Recognition: unknown
{π}_{0.7}: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Pith reviewed 2026-05-10 11:40 UTC · model grok-4.3
The pith
A robotic foundation model conditioned on diverse multimodal prompts achieves strong zero-shot performance across new environments, embodiments, and complex tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that diverse context conditioning during training, where prompts include language, metadata about task performance, and subgoal images, allows the model to be steered to different strategies and to learn from heterogeneous data sources, leading to emergent generalization capabilities such as cross-embodiment transfer and competitive performance on challenging manipulations without additional fine-tuning.
What carries the argument
diverse multimodal context conditioning in the prompt, which includes language instructions along with metadata and subgoal images to guide the model's strategy and enable use of broad data
Load-bearing premise
That training with diverse multimodal context conditioning is enough by itself to create reliable generalization and emergent skills without depending on specific choices in data collection or evaluation that favor the reported results.
What would settle it
A controlled test showing that π₀.₇ performs no better than a baseline without the extra conditioning information on a new embodiment or unseen task would falsify the central claim.
Figures




















read the original abstract
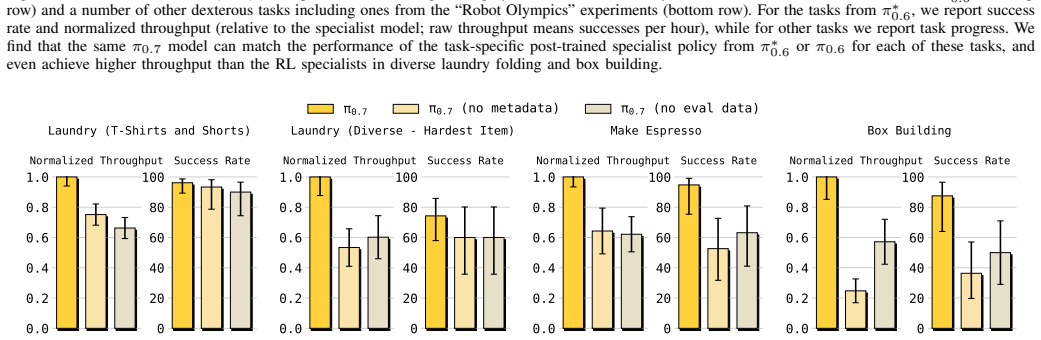
We present a new robotic foundation model, called ${\pi}_{0.7}$, that can enable strong out-of-the-box performance in a wide range of scenarios. ${\pi}_{0.7}$ can follow diverse language instructions in unseen environments, including multi-stage tasks with various kitchen appliances, provide zero-shot cross-embodiment generalization, for example enabling a robot to fold laundry without seeing the task before, and perform challenging tasks such as operating an espresso machine out of the box at a level of performance that matches much more specialized RL-finetuned models. The main idea behind ${\pi}_{0.7}$ is to use diverse context conditioning during training. This conditioning information, contained in the prompt, makes it possible to steer the model precisely to perform many tasks with different strategies. It is conditioned not just on a language command that describes what it should do, but on additional multimodal information that also describes the manner or strategy in which it should do it, including metadata about task performance and subgoal images. This enables ${\pi}_{0.7}$ to use very diverse data, including demonstrations, potentially suboptimal (autonomous) data including failures, and data from non-robot sources. Our experiments evaluate ${\pi}_{0.7}$ across numerous tasks with multiple robot platforms, on tasks that require speed and dexterity, language following, and compositional task generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents π₀.₇, a robotic foundation model trained with diverse multimodal context conditioning (language instructions, task metadata, and subgoal images) on heterogeneous data sources including demonstrations, suboptimal autonomous trajectories, and non-robot data. The central claim is that this steerable conditioning enables strong zero-shot performance on multi-stage language-following tasks in unseen environments, cross-embodiment generalization (e.g., laundry folding), and performance matching specialized RL-finetuned models on challenging tasks such as espresso machine operation, all without task-specific fine-tuning.
