Recognition: 2 theorem links
· Lean TheoremRADAR Challenge 2026: Robust Audio Deepfake Recognition under Media Transformations
Pith reviewed 2026-05-12 02:29 UTC · model grok-4.3
The pith
The RADAR Challenge shows audio deepfake detectors still fail under common media changes and multiple languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
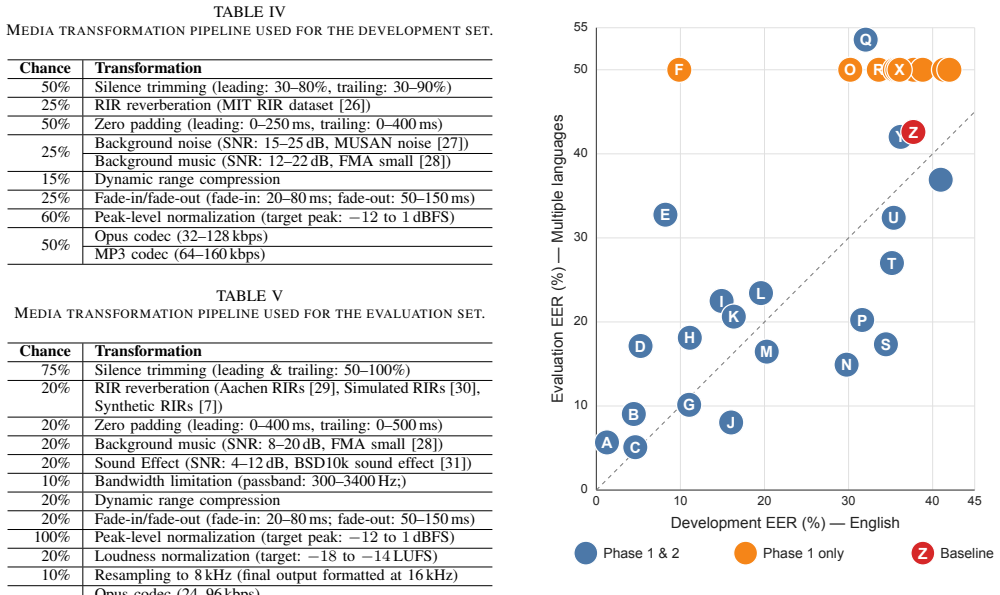
RADAR Challenge 2026 is an APSIPA Grand Challenge on Robust Audio Deepfake Recognition under Media Transformations, designed to simulate realistic media conditions in real-world audio distribution pipelines, including compression, resampling, noise, and reverberation. It consists of two phases: an English development phase with labeled data for analysis and paper writing, and a multilingual evaluation phase containing more than 100,000 utterances in English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese. Systems are evaluated using equal error rate for binary real/fake classification. During the challenge, 33 teams submitted to the development phase and 22
What carries the argument
The two-phase challenge protocol built around a dataset that applies specific media transformations and spans six languages, scored by equal error rate on real-versus-fake classification.
If this is right
- Effective detectors must maintain low error rates after audio has undergone compression, resampling, noise, and reverberation.
- Systems need to generalize across multiple languages and accents to be useful in global settings.
- Current binary classification approaches leave measurable gaps when both linguistic variety and media processing are present together.
- Organized challenges with large evaluation sets can surface limitations that smaller single-language tests miss.
Where Pith is reading between the lines
- Future work could test whether features invariant to resampling and compression also help across languages.
- The benchmark could serve as a common test for new generative models to check how detectable their outputs remain after typical distribution steps.
- Deployment on social platforms would likely require separate handling of language-specific and transformation-specific failure modes.
Load-bearing premise
The chosen media transformations and the constructed multilingual dataset accurately represent the distortions that occur in real-world audio distribution pipelines.
What would settle it
A submitted system that achieves substantially lower equal error rates than the reported results on the full multilingual evaluation set while still facing the full range of transformations would show that the claimed remaining challenges have been overcome.
