Recognition: 1 theorem link
· Lean TheoremBiosignal Fingerprinting: A Cross-Modal PPG-ECG Foundation Model
Pith reviewed 2026-05-12 02:37 UTC · model grok-4.3
The pith
A cross-modal model trained on 3.4 million paired ECG-PPG signals produces compact biosignal fingerprints that match or exceed specialist models on seven clinical tasks in frozen single-modality settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
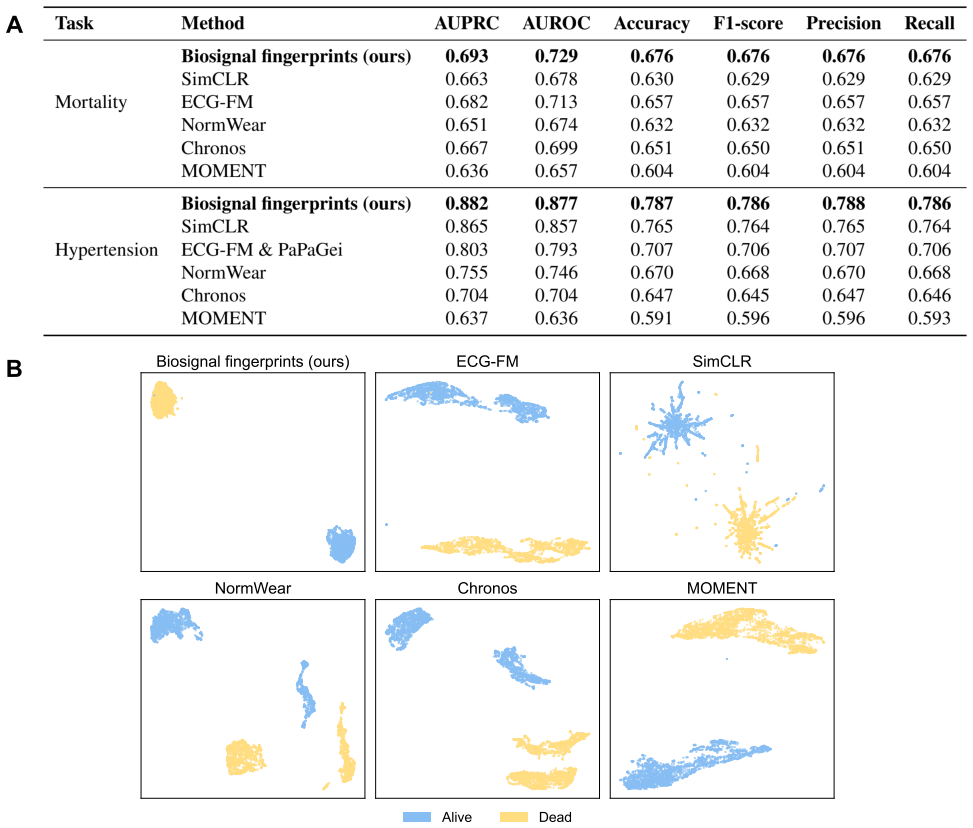
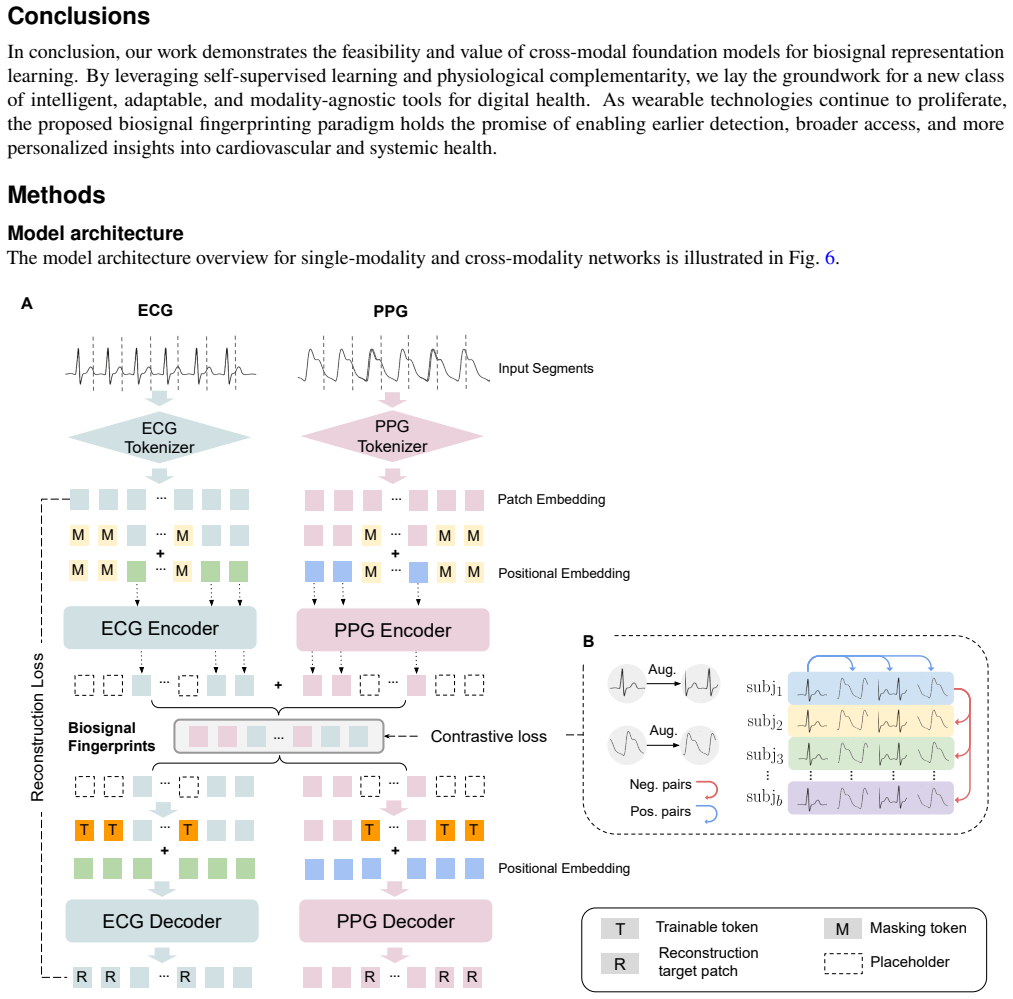
The central claim is that the Multi-modal Masked Autoencoder (M2AE), with modality-specific encoders, a shared bottleneck, and dual decoders, jointly optimized by reconstruction and cross-modal contrastive objectives on over 3.4 million paired ECG-PPG signals, yields generalizable fingerprints that retain both intra- and inter-modality information; these fingerprints deliver an AUROC of 0.974 on five-class CVD classification and 0.877 on hypertension detection, with up to 27.7 percent AUROC gains across five classification tasks relative to leading domain-specialist foundation models when used frozen on single-modality inputs.
What carries the argument
Biosignal fingerprints are the compact latent vectors produced at the shared bottleneck of the M2AE after joint reconstruction and cross-modal contrastive training; they serve as modality-agnostic encodings of cardiovascular state that can be extracted from either ECG or PPG alone.
If this is right
- Enables continuous cardiovascular monitoring on single-sensor wearables that supply only PPG without requiring ECG hardware or model updates.
- Supports privacy-preserving workflows because downstream tasks operate on the compact fingerprints rather than raw waveforms.
- Allows a single pretrained model to handle diverse tasks including disease classification, mortality prediction, and demographic inference without per-task retraining.
- Maintains competitive accuracy in resource-limited clinical or consumer settings where only one signal modality is available.
Where Pith is reading between the lines
- The same cross-modal pretraining strategy could be tested on other paired physiological signals such as EEG with EOG to create unified representations for broader neurological monitoring.
- If fingerprints prove stable across global populations, they might reduce the data collection burden for training new clinical models by leveraging existing paired datasets.
- Deployment on streaming wearable data would test whether the representations support real-time alerts without periodic model updates.