Significance. If the experimental claims hold, the work would constitute a meaningful advance in generalist robotic policies by showing that prompt-based multimodal conditioning on varied data can produce reliable transfer and emergent capabilities. The explicit use of suboptimal and non-robot data sources is a positive methodological feature that could reduce reliance on curated expert demonstrations.
minor comments (3)
- [Abstract] Abstract: the statement that performance 'matches much more specialized RL-finetuned models' should be accompanied by the specific quantitative metrics, success rates, and baselines used for this comparison; without them the claim is difficult to evaluate from the summary alone.
- [Methods] The description of 'diverse context conditioning' would benefit from an explicit equation or diagram in the methods section showing how language, metadata, and subgoal images are tokenized and fused into the policy input.
- [Experiments] Experiments: the claim of zero-shot cross-embodiment generalization would be strengthened by reporting the exact number of training embodiments versus test embodiments and any statistical significance tests on the transfer results.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on π₀.₇ and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical training procedure for a robotic foundation model π₀.₇ that conditions on multimodal prompts (language instructions, metadata, subgoal images) and trains on diverse data sources including demonstrations, suboptimal autonomous data, and non-robot sources. No mathematical derivation chain, equations, or first-principles results are described that reduce outputs to inputs by construction. Claims of zero-shot generalization, cross-embodiment transfer, and emergent capabilities are framed as outcomes of this standard context-augmented imitation learning setup, evaluated empirically across tasks and robot platforms. No self-definitional steps, fitted parameters renamed as predictions, load-bearing self-citations, or ansatz smuggling are present in the provided description or abstract. The central premise relies on external data diversity and conditioning rather than internal self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer-based models can effectively learn policies from large-scale multimodal robotic and non-robotic data when provided with rich conditioning.
Forward citations
Cited by 10 Pith papers
-
DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Discrete diffusion policies support native asynchronous execution via unmasking for real-time chunking, delivering higher success rates and 0.7x inference cost versus flow-matching RTC on dynamic robotics benchmarks a...
-
Engagement Process: Rethinking the Temporal Interface of Action and Observation
Engagement Process decouples actions and observations into separate time-based event streams within a POMDP structure to explicitly model timing mismatches, deliberation latency, and multi-rate interactions.
-
HarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models
HarmoWAM unifies predictive and reactive control in world action models via an adaptive gating mechanism to deliver improved zero-shot generalization and precision in robotic manipulation.
-
Kintsugi: Learning Policies by Repairing Executable Knowledge Bases
Kintsugi learns policies by repairing composable executable knowledge bases through agentic diagnosis, localized typed edits, and deterministic verification gates that admit only improvements.
-
LaST-R1: Reinforcing Robotic Manipulation via Adaptive Physical Latent Reasoning
LaST-R1 introduces a RL post-training method called LAPO that optimizes latent Chain-of-Thought reasoning in vision-language-action models, yielding 99.9% success on LIBERO and up to 22.5% real-world gains.
-
LaST-R1: Reinforcing Robotic Manipulation via Adaptive Physical Latent Reasoning
LaST-R1 reaches 99.8% average success on the LIBERO benchmark using one-shot warm-up plus LAPO reinforcement learning on latent physical reasoning, with up to 44% real-world gains on complex single- and dual-arm tasks.
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
-
The Agent Use of Agent Beings: Agent Cybernetics Is the Missing Science of Foundation Agents
Agent Cybernetics reframes foundation agent design by adapting classical cybernetics laws into three engineering desiderata for reliable, long-running, self-improving agents.
-
RLDX-1 Technical Report
RLDX-1 outperforms frontier VLAs such as π0.5 and GR00T N1.6 on dexterous manipulation benchmarks, reaching 86.8% success on ALLEX humanoid tasks versus around 40% for the baselines.
-
RLDX-1 Technical Report
RLDX-1 achieves 86.8% success on complex ALLEX humanoid manipulation tasks where prior VLAs reach only around 40%.