Figures
read the original abstract
RADAR Challenge 2026 is an APSIPA Grand Challenge on Robust Audio Deepfake Recognition under Media Transformations, designed to simulate realistic media conditions in real-world audio distribution pipelines, including compression, resampling, noise, and reverberation. It consists of two phases: an English development phase with labeled data for analysis and paper writing, and a multilingual evaluation phase containing more than 100,000 utterances in English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese. Systems are evaluated using equal error rate (EER) for binary real/fake classification. This paper describes the challenge task, the construction of the data set, the evaluation protocol, and the overall results. During the challenge, 33 teams submitted to the development phase and 22 teams submitted to the final evaluation phase. The reported results highlight the remaining challenges of robust audio deepfake detection under multilingual and media-transformed conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the RADAR Challenge 2026, an APSIPA Grand Challenge on robust audio deepfake recognition under media transformations (compression, resampling, noise, reverberation). It outlines a two-phase setup—an English development phase with labeled data and a multilingual evaluation phase with >100,000 utterances across English, Singapore English, Mandarin Chinese, Taiwanese Mandarin, Japanese, and Vietnamese—using equal error rate (EER) for binary real/fake classification. The paper reports participation (33 teams in development, 22 in evaluation), presents the task, dataset construction, evaluation protocol, and aggregate results, and concludes that the outcomes demonstrate ongoing challenges in robust detection under multilingual and transformed conditions.
Significance. If the dataset construction and transformations are representative, the challenge provides a valuable large-scale, multilingual benchmark that can drive progress in audio deepfake detection by exposing limitations of current systems under realistic media distortions. The observational reporting of external team submissions supplies concrete empirical evidence without introducing unverified methodological innovations, strengthening its utility as a community resource.
major comments (1)
- §3 (Dataset Construction): the manuscript supplies no parameters or implementation details for the media transformations (e.g., compression codecs and bitrates, resampling ratios, noise SNR levels, or reverberation impulse responses). Without these, it is impossible to assess whether the reported performance gaps reflect genuine robustness issues or artifacts of the simulation, directly affecting the central claim that challenges remain under the tested conditions.
minor comments (3)
- Abstract: the summary states participation numbers and the high-level conclusion but omits any quantitative EER ranges or per-language breakdowns from the 22 evaluation submissions, weakening the reader's ability to gauge the scale of the remaining challenges.
- Evaluation Protocol section: the description of the EER metric does not specify whether the multilingual test sets maintain class balance (real vs. fake) per language or transformation type, which is required for unambiguous interpretation of the aggregate scores.
- Overall: add citations to prior audio deepfake benchmarks (e.g., ASVspoof, WaveFake) to situate the new challenge relative to existing resources.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recommendation of minor revision, and the constructive comment on dataset details. We address the point below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [—] §3 (Dataset Construction): the manuscript supplies no parameters or implementation details for the media transformations (e.g., compression codecs and bitrates, resampling ratios, noise SNR levels, or reverberation impulse responses). Without these, it is impossible to assess whether the reported performance gaps reflect genuine robustness issues or artifacts of the simulation, directly affecting the central claim that challenges remain under the tested conditions.
