Recognition: no theorem link
Kintsugi: Learning Policies by Repairing Executable Knowledge Bases
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
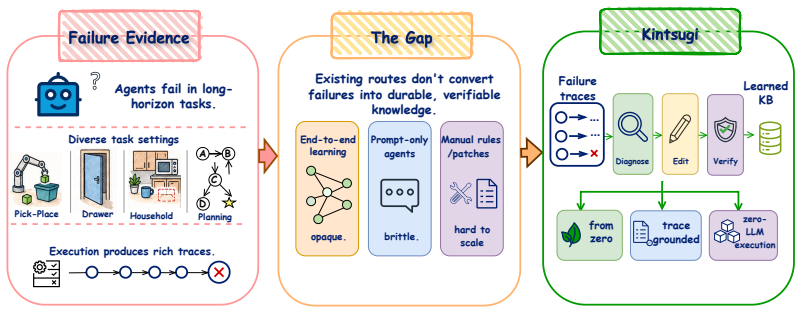
Kintsugi improves embodied policies by repairing a typed executable knowledge base using localized verifier-gated edits from rollout evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Kintsugi treats embodied policy improvement as verifier-gated construction of a typed executable knowledge base whose entries include predicates, operators, policy schemas, monitors, recovery rules, experience records, and goals; edits are induced from rollout evidence, localized to specific KB layers, and admitted only when they satisfy type safety, executability, and net-positive metric improvement without violating protected-regression checks.
What carries the argument
The typed executable Knowledge Base (KB) together with its agentic editing loop and deterministic verification gate that localizes rollout failures to editable entries and admits only safe improvements.
If this is right
- Policies remain fully inspectable and support local edits at the granularity of individual predicates, schemas, or recovery rules.
- Inference uses only a deterministic symbolic executor, removing all LLM calls during deployment.
- Policy improvement can be organized as iterative construction and repair of executable task knowledge rather than gradient updates or test-time reasoning.
- Verifier-gated deployment provides a built-in safety filter that preserves stability while incorporating evidence-based changes.
Where Pith is reading between the lines
- The same repair loop could be applied to other explicit symbolic structures beyond the listed entry types, such as planning operators or constraint sets.
- Maintaining an explicit KB may simplify knowledge transfer or composition across related tasks compared with weight-based or prompt-based methods.
- The framework invites experiments that measure how much of the performance gain comes from the KB structure versus the quality of the verification metrics.
Load-bearing premise
That trajectory failures can be accurately localized to specific layers or entries in the knowledge base and that the verification gate will admit only net-positive edits without missing critical improvements or allowing hidden regressions.
What would settle it
An experiment in which the editing loop repeatedly fails to localize a recurring failure to the correct KB entry or in which the gate accepts an edit that later produces a clear regression on a held-out task set.
Figures


read the original abstract
Modern embodied agents achieve impressive performance, but their task knowledge is often stored in neural weights, latent state, or prompt-bound memory, making individual policy knowledge difficult to inspect, validate, recombine, and reuse. We introduce \textbf{Kintsugi}, a white-box policy-learning framework that treats embodied policy improvement as verifier-gated construction of a typed executable Knowledge Base (KB). Kintsugi represents task-level policy knowledge as composable typed entries -- predicates, operators, policy schemas, monitors, recovery rules, experience records, and goals -- and improves this artifact through localized typed edits induced from rollout evidence, rather than relying on test-time language-model reasoning. Between rollouts, a tool-constrained agentic editing loop diagnoses trajectory failures, localizes them to editable KB layers, and proposes candidate edits. A deterministic verification gate admits an edit only when the candidate type-checks, the resulting KB executes, and focused validation success or trajectory-health metrics improve without violating protected-regression checks. At inference, the accepted KB is executed by a deterministic symbolic executor with zero LLM calls. Across long-horizon text-agent benchmarks and representative object-centric manipulation settings, Kintsugi achieves strong endpoint performance while preserving inspectability, local editability, and verifier-gated deployment. These results suggest that embodied policy improvement can be organized around executable task knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kintsugi, a white-box policy-learning framework that represents embodied task knowledge as a typed executable Knowledge Base (KB) of predicates, operators, policy schemas, monitors, recovery rules, experience records, and goals. Policy improvement is performed via a tool-constrained agentic editing loop that diagnoses rollout failures, localizes them to KB layers, and proposes edits; a deterministic verification gate accepts an edit only if it type-checks, executes, improves focused validation or trajectory-health metrics, and passes protected-regression checks. At inference the accepted KB is executed by a deterministic symbolic executor with zero LLM calls. The authors claim that this yields strong endpoint performance on long-horizon text-agent and object-centric manipulation benchmarks while preserving inspectability, local editability, and verifier-gated deployment.
