Recognition: no theorem link
From Pixels to Concepts: Do Segmentation Models Understand What They Segment?
Pith reviewed 2026-05-12 03:07 UTC · model grok-4.3
The pith
Promptable segmentation models often output accurate masks even for misleading prompts
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
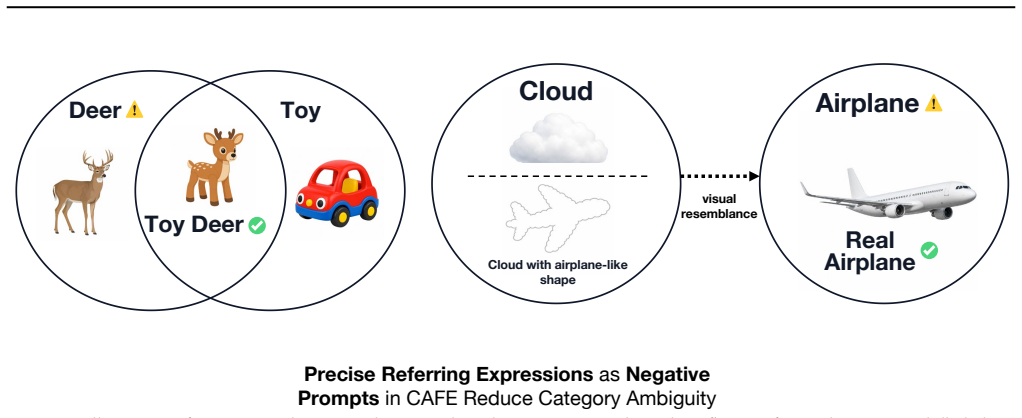
The central discovery is that there exists a systematic gap between how well models localize objects and how well they discriminate the actual concepts in prompts. This is shown through the CAFE benchmark consisting of 2146 paired samples across three types of counterfactual attribute changes: superficial mimicry, context conflict, and ontological conflict. Models generate accurate masks for negative prompts in many cases, proving that mask accuracy alone does not confirm faithful concept grounding.
What carries the argument
The CAFE benchmark, which creates test cases through attribute-level counterfactual manipulation that preserves the ground-truth mask but changes semantic attributes to generate misleading prompts.
Load-bearing premise
The counterfactual manipulations of attributes preserve the target region and ground-truth mask while introducing misleading semantic cues without confounding changes to object identity or saliency.
What would settle it
Observing that a given model produces substantially lower quality masks specifically for the misleading prompts on the CAFE test set, rather than accurate ones, would indicate the gap does not exist as claimed.
Figures







read the original abstract
Segmentation is a fundamental vision task underlying numerous downstream applications. Recent promptable segmentation models, such as Segment Anything Model 3 (SAM3), extend segmentation from category-agnostic mask prediction to concept-guided localization conditioned on high-level textual prompts. However, existing benchmarks primarily evaluate mask accuracy or object presence, leaving unclear whether these models faithfully ground the queried concept or instead rely on visually salient but semantically misleading cues. We introduce CAFE: \textbf{C}ounterfactual \textbf{A}ttribute \textbf{F}actuality \textbf{E}valuation, a novel benchmark for evaluating concept-faithful segmentation in promptable segmentation models. Our \textbf{CAFE} is built on attribute-level counterfactual manipulation: the target region and ground-truth mask are preserved, while attributes such as surface appearance, context, or material composition are modified to introduce misleading semantic cues. The benchmark contains 2,146 paired test samples, each consisting of a target image, a ground-truth mask, a positive prompt, and a misleading negative prompt. These samples cover three counterfactual categories: Superficial Mimicry (\textbf{SM}), Context Conflict (\textbf{CC}), and Ontological Conflict (\textbf{OC}). We evaluate various model types and sizes on our CAFE. Experiments reveal a systematic gap between localization quality and concept discrimination: models often generate accurate masks even for misleading prompts, suggesting that strong mask prediction does not necessarily imply faithful semantic grounding. Our CAFE provides a controlled benchmark for diagnosing whether promptable segmentation models perform concept-faithful grounding rather than shortcut-driven mask retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAFE, a benchmark of 2,146 paired samples for testing concept-faithful segmentation in promptable models such as SAM3. Samples are created via attribute-level counterfactual manipulations (Superficial Mimicry, Context Conflict, Ontological Conflict) that preserve the target region and ground-truth mask while modifying surface appearance, context, or material to generate misleading negative prompts. Experiments demonstrate that models frequently produce accurate masks even for negative prompts, indicating a systematic gap between localization quality and semantic grounding.