Authors: We agree that explicit parameters for the media transformations are necessary for reproducibility and to substantiate that the observed performance gaps reflect real robustness challenges rather than simulation artifacts. The original manuscript provided only a high-level overview of the transformations to maintain focus on the challenge structure and results. In the revised version we will expand §3 with a dedicated subsection listing the precise implementation details used during dataset construction, including the specific codecs and bitrates for compression, the resampling ratios applied, the SNR ranges and noise types, and the impulse-response sources and room parameters for reverberation. These details will be drawn directly from the data-generation pipeline employed for the RADAR Challenge 2026. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a challenge description paper that defines a task, constructs a dataset and evaluation protocol, and reports aggregate EER results from 22 external team submissions on a multilingual transformed test set. No derivations, equations, fitted parameters, or predictions appear in the provided text. The central observational claim (remaining challenges under the tested conditions) follows directly from the reported submission outcomes without any self-referential reduction, self-citation load-bearing step, or renaming of known results. This is the expected non-finding for a purely descriptive challenge paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RADAR Challenge 2026 ... focuses on binary real/fake classification ... evaluated using equal error rate (EER) ... media transformations including compression, resampling, noise, and reverberation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The reported results highlight the remaining challenges of robust audio deepfake detection under multilingual and media-transformed conditions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ASVspoof 2019: A large-scale pub- lic database of synthesized, converted and replayed speech,
X. Wang et al., “ASVspoof 2019: A large-scale pub- lic database of synthesized, converted and replayed speech,”Computer Speech & Language, vol. 64, p. 101 114, Nov. 2020,ISSN: 08852308
work page 2019
-
[2]
doi: 10.1109/TASLP .2024.3402087
X. Liu et al., “ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Transactions on Audio, Speech, and Language Process- ing, vol. 31, pp. 2507–2522, 2023.DOI: 10.1109/TASLP. 2023.3285283
-
[3]
https://doi.org/https://doi.org/10.1016/j
X. Wang et al., “ASVspoof 5: Design, collection and validation of resources for spoofing, deepfake, and ad- versarial attack detection using crowdsourced speech,” Computer Speech & Language, vol. 95, p. 101 825, 2026,ISSN: 0885-2308.DOI: https://doi.org/10.1016/j. csl.2025.101825
work page doi:10.1016/j 2026
-
[4]
Safe: Synthetic audio forensics evalua- tion challenge,
T. Kirill et al., “Safe: Synthetic audio forensics evalua- tion challenge,” inProc. ACM IH&MMSEC Workshop, 2025, pp. 174–180
work page 2025
-
[5]
Audioclip: Extending clip to image, text and audio
J. Yi et al., “ADD 2022: The first audio deep synthesis detection challenge,” inProc. ICASSP, 2022, pp. 9216– 9220.DOI: 10.1109/ICASSP43922.2022.9746939
-
[6]
ADD 2023: The Second Audio Deepfake Detection Challenge,
J. Yi et al., “ADD 2023: The Second Audio Deepfake Detection Challenge,” inProc. IJCAI DADA Workshop, May 2023
work page 2023
-
[7]
Room impulse responses help attackers to evade deep fake detection,
H.-T. Luong, D.-T. Truong, K. A. Lee, and E. S. Chng, “Room impulse responses help attackers to evade deep fake detection,” in2024 IEEE Spoken Language Technology Workshop (SLT), IEEE, 2024, pp. 623–629
work page 2024
-
[8]
Llamapartialspoof: An llm-driven fake speech dataset simulating disinformation generation,
H.-T. Luong, H. Li, L. Zhang, K. A. Lee, and E. S. Chng, “Llamapartialspoof: An llm-driven fake speech dataset simulating disinformation generation,” inProc. ICASSP, 2025.DOI: 10 . 1109 / ICASSP49660 . 2025 . 10888070
work page 2025
-
[9]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,
H. Zen et al., “LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,” inInterspeech 2019, 2019, pp. 2638–2642
work page 2019
-
[10]
JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech,
J. Lim, J. Ye, S. Chun, S. Kim, and J. Cho, “JETS: Jointly Training FastSpeech2 and HiFi-GAN for End to End Text to Speech,” inInterspeech 2022, 2022, pp. 2338–2342
work page 2022
-
[11]
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot V oice Conversion for Everyone,
E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. G¨olge, and M. A. Ponti, “YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot V oice Conversion for Everyone,” inICML, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, Eds., ser. Proceed- ings of Machine Learning Research, vol. 162, PMLR, 17–23 Jul 2022, pp. 2709–2720
work page 2022
-
[12]
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,
E. Casanova et al., “XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,” inInterspeech 2024, 2024, pp. 4978–4982
work page 2024
-
[13]