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[2]
A generalist agent.Transactions on Machine Learning Research (TMLR), 2022
Scott Reed, Konrad ˙Zołna, Emilio Parisotto, et al. A generalist agent.Transactions on Machine Learning Research (TMLR), 2022
2022
-
[3]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 10
work page internal anchor Pith review arXiv 2024
-
[4]
Rdt-1b: a diffusion foundation model for bimanual manipulation.International Conference on Learning Representations (ICLR), 2025
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.International Conference on Learning Representations (ICLR), 2025
2025
-
[5]
Scaling proprioceptive-visual learning with hetero- geneous pre-trained transformers
Lirui Wang, Xinlei Chen, Jialiang Zhao, and Kaiming He. Scaling proprioceptive-visual learning with hetero- geneous pre-trained transformers. InNeurips, 2024. 10
2024
-
[6]
TRI LBM Team, Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muham- mad Zubair Irshad, Masha Itkina, Naveen Kuppuswamy, Kuan-Hui Lee, Katherine Liu, Dale McConachie, Ian McMahon, Haruki Nishimura, Calder Phillips- Grafflin, Charles Richter, Paarth Shah, Krishnan Srini- vasan, Bla...
-
[7]
Rt-2: Vision-language- action models transfer web knowledge to robotic con- trol
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic con- trol. InConference on Robot Learning, pages 2165–
-
[8]
Open X-Embodiment Collaboration, Abhishek Padalkar, Acorn Pooley, Ajinkya Jain, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, Antonin Raffin, Ayzaan Wahid, Ben Burgess-Limerick, Beomjoon Kim, Bernhard Sch ¨olkopf, Brian Ichter, Cewu Lu, Charles Xu, Chelsea Finn, Chenfeng Xu, Cheng Chi, Chenguang Huang...
2023
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilin- sky.π 0: A vi...
work page internal anchor Pith review arXiv
-
[11]
Tinyvla: To- wards fast, data-efficient vision-language-action models for robotic manipulation, 2024
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, and Jian Tang. Tinyvla: Towards fast, data-efficient vision-language- action models for robotic manipulation.arXiv preprint arXiv:2409.12514, 2024
-
[12]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[14]
In9th Annual Conference on Robot Learning, 2025
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π 0.5: a vision-language-action model with open- world generalization. In9th Annual Conference on Robot Learning, 2025. 3, 4, 10
2025
-
[15]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Ji- ayin Zou, Yilun Chen, Jia Zeng, et al. X- vla: Soft-prompted transformer as scalable cross- embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Galaxea g0: Open-world dataset and dual-system vla model.arXiv preprint arXiv:2509.00576v1, 2025
Tao Jiang, Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Jianning Cui, Xiao Liu, Shuiqi Cheng, Jiyang Gao, Huazhe Xu, and Hang Zhao. Galaxea open-world dataset and g0 dual-system vla model.arXiv preprint arXiv:2509.00576, 2025
-
[17]
Vision- language foundation models as effective robot imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision- language foundation models as effective robot imitators. International Conference on Learning Representations (ICLR), 2024
2024
-
[18]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page Pith review arXiv 2024
-
[19]
Spatialvla: Explor- ing spatial representations for visual-language-action model.Robotics: Science and Systems (RSS), 2025
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Explor- ing spatial representations for visual-language-action model.Robotics: Science and Systems (RSS), 2025
2025
-
[20]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
-
[22]
AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, et al. Agibot world colosseo: A large- scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model, 2025
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, and Yi Xu. Chatvla: Unified multimodal understanding and robot control with vision-language-action model.arXiv preprint arXiv:2502.14420, 2025. 3
-
[24]
