Recognition: 2 theorem links
· Lean TheoremConCovUp: Effective Agent-Based Test Driver Generation for Concurrency Testing
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
ConCovUp combines LLMs and static analysis in a multi-agent setup to generate test drivers that achieve higher coverage of shared memory access pairs in concurrency testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
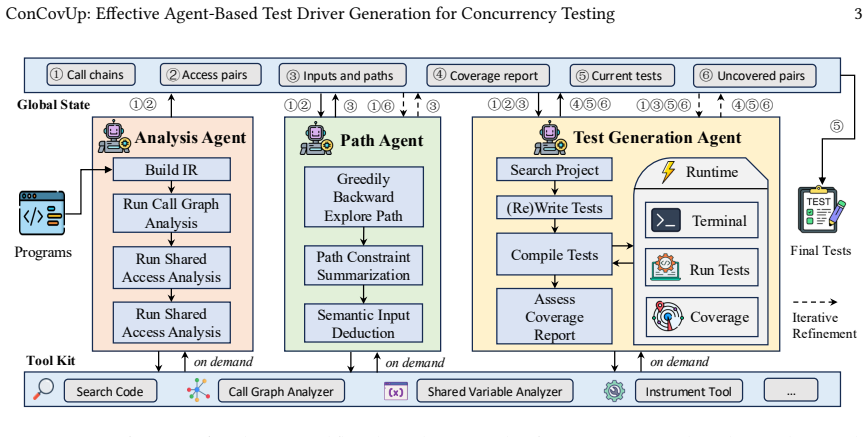
ConCovUp is a multi-agent framework that combines LLMs with program analysis by extracting shared memory accesses and calling contexts through static analysis, using LLM semantic reasoning in backward tracing to deduce concrete inputs for hard-to-reach accesses, and iteratively refining generated tests via dynamic execution feedback.
What carries the argument
LLM-driven backward tracing, which uses the model's semantic reasoning to satisfy path constraints for triggering shared memory accesses.
If this is right
- Test drivers can reach more critical shared-memory interactions during runtime execution.
- Dynamic analysis tools benefit from higher coverage to detect more concurrency-related bugs.
- The approach reduces the manual effort needed to create effective concurrent tests for C/C++ libraries.
- Improved coverage on real-world libraries indicates potential for broader adoption in automated testing pipelines.
Where Pith is reading between the lines
- This method might generalize to other programming languages if equivalent static analysis tools are available.
- Combining it with more precise constraint solvers could address cases where LLMs hallucinate on complex paths.
- Future work could explore applying the backward tracing to other types of hard-to-reach code paths beyond concurrency.
Load-bearing premise
The large language model can accurately deduce concrete inputs that satisfy the complex path constraints for hard-to-reach shared memory accesses without producing unsatisfiable solutions.
What would settle it
Evaluating ConCovUp on a new collection of C/C++ programs where the backward tracing frequently fails to find valid inputs would determine if the coverage improvements hold.
