Recognition: no theorem link
Spectral Transformer Neural Processes
Pith reviewed 2026-05-12 03:59 UTC · model grok-4.3
The pith
Spectral Transformer Neural Processes capture periodicity by injecting spectral mixture features into transformer embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STNPs extend TNPs by adding a Spectral Aggregator that estimates an empirical context spectrum, compresses it into a spectral mixture, samples task-adaptive spectral features, and concatenates them with time-domain embeddings. This injects a spectral-mixture-kernel bias that reshapes the similarity geometry, allowing inputs distant in Euclidean space to be close in a periodic manifold and enhancing time-frequency interactions.
What carries the argument
Spectral Aggregator that estimates context spectrum, compresses to mixture, samples features and concatenates to time embeddings to reshape similarity for periodicity.
Load-bearing premise
That the concatenation of sampled spectral features reliably captures periodicity and quasi-periodicity without new overfitting or heavy tuning requirements.
What would settle it
Running STNP and TNP on the same periodic time series test set and finding no statistically significant improvement in log likelihood or error metrics for STNP.
Figures




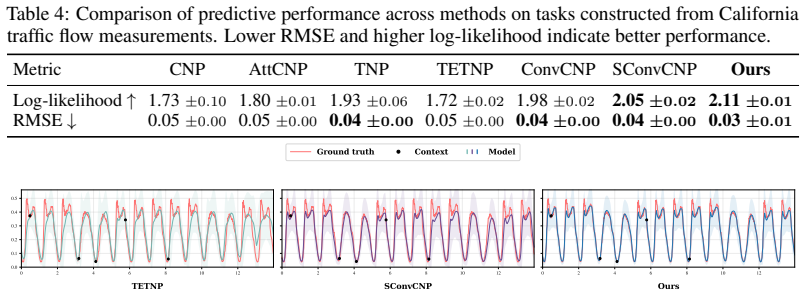


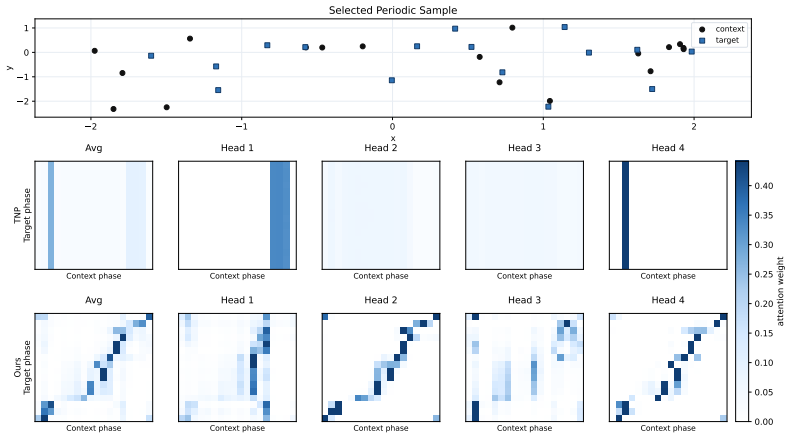
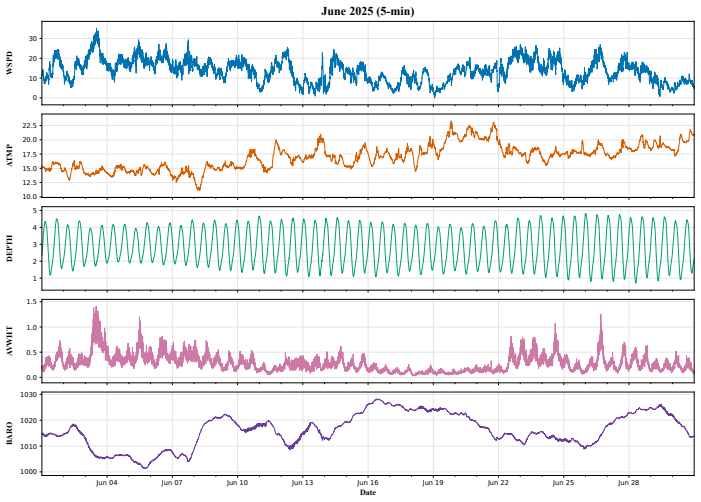

read the original abstract
Time series, spatial data, and images are natural applications of Neural Processes. However, when such data exhibit strong periodicity and quasi-periodicity, existing methods often suffer from underfitting and generalise poorly beyond the training distribution. In this work, we propose Spectral Transformer Neural Processes (STNPs), a frequency-aware extension of Transformer Neural Processes (TNPs). STNPs introduce a Spectral Aggregator that estimates an empirical context spectrum, compresses it into a spectral mixture, samples task-adaptive spectral features, and concatenates them with time-domain embeddings, thereby injecting a spectral-mixture-kernel bias into TNPs. This design reshapes the similarity geometry, allowing inputs that are distant in Euclidean space to remain close in an induced periodic manifold while enhancing time-frequency interactions. Extensive experiments on synthetic regression tasks, real-world time-series datasets, and an image dataset demonstrate that STNPs consistently improve predictive performance over existing baselines, extending Neural Processes beyond translation equivariance towards effective modelling of periodicity and quasi-periodicity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spectral Transformer Neural Processes (STNPs) as a frequency-aware extension of Transformer Neural Processes. A Spectral Aggregator estimates an empirical context spectrum, compresses it into a spectral mixture, samples task-adaptive spectral features, and concatenates them with time-domain embeddings to inject a spectral-mixture-kernel bias. This is intended to reshape similarity geometry so that Euclidean-distant inputs remain close on a periodic manifold, improving modeling of periodicity and quasi-periodicity. Experiments on synthetic regression, real-world time-series, and image tasks are reported to show consistent predictive gains over baselines.