Cosmos policy: Fine-tuning video models for visuomotor control and planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. InInternational Conference on Learning Representations (ICLR), 2026. 3
2026
-
[25]
mimic- video: Video-action models for generalizable robot con- trol beyond vlas, 2025
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic- video: Video-action models for generalizable robot con- trol beyond vlas, 2025. URL https://arxiv.org/abs/2512. 15692. 3
2025
-
[26]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 3
work page internal anchor Pith review arXiv 2026
-
[27]
Unleashing large-scale video genera- tive pre-training for visual robot manipulation.Interna- tional Conference on Learning Representations (ICLR), 2024
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video genera- tive pre-training for visual robot manipulation.Interna- tional Conference on Learning Representations (ICLR), 2024
2024
-
[28]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, Hanbo Zhang, and Minzhao Zhu. Gr- 2: A generative video-language-action model with web- scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[29]
arXiv preprint arXiv:2412.10345 (2024)
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´e III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Vi- sual trace prompting enhances spatial-temporal aware- ness for generalist robotic policies.arXiv preprint arXiv:2412.10345, 2024. 3
-
[30]
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
-
[31]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xi- angyu Zhang, and Gao Huang. Memoryvla: Perceptual- cognitive memory in vision-language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
-
[32]
Onetwovla: A unified vision-language-action model with adaptive reasoning
Fanqi Lin, Ruiqian Nai, Yingdong Hu, Jiacheng You, Junming Zhao, and Yang Gao. Onetwovla: A unified vision-language-action model with adaptive reasoning. arXiv preprint arXiv:2505.11917, 2025
-
[33]
Haoquan Fang, Markus Grotz, Wilbert Pumacay, Yi Ru Wang, Dieter Fox, Ranjay Krishna, and Jiafei Duan. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564, 2025
-
[34]
Hao Li, Shuai Yang, Yilun Chen, Yang Tian, Xiaoda Yang, Xinyi Chen, Hanqing Wang, Tai Wang, Feng Zhao, Dahua Lin, et al. Cronusvla: Transferring la- tent motion across time for multi-frame prediction in manipulation.arXiv preprint arXiv:2506.19816, 2025
-
[35]
Ta-vla: Elucidating the design space of torque-aware vision-language-action models
Zongzheng Zhang, Haobo Xu, Zhuo Yang, Chenghao Yue, Zehao Lin, Huan-ang Gao, Ziwei Wang, and Hao Zhao. Ta-vla: Elucidating the design space of torque- aware vision-language-action models.arXiv preprint arXiv:2509.07962, 2025
-
[36]
Huiwon Jang, Sihyun Yu, Heeseung Kwon, Hojin Jeon, Younggyo Seo, and Jinwoo Shin. Contextvla: Vision- language-action model with amortized multi-frame con- text.arXiv preprint arXiv:2510.04246, 2025
-
[37]
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models. arXiv preprint arXiv:2603.03596, 2026. 3, 4, 6, 10, 22
-
[38]
Do as i can, not as i say: Grounding language in robotic affordances.Conference on Robot Learning (CoRL), 2022
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, et al. Do as i can, not as i say: Grounding language in robotic affordances.Conference on Robot Learning (CoRL), 2022. 3
2022
-
[39]
Code as policies: Language model programs for embod- ied control.IEEE International Conference on Robotics and Automation (ICRA), 2023
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embod- ied control.IEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[40]
arXiv preprint arXiv:2502.19417 , year=
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liy- iming Ke, Karl Pertsch, Quan Vuong, James Tanner, Anna Walling, Haohuan Wang, Niccolo Fusai, et al. Hi robot: Open-ended instruction following with hier- archical vision-language-action models.arXiv preprint arXiv:2502.19417, 2025. 3
-
[41]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.Computer Vision and Pattern Recognition (CVPR), 2025
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[42]
3, 8, 10
Physical Intelligence Team.π 0.6 model card, 2025. 3, 8, 10
2025
-