Figures




read the original abstract
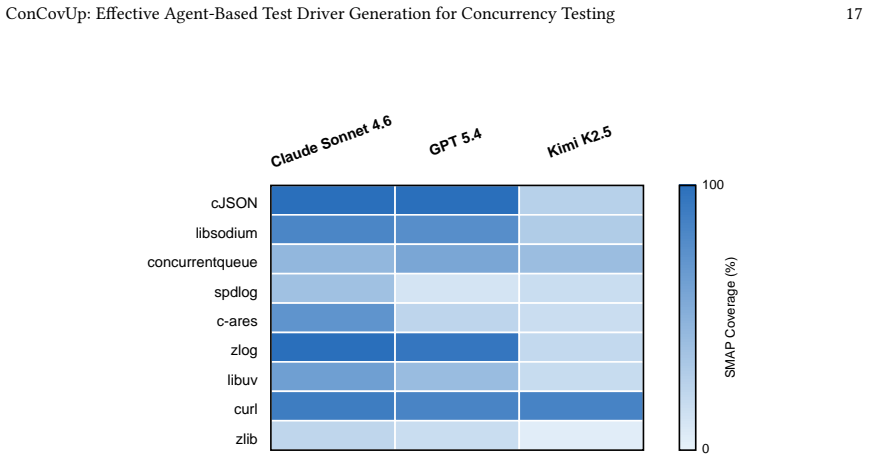
Concurrency testing is essential to improve the reliability and security of multi-threaded programs. Dynamic analysis tools, such as TSan, depend on high-quality test drivers that reach critical shared-memory interactions at runtime. However, current testing practices predominantly focus on sequential logic, leaving a gap in automated concurrent test generation. Recently, large language models (LLMs) have shown promise in generating sequential tests, but they struggle to produce effective concurrent tests without a deep understanding of concurrency semantics. This paper presents ConCovUp, a multi-agent framework that combines LLMs with program analysis. ConCovUp grounds test generation in static analysis to extract shared memory accesses and their calling contexts. To trigger hard-to-reach accesses, it introduces an LLM-driven backward tracing approach, leveraging the model's semantic reasoning to deduce concrete inputs that satisfy complex path constraints, and iteratively refines the generated tests via dynamic execution feedback. Our evaluation on nine real-world C/C++ libraries shows that ConCovUp improves average Shared Memory Access Pair Coverage (SMAP Coverage) from 36.6% to 68.1% over the general Claude Code agent baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ConCovUp, a multi-agent framework that combines LLMs with static program analysis to generate test drivers for concurrency testing in C/C++ code. Static analysis extracts shared-memory accesses and calling contexts; an LLM-driven backward-tracing procedure deduces concrete inputs to satisfy path constraints; and dynamic execution feedback iteratively refines the tests. The central claim is an empirical result: on nine real-world libraries, ConCovUp raises average Shared Memory Access Pair (SMAP) coverage from 36.6 % (general Claude Code agent baseline) to 68.1 %.
Significance. If the coverage gains prove statistically robust, the work offers a concrete advance in automated concurrency testing by grounding LLM generation in static analysis and execution feedback. This addresses a recognized gap between sequential test generation and the needs of dynamic tools such as TSan. The multi-agent architecture and backward-tracing idea are technically interesting and could be reusable beyond the reported setting.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation): the headline result—an average SMAP-coverage lift from 36.6 % to 68.1 %—is reported as two scalar averages with no indication of the number of independent trials per library, per-library or aggregate standard deviations, error bars, or any hypothesis test. Because LLM generation is stochastic, the absence of these statistics leaves open the possibility that the 31.5 pp difference is an artifact of lucky seeds or an unequally resourced baseline run.
- [§4 (Evaluation)] §4 (Evaluation): the manuscript does not state whether the Claude Code baseline was supplied with the same static-analysis artifacts (shared-memory access pairs and calling contexts) that ConCovUp receives, or whether it was run under an otherwise identical experimental protocol. This information is required to interpret the reported improvement as a fair comparison.
minor comments (2)
- [Abstract] The acronym SMAP is introduced in the abstract without an explicit definition or pointer to its formal definition in the body; a concise definition should appear at first use.
- [§4 (Evaluation)] The nine libraries are referred to only as “real-world C/C++ libraries”; a table or appendix listing their names, versions, and sizes would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our evaluation. We agree that the current presentation of results requires additional statistical detail and protocol clarification to strengthen the claims, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 (Evaluation)] §4 (Evaluation): the headline result—an average SMAP-coverage lift from 36.6 % to 68.1 %—is reported as two scalar averages with no indication of the number of independent trials per library, per-library or aggregate standard deviations, error bars, or any hypothesis test. Because LLM generation is stochastic, the absence of these statistics leaves open the possibility that the 31.5 pp difference is an artifact of lucky seeds or an unequally resourced baseline run.
