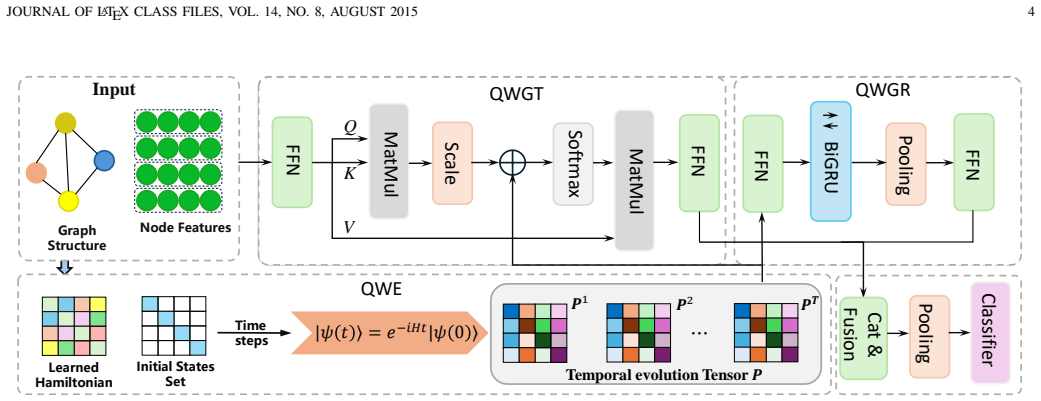
CTQWformer is the first hybrid CTQW-based Transformer: a trainable Hamiltonian that fuses topology and features generates continuous-time quantum walk dynamics whose final-time probabilities serve as structural biases in self-attention while the walk trajectories feed a recurrent module that models temporal evolution, yielding higher accuracy than graph kernels and GNNs on benchmark classification tasks.
What carries the argument
The trainable Hamiltonian that fuses graph topology and node features to generate CTQW dynamics, which are then inserted as attention biases and temporal sequences.
If this is right
- Final-time quantum walk probabilities act as learned structural biases that improve self-attention on graphs.
- The temporal evolution of the walk supplies sequential patterns that bidirectional recurrent layers can model directly.
- The resulting hybrid architecture surpasses both graph kernel methods and standard GNNs on multiple classification benchmarks.
- Quantum dynamics can be simulated classically inside end-to-end trainable deep learning pipelines for graph data.
Where Pith is reading between the lines
- The same Hamiltonian-plus-walk construction could be tested on node-level or link-prediction tasks to check whether the benefit is classification-specific.
- Replacing CTQW with other exactly solvable quantum dynamics (e.g., discrete-time walks or Lindblad evolution) would reveal which physical features matter most.
- Because the Hamiltonian is trainable, the model effectively learns a graph-specific quantum generator; this suggests a broader template for physics-informed layers in GNNs.
- Scaling the approach to very large graphs would require efficient CTQW simulators, linking the method to ongoing work on fast quantum-walk algorithms.
Load-bearing premise
That the quantum walk trajectories produced by the trainable Hamiltonian encode graph information in a way that the transformer and recurrent modules can exploit beyond what classical diffusion or random-walk models achieve.
What would settle it
Replace the CTQW module with an otherwise identical classical diffusion process driven by the same trainable fusion of topology and features, then measure accuracy on the same benchmark datasets; equal or higher performance would undermine the necessity of the quantum-walk component.
Figures


read the original abstract
Graph Neural Networks (GNN) and Transformer-based architectures have achieved remarkable progress in graph learning, yet they still struggle to capture both global structural dependencies and model the dynamic information propagation. In this paper, we propose CTQWformer, a hybrid graph learning framework that integrates continuous-time quantum walks (CTQW) with GNN. CTQWformer employs a trainable Hamiltonian that fuses graph topology and node features, enabling physically grounded modeling of quantum walk dynamics that captures rich and intricate graph structure information. The extracted CTQW-based representations are incorporated into two complementary modules:(i) a Graph Transformer module that embeds final-time propagation probabilities as structural biases in the self-attention mechanism, and (ii) a Graph Recurrent Module that captures temporal evolution patterns with bidirectional recurrent networks. Extensive experiments on benchmark graph classification datasets demonstrate that CTQWformer outperforms graph kernel and GNN-based methods, demonstrating the potential of integrating quantum dynamics into trainable deep learning frameworks for graph representation learning. To the best of our knowledge, CTQWformer is the first hybrid CTQW-based Transformer, integrating CTQW-derived structural bias with temporal evolution modeling to advance graph learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CTQWformer, a hybrid graph learning model that integrates continuous-time quantum walks (CTQW) into a GNN-Transformer architecture for graph classification. It introduces a trainable Hamiltonian fusing graph topology and node features to generate CTQW-based representations, which are then used as structural biases in a Graph Transformer self-attention module and as input to a bidirectional Graph Recurrent Module for capturing temporal evolution. The abstract claims that this yields richer structural information than standard GNNs or kernels and reports outperformance on benchmark datasets, positioning the work as the first CTQW-based Transformer hybrid.
