Recognition: no theorem link
Crosslingual On-Policy Self-Distillation for Multilingual Reasoning
Pith reviewed 2026-05-12 04:41 UTC · model grok-4.3
The pith
COPSD uses a model's own English reasoning as teacher to improve its low-resource language math performance via on-policy token distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COPSD lets a single model transfer its high-resource English reasoning behavior to low-resource languages by minimizing full-distribution token-level divergence on student rollouts, where the teacher alone receives the problem translation and reference solution in English.
What carries the argument
Crosslingual On-Policy Self-Distillation (COPSD): on-policy self-distillation that minimizes token-level output divergence between a student seeing only the low-resource input and a teacher given English translation plus reference solution.
If this is right
- Consistent accuracy gains on low-resource mathematical reasoning across different model sizes.
- Substantial outperformance of GRPO on 17 African languages.
- Improved adherence to answer formats and stronger test-time scaling.
- Generalization to harder multilingual reasoning benchmarks, with especially large gains for lower-resource languages.
Where Pith is reading between the lines
- The approach might extend to non-math reasoning tasks such as code generation or logical inference by supplying analogous privileged English context during distillation.
- It could lower the need for external translators or parallel data by relying on the model's internal crosslingual knowledge.
- Removing the reference solution from the teacher's context while keeping only the translation might still yield partial gains but would likely reduce reliability.
Load-bearing premise