Significance. If the gains are robust, the work would usefully extend Neural Processes beyond translation equivariance to periodic data, with applications in time-series and spatial modeling. The multi-domain evaluation (synthetic, time-series, images) and explicit focus on a known failure mode of existing NPs are strengths that could make the contribution substantive if the mechanism is shown to be reliable.
major comments (2)
- [§3] §3 (Spectral Aggregator): The compression of the empirical context spectrum into a spectral mixture and the subsequent sampling of task-adaptive features are described at a high level only. No equations specify the compression objective, choice of mixture components, or handling of phase/multi-frequency information. This is load-bearing for the central claim, as the skeptic concern correctly identifies that high-variance or biased spectrum estimates from small context sets could prevent the intended periodic manifold from forming.
- [§4] §4 (Experiments): Reported improvements lack error bars across runs, statistical significance tests, and ablations isolating the spectral-mixture concatenation from other architectural choices or hyperparameter effects. Without these, it is impossible to confirm that performance gains arise from the claimed reshaping of similarity geometry rather than post-hoc tuning or dataset selection.
minor comments (2)
- [Abstract] Abstract: The phrase 'consistently improve predictive performance' would be strengthened by including at least one quantitative example (e.g., average RMSE reduction) rather than remaining purely qualitative.
- Notation: The interaction between the sampled spectral features and the Transformer attention layers should be formalized with an explicit equation showing how the concatenated embeddings modify the similarity kernel.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the recognition of the potential contribution in extending Neural Processes to handle periodicity. We address each major comment below and commit to revising the manuscript to incorporate the suggested improvements, including additional mathematical details and enhanced experimental analysis.
read point-by-point responses
-
Referee: [§3] §3 (Spectral Aggregator): The compression of the empirical context spectrum into a spectral mixture and the subsequent sampling of task-adaptive features are described at a high level only. No equations specify the compression objective, choice of mixture components, or handling of phase/multi-frequency information. This is load-bearing for the central claim, as the skeptic concern correctly identifies that high-variance or biased spectrum estimates from small context sets could prevent the intended periodic manifold from forming.
Authors: We agree with the referee that the description of the Spectral Aggregator in §3 is at a high level. In the revised manuscript, we will expand this section with detailed equations specifying the compression objective for the empirical context spectrum into a spectral mixture, the choice and fitting of mixture components, and the handling of phase and multi-frequency information through the sampling of task-adaptive spectral features. We will also include additional analysis addressing the potential issues with high-variance or biased spectrum estimates from small context sets, such as empirical evaluations on varying context sizes to demonstrate the robustness of the periodic manifold formation. revision: yes
-
Referee: [§4] §4 (Experiments): Reported improvements lack error bars across runs, statistical significance tests, and ablations isolating the spectral-mixture concatenation from other architectural choices or hyperparameter effects. Without these, it is impossible to confirm that performance gains arise from the claimed reshaping of similarity geometry rather than post-hoc tuning or dataset selection.