[43]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024. 3
work page Pith review arXiv 2024
-
[44]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone
Xiaopeng Lin, Shijie Lian, Bin Yu, Ruoqi Yang, Changti Wu, Yuzhuo Miao, Yurun Jin, Yukun Shi, Cong Huang, Bojun Cheng, and Kai Chen. Physbrain: Human ego- centric data as a bridge from vision language models to physical intelligence, 2025. URL https://arxiv.org/abs/ 2512.16793
-
[45]
Simar Kareer, Karl Pertsch, James Darpinian, Judy Hoffman, Danfei Xu, Sergey Levine, Chelsea Finn, and Suraj Nair. Emergence of human to robot trans- fer in vision-language-action models.arXiv preprint arXiv:2512.22414, 2025. 3
-
[46]
Zuolei Li, Xingyu Gao, Xiaofan Wang, and Jianlong Fu. Latbot: Distilling universal latent actions for vision- language-action models, 2025. URL https://arxiv.org/ abs/2511.23034
-
[47]
Egovla: Learning vision- language-action models from egocentric human videos,
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, Hongxu Yin, Sifei Liu, Song Han, Yao Lu, and Xiaolong Wang. Egovla: Learning vision- language-action models from egocentric human videos,
- [48]
-
[49]
Being-h0.5: Scaling human-centric robot learning for cross-embodiment generalization
Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Haiweng Xu, Haoqi Yuan, Chi Zhang, Yiqing Wang, Yicheng Feng, and Zongqing Lu. Being-h0.5: Scaling human-centric robot learning for cross-embodiment generalization, 2026. URL https:// arxiv.org/abs/2601.12993
-
[50]
Clap: Contrastive latent action pretraining for learn- ing vision-language-action models from human videos,
Chubin Zhang, Jianan Wang, Zifeng Gao, Yue Su, Tianru Dai, Cai Zhou, Jiwen Lu, and Yansong Tang. Clap: Contrastive latent action pretraining for learn- ing vision-language-action models from human videos,
- [51]
-
[52]
Physical Intelligence Team.π ⋆ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025. 3, 8, 9
work page Pith review arXiv 2025
-
[53]
Charles Xu, Qiyang Li, Jianlan Luo, and Sergey Levine. Rldg: Robotic generalist policy distillation via rein- forcement learning.arXiv preprint arXiv:2412.09858, 2024
-
[54]
Wenli Xiao, Haotian Lin, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi Fan, et al. Self-improving vision-language- action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025. 3
-
[55]
R3m: A universal visual representation for robot manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation. InConfer- ence on Robot Learning, pages 892–909. PMLR, 2023. 3
2023
-
[56]
Vip: Towards universal visual reward and representation via value-implicit pre-training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. InThe Eleventh Interna- tional Conference on Learning Representations, 2022
2022
-
[57]
Masked visual pre-training for motor control
Tete Xiao, Ilija Radosavovic, Trevor Darrell, and Jiten- dra Malik. Masked visual pre-training for motor control. arXiv preprint arXiv:2203.06173, 2022
-
[58]
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
Chethan Bhateja, Derek Guo, Dibya Ghosh, Anikait Singh, Manan Tomar, Quan Vuong, Yevgen Chebotar, Sergey Levine, and Aviral Kumar. Robotic offline rl from internet videos via value-function pre-training. arXiv preprint arXiv:2309.13041, 2023
-
[59]
Manipulator-independent representations for vi- sual imitation.arXiv preprint arXiv:2103.09016, 2021
Yuxiang Zhou, Yusuf Aytar, and Konstantinos Bous- malis. Manipulator-independent representations for vi- sual imitation.arXiv preprint arXiv:2103.09016, 2021
-
[60]
Visual affordance prediction for guiding robot exploration.arXiv preprint arXiv:2305.17783, 2023
Homanga Bharadhwaj, Abhinav Gupta, and Shubham Tulsiani. Visual affordance prediction for guiding robot exploration.arXiv preprint arXiv:2305.17783, 2023. 3
-
[61]
Hongyi Chen, Tony Dong, Tiancheng Wu, Liquan Wang, Yash Jangir, Yaru Niu, Yufei Ye, Homanga Bharadhwaj, Zackory Erickson, and Jeffrey Ichnowski. Dexterous manipulation policies from rgb human videos via 3d hand-object trajectory reconstruction.arXiv preprint arXiv:2602.09013, 2026. 3
-
[62]
Videodex: Learning dexterity from internet videos