The teacher's privileged English context generates supervision that transfers useful reasoning patterns to the student's low-resource generations without harmful biases or inconsistencies introduced by translation or the reference solution.
What would settle it
Training with COPSD on the same low-resource languages and models but measuring no increase (or a decrease) in math problem accuracy compared to standard supervised fine-tuning or GRPO would show the crosslingual distillation signal is not reliably beneficial.
Figures





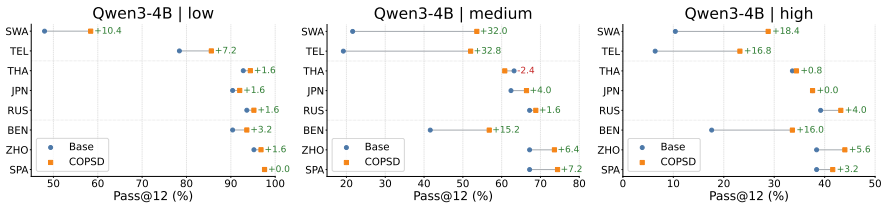


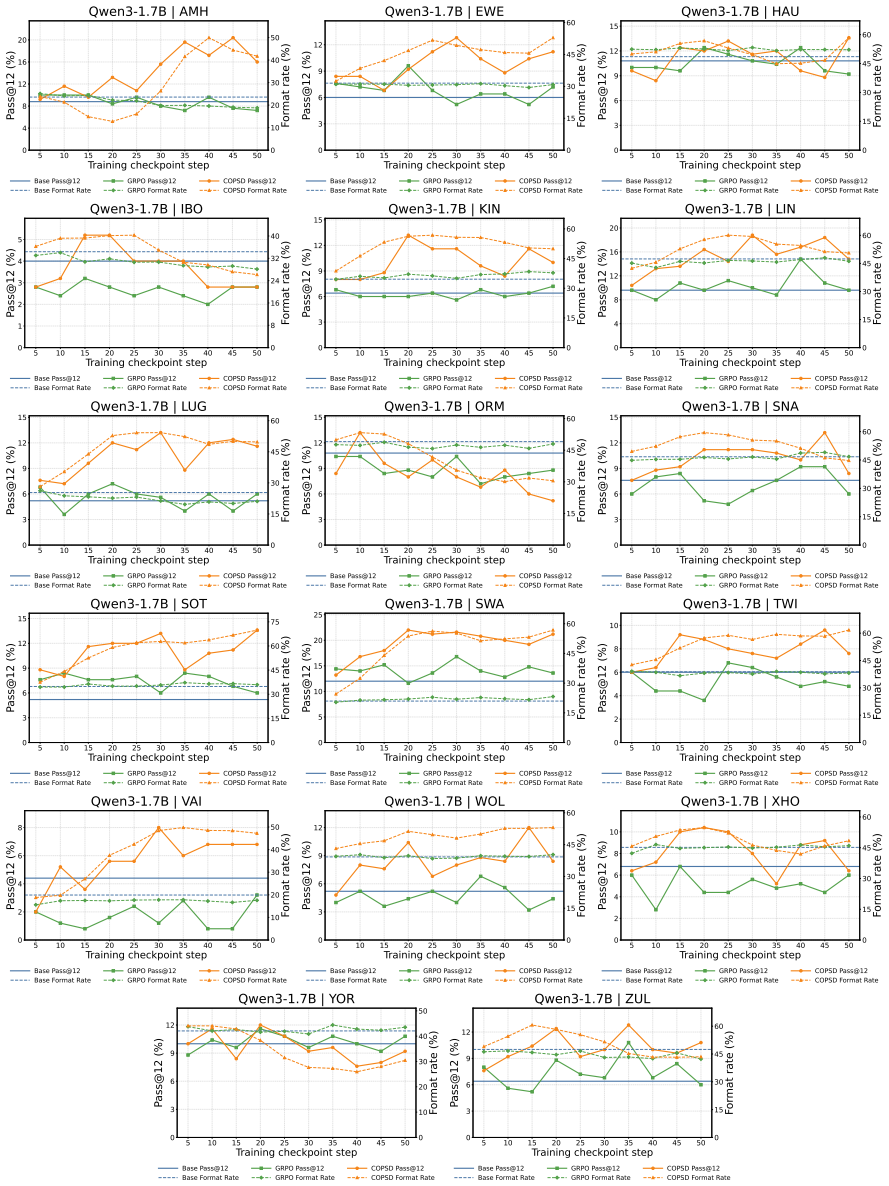
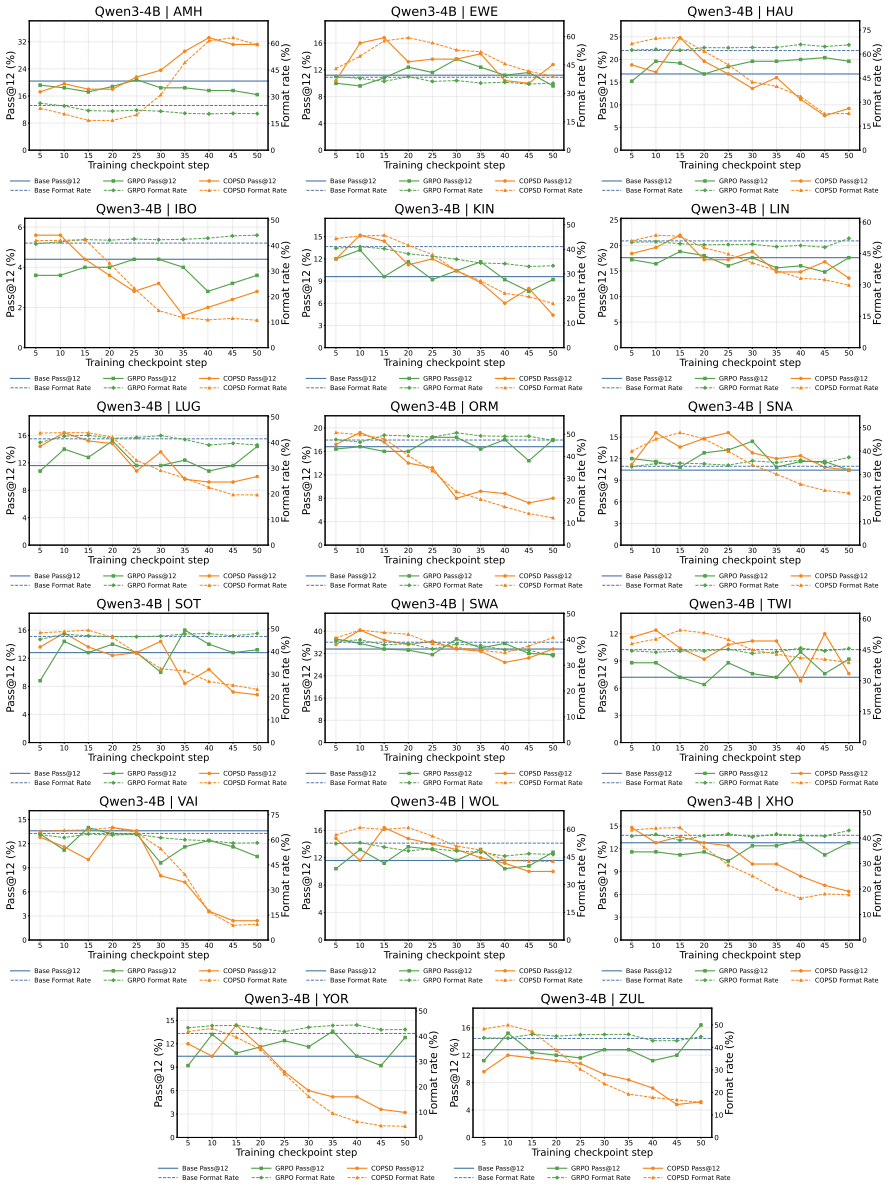
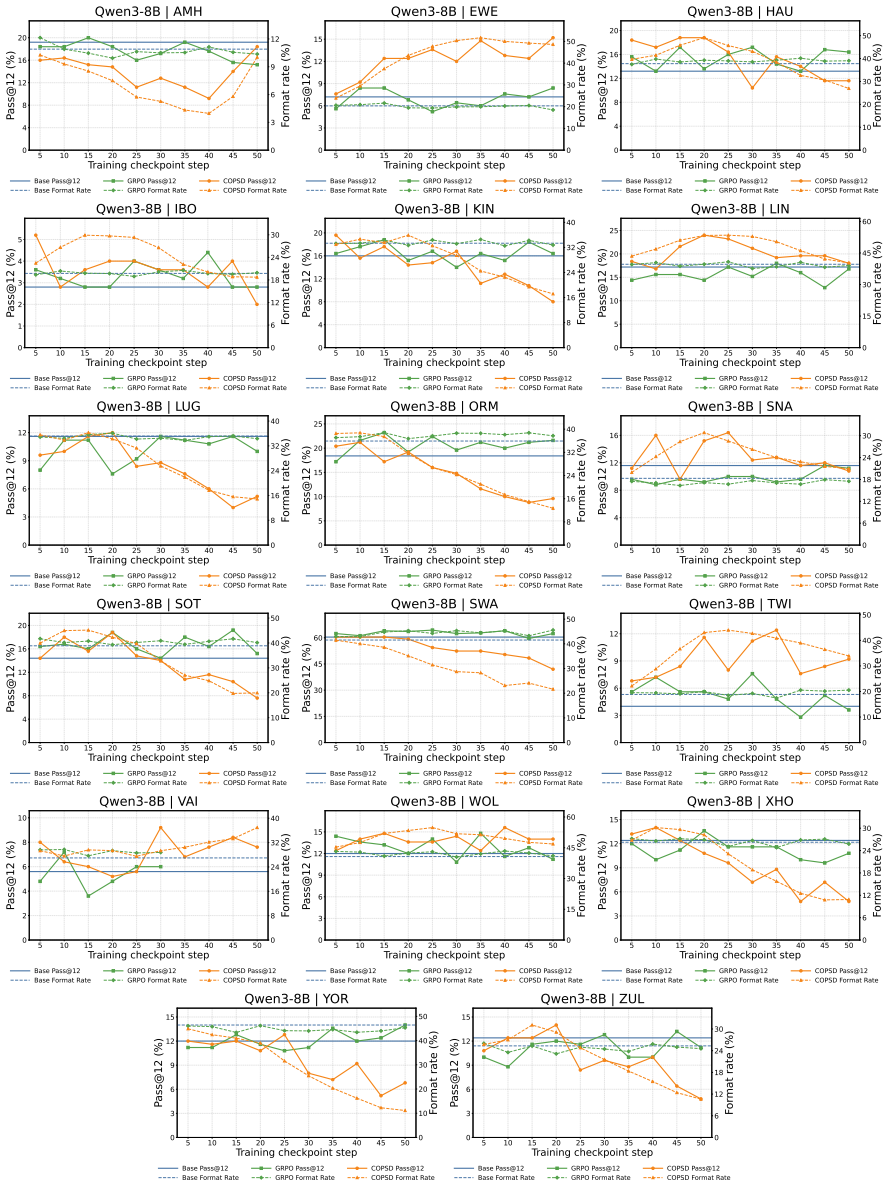

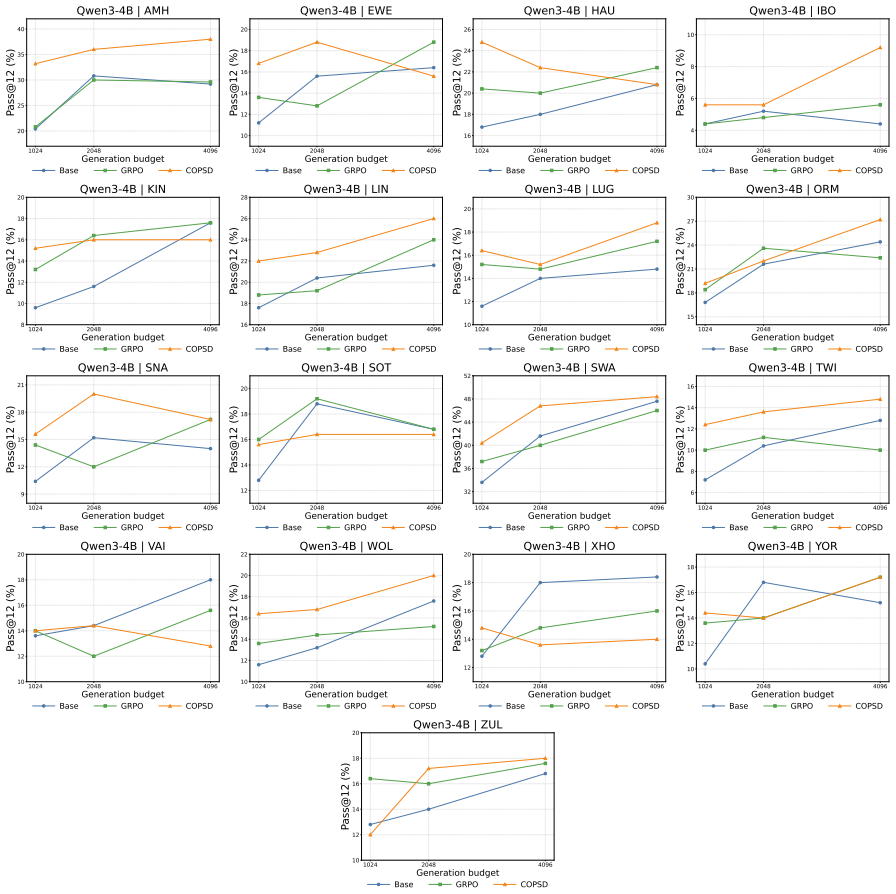




read the original abstract
Large language models (LLMs) have achieved remarkable progress in mathematical reasoning, but this ability is not equally accessible across languages. Especially low-resource languages exhibit much lower reasoning performance. To address this, we propose Crosslingual On-Policy Self-Distillation (COPSD), which transfers a model's own high-resource reasoning behavior to low-resource languages. COPSD uses the same model as student and teacher: the student sees only the low-resource problem, while the teacher receives privileged crosslingual context, including the problem translation and reference solution in English. Training minimizes full-distribution token-level divergence on the student's own rollouts, providing dense supervision while avoiding the sparsity and instability of outcome-only reinforcement learning (RL). Experiments on 17 low-resource African languages show that COPSD consistently improves low-resource mathematical reasoning across model sizes and substantially outperforms Group Relative