Significance. If the central claims hold, the work could demonstrate a viable route for embedding quantum dynamics into trainable graph models, potentially improving global dependency capture without sacrificing end-to-end learning. The dual use of final-time probabilities and full temporal trajectories is a concrete architectural contribution. However, the significance is currently limited by the absence of explicit verification that the dynamics remain quantum-mechanical.
major comments (2)
- [Abstract and §3] Abstract and §3 (model description): the claim that the trainable Hamiltonian 'enables physically grounded modeling of quantum walk dynamics' is load-bearing for the entire contribution. Continuous-time quantum walks require a Hermitian operator H so that U(t) = exp(-iHt) is unitary and probabilities are conserved. The abstract and model overview give no indication that the fusion step (topology + features) includes an explicit symmetrization, Hermitian projection, or constraint ensuring H = H†. If the resulting matrix is non-Hermitian, the evolution is simply a non-unitary linear system and the 'quantum' justification collapses.
- [§4] §4 (experiments): the reported outperformance over graph kernels and GNN baselines is presented without error bars, statistical significance tests, or details on data splits and hyper-parameter search. Given that the Hamiltonian parameters are learned, it is unclear whether the gains arise from the CTQW dynamics or from the additional capacity of the trainable fusion layer; a controlled ablation removing the quantum propagator while retaining the same parameter count is needed to isolate the contribution.
minor comments (2)
- [§3] Notation for the Hamiltonian construction and the final-time probability extraction should be introduced with explicit equations rather than descriptive prose, to allow readers to verify unitarity and reproducibility.
- [§2] The abstract states 'to the best of our knowledge, CTQWformer is the first hybrid CTQW-based Transformer'; a brief related-work paragraph contrasting with prior quantum-walk or quantum-inspired GNN papers would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and have revised the manuscript to strengthen the presentation and experimental rigor.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (model description): the claim that the trainable Hamiltonian 'enables physically grounded modeling of quantum walk dynamics' is load-bearing for the entire contribution. Continuous-time quantum walks require a Hermitian operator H so that U(t) = exp(-iHt) is unitary and probabilities are conserved. The abstract and model overview give no indication that the fusion step (topology + features) includes an explicit symmetrization, Hermitian projection, or constraint ensuring H = H†. If the resulting matrix is non-Hermitian, the evolution is simply a non-unitary linear system and the 'quantum' justification collapses.
Authors: We agree that Hermitian symmetry of H is required to preserve the unitary evolution and quantum-mechanical interpretation. The original manuscript described the fusion of topology and node features into a trainable Hamiltonian but did not explicitly state the symmetrization step. In the revised version we have added to §3 a clear construction: after forming the fused matrix H_fused from adjacency and feature matrices, we compute H = (H_fused + H_fused^T)/2 + i·diag(·) (with the imaginary part constrained to zero) to enforce H = H† by design. We have also updated the abstract to reference this Hermitian projection. These changes make the physical grounding explicit without altering the model architecture. revision: yes
-
Referee: [§4] §4 (experiments): the reported outperformance over graph kernels and GNN baselines is presented without error bars, statistical significance tests, or details on data splits and hyper-parameter search. Given that the Hamiltonian parameters are learned, it is unclear whether the gains arise from the CTQW dynamics or from the additional capacity of the trainable fusion layer; a controlled ablation removing the quantum propagator while retaining the same parameter count is needed to isolate the contribution.