Significance. If the counterfactuals are shown to be valid, CAFE offers a controlled diagnostic for distinguishing shortcut-driven mask prediction from true concept understanding in segmentation models. This addresses a gap in existing benchmarks focused only on mask accuracy or presence, and could inform development of more semantically grounded promptable models. The scale and categorization into three conflict types are strengths for systematic evaluation.
major comments (2)
- [CAFE Benchmark Construction] The central claim—that strong mask prediction does not imply faithful semantic grounding—depends on the counterfactual edits preserving the exact target region and ground-truth mask while introducing only the intended misleading semantic cues without confounding changes to visual saliency, object identity, or low-level features (e.g., texture gradients or boundary contrast). The manuscript describes the construction of 2,146 pairs across SM/CC/OC but provides no details on the sample creation process, inter-annotator agreement, human verification of identity preservation, or quantitative checks (such as saliency metrics or feature similarity between positive/negative pairs). Without these, the observed gap cannot be cleanly attributed to lack of concept grounding rather than robustness to the edits. See the CAFE benchmark description and experimental setup.
- [Experiments] Table or figure reporting per-category results (e.g., mask IoU on positive vs. negative prompts) should include controls or ablations demonstrating that the attribute manipulations do not alter the core object in ways that affect mask prediction independently of the prompt. The current high-level outcome leaves open whether the gap reflects semantic failure or edit-induced feature invariance.
minor comments (3)
- [Abstract] The abstract states evaluation on 'various model types and sizes' but does not list the specific models (e.g., SAM variants, other promptable segmentors); this should be added for reproducibility.
- Consider adding a table or figure with example positive/negative prompt pairs and corresponding masks for each of the three categories (SM, CC, OC) to illustrate the manipulations.
- [Related Work] Ensure all citations to related work on counterfactual evaluation in vision and language grounding are included and discussed in the related work section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of benchmark validity and experimental rigor. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [CAFE Benchmark Construction] The central claim—that strong mask prediction does not imply faithful semantic grounding—depends on the counterfactual edits preserving the exact target region and ground-truth mask while introducing only the intended misleading semantic cues without confounding changes to visual saliency, object identity, or low-level features (e.g., texture gradients or boundary contrast). The manuscript describes the construction of 2,146 pairs across SM/CC/OC but provides no details on the sample creation process, inter-annotator agreement, human verification of identity preservation, or quantitative checks (such as saliency metrics or feature similarity between positive/negative pairs). Without these, the observed gap cannot be cleanly attributed to lack of concept grounding rather than robustness to the edits. See the CAFE benchmark description and experimental setup.
Authors: We agree that explicit documentation of the construction process is necessary to support the validity of the counterfactuals. In the revised manuscript, we will substantially expand the CAFE Benchmark Construction section with: (1) a detailed step-by-step account of how attribute-level manipulations were performed for each category (Superficial Mimicry, Context Conflict, Ontological Conflict) while preserving the target region and ground-truth mask; (2) the protocol for human verification, including that multiple annotators independently confirmed object identity and mask preservation; (3) inter-annotator agreement statistics (e.g., Cohen's kappa); and (4) quantitative controls such as saliency map similarity (using off-the-shelf saliency models) and feature-level comparisons (CLIP embedding cosine similarity and low-level texture/gradient metrics) between positive and negative pairs. These additions will allow readers to assess whether confounding changes were minimized. revision: yes
-
Referee: [Experiments] Table or figure reporting per-category results (e.g., mask IoU on positive vs. negative prompts) should include controls or ablations demonstrating that the attribute manipulations do not alter the core object in ways that affect mask prediction independently of the prompt. The current high-level outcome leaves open whether the gap reflects semantic failure or edit-induced feature invariance.