Authors: We acknowledge the importance of rigorous statistical validation in the experiments. In the revised version, we will include error bars (standard deviations across multiple random seeds/runs), perform statistical significance tests (e.g., paired t-tests or Wilcoxon tests) to compare STNPs against baselines, and add ablation studies that isolate the effect of the spectral-mixture concatenation by comparing variants with and without it, while controlling for other hyperparameters. These additions will help confirm that the gains stem from the proposed mechanism. revision: yes
Circularity Check
No significant circularity; architectural extension validated empirically
full rationale
The paper proposes STNPs as a frequency-aware extension of TNPs via a new Spectral Aggregator module that estimates an empirical context spectrum, compresses it, samples features, and concatenates them with time-domain embeddings. This is an explicit architectural design choice whose claimed benefits (improved modeling of periodicity) are demonstrated through experiments on synthetic, time-series, and image data rather than derived from prior equations. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the central claim remains independent of its inputs and is tested against external baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- spectral mixture components
axioms (1)
- domain assumption Transformer attention can effectively integrate concatenated time-domain and spectral features
invented entities (1)
-
Spectral Aggregator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aky¨urek, E., Schuurmans, D., Andreas, J., Ma, T., and Zhou, D
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning.ArXiv, abs/2306.00297,
-
[2]
URLhttps://api.semanticscholar.org/CorpusID:258999480
-
[3]
What learning algorithm is in-context learning? investigations with linear models, 2023
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models.ArXiv, abs/2211.15661,
-
[4]
URLhttps://api.semanticscholar.org/CorpusID:254043800
-
[5]
Matthew Ashman, Cristiana-Diana Diaconu, Junhyuck Kim, Lakee Sivaraya, Stratis Markou, James Requeima, Wessel P. Bruinsma, and Richard E. Turner. Translation equivari- ant transformer neural processes.ArXiv, abs/2406.12409, 2024. URL https://api. semanticscholar.org/CorpusID:270562561
-
[6]
Matthew Ashman, Cristiana-Diana Diaconu, Eric Langezaal, Adrian Weller, and Richard E. Turner. Gridded transformer neural processes for spatio-temporal data. InInternational Confer- ence on Machine Learning, 2025. URL https://api.semanticscholar.org/CorpusID: 283567166
work page 2025
-
[7]
Yu Bai, Fan Chen, Haiquan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection.ArXiv, abs/2306.04637, 2023. URLhttps://api.semanticscholar.org/CorpusID:259095794
-
[8]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Ma teusz L...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[9]
Bruinsma, James Requeima, Andrew Y
Wessel P. Bruinsma, James Requeima, Andrew Y . K. Foong, Jonathan Gordon, and Richard E. Turner. The gaussian neural process.ArXiv, abs/2101.03606, 2021. URL https://api. semanticscholar.org/CorpusID:228102666
-
[10]
Xiang Cheng, Yuxin Chen, and Suvrit Sra. Transformers implement functional gradient descent to learn non-linear functions in context.ArXiv, abs/2312.06528, 2023. URL https: //api.semanticscholar.org/CorpusID:266162320
-
[11]
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild.2014 IEEE Conference on Computer Vision and Pattern Recog- nition, pages 3606–3613, 2013. URL https://api.semanticscholar.org/CorpusID: 4309276
work page 2014
-
[12]
J. L. B. Cooper and Salomon Bochner. Harmonic analysis and the theory of probability.The Mathematical Gazette, 41:154 – 155, 1957. URL https://api.semanticscholar.org/ CorpusID:121662867
work page 1957
-
[13]
Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers
-
[14]
URLhttps://api.semanticscholar.org/CorpusID:258686544
-
[15]
Fan: Fourier analysis networks.ArXiv, abs/2410.02675, 2024
Yihong Dong, Ge Li, Yongding Tao, Xue Jiang, Kechi Zhang, Jia Li, Jing Su, Jun Zhang, and Jingjing Xu. Fan: Fourier analysis networks.ArXiv, abs/2410.02675, 2024. URL https://api.semanticscholar.org/CorpusID:273098297
-
[16]
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes.ArXiv, abs/2208.01066, 2022. URL https://api.semanticscholar.org/CorpusID:251253368. 10
-
[17]
Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo Jimenez Rezende, and S
Marta Garnelo, Dan Rosenbaum, Chris J. Maddison, Tiago Ramalho, David Saxton, Murray Shanahan, Yee Whye Teh, Danilo Jimenez Rezende, and S. M. Ali Eslami. Conditional neural processes.ArXiv, abs/1807.01613, 2018. URL https://api.semanticscholar. org/CorpusID:49574993
- [18]
-
[19]
Jonathan Gordon, Wessel P. Bruinsma, Andrew Y . K. Foong, James Requeima, Yann Dubois, and Richard E. Turner. Convolutional conditional neural processes.ArXiv, abs/1910.13556,
-
[20]
URLhttps://api.semanticscholar.org/CorpusID:204960684
-
[21]
Scalable Spatiotemporal Inference with Biased Scan Attention Transformer Neural Processes