Authors: We acknowledge this limitation. The reported figures reflect single executions per library. In the revised manuscript we will execute five independent runs per library using distinct random seeds, report per-library and aggregate standard deviations, add error bars to the coverage plots, and include a paired Wilcoxon signed-rank test to assess statistical significance of the improvement. These changes will appear in §4. revision: yes
-
Referee: [§4 (Evaluation)] §4 (Evaluation): the manuscript does not state whether the Claude Code baseline was supplied with the same static-analysis artifacts (shared-memory access pairs and calling contexts) that ConCovUp receives, or whether it was run under an otherwise identical experimental protocol. This information is required to interpret the reported improvement as a fair comparison.
Authors: The baseline was deliberately run without the static-analysis artifacts; it received only the library source code and a generic prompt to produce concurrent test drivers. Model version, temperature, and the number of generated candidates were matched to the ConCovUp runs. We will add an explicit description of the baseline protocol and input differences to §4 so that the comparison is fully transparent. revision: yes
Circularity Check
No circularity: empirical coverage comparison rests on external baseline and independent execution
full rationale
The paper's core contribution is an empirical demonstration that ConCovUp raises average SMAP Coverage from 36.6% to 68.1% versus the Claude Code agent baseline across nine C/C++ libraries. This result is obtained by running the generated test drivers under dynamic analysis (TSan) and measuring shared-memory access pair coverage; no equations, fitted parameters, or self-citations are invoked to derive or force the reported numbers. The framework description (static analysis for calling contexts, LLM backward tracing, dynamic feedback loop) is presented as an engineering design whose effectiveness is validated by direct measurement against an independent external agent, not by any reduction to the authors' own prior definitions or fitted inputs. Consequently the derivation chain contains no self-definitional, fitted-input, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ConCovUp grounds test generation in static analysis to extract shared memory accesses and their calling contexts... LLM-driven backward tracing... iterative refinement via dynamic execution feedback.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
improves average Shared Memory Access Pair Coverage (SMAP Coverage) from 36.6% to 68.1%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cristian Cadar, Daniel Dunbar, and Dawson R. Engler. 2008. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs. In8th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2008, December 8-10, 2008, San Diego, California, USA, Proceedings, Richard Draves and Robbert van Renesse (Eds.). USENIX Assoc...
work page 2008
-
[2]
Yuandao Cai, Peisen Yao, and Charles Zhang. 2021. Canary: practical static detection of inter-thread value-flow bugs. InPLDI ’21: 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual Event, Canada, June 20-25, 2021, Stephen N. Freund and Eran Yahav (Eds.). ACM, 1126–1140. https://doi.org/10.1145/3453483.3454099
-
[3]
Yuandao Cai, Chengfeng Ye, Qingkai Shi, and Charles Zhang. 2022. Peahen: fast and precise static deadlock detection via context reduction. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022, Abhik Roychoudhury, Cris...
-
[4]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. ChatUniTest: A Framework for LLM-Based Test Generation. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering(Porto de Galinhas, Brazil)(FSE 2024). Association for Computing Machinery, New York, NY, USA, 572–576. http...
-
[5]
Yiu Wai Chow, Max Schäfer, and Michael Pradel. 2023. Beware of the Unexpected: Bimodal Taint Analysis.CoRRabs/2301.10545 (2023). https://doi.org/10.48550/ARXIV.2301.10545 arXiv:2301.10545
-
[6]
Cormac Flanagan and Stephen N. Freund. 2009. FastTrack: efficient and precise dynamic race detection. InProceedings of the 30th ACM SIGPLAN Conference on Programming Language Design and Implementation(Dublin, Ireland)(PLDI ’09). Association for Computing Machinery, New York, NY, USA, 121–133. https://doi.org/10.1145/1542476.1542490
-
[7]
Sishuai Gong, Dinglan Peng, Deniz Altınbüken, Pedro Fonseca, and Petros Maniatis. 2023. Snowcat: Efficient Kernel Concurrency Testing using a Learned Coverage Predictor. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). Association for Computing Machinery, New York, NY, USA, 35–51. https://doi.org/10.1145/360...