Kenneth Shaw, Shikhar Bahl, and Deepak Pathak. Videodex: Learning dexterity from internet videos. In Conference on Robot Learning, pages 654–665. PMLR, 2023
2023
-
[63]
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tul- siani, and Vikash Kumar. Zero-shot robot manipu- lation from passive human videos.arXiv preprint arXiv:2302.02011, 2023
-
[64]
Human-to-robot imitation in the wild
Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. Human-to-robot imitation in the wild.arXiv preprint arXiv:2207.09450, 2022
-
[65]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. InCVPR, 2023
2023
-
[66]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 13226– 13233. IEEE, 2025
2025
-
[67]
Learning adaptive dexterous grasping from single demonstrations
Liangzhi Shi, Yulin Liu, Lingqi Zeng, Bo Ai, Zheng- dong Hong, and Hao Su. Learning adaptive dexterous grasping from single demonstrations. In2025 IEEE/RSJ International Conference on Intelligent Robots and Sys- tems (IROS), pages 9456–9463. IEEE, 2025. 3
2025
-
[68]
Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Com- puter Vision, pages 306–324. Springer, 2024. 3
2024
-
[69]
Robotap: Tracking arbitrary points for few-shot visual imitation
Mel Vecerik, Carl Doersch, Yi Yang, Todor Davchev, Yusuf Aytar, Guangyao Zhou, Raia Hadsell, Lourdes Agapito, and Jon Scholz. Robotap: Tracking arbitrary points for few-shot visual imitation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5397–5403. IEEE, 2024
2024
-
[70]
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajec- tory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
-
[71]
Rt-trajectory: Robotic task generalization via hindsight trajectory sketches.International Conference on Learning Representations (ICLR), 2024
Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, et al. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches.International Conference on Learning Representations (ICLR), 2024. 3
2024
-
[72]
Dall-e-bot: Introducing web-scale diffusion models to robotics.IEEE Robotics and Automation Letters, 8(7): 3956–3963, 2023
Ivan Kapelyukh, Vitalis V osylius, and Edward Johns. Dall-e-bot: Introducing web-scale diffusion models to robotics.IEEE Robotics and Automation Letters, 8(7): 3956–3963, 2023. 3
2023
-
[73]
Cacti: A framework for scalable multi-task multi-scene visual imitation learning,
Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, and Vikash Ku- mar. Cacti: A framework for scalable multi-task multi-scene visual imitation learning.arXiv preprint arXiv:2212.05711, 2022
-
[74]
Genaug: Retargeting behaviors to unseen situ- ations via generative augmentation, 2023
Zoey Chen, Sho Kiami, Abhishek Gupta, and Vikash Kumar. Genaug: Retargeting behaviors to unseen sit- uations via generative augmentation.arXiv preprint arXiv:2302.06671, 2023
-
[75]
Scaling robot learning with semantically imagined experience.arXiv preprint arXiv:2302.11550, 2023
Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Jodilyn Peralta, Brian Ichter, et al. Scaling robot learning with semantically imagined experience.arXiv preprint arXiv:2302.11550, 2023
- [76]
-
[77]
Sajjadi, et al
Danny Driess, Fei Xia, Mehdi S.M. Sajjadi, et al. Palm- e: An embodied multimodal language model.Interna- tional Conference on Machine Learning (ICML), 2023
2023
-
[78]
Vima: General robot manipulation with multimodal prompts.Interna- tional Conference on Machine Learning (ICML), 2023
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts.Interna- tional Conference on Machine Learning (ICML), 2023. 3
2023
-
[79]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
OX-Embodiment Collaboration, A Padalkar, A Pooley, A Jain, A Bewley, A Herzog, A Irpan, A Khazatsky, A Rai, A Singh, et al. Open X-Embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 1(2), 2023. 3
work page internal anchor Pith review arXiv 2023
-
[80]
Data analogies enable efficient cross-embodiment transfer
Jonathan Yang, Chelsea Finn, and Dorsa Sadigh. Data analogies enable efficient cross-embodiment transfer. arXiv preprint arXiv:2603.06450, 2026. 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.