Policy Optimization (GRPO). Further analyses show that COPSD improves answer-format adherence, strengthens test-time scaling, and generalizes to harder multilingual reasoning benchmarks, with especially large gains for lower-resource languages. We make our code and data available at: https://github.com/cisnlp/COPSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Crosslingual On-Policy Self-Distillation (COPSD), a self-distillation procedure in which the same LLM acts as both student and teacher: the student receives only the low-resource-language problem statement, while the teacher is given privileged crosslingual context consisting of an English translation and reference solution. Training minimizes full-distribution token-level KL divergence on the student's own on-policy rollouts. Experiments across 17 low-resource African languages and multiple model sizes report consistent gains in mathematical reasoning, outperformance relative to Group Relative Policy Optimization (GRPO), improved answer-format adherence, stronger test-time scaling, and generalization to harder benchmarks, with larger gains for lower-resource languages. Code and data are released.
Significance. If the central claim holds, COPSD offers a practical, dense-supervision alternative to outcome-only RL for closing the multilingual reasoning gap without external data or unstable policy optimization. The open release of code and data, together with evaluation on 17 languages and multiple model scales, strengthens the work's reproducibility and potential impact for low-resource settings.
major comments (2)
- [Method] Method section (COPSD description): the teacher is conditioned on the English reference solution while the student sees only the low-resource problem; token-level divergence on student rollouts can therefore reward reproduction of the known correct answer path rather than induction of language-internal reasoning steps. This risks answer leakage, especially given imperfect translations or style mismatches in low-resource languages. No ablation that removes the reference solution from the teacher (or substitutes a no-reference teacher) is reported, leaving the interpretation of the gains over GRPO open to the alternative explanation of privileged-answer mimicry.
- [Experiments] Experiments and results sections: the headline claims of 'consistent improvements across model sizes' and 'substantially outperforms GRPO' on 17 languages rest on quantitative results that, per the abstract, lack reported error bars, statistical significance tests, or per-language breakdowns. Without these, it is difficult to assess whether the observed deltas are robust or driven by a subset of languages or model scales.
minor comments (2)
- [Abstract] The abstract states improvements but supplies no numerical deltas, baseline scores, or key metrics; adding one or two representative numbers (e.g., average accuracy lift on the 17-language suite) would improve readability.
- [Method] Notation for the divergence objective and rollout sampling procedure could be clarified with an explicit equation or pseudocode block to make the on-policy self-distillation step easier to replicate.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where we will revise the manuscript to strengthen the presentation and address the concerns raised.
read point-by-point responses
-