-
[8]
Yuqi Guo, Shihao Zhu, Yan Cai, Liang He, and Jian Zhang. 2024. Reorder Pointer Flow in Sound Concurrency Bug Prediction. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 19:1–19:13. https: //doi.org/10.1145/3597503.3623300
-
[9]
Shin Hong, Jaemin Ahn, Sangmin Park, Moonzoo Kim, and Mary Jean Harrold. 2012. Testing concurrent programs to achieve high synchronization coverage. InInternational Symposium on Software Testing and Analysis, ISSTA 2012, Minneapolis, MN, USA, July 15-20, 2012, Mats Per Erik Heimdahl and Zhendong Su (Eds.). ACM, 210–220. https://doi.org/10.1145/2338965.2336779
-
[10]
Jeff Huang. 2015. Stateless model checking concurrent programs with maximal causality reduction. InProceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, Portland, OR, USA, June 15-17, 2015, David Grove and Stephen M. Blackburn (Eds.). ACM, 165–174. https://doi.org/10.1145/2737924.2737975
-
[11]
Jeff Huang. 2016. Scalable thread sharing analysis. InProceedings of the 38th International Conference on Software Engineering, ICSE 2016, Austin, TX, USA, May 14-22, 2016, Laura K. Dillon, Willem Visser, and Laurie A. Williams (Eds.). ACM, 1097–1108. https://doi.org/10.1145/2884781.2884811
-
[12]
Jeff Huang, Patrick O’Neil Meredith, and Grigore Rosu. 2014. Maximal sound predictive race detection with control flow abstraction. InACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11, 2014, Michael F. P. O’Boyle and Keshav Pingali (Eds.). ACM, 337–348. https://doi.org/10.1145/2594...
-
[13]
Jeff Huang and Arun K. Rajagopalan. 2016. Precise and maximal race detection from incomplete traces. InProceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2016, part of SPLASH 2016, Amsterdam, The Netherlands, October 30 - November 4, 2016, Eelco Visser and Yannis Smarag...
-
[14]
Ao Li, Byeongjee Kang, Vasudev Vikram, Isabella Laybourn, Samvid Dharanikota, Shrey Tiwari, and Rohan Padhye. 2025. Fray: An Efficient General-Purpose Concurrency Testing Platform for the JVM.Proc. ACM Program. Lang.9, OOPSLA2, Article 417 (Oct. 2025), 29 pages. https: //doi.org/10.1145/3764119
-
[15]
Jinwei Liu, Chao Li, Rui Chen, Shaofeng Li, Bin Gu, and Mengfei Yang. 2025. STRUT: Structured Seed Case Guided Unit Test Generation for C Programs using LLMs.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA093 (June 2025), 23 pages. https://doi.org/10.1145/3728970
-
[16]
Andrea Lops, Fedelucio Narducci, Azzurra Ragone, and Michelantonio Trizio. 2024. AgoneTest: Automated creation and assessment of Unit tests leveraging Large Language Models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New York, NY, USA, 24...