Load-bearing premise
Cross-modal training on paired ECG and PPG produces representations that stay effective and generalizable when applied to single-modality inputs from new devices or populations without any task-specific retraining.
What would settle it
A clear performance drop, such as AUROC falling below 0.85 on the five-class CVD task, when fingerprints extracted from PPG signals collected on an unseen device or from a held-out population are fed into the frozen downstream classifiers.
Figures




read the original abstract
Cardiovascular disease remains the leading cause of global mortality, yet scalable cardiac monitoring is hindered by the gap between diagnostic-rich ECG and ubiquitous wearable PPG. Bridging this gap requires representations that are compact, transferable across modalities and devices, and deployable without task-specific retraining. Here we introduce biosignal fingerprints: compact latent representations of cardiovascular state derived from a cross-modal foundation model, the Multi-modal Masked Autoencoder (M2AE), trained on over 3.4 million paired ECG and PPG signals. M2AE integrates modality-specific encoders with a shared bottleneck and dual decoders, jointly optimized using reconstruction and cross-modal contrastive objectives, yielding generalizable fingerprints that retain intra- and inter-modality features. Like a biometric fingerprint, these representations uniquely encode an individual's cardiovascular state in a modality-agnostic, privacy-preserving form reusable across clinical tasks without exposing raw waveform data or requiring model retraining. Across 7 downstream tasks, spanning cross-modal reconstruction, cardiovascular disease classification, hypertension detection, mortality prediction, and demographic inference, biosignal fingerprints achieve competitive or superior performance compared to leading domain-specialist foundation models in frozen settings, including an AUROC of 0.974 for five-class CVD classification and 0.877 for hypertension detection, with a maximum improvement of 27.7% in AUROC across 5 classification tasks. Critically, strong performance is maintained with only a single modality, enabling deployment in resource-constrained, single-sensor environments typical of real-world wearable monitoring, with direct implications for continuous cardiovascular monitoring across clinical and consumer health settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces biosignal fingerprints as compact latent representations generated by a Multi-modal Masked Autoencoder (M2AE) trained on over 3.4 million paired ECG-PPG signals. The model uses modality-specific encoders, a shared bottleneck, and dual decoders optimized with reconstruction and cross-modal contrastive losses. It claims these fingerprints are modality-agnostic and privacy-preserving, achieving competitive or superior frozen performance across 7 downstream tasks (cross-modal reconstruction, 5-class CVD classification with AUROC 0.974, hypertension detection with AUROC 0.877, mortality prediction, and demographic inference), with up to 27.7% AUROC improvement over leading domain-specialist foundation models, and strong results maintained on single-modality inputs.
Significance. If the generalization and performance claims hold under rigorous evaluation, the work has substantial significance for scalable, privacy-preserving cardiovascular monitoring. It could enable high-accuracy models deployable on ubiquitous single-sensor wearables by leveraging richer paired ECG-PPG data only during pretraining, addressing a key gap between diagnostic and consumer-grade biosignals. The cross-modal contrastive and reconstruction objectives represent a promising direction for modality-agnostic representations.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Setup): The reported AUROCs (e.g., 0.974 for five-class CVD, 0.877 for hypertension) and maximum 27.7% improvement lack any description of dataset splits, baseline implementations, statistical testing, error bars, or controls for data leakage between pretraining and downstream tasks. This is load-bearing for the central superiority claim, as the numbers cannot be assessed for robustness or validity without these details.
- [§5] §5 (Downstream Tasks and Generalization): The evaluation protocol provides no experiments testing distribution shifts across devices, populations, or recording conditions. The architecture (modality-specific encoders + shared bottleneck) and losses do not demonstrably enforce device- or population-invariant features, so the claim that single-modality fingerprints remain effective on new inputs without retraining is unsupported and central to the deployability argument.
minor comments (2)
- [§3] The term 'biosignal fingerprints' is introduced without a precise mathematical definition or comparison to standard embedding terminology; clarify in §3 whether it denotes the bottleneck output or a post-processed representation.