Authors: We accept that the experimental section required additional statistical rigor and controls. The revised manuscript now reports mean accuracy and standard deviation over 10 independent runs with different random seeds for every method. We include paired t-test p-values against the strongest baselines and document the 10-fold cross-validation splits together with the hyper-parameter grid search procedure in the supplementary material. We have also added an ablation that replaces the CTQW propagator with a non-quantum linear layer of identical dimensionality and parameter count; the performance drop in this ablation supports that the gains originate from the quantum dynamics rather than extra capacity alone. revision: yes
Circularity Check
No circularity: trainable Hamiltonian and CTQW representations are standard parametric components, not self-defining or fitted-input renamings.
full rationale
The paper's derivation proceeds from a trainable Hamiltonian (parameterized fusion of topology and features) to CTQW evolution, extraction of final-time probabilities as structural biases, and their insertion into transformer/recurrent modules for end-to-end classification training. No quoted equation reduces the extracted probabilities or final representations to the fitted parameters by construction (e.g., no self-definitional loop where the output is the input fit, and no 'prediction' of a quantity that is statistically forced by the same fit). The architecture is a conventional deep-learning pipeline with a quantum-inspired layer; the downstream task loss drives all parameters without tautological renaming or load-bearing self-citation chains. This is the normal, non-circular case for hybrid models.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe define a learnable Hamiltonian ... Wij = σ(W2 · ϕ(W1 eij)) ... Asym = ½(Wθ + Wθ^T) ... Hθ = D' - Asym ... |ψ(t)⟩ = e^{-i H t} |ψ(0)⟩ ... P ∈ R^{T×n×n}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe extracted CTQW-based representations are incorporated into ... Graph Transformer ... Graph Recurrent Module
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,”IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020
work page 2020
-
[2]
S. Yun, M. Jeong, R. Kim, J. Kang, and H. J. Kim, “Graph transformer networks,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[3]
Do transformers really perform badly for graph representation?
C. Ying, T. Cai, S. Luo, S. Zheng, G. Ke, D. He, Y. Shen, and T.-Y. Liu, “Do transformers really perform badly for graph representation?” Advances in neural information processing systems, vol. 34, pp. 28877– 28888, 2021
work page 2021
-
[4]
G. Corso, H. Stark, S. Jegelka, T. Jaakkola, and R. Barzilay, “Graph neural networks,”Nature Reviews Methods Primers, vol. 4, no. 1, p. 17, 2024
work page 2024
-
[5]
A quantum jensen– shannon graph kernel for unattributed graphs,
L. Bai, L. Rossi, A. Torsello, and E. R. Hancock, “A quantum jensen– shannon graph kernel for unattributed graphs,”Pattern Recognition, vol. 48, no. 2, pp. 344–355, 2015
work page 2015
-
[6]
D. Aharonov, A. Ambainis, J. Kempe, and U. Vazirani, “Quantum walks on graphs,” inProceedings of the thirty-third annual ACM symposium on Theory of computing, 2001, pp. 50–59
work page 2001
-
[8]
Convolution kernels on discrete structures,
D. Haussleret al., “Convolution kernels on discrete structures,” Tech- nical report, Department of Computer Science, University of Califor- nia ..., Tech. Rep., 1999
work page 1999
-
[9]
Efficient graphlet kernels for large graph comparison,
N. Shervashidze, S. Vishwanathan, T. Petri, K. Mehlhorn, and K. Borg- wardt, “Efficient graphlet kernels for large graph comparison,” inArti- ficial intelligence and statistics. PMLR, 2009, pp. 488–495
work page 2009
-
[10]
Weisfeiler-lehman graph kernels
N. Shervashidze, P. Schweitzer, E. J. Van Leeuwen, K. Mehlhorn, and K. M. Borgwardt, “Weisfeiler-lehman graph kernels.”Journal of Machine Learning Research, vol. 12, no. 9, 2011
work page 2011
-
[11]
On graph kernels: Hardness results and efficient alternatives,
T. Gärtner, P. Flach, and S. Wrobel, “On graph kernels: Hardness results and efficient alternatives,” inLearning theory and kernel machines: 16th annual conference on learning theory and 7th kernel workshop, COLT/kernel 2003, washington, DC, USA, August 24-27, 2003. pro- ceedings. Springer, 2003, pp. 129–143
work page 2003
-
[12]
Attributed graph kernels using the jensen-tsallis q-differences,
L. Bai, L. Rossi, H. Bunke, and E. R. Hancock, “Attributed graph kernels using the jensen-tsallis q-differences,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2014, pp. 99–114
work page 2014
-
[13]
Haqjsk: Hierarchical-aligned quantum jensen-shannon kernels for graph classification,
L. Bai, L. Cui, Y. Wang, M. Li, J. Li, P. S. Yu, and E. R. Hancock, “Haqjsk: Hierarchical-aligned quantum jensen-shannon kernels for graph classification,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6370–6384, 2024
work page 2024
-
[14]
Aerk: Aligned entropic reproducing kernels through continuous-time quantum walks,
L. Cui, M. Li, Y. Wang, L. Bai, and E. R. Hancock, “Aerk: Aligned entropic reproducing kernels through continuous-time quantum walks,” arXiv preprint arXiv:2303.03396, 2023
-
[15]
N. M. Kriege, F. D. Johansson, and C. Morris, “A survey on graph kernels,”Applied Network Science, vol. 5, no. 1, p. 6, 2020
work page 2020
-
[16]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,”arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[18]
How Powerful are Graph Neural Networks?