-
[17]
Zhengxiong Luo, Huan Zhao, Dylan Wolff, Cristian Cadar, and Abhik Roychoudhury. 2026. Agentic Concolic Execution. InProceedings of the 47th IEEE Symposium on Security and Privacy (S&P). IEEE. Manuscript submitted to ACM 20 Yuandao Cai, Shuhao Fu, et al
work page 2026
-
[18]
Moonshot AI. 2026. Kimi K2.5: Visual Agentic Intelligence. https://github.com/MoonshotAI/Kimi-K2.5 Accessed: May 4, 2026
work page 2026
-
[19]
Suvam Mukherjee, Pantazis Deligiannis, Arpita Biswas, and Akash Lal. 2020. Learning-based controlled concurrency testing.Proc. ACM Program. Lang.4, OOPSLA, Article 230 (Nov. 2020), 31 pages. https://doi.org/10.1145/3428298
-
[20]
Zifan Nan, Zhaoqiang Guo, Kui Liu, and Xin Xia. 2025. Test Intention Guided LLM-Based Unit Test Generation. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 1026–1038. https://doi.org/10.1109/ICSE55347. 2025.00243
-
[21]
Rangeet Pan, Myeongsoo Kim, Rahul Krishna, Raju Pavuluri, and Saurabh Sinha. 2025. ASTER: Natural and Multi-Language Unit Test Generation with LLMs. In47th IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice, SEIP@ICSE 2025, Ottawa, ON, Canada, April 27 - May 3, 2025. IEEE, 413–424. https://doi.org/10.1109/ICSE-SEIP...
-
[22]
Juan Altmayer Pizzorno and Emery D. Berger. 2025. CoverUp: Effective High Coverage Test Generation for Python.Proc. ACM Softw. Eng.2, FSE (2025), 2897–2919. https://doi.org/10.1145/3729398
-
[23]
Malavika Samak and Murali Krishna Ramanathan. 2014. Multithreaded test synthesis for deadlock detection. InProceedings of the 2014 ACM International Conference on Object Oriented Programming Systems Languages & Applications, OOPSLA 2014, part of SPLASH 2014, Portland, OR, USA, October 20-24, 2014, Andrew P. Black and Todd D. Millstein (Eds.). ACM, 473–489...
-
[24]
Malavika Samak and Murali Krishna Ramanathan. 2015. Synthesizing tests for detecting atomicity violations. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, Bergamo, Italy, August 30 - September 4, 2015, Elisabetta Di Nitto, Mark Harman, and Patrick Heymans (Eds.). ACM, 131–142. https://doi.org/10.1145/278...
-
[25]
Malavika Samak, Murali Krishna Ramanathan, and Suresh Jagannathan. 2015. Synthesizing racy tests. InProceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, Portland, OR, USA, June 15-17, 2015, David Grove and Stephen M. Blackburn (Eds.). ACM, 175–185. https://doi.org/10.1145/2737924.2737998
-
[26]
Malavika Samak, Omer Tripp, and Murali Krishna Ramanathan. 2016. Directed synthesis of failing concurrent executions. InProceedings of the 2016 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2016, part of SPLASH 2016, Amsterdam, The Netherlands, October 30 - November 4, 2016, Eelco Visser ...
-
[27]
Shiqi Shen, Shweta Shinde, Soundarya Ramesh, Abhik Roychoudhury, and Prateek Saxena. 2019. Neuro-Symbolic Execution: Augmenting Symbolic Execution with Neural Constraints. In26th Annual Network and Distributed System Security Symposium, NDSS 2019, San Diego, California, USA, February 24-27, 2019. The Internet Society. https://www.ndss-symposium.org/ndss-p...
work page 2019
-
[28]
Qingkai Shi, Xiao Xiao, Rongxin Wu, Jinguo Zhou, Gang Fan, and Charles Zhang. 2018. Pinpoint: fast and precise sparse value flow analysis for million lines of code. InProceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2018, Philadelphia, PA, USA, June 18-22, 2018, Jeffrey S. Foster and Dan Grossman (Eds....
-
[29]
Yao Shi, Soyeon Park, Zuoning Yin, Shan Lu, Yuanyuan Zhou, Wenguang Chen, and Weimin Zheng. 2010. Do I use the wrong definition?: DeFuse: definition-use invariants for detecting concurrency and sequential bugs. InProceedings of the 25th Annual ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2010, October...
