Recognition: 1 theorem link
· Lean TheoremTIDE-Bench: Task-Aware and Diagnostic Evaluation of Tool-Integrated Reasoning
Pith reviewed 2026-05-12 02:40 UTC · model grok-4.3
The pith
TIDE-Bench reveals tool grounding as the main persistent bottleneck in tool-integrated reasoning methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TIDE-Bench supplies diverse task settings that merge mathematical reasoning and knowledge QA with new tool-grounded experimental design and dynamic interactive tasks. It applies a comprehensive task-aware protocol that jointly tracks final answer quality, process reliability, tool-use efficiency, and inference cost. High-quality sets are built by filtering low-discrimination instances from existing datasets, which cuts evaluation cost while concentrating on harder samples. Tests on multiple foundation models and TIR methods identify persistent bottlenecks in tool grounding.
What carries the argument
TIDE-Bench, the benchmark that pairs expanded TIR task types with a multi-dimensional task-aware scoring protocol and discrimination-filtered datasets to isolate tool-use weaknesses.
If this is right
- TIR research must prioritize improvements in tool selection and invocation to raise overall performance.
- Evaluations should routinely include interactive and multi-tool coordination scenarios to capture real usage demands.
- Filtered evaluation sets can lower compute costs while preserving or sharpening the ability to distinguish methods.
- Diagnostic results from such benchmarks can direct targeted fixes rather than broad scaling efforts.
Where Pith is reading between the lines
- The same filtering technique could sharpen other AI reasoning benchmarks by removing cases that do not separate systems.
- Persistent grounding failures may reflect missing pretraining signals on tool interfaces more than deficits in general reasoning.
- Applying the benchmark to additional tool environments such as code interpreters or external APIs would test whether the observed limits are general.
Load-bearing premise
Filtering low-discrimination instances from existing datasets produces more challenging and diagnostically useful sets without introducing selection bias or dropping information essential for judging tool-use ability.
What would settle it
Re-running the full original unfiltered datasets and finding that tool-grounding bottlenecks no longer appear as the dominant failure mode or that method rankings shift substantially.
Figures




read the original abstract
Tool-integrated reasoning has emerged as a promising paradigm for enhancing large language models with external computation, retrieval, and execution capabilities. However, the field still lacks a high-quality and unified evaluation benchmark, and existing TIR evaluations remain limited in dataset quality, task diversity, diagnostic comprehensiveness, and evaluation efficiency. In this work, we introduce TIDE-Bench, a holistic and efficient benchmark for evaluating TIR methods, featuring three key advantages. First, it provides diverse task settings, combining widely used mathematical reasoning and knowledge-intensive QA tasks with two newly designed tasks, namely the tool-grounded experimental design task and the dynamic interactive task, to probe models' abilities in complex tool invocation and multi-tool coordination. Second, TIDE-Bench adopts a comprehensive yet task-aware evaluation protocol, jointly measuring final answer quality, process reliability, tool-use efficiency, and inference cost across heterogeneous task settings. Third, TIDE-Bench constructs high-quality and discriminative evaluation sets by filtering low-discrimination instances from existing datasets, substantially reducing evaluation cost while focusing on more challenging samples. Extensive experiments on multiple foundation models and TIR methods reveal persistent bottlenecks in tool grounding, offering insights for future TIR research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TIDE-Bench, a benchmark for tool-integrated reasoning (TIR) that augments standard mathematical reasoning and knowledge-intensive QA tasks with two newly designed tasks (tool-grounded experimental design and dynamic interactive) to test complex tool invocation and multi-tool coordination. It proposes a task-aware evaluation protocol that jointly assesses final answer quality, process reliability, tool-use efficiency, and inference cost, and constructs high-quality discriminative test sets by filtering low-discrimination instances from existing datasets to reduce evaluation cost. Experiments across multiple foundation models and TIR methods identify persistent bottlenecks in tool grounding.