- [Figure 1] Figure 1 (model diagram) and associated text would benefit from explicit notation for the contrastive loss temperature parameter and how cross-modal pairs are sampled.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the presentation of our results. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Setup): The reported AUROCs (e.g., 0.974 for five-class CVD, 0.877 for hypertension) and maximum 27.7% improvement lack any description of dataset splits, baseline implementations, statistical testing, error bars, or controls for data leakage between pretraining and downstream tasks. This is load-bearing for the central superiority claim, as the numbers cannot be assessed for robustness or validity without these details.
Authors: We agree these methodological details are essential. The full manuscript describes the pretraining split as 70/15/15 on the 3.4M paired signals in §4.1, with downstream tasks evaluated on completely held-out cohorts from distinct sources (MIMIC-IV, PhysioNet, and wearable datasets) to prevent leakage; baselines follow original implementations as detailed in §4.2 and Appendix B; and results include means and standard deviations over five random seeds in Table 2, with DeLong tests for AUROC comparisons. However, we acknowledge the need for greater explicitness. We will add a dedicated subsection 'Evaluation Protocol, Statistical Analysis, and Leakage Controls' to §4 that consolidates these elements, reports exact p-values, and ensures error bars appear in the abstract and main figures. This revision will be made. revision: yes
-
Referee: [§5] §5 (Downstream Tasks and Generalization): The evaluation protocol provides no experiments testing distribution shifts across devices, populations, or recording conditions. The architecture (modality-specific encoders + shared bottleneck) and losses do not demonstrably enforce device- or population-invariant features, so the claim that single-modality fingerprints remain effective on new inputs without retraining is unsupported and central to the deployability argument.
Authors: We concur that explicit distribution-shift experiments would better support the deployability claims. Our pretraining corpus already aggregates signals from hospital-grade ECG monitors and multiple consumer PPG wearables across adult populations, and the cross-modal contrastive objective plus shared bottleneck are intended to promote invariance to modality-specific noise. Nevertheless, we did not include dedicated ablations on device or demographic shifts. In the revision we will add a new subsection §5.4 that evaluates the frozen single-modality model on an external test set drawn from a different recording device and population (e.g., a separate wearable cohort), reporting the resulting AUROC retention. We will also qualify the generalization language in the abstract and §5 to reflect the scope of the current evidence while highlighting the architectural inductive biases. This constitutes a partial revision; if the additional experiment cannot be completed within the revision window we will instead temper the claims. revision: partial
Circularity Check
No significant circularity; performance claims rest on held-out empirical evaluation rather than tautological reduction to inputs.
full rationale
The paper describes training an M2AE model on 3.4M paired ECG-PPG signals using reconstruction and contrastive losses, then reports AUROC metrics on 7 downstream tasks in frozen single-modality settings. No equations, derivations, or first-principles predictions are presented that reduce by construction to fitted parameters or self-citations. The reported numbers (e.g., 0.974 AUROC for CVD classification) are measured on separate held-out evaluation protocols, not generated as direct outputs of the training objectives themselves. No self-definitional steps, fitted-input-as-prediction patterns, or load-bearing self-citation chains appear in the provided text. The central claims therefore remain independent of the training data in the required sense.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of deep representation learning: that reconstruction and contrastive objectives on large paired datasets produce transferable latent features.
invented entities (1)
-
biosignal fingerprints
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
jointly optimized using reconstruction and cross-modal contrastive objectives... InfoNCE loss... L^c = L^c_contrast + λ L^c_recon
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Clifford, G. D.et al.Af classification from a short single lead ecg recording: The physionet/computing in cardiology challenge 2017. In2017 computing in cardiology (CinC), 1–4 (IEEE, 2017). 2.Charlton, P. H.et al.Wearable photoplethysmography for cardiovascular monitoring.Proc. IEEE110, 355–381 (2022)
work page 2017
-
[2]
Gu, X.et al.Transforming label-efficient decoding of healthcare wearables with self-supervised learning and "embedded" medical domain expertise.Commun. Eng.4, 135, DOI: 10.1038/s44172-025-00467-6 (2025). 4.Ribeiro, A. H.et al.Automatic diagnosis of the 12-lead ecg using a deep neural network.Nat. communications11, 1760 (2020). 1https://github.com/pulselab...