Referee: [Method] Method section (COPSD description): the teacher is conditioned on the English reference solution while the student sees only the low-resource problem; token-level divergence on student rollouts can therefore reward reproduction of the known correct answer path rather than induction of language-internal reasoning steps. This risks answer leakage, especially given imperfect translations or style mismatches in low-resource languages. No ablation that removes the reference solution from the teacher (or substitutes a no-reference teacher) is reported, leaving the interpretation of the gains over GRPO open to the alternative explanation of privileged-answer mimicry.
Authors: We appreciate the referee's point on potential answer leakage. The design intentionally provides the teacher with privileged crosslingual context (English translation plus reference solution) to generate high-quality reasoning distributions that the student can distill from its own on-policy rollouts. This enables dense supervision without external data. However, we acknowledge that the current experiments do not isolate whether gains arise from reasoning transfer versus direct mimicry of the reference path, particularly with imperfect translations. We will add an ablation in the revised manuscript that removes the reference solution from the teacher's prompt (retaining only the English translation) and compare performance against the full COPSD setup and GRPO. This will clarify the contribution of each component. revision: yes
-
Referee: [Experiments] Experiments and results sections: the headline claims of 'consistent improvements across model sizes' and 'substantially outperforms GRPO' on 17 languages rest on quantitative results that, per the abstract, lack reported error bars, statistical significance tests, or per-language breakdowns. Without these, it is difficult to assess whether the observed deltas are robust or driven by a subset of languages or model scales.