Authors: We accept this point and will improve the experimental presentation. The revised manuscript will include per-category breakdowns (SM, CC, OC) of mask IoU for both positive and negative prompts in an expanded Table 2 or new supplementary figure. We will also add an ablation study evaluating models on the counterfactual images using neutral prompts (e.g., 'the object' or 'segment the main region') to measure whether the edits affect mask quality independently of the semantic content of the prompt. Additionally, we will report results on a small control subset where only low-level visual features are altered without introducing semantic conflict. These controls will help isolate the contribution of concept grounding versus edit-induced invariance. revision: yes
Circularity Check
No circularity: external benchmark evaluated on public models
full rationale
The paper defines CAFE via manual attribute-level counterfactual edits that preserve target regions and GT masks, then runs off-the-shelf models (SAM3 and variants) on the 2,146 pairs. No parameters are fitted to the test data, no predictions are made from fitted inputs, and no self-citations or uniqueness theorems are invoked to justify the central claim. The reported gap between localization quality and concept discrimination is a direct empirical observation on an independently constructed benchmark, not a reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs.IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017
work page 2017
-
[3]
Masklab: Instance segmentation by refining object detection with semantic and direction features
Liang-Chieh Chen, Alexander Hermans, George Papandreou, Florian Schroff, Peng Wang, and Hartwig Adam. Masklab: Instance segmentation by refining object detection with semantic and direction features. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4013–4022, 2018
work page 2018
-
[4]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
work page 2024
-
[5]
Scaling open-vocabulary image segmentation with image-level labels
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scaling open-vocabulary image segmentation with image-level labels. InEuropean conference on computer vision, pages 540–557. Springer, 2022
work page 2022
-
[6]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019
work page 2019
-
[7]
Simultaneous detection and segmentation
Bharath Hariharan, Pablo Arbeláez, Ross Girshick, and Jitendra Malik. Simultaneous detection and segmentation. InEuropean conference on computer vision, pages 297–312. Springer, 2014
work page 2014
-
[8]
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017
work page 2017
-
[9]
Learning the difference that makes a difference with counterfactually-augmented data
Divyansh Kaushik, Eduard Hovy, and Zachary Lipton. Learning the difference that makes a difference with counterfactually-augmented data. InInternational Conference on Learning Representations. 10
-
[10]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
work page 2014
-
[11]
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Dollár. Panoptic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9404–9413, 2019
work page 2019
-
[12]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023
work page 2023
-
[13]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[14]
Counterfactual fairness.Advances in neural information processing systems, 30, 2017
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness.Advances in neural information processing systems, 30, 2017
work page 2017
-
[15]
Baiqi Li, Zhiqiu Lin, Wenxuan Peng, Jean de Dieu Nyandwi, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna, Graham Neubig, and Deva Ramanan. Naturalbench: Evaluating vision-language models on natural adversarial samples.Advances in Neural Information Processing Systems, 37:17044–17068, 2024
work page 2024
-
[16]
XinzhuoLi,AdheeshJuvekar,XingyouLiu,MuntasirWahed,KietANguyen,andIsminiLourentzou. Hallusegbench: Counterfactual visual reasoning for segmentation hallucination evaluation.arXiv e-prints, pages arXiv–2506, 2025
work page 2025
-
[17]
Counterfactual Segmentation Reasoning: Diagnosing and Mitigating Pixel-Grounding Hallucination
Xinzhuo Li, Adheesh Juvekar, Jiaxun Zhang, Xingyou Liu, Muntasir Wahed, Kiet A Nguyen, Yifan Shen, Tianjiao Yu, and Ismini Lourentzou. Counterfactual segmentation reasoning: Diagnosing and mitigating pixel-grounding hallucination.arXiv preprint arXiv:2506.21546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[19]