Daniel Jenson, Jhonathan Navott, Piotr Grynfelder, Mengyan Zhang, Makkunda Sharma, Elizaveta Semenova, and Seth Flaxman. Scalable spatiotemporal inference with biased scan attention transformer neural processes.ArXiv, abs/2506.09163, 2025. URL https://api. semanticscholar.org/CorpusID:279306065
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
URLhttps://api.semanticscholar.org/CorpusID:58014184
-
[24]
Reformer: The Efficient Transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. ArXiv, abs/2001.04451, 2020. URL https://api.semanticscholar.org/CorpusID: 209315300
work page internal anchor Pith review arXiv 2001
-
[25]
Guokun Lai, Wei-Cheng Chang, Yiming Yang, and Hanxiao Liu. Modeling long- and short-term temporal patterns with deep neural networks.The 41st International ACM SI- GIR Conference on Research & Development in Information Retrieval, 2017. URL https: //api.semanticscholar.org/CorpusID:4922476
work page 2017
-
[26]
Bootstrapping neural processes.ArXiv, abs/2008.02956, 2020
Juho Lee, Yoonho Lee, Jungtaek Kim, Eunho Yang, Sung Ju Hwang, and Yee Whye Teh. Bootstrapping neural processes.ArXiv, abs/2008.02956, 2020. URL https://api. semanticscholar.org/CorpusID:221083236
-
[27]
SHIYANG LI, Xiaoyong Jin, Yao Xuan, Xiyou Zhou, Wenhu Chen, Yu-Xiang Wang, and Xifeng Yan. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting.ArXiv, abs/1907.00235, 2019. URL https://api.semanticscholar. org/CorpusID:195766887
-
[28]
Largest: A benchmark dataset for large-scale traffic forecasting
Xu Liu, Yutong Xia, Yuxuan Liang, Junfeng Hu, Yiwei Wang, Lei Bai, Chaoqin Huang, Zhen- guang Liu, Bryan Hooi, and Roger Zimmermann. Largest: A benchmark dataset for large-scale traffic forecasting.ArXiv, abs/2306.08259, 2023. URL https://api.semanticscholar. org/CorpusID:259165246
-
[29]
Spectral convolutional conditional neural processes
Peiman Mohseni and Nick Duffield. Spectral convolutional conditional neural processes. ArXiv, abs/2404.13182, 2024. URL https://api.semanticscholar.org/CorpusID: 269292913
-
[30]
Neural processes for short-term forecasting of weather attributes
Benedetta L Mussati, Helen McKay, and Stephen Roberts. Neural processes for short-term forecasting of weather attributes
-
[31]
On estimating regression.Theory of Probability & Its Applications, 9(1): 141–142, 1964
Elizbar A Nadaraya. On estimating regression.Theory of Probability & Its Applications, 9(1): 141–142, 1964
work page 1964
-
[32]
Tung Nguyen and Aditya Grover. Transformer neural processes: Uncertainty-aware meta learning via sequence modeling.ArXiv, abs/2207.04179, 2022. URL https://api. semanticscholar.org/CorpusID:250340974
-
[33]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in Neural Information Processing Systems, 2007. 11
work page 2007
-
[34]
Gautam Singh, Jaesik Yoon, Youngsung Son, and Sungjin Ahn. Sequential neural processes. In Neural Information Processing Systems, 2019. URL https://api.semanticscholar.org/ CorpusID:195584118
work page 2019
-
[35]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeural Information Processing Systems, 2017. URLhttps://api.semanticscholar.org/CorpusID:13756489
work page 2017
-
[36]
Distance-informed neural processes
Aishwarya Venkataramanan and Joachim Denzler. Distance-informed neural processes. ArXiv, abs/2508.18903, 2025. URL https://api.semanticscholar.org/CorpusID: 280870623
-
[37]
Randazzo, João Sacramento, Alexander Mord- vintsev, Andrey Zhmoginov, and Max Vladymyrov
Johannes von Oswald, Eyvind Niklasson, E. Randazzo, João Sacramento, Alexander Mord- vintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gra- dient descent. InInternational Conference on Machine Learning, 2022. URL https: //api.semanticscholar.org/CorpusID:254685643
work page 2022
- [38]
-
[39]
URLhttps://api.semanticscholar.org/CorpusID:270063827
-
[40]
Andrew Gordon Wilson and Ryan P. Adams. Gaussian process kernels for pattern discovery and extrapolation. InInternational Conference on Machine Learning, 2013. URL https: //api.semanticscholar.org/CorpusID:279814
work page 2013
-
[41]
Autoformer: Decomposition trans- formers with auto-correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition trans- formers with auto-correlation for long-term series forecasting. InNeural Information Processing Systems, 2021. URLhttps://api.semanticscholar.org/CorpusID:235623791
work page 2021
- [42]
-
[43]
Multi- resolution time-series transformer for long-term forecasting
Yitian Zhang, Liheng Ma, Soumyasundar Pal, Yingxue Zhang, and Mark Coates. Multi- resolution time-series transformer for long-term forecasting. InInternational Conference on Artificial Intelligence and Statistics, 2023. URL https://api.semanticscholar.org/ CorpusID:265043382
work page 2023
-
[44]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wan Zhang. Informer: Beyond efficient transformer for long sequence time-series forecast- ing.ArXiv, abs/2012.07436, 2020. URL https://api.semanticscholar.org/CorpusID: 229156802
-
[45]
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. InInterna- tional Conference on Machine Learning, 2022. URL https://api.semanticscholar.org/ CorpusID:246430171. 12 Table 7: Key symbols used in the main text and appendix. Symbol Meaning X,YInput an...