Significance. If the benchmark construction and filtering are validated, TIDE-Bench would supply the TIR field with a more diverse, diagnostically comprehensive, and computationally efficient evaluation framework than prior ad-hoc setups. The new task categories directly target under-explored capabilities, and the multi-metric protocol could yield actionable insights into specific failure modes such as tool grounding. The efficiency gain from focused test sets is a practical strength if selection bias is demonstrably avoided.
major comments (1)
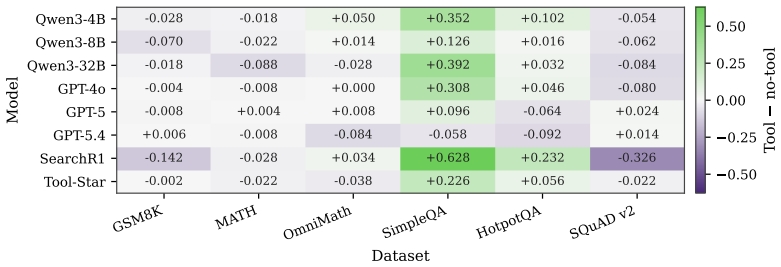
- [§4.2] §4.2 (evaluation set construction): the central claim that filtering low-discrimination instances yields 'high-quality and discriminative evaluation sets' while preserving diagnostic value is load-bearing for the reported 'persistent bottlenecks in tool grounding,' yet the manuscript supplies no explicit definition of the discrimination criterion, no quantitative ablation or distributional comparison of retained versus discarded instances (e.g., multi-tool coordination complexity or edge-case grounding), and no verification that coverage of the two new tasks remains balanced post-filtering. This directly engages the stress-test concern and requires concrete evidence before the diagnostic conclusions can be accepted.
minor comments (2)
- [Abstract] Abstract: the summary of experimental findings is entirely qualitative; adding one or two headline numbers (e.g., number of models evaluated, average performance gap on tool-grounding metrics) would improve immediate readability without lengthening the paragraph.
- [Evaluation protocol] Evaluation protocol section: the precise operationalization of 'process reliability' and 'tool-use efficiency' (e.g., exact formulas or rubrics) should be stated explicitly, ideally with a small illustrative example, to allow replication.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address the major comment point by point below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§4.2] §4.2 (evaluation set construction): the central claim that filtering low-discrimination instances yields 'high-quality and discriminative evaluation sets' while preserving diagnostic value is load-bearing for the reported 'persistent bottlenecks in tool grounding,' yet the manuscript supplies no explicit definition of the discrimination criterion, no quantitative ablation or distributional comparison of retained versus discarded instances (e.g., multi-tool coordination complexity or edge-case grounding), and no verification that coverage of the two new tasks remains balanced post-filtering. This directly engages the stress-test concern and requires concrete evidence before the diagnostic conclusions can be accepted.
Authors: We appreciate the referee's emphasis on rigorously validating the filtering procedure, as it is indeed central to our claims. Upon review, we agree that the manuscript would benefit from more explicit details on the discrimination criterion and supporting analyses. In the revised manuscript, we will: (1) provide a formal definition of the discrimination criterion, including the formula or method used to identify low-discrimination instances; (2) include quantitative ablations and distributional comparisons between retained and discarded instances, covering aspects such as multi-tool coordination complexity, edge-case grounding requirements, and other relevant metrics; (3) verify and report that the coverage of the two newly designed tasks remains balanced after filtering. These additions will substantiate the preservation of diagnostic value and support our findings on persistent bottlenecks in tool grounding. We believe this revision will fully address the concern. revision: yes
Circularity Check
No circularity: benchmark construction with independent task and metric design
full rationale
The paper constructs TIDE-Bench by defining new tasks (tool-grounded experimental design and dynamic interactive), adopting a multi-aspect evaluation protocol, and applying a filtering procedure to existing datasets. No equations, predictions, or fitted parameters appear in the abstract or described contributions. The filtering of low-discrimination instances is presented as a methodological choice for efficiency and focus, not as a derivation that reduces to its own inputs or relies on self-citation for uniqueness. The work contains no self-definitional loops, fitted-input predictions, or ansatz smuggling; its claims rest on the explicit construction of new evaluation artifacts rather than any chain that equates outputs to prior fitted values by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing TIR datasets contain low-discrimination instances that can be safely filtered to create more efficient and focused evaluation sets
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2508.19201 , year=
Understanding tool-integrated reasoning , author=. arXiv preprint arXiv:2508.19201 , year=
-
[3]
Advances in Neural Information Processing Systems , year=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , year=
-
[4]