Authors: We agree that additional statistical details would improve the robustness assessment. The reported results are averages over the 17 languages, but we did not include per-language tables, standard deviations across runs, or formal significance tests in the main text or appendix for space reasons. In the revision we will add (i) a per-language breakdown table with mean and standard deviation (computed from the multiple model scales and seeds where available), (ii) error bars on all main figures, and (iii) paired statistical tests (e.g., Wilcoxon signed-rank) comparing COPSD against GRPO and other baselines. These additions will be placed in the results section and appendix. revision: yes
Circularity Check
No significant circularity in the proposed method or claims
full rationale
The paper describes COPSD as a procedural training recipe: the same model acts as student (receiving only the low-resource problem) and teacher (receiving privileged English translation plus reference solution), with training via token-level divergence minimization on student-generated rollouts. This is a standard on-policy distillation setup with no mathematical derivation chain, no fitted parameters renamed as predictions, and no self-referential quantities. The performance claims rest on empirical results across 17 languages and model sizes rather than any reduction to the method's own inputs by construction. No load-bearing self-citations or ansatz smuggling appear in the description. The approach is self-contained as an independent training procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Ahn, Janice and Verma, Rishu and Lou, Renze and Liu, Di and Zhang, Rui and Yin, Wenpeng. Large Language Models for Mathematical Reasoning: Progresses and Challenges. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop. 2024. doi:10.18653/v1/2024.eacl-srw.17
-
[2]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[3]
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
work page 2022
-
[4]
Learn Globally, Speak Locally: Bridging the Gaps in Multilingual Reasoning , author=. 2025 , eprint=
work page 2025
-
[5]
Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers , author=. 2024 , eprint=
work page 2024
-
[6]
The Thirteenth International Conference on Learning Representations,
Wen Yang and Junhong Wu and Chen Wang and Chengqing Zong and Jiajun Zhang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[7]
Long Chain-of-Thought Reasoning Across Languages , author=. 2026 , eprint=
work page 2026
-
[8]
Wu, Linjuan and Wei, Hao-Ran and Yang, Baosong and Lu, Weiming. From E nglish to Second Language Mastery: Enhancing LLM s with Cross-Lingual Continued Instruction Tuning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1121
- [9]
-
[10]
Neural Machine Translation for Mathematical Formulae
Petersen, Felix and Schubotz, Moritz and Greiner-Petter, Andre and Gipp, Bela. Neural Machine Translation for Mathematical Formulae. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.645
-
[11]
What Makes Good Multilingual Reasoning? Disentangling Reasoning Traces with Measurable Features , author=. 2026 , eprint=
work page 2026
-
[12]
Zhang, Yuanchi and Wang, Yile and Liu, Zijun and Wang, Shuo and Wang, Xiaolong and Li, Peng and Sun, Maosong and Liu, Yang. Enhancing Multilingual Capabilities of Large Language Models through Self-Distillation from Resource-Rich Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 202...