-
[30]
Terminal-Bench. 2026. terminal-bench@2.0 Leaderboard. https://www.tbench.ai/leaderboard/terminal-bench/2.0 Accessed: April 18, 2026
work page 2026
-
[31]
Valerio Terragni and Shing-Chi Cheung. 2016. Coverage-driven test code generation for concurrent classes. InProceedings of the 38th International Conference on Software Engineering(Austin, Texas)(ICSE ’16). Association for Computing Machinery, New York, NY, USA, 1121–1132. https: //doi.org/10.1145/2884781.2884876
-
[32]
Mosaad Al Thokair, Minjian Zhang, Umang Mathur, and Mahesh Viswanathan. 2023. Dynamic Race Detection with O(1) Samples.Proc. ACM Program. Lang.7, POPL (2023), 1308–1337. https://doi.org/10.1145/3571238
-
[33]
David Trabish, Timotej Kapus, Noam Rinetzky, and Cristian Cadar. 2020. Past-sensitive pointer analysis for symbolic execution. InESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, November 8-13, 2020, Prem Devanbu, Myra B. Cohen, and Thomas Zimmermann (Eds.). ...
-
[34]
Wenwen Wang, Zhenjiang Wang, Chenggang Wu, Pen-Chung Yew, Xipeng Shen, Xiang Yuan, Jianjun Li, Xiaobing Feng, and Yong Guan
-
[35]
Localization of concurrency bugs using shared memory access pairs. InProceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering(Vasteras, Sweden)(ASE ’14). Association for Computing Machinery, New York, NY, USA, 611–622. https: //doi.org/10.1145/2642937.2642972
-
[36]
Zejun Wang, Kaibo Liu, Ge Li, and Zhi Jin. 2024. HITS: High-coverage LLM-based Unit Test Generation via Method Slicing. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New York, NY, USA, 1258–1268. https://doi.org/10.1145/3691620.3695501
-
[37]
Cheng Wen, Mengda He, Bohao Wu, Zhiwu Xu, and Shengchao Qin. 2022. Controlled Concurrency Testing via Periodical Scheduling. In 44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 474–486. https: //doi.org/10.1145/3510003.3510178 Manuscript submitted to ACM ConCovUp: Effective Agent-Ba...
-
[38]
Duck, Umang Mathur, and Abhik Roychoudhury
Dylan Wolff, Zheng Shi, Gregory J. Duck, Umang Mathur, and Abhik Roychoudhury. 2024. Greybox Fuzzing for Concurrency Testing. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS 2024, La Jolla, CA, USA, 27 April 2024- 1 May 2024, Rajiv Gupta, Nael B. Abu-Ghazaleh...
-
[39]
Minjian Zhang, Daniel Wee Soong Lim, Mosaad Al Thokair, Umang Mathur, and Mahesh Viswanathan. 2025. Efficient Timestamping for Sampling- Based Race Detection.Proc. ACM Program. Lang.9, PLDI (2025), 150–175. https://doi.org/10.1145/3729252
-
[40]
Mingwei Zheng, Danning Xie, Qingkai Shi, Chengpeng Wang, and Xiangyu Zhang. 2025. Validating Network Protocol Parsers with Traceable RFC Document Interpretation.Proc. ACM Softw. Eng.2, ISSTA (2025), 1772–1794. https://doi.org/10.1145/3728955
-
[41]
Shihao Zhu, Yuqi Guo, Yan Cai, Bin Liang, Long Zhang, Rui Chen, and Tingting Yu. 2025. Reduce Dependence for Sound Concurrency Bug Prediction. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 242–254. https://doi.org/10.1109/ICSE55347.2025.00149
-
[42]
Shihao Zhu, Yuqi Guo, Long Zhang, and Yan Cai. 2023. Tolerate Control-Flow Changes for Sound Data Race Prediction. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 1342–1354. https://doi.org/10.1109/ICSE48619.2023.00118 A SIMPLIFIED SKILLS This section lists simplified skills used fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.