work page 2022
-
[46]
Synthetic regression and California traffic flow.These are scalar-input, scalar-output settings withd x =d y = 1andP={1}
-
[47]
DTD image completion.The spectral branch uses the full two-dimensional pixel coordinate, P={1,2}, and the shared selected-channel spectrum with all RGB channels,A={1,2,3}
-
[48]
For multivariate datasets, the spectral summary uses the shared all-channel aggregation, A={1,
Six-dataset forecasting benchmark.The spectral branch is applied to the temporal coordinate, so P={1} . For multivariate datasets, the spectral summary uses the shared all-channel aggregation, A={1, . . . , d y}
-
[49]
Chimet.The input side also uses the temporal coordinate, so P={1} . The prediction head outputs all five variables {WSPD,ATMP,DEPTH,AVWHT,BARO} , but the spectral branch uses channel-wise selected spectra withA={ATMP,DEPTH} . Specifically, one scalar spectral branch is built from ATMP and one from DEPTH, using the period ranges reported in Table 18; their...
-
[50]
(a) Irregular spectral energy estimation.Let K be the number of grid frequencies and let P ⊆ {1,
Context-side spectral parameter estimation.This stage operates only on the context set and consists of three operations. (a) Irregular spectral energy estimation.Let K be the number of grid frequencies and let P ⊆ {1, . . . , dx} be the input-coordinate subset used by the spectral branch, with dp =|P| . For each of the M context points and each of theK ve...
-
[51]
This stage consists of two parts
Token-wise embedding construction.Once the spectral parameters are estimated from the context set, they are used to construct token embeddings for all N tokens. This stage consists of two parts. (a) Spectral features.For each of the Q mixture components, the model samples D0 vector frequencies in Rdp. Sampling with a full covariance requires O(Qd3 p) oper...
-
[52]
Total embedding complexity.By combining the context-side estimation and the token-wise embedding construction, we obtain T SMK embed(N, M) =O M K(dp +α) +K κCinC+ (L c −2)κC 2 +CQ +QKd 2 p +Qd 3 p +QD 0d2 p +N QD 0dp +N . For channel-wise selected spectra, such as the Chimet configuration, the same expression is applied independently to each selected chan...
-
[53]
Overall complexity.Substituting this into the backbone-plus-embedding decomposition yields Tours(N, M)∈ O N2 +M K(d p +α) +K κCinC+ (L c −2)κC 2 +CQ +QKd 2 p +Qd 3 p +QD 0d2 p +N QD 0dp +N . 19 When K, Q, D0, dp, α, κ, C, and Lc (or the corresponding channel-wise sets {Kc, Qc, D0,c}c∈A) are treated as fixed hyperparameters, all terms except those dependin...
work page 2020
-
[54]
(2) Electricity4 contains the hourly electricity consumption of 321 clients from 2012 to
work page 2012
-
[55]
(3) Exchange Rate [20] records the daily exchange rates of eight countries ranging from 1990 to 2016. (4) Traffic5 is a collection of hourly road occupancy measurements from the California Department of Transportation, capturing sensor readings on San Francisco Bay Area freeways. (5) Weather6 is recorded every 10 minutes over the year 2020 and contains 21...
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.