Significance. If the localization and gate mechanisms prove reliable, the work would be significant for embodied AI by shifting policy learning from opaque neural weights or prompt memory to an inspectable, locally editable, and formally verifiable executable KB. The verifier-gated construction and tool-constrained editing loop constitute a concrete alternative to test-time LLM reasoning; the zero-LLM inference path is a clear practical advantage if the empirical claims hold.
major comments (3)
- [Abstract] Abstract: the central claim of 'strong endpoint performance' is stated without any quantitative results, baselines, error bars, or ablation numbers, leaving the reader unable to assess whether the verifier-gated KB construction actually outperforms existing methods.
- [Editing loop description (likely §3)] The iterative improvement argument rests on the assumption that trajectory failures can be accurately localized to individual typed KB entries rather than to emergent compositional interactions across layers; no quantitative localization accuracy, confusion matrices, or failure-case studies are supplied to support this load-bearing step.
- [Verification gate (Abstract and §3)] The deterministic verification gate is asserted to admit only net-positive edits, yet the manuscript supplies no false-positive or false-negative rates for the gate, no protected-regression violation statistics, and no analysis of how the gate behaves on compositional failures; these metrics are required to substantiate the 'without violating protected-regression checks' guarantee.
minor comments (2)
- [KB representation] The typing discipline for KB entries (predicates, operators, schemas) is described at a high level; a small formal grammar or example signature table would improve precision.
- [Figure 1 (if present)] If a system diagram exists, it should explicitly label the inputs and outputs of the verification gate to clarify the data flow between rollout evidence and accepted edits.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for major revision. We address each major comment below and will incorporate the suggested additions and clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'strong endpoint performance' is stated without any quantitative results, baselines, error bars, or ablation numbers, leaving the reader unable to assess whether the verifier-gated KB construction actually outperforms existing methods.
Authors: We agree that the abstract should include quantitative support for the performance claims. In the revised version we will add specific endpoint success rates on the long-horizon text-agent and object-centric manipulation benchmarks, direct comparisons to the strongest baselines, and references to the error bars and ablation results already reported in the experimental section. revision: yes
-
Referee: [Editing loop description (likely §3)] The iterative improvement argument rests on the assumption that trajectory failures can be accurately localized to individual typed KB entries rather than to emergent compositional interactions across layers; no quantitative localization accuracy, confusion matrices, or failure-case studies are supplied to support this load-bearing step.
Authors: Localization is performed by the agentic diagnosis step that matches execution traces against the typed KB structure. The manuscript contains qualitative examples but lacks quantitative localization accuracy or confusion matrices. We will add a dedicated failure-case study subsection together with localization success rates computed on a held-out trajectory set; the verification gate remains the primary safeguard against imperfect localization. revision: partial
-
Referee: [Verification gate (Abstract and §3)] The deterministic verification gate is asserted to admit only net-positive edits, yet the manuscript supplies no false-positive or false-negative rates for the gate, no protected-regression violation statistics, and no analysis of how the gate behaves on compositional failures; these metrics are required to substantiate the 'without violating protected-regression checks' guarantee.
Authors: We acknowledge that aggregate false-positive/negative rates for the gate and detailed regression-violation statistics are not reported. We will add these metrics by logging every proposed edit and its outcome across the experimental runs. We will also include a short analysis of gate behavior on compositional failures, showing how the combination of focused validation metrics and protected-regression checks prevents net-negative edits in such cases. revision: yes
Circularity Check
No significant circularity; framework presented as independent new construction
full rationale
The paper introduces Kintsugi as a novel white-box framework for policy learning via verifier-gated KB repair, with no equations, fitted parameters, or predictions that reduce to inputs by construction. The abstract describes the approach in terms of typed KB entries, localized edits from rollout evidence, and a deterministic verification gate, without self-referential definitions, self-citation load-bearing claims, or renaming of known results. No derivation chain is present that loops back to its own assumptions or data fits; the central claims rest on the empirical performance across benchmarks rather than on any internal reduction. This is a self-contained framework proposal with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embodied policy knowledge can be represented as composable typed entries (predicates, operators, schemas, monitors, recovery rules, experience records, goals) that admit localized edits.