K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?”arXiv preprint arXiv:1810.00826, 2018
work page internal anchor Pith review arXiv 2018
-
[19]
Recipe for a general, powerful, scalable graph transformer,
L. Rampášek, M. Galkin, V. P. Dwivedi, A. T. Luu, G. Wolf, and D. Beaini, “Recipe for a general, powerful, scalable graph transformer,” Advances in Neural Information Processing Systems, vol. 35, pp. 14501– 14515, 2022
work page 2022
-
[20]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[21]
Random walk graph neural networks,
G. Nikolentzos and M. Vazirgiannis, “Random walk graph neural networks,”Advances in Neural Information Processing Systems, vol. 33, pp. 16211–16222, 2020
work page 2020
-
[22]
Graph inductive biases in transformers without message passing,
L. Ma, C. Lin, D. Lim, A. Romero-Soriano, P. K. Dokania, M. Coates, P. Torr, and S.-N. Lim, “Graph inductive biases in transformers without message passing,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 23321–23337
work page 2023
-
[23]
G. Yan, Y. Tang, and J. Yan, “Towards a native quantum paradigm for graph representation learning: A sampling-based recurrent embedding approach,” inProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 2160–2168. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
work page 2022
-
[24]
Link prediction with continuous-time classical and quantum walks,
M. Goldsmith, H. Saarinen, G. García-Pérez, J. Malmi, M. A. Rossi, and S. Maniscalco, “Link prediction with continuous-time classical and quantum walks,”Entropy, vol. 25, no. 5, p. 730, 2023
work page 2023
-
[25]
Quantum walk and its applica- tion domains: A systematic review,
K. Kadian, S. Garhwal, and A. Kumar, “Quantum walk and its applica- tion domains: A systematic review,”Computer Science Review, vol. 41, p. 100419, 2021
work page 2021
-
[26]
Gqwformer: A quantum- based transformer for graph representation learning,
L. Yu, H. Chen, J. Lv, and L. Yang, “Gqwformer: A quantum- based transformer for graph representation learning,”arXiv preprint arXiv:2412.02285, 2024
-
[27]
C. Morris, N. M. Kriege, F. Bause, K. Kersting, P. Mutzel, and M. Neu- mann, “Tudataset: A collection of benchmark datasets for learning with graphs,”arXiv preprint arXiv:2007.08663, 2020
-
[28]
Design space for graph neural networks,
J. You, Z. Ying, and J. Leskovec, “Design space for graph neural networks,”Advances in Neural Information Processing Systems, vol. 33, pp. 17009–17021, 2020
work page 2020
-
[29]
P. Yanardag and S. Vishwanathan, “Deep graph kernels,” inProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, 2015, pp. 1365–1374
work page 2015
-
[30]
An end-to-end deep learning architecture for graph classification,
M. Zhang, Z. Cui, M. Neumann, and Y. Chen, “An end-to-end deep learning architecture for graph classification,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
work page 2018
-
[31]
Learning convolutional neural networks for graphs,
M. Niepert, M. Ahmed, and K. Kutzkov, “Learning convolutional neural networks for graphs,” inInternational conference on machine learning. PMLR, 2016, pp. 2014–2023
work page 2016
-
[32]
P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Ben- gio, “Graph attention networks,”arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Z. Xinyi and L. Chen, “Capsule graph neural network,” inInternational conference on learning representations, 2018
work page 2018
-
[34]
Universal graph trans- former self-attention networks,
D. Q. Nguyen, T. D. Nguyen, and D. Phung, “Universal graph trans- former self-attention networks,” inCompanion Proceedings of the Web Conference 2022, 2022, pp. 193–196
work page 2022
-
[35]
A fair compari- son of graph neural networks for graph classification,
F. Errica, M. Podda, D. Bacciu, and A. Micheli, “A fair compari- son of graph neural networks for graph classification,”arXiv preprint arXiv:1912.09893, 2019
-
[36]
A comprehensive evaluation of graph kernels for unattributed graphs,
Y. Zhang, L. Wang, and L. Wang, “A comprehensive evaluation of graph kernels for unattributed graphs,”Entropy, vol. 20, p. 984, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.