RVC-Boss,GPT-SoVITS, https://github.com/RVC-Boss/ GPT-SoVITS, Accessed: 2026-05-09, 2024
work page 2026
- [14]
-
[15]
Z. Du et al., “Cosyvoice: A scalable multilingual zero- shot text-to-speech synthesizer based on supervised se- mantic tokens,”arXiv preprint arXiv:2407.05407, 2024
-
[16]
Common voice: A massively- multilingual speech corpus,
R. Ardila et al., “Common voice: A massively- multilingual speech corpus,” inProceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215
work page 2020
-
[17]
The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,
D. Galvez et al., “The people’s speech: A large-scale di- verse english speech recognition dataset for commercial usage,”arXiv preprint arXiv:2111.09344, 2021
-
[18]
Building the Singapore English National Speech Corpus,
J. X. Koh et al., “Building the Singapore English National Speech Corpus,” inInterspeech 2019, pp. 321– 325
work page 2019
-
[19]
imagicdatatech.com/index.php/home/dataopensource/ data info/id/101, Accessed: 2019-05, 2019
Magic Data Technology Co., Ltd.,Openslr68: Magic- data mandarin chinese read speech corpus, http://www. imagicdatatech.com/index.php/home/dataopensource/ data info/id/101, Accessed: 2019-05, 2019
work page 2019
-
[20]
Formosa speech recognition challenge 2020 and taiwanese across taiwan corpus,
Y .-F. Liao et al., “Formosa speech recognition challenge 2020 and taiwanese across taiwan corpus,” inProc. O- COCOSDA 2020, IEEE, 2020, pp. 65–70
work page 2020
-
[21]
Cpjd corpus: Crowd- sourced parallel speech corpus of japanese dialects,
S. Takamichi and H. Saruwatari, “Cpjd corpus: Crowd- sourced parallel speech corpus of japanese dialects,” in Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018), 2018
work page 2018
-
[22]
D. C. Tran,FPT Open Speech Dataset (FOSD) - Viet- namese, version V4, Mendeley Data, 2020.DOI: 10 . 17632/k9sxg2twv4.4
work page 2020
-
[23]
Z. Du et al., “CosyV oice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training,”arXiv preprint arXiv:2505.17589, 2025
-
[24]
Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
H. Hu et al., “Qwen3-tts technical report,”arXiv preprint arXiv:2601.15621, 2026
-
[25]
Fish audio s2 technical report,
S. Liao et al., “Fish audio s2 technical report,”arXiv preprint arXiv:2603.08823, 2026
-
[26]
Statistics of natural reverberation enable perceptual separation of sound and space,
J. Traer and J. H. McDermott, “Statistics of natural reverberation enable perceptual separation of sound and space,”PNAS, vol. 113, no. 48, E7856–E7865, 2016
work page 2016
-
[27]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
work page Pith review arXiv 2015
-
[28]
Fma: A dataset for music analysis,
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “Fma: A dataset for music analysis,” in18th International Society for Music Information Retrieval Conference, 2017
work page 2017
-
[29]
A binaural room im- pulse response database for the evaluation of dereverber- ation algorithms,
M. Jeub, M. Schafer, and P. Vary, “A binaural room im- pulse response database for the evaluation of dereverber- ation algorithms,” in2009 16th international conference on digital signal processing, IEEE, 2009, pp. 1–5
work page 2009
-
[30]
Image method for ef- ficiently simulating small-room acoustics,
J. B. Allen and D. A. Berkley, “Image method for ef- ficiently simulating small-room acoustics,”The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979
work page 1979
-
[31]
Hierarchical and multimodal learning for hetero- geneous sound classification,
P. Anastasopoulou, F. A. Dal R ´ı, X. Serra, and F. Font, “Hierarchical and multimodal learning for hetero- geneous sound classification,” inProc. DCASE 2025, 2025
work page 2025
-
[32]
H. Tak, M. Todisco, X. Wang, J.-w. Jung, J. Yamagishi, and N. Evans, “Automatic Speaker Verification Spoofing and Deepfake Detection Using Wav2vec 2.0 and Data Augmentation,” inOdyssey, 2022, pp. 112–119
work page 2022
-
[33]
Robust localization of partially fake speech: Metrics and out-of-domain evaluation,
H.-T. Luong, I. Rimon, H. Permuter, K. A. Lee, and E. S. Chng, “Robust localization of partially fake speech: Metrics and out-of-domain evaluation,” in2025 Asia Pacific Signal and Information Processing Asso- ciation Annual Summit and Conference (APSIPA ASC), IEEE, 2025, pp. 2205–2210
work page 2025
-
[34]
Measuring the ro- bustness of audio deepfake detectors,
X. Li, P.-Y . Chen, and W. Wei, “Measuring the ro- bustness of audio deepfake detectors,”arXiv preprint arXiv:2503.17577, 2025
-
[35]
Replay attacks against audio deepfake detection,
N. M ¨uller et al., “Replay attacks against audio deepfake detection,”Interspeech 2025, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.