invented entities (1)
-
verifier-gated construction of typed executable KB
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Automan- ual: Constructing instruction manuals by llm agents via interactive environmental learning
Minghao Chen, Yihang Li, Yanting Yang, Shiyu Yu, Binbin Lin, and Xiaofei He. Automan- ual: Constructing instruction manuals by llm agents via interactive environmental learning. volume 37, pages 589–631, 2024
work page 2024
-
[4]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 2025
work page 2025
-
[5]
Learning neuro-symbolic relational transition models for bilevel planning
Rohan Chitnis, Tom Silver, Joshua B Tenenbaum, Tomas Lozano-Perez, and Leslie Pack Kaelbling. Learning neuro-symbolic relational transition models for bilevel planning. In2022 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 4166–4173. IEEE, 2022
work page 2022
-
[6]
Yu Deng, Yufeng Jin, Xiaogang Jia, Jiahong Xue, Gerhard Neumann, and Georgia Chalvatzaki. Robot-dift: Distilling diffusion features for geometrically consistent visuomotor control.arXiv preprint arXiv:2602.11934, 2026
-
[7]
Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning
Caelan Reed Garrett, Tomás Lozano-Pérez, and Leslie Pack Kaelbling. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. InProceedings of the international conference on automated planning and scheduling, volume 30, pages 440–448, 2020. 10
work page 2020
-
[8]
Caelan Reed Garrett, Rohan Chitnis, Rachel Holladay, Beomjoon Kim, Tom Silver, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Integrated task and motion planning.Annual review of control, robotics, and autonomous systems, 4(1):265–293, 2021
work page 2021
-
[9]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Muzhi Han, Yifeng Zhu, Song-Chun Zhu, Ying Nian Wu, and Yuke Zhu. Interpret: Interactive predicate learning from language feedback for generalizable task planning.arXiv preprint arXiv:2405.19758, 2024
-
[11]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. 2023
work page 2023
-
[12]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. π0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Hierarchical task and motion planning in the now
Leslie Pack Kaelbling and Tomás Lozano-Pérez. Hierarchical task and motion planning in the now. In2011 IEEE international conference on robotics and automation. IEEE, 2011
work page 2011
-
[14]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
George Konidaris, Leslie Pack Kaelbling, and Tomas Lozano-Perez. From skills to sym- bols: Learning symbolic representations for abstract high-level planning.Journal of Artificial Intelligence Research, 61:215–289, 2018
work page 2018
-
[16]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
work page 2023
-
[17]
Visualpredicator: Learning abstract world models with neuro-symbolic predicates for robot planning
Yichao Liang, Nishanth Kumar, Hao Tang, Adrian Weller, Joshua B Tenenbaum, Tom Silver, Joao F Henriques, and Kevin Ellis. Visualpredicator: Learning abstract world models with neuro-symbolic predicates for robot planning. InThe Thirteenth International Conference on Learning Representations
-
[18]
Tenenbaum, Carl Edward Rasmussen, Adrian Weller, Zenna Tavares, Tom Silver, and Kevin Ellis
Yichao Liang, Thanh Dat Nguyen, Cambridge Yang, Tianyang Li, Joshua B. Tenenbaum, Carl Edward Rasmussen, Adrian Weller, Zenna Tavares, Tom Silver, and Kevin Ellis. Exo- predicator: Learning abstract models of dynamic worlds for robot planning. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[19]
Embodied lifelong learning for task and motion planning
Jorge Mendez-Mendez, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Embodied lifelong learning for task and motion planning. InConference on Robot Learning, pages 2134–2150. PMLR, 2023
work page 2023
-
[20]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
work page 2023
-
[21]
Adapt: As-needed decomposition and planning with language models
Archiki Prasad, Alexander Koller, Mareike Hartmann, Peter Clark, Ashish Sabharwal, Mohit Bansal, and Tushar Khot. Adapt: As-needed decomposition and planning with language models. InFindings of the Association for Computational Linguistics: NAACL 2024, 2024
work page 2024
-
[22]
Stateact: Enhancing llm base agents via self-prompting and state-tracking
Nikolai Rozanov and Marek Rei. Stateact: Enhancing llm base agents via self-prompting and state-tracking. InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 367–385, 2025
work page 2025
-
[23]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. volume 36, pages 8634–8652, 2023. 11
work page 2023
-
[24]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review arXiv 2010
-
[25]
Learning symbolic operators for task and motion planning
Tom Silver, Rohan Chitnis, Joshua Tenenbaum, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. Learning symbolic operators for task and motion planning. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3182–3189. IEEE, 2021
work page 2021
-
[26]
Predicate invention for bilevel planning
Tom Silver, Rohan Chitnis, Nishanth Kumar, Willie McClinton, Tomás Lozano-Pérez, Leslie Kaelbling, and Joshua B Tenenbaum. Predicate invention for bilevel planning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12120–12129, 2023
work page 2023
-
[27]
Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[28]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856
work page 2024
-
[30]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Bin Wen, Ruoxuan Zhang, Yang Chen, Hongxia Xie, and Lan-Zhe Guo. Aligning progress and feasibility: A neuro-symbolic dual memory framework for long-horizon llm agents.arXiv preprint arXiv:2604.02734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 2022
work page 2022
-
[33]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[34]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, 2020
work page 2020
-
[35]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. 2024
work page 2024
-
[36]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
work page 2024
-
[37]
arXiv preprint arXiv:2504.15785 , year =
Siyu Zhou, Tianyi Zhou, Yijun Yang, Guodong Long, Deheng Ye, Jing Jiang, and Chengqi Zhang. Wall-e 2.0: World alignment by neurosymbolic learning improves world model-based llm agents.arXiv preprint arXiv:2504.15785, 2025
-
[38]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Abhiram Maddukuri, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review arXiv 2009
-
[39]
diff" apply_failed := decision==
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 12 A Appendix Roadmap and Evaluation Contract The appendix supplements the main text r...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.