-
[13]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. 2026 , eprint=
work page 2026
-
[14]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. 2026 , eprint=
work page 2026
-
[15]
OPSDL: On-Policy Self-Distillation for Long-Context Language Models , author=. 2026 , eprint=
work page 2026
-
[16]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. 2026 , eprint=
work page 2026
-
[17]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation , author=. 2026 , eprint=
work page 2026
- [18]
-
[19]
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
Wang, Mingyang and Lange, Lukas and Adel, Heike and Ma, Yunpu and Str. Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.132
-
[20]
When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy
Qi, Jirui and Chen, Shan and Xiong, Zidi and Fern \'a ndez, Raquel and Bitterman, Danielle and Bisazza, Arianna. When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1103
-
[21]
Zhao, Raoyuan and Liu, Yihong and Schuetze, Hinrich and Hedderich, Michael A. A Comprehensive Evaluation of Multilingual Chain-of-Thought Reasoning: Performance, Consistency, and Faithfulness Across Languages. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.276
-
[22]
Crosslingual Reasoning through Test-Time Scaling , author=. 2025 , eprint=
work page 2025
-
[23]
Schulhoff, Sander and Pinto, Jeremy and Khan, Anaum and Bouchard, Louis-Fran c ois and Si, Chenglei and Anati, Svetlina and Tagliabue, Valen and Kost, Anson and Carnahan, Christopher and Boyd-Graber, Jordan. Ignore This Title and H ack AP rompt: Exposing Systemic Vulnerabilities of LLM s Through a Global Prompt Hacking Competition. Proceedings of the 2023...
-
[24]
Systematically Analyzing Prompt Injection Vulnerabilities in Diverse LLM Architectures , author=. 2024 , eprint=
work page 2024
-
[25]
OpenThoughts: Data Recipes for Reasoning Models , author=. 2025 , eprint=
work page 2025
-
[26]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
work page 2022
-
[27]
I roko B ench: A New Benchmark for A frican Languages in the Age of Large Language Models
Adelani, David Ifeoluwa and Ojo, Jessica and Azime, Israel Abebe and Zhuang, Jian Yun and Alabi, Jesujoba Oluwadara and He, Xuanli and Ochieng, Millicent and Hooker, Sara and Bukula, Andiswa and Lee, En-Shiun Annie and Chukwuneke, Chiamaka Ijeoma and Buzaaba, Happy and Sibanda, Blessing Kudzaishe and Kalipe, Godson Koffi and Mukiibi, Jonathan and Kabongo ...
-
[28]
The Eleventh International Conference on Learning Representations,
Freda Shi and Mirac Suzgun and Markus Freitag and Xuezhi Wang and Suraj Srivats and Soroush Vosoughi and Hyung Won Chung and Yi Tay and Sebastian Ruder and Denny Zhou and Dipanjan Das and Jason Wei , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
work page 2023
-
[29]
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts , author=. 2025 , eprint=
work page 2025
-
[30]
SPoC: Search-based Pseudocode to Code , booktitle =
Sumith Kulal and Panupong Pasupat and Kartik Chandra and Mina Lee and Oded Padon and Alex Aiken and Percy Liang , editor =. SPoC: Search-based Pseudocode to Code , booktitle =. 2019 , url =
work page 2019
-
[31]
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
work page 2021
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[33]
The Twelfth International Conference on Learning Representations,
Rishabh Agarwal and Nino Vieillard and Yongchao Zhou and Piotr Stanczyk and Sabela Ramos Garea and Matthieu Geist and Olivier Bachem , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[34]
The Twelfth International Conference on Learning Representations,
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[35]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[36]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation , author=. 2026 , eprint=
work page 2026
-
[37]
The Annals of Mathematical Statistics , volume=
On Information and Sufficiency , author=. The Annals of Mathematical Statistics , volume=. 1951 , publisher=
work page 1951
-
[38]
Scaling Instruction-Finetuned Language Models , journal =
Hyung Won Chung and Le Hou and Shayne Longpre and Barret Zoph and Yi Tay and William Fedus and Yunxuan Li and Xuezhi Wang and Mostafa Dehghani and Siddhartha Brahma and Albert Webson and Shixiang Shane Gu and Zhuyun Dai and Mirac Suzgun and Xinyun Chen and Aakanksha Chowdhery and Alex Castro. Scaling Instruction-Finetuned Language Models , journal =. 2024 , url =
work page 2024
-
[39]
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Yang, Zhaorui and Pang, Tianyu and Feng, Haozhe and Wang, Han and Chen, Wei and Zhu, Minfeng and Liu, Qian. Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.58
-
[40]
Ye, Junjie and Yang, Yuming and Nan, Yang and Li, Shuo and Zhang, Qi and Gui, Tao and Huang, Xuanjing and Wang, Peng and Shi, Zhongchao and Fan, Jianping. Analyzing the Effects of Supervised Fine-Tuning on Model Knowledge from Token and Parameter Levels. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.1...