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
work page 2023
-
[5]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning , author=. arXiv preprint arXiv:2505.16410 , year=
-
[6]
T-eval: Evaluating the tool utilization capability of large language models step by step , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Acting less is reasoning more! teaching model to act efficiently, 2025
Acting less is reasoning more! teaching model to act efficiently , author=. arXiv preprint arXiv:2504.14870 , year=
-
[10]
Autotir: Autonomous tools integrated reasoning via reinforcement learning , author=. arXiv preprint arXiv:2507.21836 , year=
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
ToolRL: Reward is All Tool Learning Needs
Toolrl: Reward is all tool learning needs , author=. arXiv preprint arXiv:2504.13958 , year=
work page internal anchor Pith review arXiv
-
[13]
Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning , author=. arXiv preprint arXiv:2509.02479 , year=
-
[14]
Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
Advances in Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , year=
-
[16]
Tool learning with foundation models
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and others , year=. 2304.08354 , archivePrefix=
-
[17]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs
Li, Minghao and Yang, Fei and Yang, Bin and Wang, Shang and Wang, Ying and Luo, Song and Li, Ze and Chen, Ying and Xu, Wanxiang and Liu, Dayiheng , year=. 2304.08244 , archivePrefix=
work page internal anchor Pith review arXiv
-
[18]
International Conference on Learning Representations , year=
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use , author=. International Conference on Learning Representations , year=
-
[19]
Ning, K., Su, Y ., Lv, X., Zhang, Y ., Liu, J., Liu, K., and Xu, J
Ning, Kangyun and Su, Yisong and Lv, Xueqiang and Zhang, Yuanzhe and Liu, Jian and Liu, Kang and Xu, Jinan , year=. 2407.12823 , archivePrefix=
-
[20]
AgentBench: Evaluating LLMs as Agents
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangli and Men, Kaiwen and Yang, Keqin and others , year=. 2308.03688 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle=. Measuring Mathematical Problem Solving With the
-
[24]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Benson, Emily and Huang, William and Yin, Wentau and Smola, Alex and Chen, Christopher , booktitle=
-
[25]
Know What You Don't Know: Unanswerable Questions for
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , booktitle=. Know What You Don't Know: Unanswerable Questions for
-
[26]
Measuring Short-Form Factuality in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[27]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Gao, Bofei and Song, Feifan and Yang, Zhe and Cai, Zeyu and Zhang, Yibo and Liang, Yutong and Ma, Tiyu and Mi, Jiaqi and Li, Lijun and others , year=. 2410.07985 , archivePrefix=
work page internal anchor Pith review arXiv
-
[28]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zhuohan and Li, Zi and Li, Dacheng and Xing, Eric P. and others , booktitle=. Judging
-
[29]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu, Chris and Lu, Cong and Lange, Robert T. and Foerster, Jakob and Clune, Jeff and Ha, David , year=. The. 2408.06292 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
- [30]
-
[31]
arXiv preprint arXiv:2505.11833 , year=
ToLeaP: Rethinking Development of Tool Learning with Large Language Models , author=. arXiv preprint arXiv:2505.11833 , year=
-
[32]
Criticsearch: Fine-grained credit assignment for search agents via a retrospective critic , author=. arXiv preprint arXiv:2511.12159 , year=
-
[33]
Function Calling in Large Language Models: Industrial Practices, Challenges, and Future Directions , author=. ACM Computing Surveys , year=
-
[34]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Minicpm4: Ultra-efficient llms on end devices
Minicpm4: Ultra-efficient llms on end devices , author=. arXiv preprint arXiv:2506.07900 , year=
-
[36]
arXiv preprint arXiv:2602.06485 , year=
AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents , author=. arXiv preprint arXiv:2602.06485 , year=
-
[37]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Flashrag: A modular toolkit for efficient retrieval-augmented generation research , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
work page 2025
-
[38]
arXiv preprint arXiv:2509.23285 , year=
Toward Effective Tool-Integrated Reasoning via Self-Evolved Preference Learning , author=. arXiv preprint arXiv:2509.23285 , year=
-
[39]
arXiv preprint arXiv:2508.15754 , year=
Dissecting Tool-Integrated Reasoning: An Empirical Study and Analysis , author=. arXiv preprint arXiv:2508.15754 , year=
-
[40]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Mind2web: Towards a generalist agent for the web , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
work page 2022
-
[44]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[45]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes , author=. arXiv preprint arXiv:2601.11659 , year=
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.