-
[3]
Neri, L.et al.Electrocardiogram monitoring wearable devices and artificial-intelligence-enabled diagnostic capabilities: a review.Sensors23, 4805 (2023)
work page 2023
-
[4]
Kim, K. B. & Baek, H. J. Photoplethysmography in wearable devices: a comprehensive review of technological advances, current challenges, and future directions.Electronics12, 2923 (2023)
work page 2023
-
[5]
Loh, H. W.et al.Application of photoplethysmography signals for healthcare systems: An in-depth review.Comput. Methods Programs Biomed.216, 106677 (2022). 8.Pereira, T.et al.Photoplethysmography based atrial fibrillation detection: a review.NPJ digital medicine3, 3 (2020)
work page 2022
-
[6]
Liu, Z., Zhu, T., Lu, L., Zhang, Y.-t. & Clifton, D. A. Intelligent electrocardiogram acquisition via ubiquitous photoplethysmography monitoring.IEEE J. Biomed. Heal. Informatics28, 1321–1330 (2023)
work page 2023
-
[7]
Gu, X.et al.Cardiac health assessment across scenarios and devices using a multimodal foundation model pretrained on data from 1.7 million individuals.Nat. Mach. Intell.8, 220–233 (2026)
work page 2026
-
[8]
neural information processing systems33, 1877–1901 (2020)
Brown, T.et al.Language models are few-shot learners.Adv. neural information processing systems33, 1877–1901 (2020)
work page 1901
-
[9]
On the Opportunities and Risks of Foundation Models
He, K.et al.Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16000–16009 (2022). 13.Bommasani, R.et al.On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Mathew, G., Barbosa, D., Prince, J. & Venkatraman, S. Foundation models for cardiovascular disease detection via biosignals from digital stethoscopes.npj Cardiovasc. Heal.1, 25 (2024)
work page 2024
-
[11]
Health-llm: Large language models for health prediction via wearable sensor data,
Kim, Y., Xu, X., McDuff, D., Breazeal, C. & Park, H. W. Health-llm: Large language models for health prediction via wearable sensor data.arXiv preprint arXiv:2401.06866(2024)
-
[12]
Vaid, A.et al.A foundational vision transformer improves diagnostic performance for electrocardiograms.NPJ Digit. Medicine6, 108 (2023)
work page 2023
- [13]
-
[14]
Ding, C.et al.Siamquality: a convnet-based foundation model for photoplethysmography signals.Physiol. Meas.45, 085004 (2024)
work page 2024
-
[15]
InProceedings of the Twelfth International Conference on Learning Representations(2024)
Abbaspourazad, S.et al.Large-scale training of foundation models for wearable biosignals. InProceedings of the Twelfth International Conference on Learning Representations(2024)
work page 2024
-
[16]
Luo, Y., Chen, Y., Salekin, A. & Rahman, T. Toward foundation model for multivariate wearable sensing of physiological signals (2025). 2412.09758
-
[17]
Gu, X., Shu, Y., Han, J., Liu, Y.et al.Foundation models for biosignals: A survey.TechRxivDOI: 10.36227/techrxiv. 175606236.62808131 (2025)
- [18]
-
[19]
Kiyasseh, D., Zhu, T. & Clifton, D. A. CLOCS: Contrastive learning of cardiac signals across space, time, and patients. In Proceedings of the 38th International Conference on Machine Learning(PMLR, 2021)
work page 2021
- [20]
-
[21]
Ecg-fm: An open electrocardiogram foundation model,
Chen,T.,Kornblith,S.,Sohl-Dickstein,J.,Hinton,G.&Norouzi,M. Bigself-supervisedmodelsarestrongsemi-supervised learners.Adv. Neural Inf. Process. Syst.33, 22243–22255 (2020). 26.McKeen, K.et al.Ecg-fm: An open electrocardiogram foundation model (2024). 2408.05178
-
[22]
Pillai, A., Spathis, D., Kawsar, F. & Malekzadeh, M. Papagei: Open foundation models for optical physiological signals (2025). 2410.20542. 28.Ansari, A. F.et al.Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815(2024). 29.Goswami, M.et al.Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885(2024)