-
[41]
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs , author=. 2025 , eprint=
work page 2025
-
[42]
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , eprint=
work page 2025
-
[43]
Multilingual Reasoning via Self-training
Ranaldi, Leonardo and Pucci, Giulia. Multilingual Reasoning via Self-training. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.577
-
[44]
A Survey of Multilingual Reasoning in Language Models
Ghosh, Akash and Datta, Debayan and Saha, Sriparna and Agarwal, Chirag. A Survey of Multilingual Reasoning in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.474
-
[45]
Large Reasoning Models Are (Not Yet) Multilingual Latent Reasoners , author=. 2026 , eprint=
work page 2026
-
[46]
Language Matters: How Do Multilingual Input and Reasoning Paths Affect Large Reasoning Models? , author=. 2025 , eprint=
work page 2025
-
[47]
Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages
Qin, Libo and Chen, Qiguang and Wei, Fuxuan and Huang, Shijue and Che, Wanxiang. Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.163
-
[48]
Huang, Haoyang and Tang, Tianyi and Zhang, Dongdong and Zhao, Xin and Song, Ting and Xia, Yan and Wei, Furu. Not All Languages Are Created Equal in LLM s: Improving Multilingual Capability by Cross-Lingual-Thought Prompting. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.826
-
[49]
Question Translation Training for Better Multilingual Reasoning
Zhu, Wenhao and Huang, Shujian and Yuan, Fei and She, Shuaijie and Chen, Jiajun and Birch, Alexandra. Question Translation Training for Better Multilingual Reasoning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.498
-
[50]
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models? , author=. 2026 , eprint=
work page 2026
-
[51]
Demystifying Multilingual Reasoning in Process Reward Modeling
Wang, Weixuan and Wu, Minghao and Haddow, Barry and Birch, Alexandra. Demystifying Multilingual Reasoning in Process Reward Modeling. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.519
-
[52]
LLaMA Beyond English: An Empirical Study on Language Capability Transfer , author=. 2024 , eprint=
work page 2024
-
[53]
Beyond English-Centric Training: How Reinforcement Learning Improves Cross-Lingual Reasoning in LLMs , author=. 2025 , eprint=
work page 2025
-
[54]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.845
-
[55]
The Twelfth International Conference on Learning Representations,
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[56]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
work page 2015
-
[57]
7th International Conference on Learning Representations,
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations,. 2019 , url =
work page 2019
-
[58]
RLHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLM s
Dang, John and Ahmadian, Arash and Marchisio, Kelly and Kreutzer, Julia and. RLHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.729
-
[59]
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Shaham, Uri and Herzig, Jonathan and Aharoni, Roee and Szpektor, Idan and Tsarfaty, Reut and Eyal, Matan. Multilingual Instruction Tuning With Just a Pinch of Multilinguality. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.136
-
[60]
m C o T : Multilingual Instruction Tuning for Reasoning Consistency in Language Models
Lai, Huiyuan and Nissim, Malvina. m C o T : Multilingual Instruction Tuning for Reasoning Consistency in Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.649
-
[61]
MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization
She, Shuaijie and Zou, Wei and Huang, Shujian and Zhu, Wenhao and Liu, Xiang and Geng, Xiang and Chen, Jiajun. MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.539
-
[62]
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning , author=. 2026 , eprint=
work page 2026
-
[63]
Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning , author=. 2026 , eprint=
work page 2026
-
[64]
Aligning Multilingual Reasoning with Verifiable Semantics from a High-Resource Expert Model , author=. 2025 , eprint=
work page 2025
-
[65]
Reasoning Transfer for an Extremely Low-Resource and Endangered Language: Bridging Languages Through Sample-Efficient Language Understanding , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.