-
[23]
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning(2020). 15/21
work page 2020
-
[24]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J. & Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Becht, E.et al.Dimensionality reduction for visualizing single-cell data using UMAP.Nat. Biotechnol.37, 38–44 (2019)
work page 2019
-
[26]
Mimic-iii, a freely accessible critical care database
Johnson, A. E.et al.Mimic-iii, a freely accessible critical care database.Sci. Data3, DOI: 10.1038/sdata.2016.35 (2016). [Online; accessed 2025-05-29]
-
[27]
Wang, W., Mohseni, P., Kilgore, K. L. & Najafizadeh, L. Pulsedb: A large, cleaned dataset based on mimic-iii and vitaldb for benchmarking cuff-less blood pressure estimation methods.Front. Digit. Heal.4, 1090854 (2023). 35.Wagner, P.et al.PTB-XL, a large publicly available electrocardiography dataset.Sci. Data7, 154 (2020)
work page 2023
-
[28]
Ribeiro,A.H.etal.CODE-15%: ALargeScaleAnnotatedDatasetof12-LeadECGs(1.0.0),DOI:10.5281/zenodo.4916206 (2021). Data set
-
[29]
Goldberger, A. L.et al.Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals.Circulation101, E215–20, DOI: 10.1161/01.cir.101.23.e215 (2000). [Online; accessed 2025-05-29]
-
[30]
Liu, Z.et al.Patient clustering for vital organ failure using ICD code with graph attention.IEEE Transactions on Biomed. Eng.70, 2329–2337 (2023)
work page 2023
-
[31]
Zacarías-Pons, L., Vilanova, M. B., Lluis-Ganella, C.et al.Performance of the Framingham and SCORE cardiovascular risk prediction functions in a non-diabetic population of a Spanish health care centre: a validation study.BMC Fam. Pract. 11, 67 (2010)
work page 2010
-
[32]
Li, Y., Shen, L., Gao, X.et al.Comparison of the Framingham Risk Score, SCORE and WHO/ISH cardiovascular risk prediction models in an Asian population.Int. J. Cardiol.168, 1696–1700 (2014)
work page 2014
-
[33]
Radhakrishnan, A.et al.Cross-modal autoencoder framework learns holistic representations of cardiovascular state.Nat. Commun.14, 2436 (2023)
work page 2023
-
[34]
Lai, J.et al.Practical intelligent diagnostic algorithm for wearable 12-lead ECG via self-supervised learning on large-scale dataset.Nat. Commun.14, 3741 (2023). 43.Xu, J.et al.Federated learning for healthcare informatics.J. Healthc. Informatics Res.5, 1–19 (2021)
work page 2023
-
[35]
Dosovitskiy, A.et al.An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[36]
V.et al.Large-scale assessment of a smartwatch to identify atrial fibrillation.New Engl
Perez, M. V.et al.Large-scale assessment of a smartwatch to identify atrial fibrillation.New Engl. J. Medicine381, 1909–1917 (2019)
work page 1909
-
[37]
Goldberger, A. L., Goldberger, Z. D. & Shvilkin, A.Goldberger’s Clinical Electrocardiography-E-Book: A Simplified Approach(Elsevier Health Sciences, 2023). 47.Ramkumar, S.et al.Atrial fibrillation detection using single lead portable electrocardiographic monitoring: a systematic review and meta-analysis.BMJ open8, e024178 (2018)
work page 2023
-
[38]
Hannun, A. Y.et al.Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network.Nat. medicine25, 65–69 (2019)
work page 2019
-
[39]
Makowski, D.et al.Neurokit2: A python toolbox for neurophysiological signal processing.Behav. research methods1–8 (2021). 16/21 S1 Method-related Supplementary Material S1.1 Algorithm of signal augmentation strategy The signal augmentation strategy applied during cross-modal contrastive learning (Fig. 6B) is described in Algorithm 1. Algorithm 1Signal Aug...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.