Gres: Generalized referring expression segmentation
Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23592–23601, 2023
work page 2023
-
[20]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision, pages 38–55. Springer, 2024
work page 2024
-
[21]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015
work page 2015
-
[22]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016
work page 2016
-
[23]
One-shot instance segmentation
Claudio Michaelis, Ivan Ustyuzhaninov, Matthias Bethge, and Alexander S Ecker. One-shot instance segmentation. arXiv preprint arXiv:1811.11507, 2018
-
[24]
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems, 36:72983–73007, 2023
work page 2023
-
[25]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. InThe Thirteenth International Conference on Learning Representations. 11
-
[26]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Is this generated person existedinreal-world? fine-graineddetectingandcalibratingabnormalhuman-body
Zeqing Wang, Qingyang Ma, Wentao Wan, Haojie Li, Keze Wang, and Yonghong Tian. Is this generated person existedinreal-world? fine-graineddetectingandcalibratingabnormalhuman-body. InProceedingsoftheComputer Vision and Pattern Recognition Conference, pages 21226–21237, 2025
work page 2025
-
[28]
Zeqing Wang, Keze Wang, and Lei Zhang. Phydetex: Detecting and explaining the physical plausibility of t2v models.arXiv preprint arXiv:2512.01843, 2025
-
[29]
Videoverse: How far is your t2v generator from a world model?arXiv preprint arXiv:2510.08398, 2025
ZeqingWang,XinyuWei,BairuiLi,ZhenGuo,JinruiZhang,HongyangWei,KezeWang,andLeiZhang. Videoverse: How far is your t2v generator from a world model?arXiv preprint arXiv:2510.08398, 2025
-
[30]
Zeqing Wang, Shiyuan Zhang, Chengpei Tang, and Keze Wang. Timecausality: Evaluating the causal ability in time dimension for vision language models.arXiv preprint arXiv:2505.15435, 2025
-
[31]
Towards top-down reasoning: An explainable multi-agent approach for visual question answering
Zeqing Wang, Wentao Wan, Qiqing Lao, Runmeng Chen, Minjie Lang, Xiao Wang, Feng Gao, Keze Wang, and Liang Lin. Towards top-down reasoning: An explainable multi-agent approach for visual question answering. IEEE Transactions on Multimedia, 2026
work page 2026
-
[32]
Tiif-bench: How does your t2i model follow your instructions? arXiv preprint arXiv:2506.02161, 2025
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions?arXiv preprint arXiv:2506.02161, 2025
-
[33]
Openworldsam: Extending sam2 for universal image segmentation with language prompts
Shiting Xiao, Rishabh Kabra, Yuhang Li, Donghyun Lee, Joao Carreira, and Priyadarshini Panda. Openworldsam: Extending sam2 for universal image segmentation with language prompts. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[34]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[35]
Open-vocabulary panoptic segmentation with text-to-image diffusion models
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, and Shalini De Mello. Open-vocabulary panoptic segmentation with text-to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2955–2966, 2023
work page 2023
-
[36]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
work page 2016
-
[37]
A simple framework for open-vocabulary segmentation and detection
Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation and detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1020–1031, 2023
work page 2023
-
[38]
Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset.International Journal of Computer Vision, 127(3):302–321, 2019. 12 A. Dataset Preparation A.1. CAFE Annotation Pipeline The CAFE annotation pipeline is shown in Fig. 4. To fit the input resolution o...
work page 2019
-
[39]
If there are multiple instances of the target object class in the image, read the query carefully to determine whether it applies to all instances or just one, and ground accordingly
-
[40]
Identify the actual target object the user is asking you to ground. Do not ground secondary objects that only exist to help identify the target. For example, given "a giraffe with its head up", ground the whole giraffe, not just the head. Given "a person holding a blender with their left hand", ground the person, not the blender or hand
-
[41]
Do not include masks for objects mentioned only for identification purposes. For example, given "a man carrying a young girl", ground only the man
-
[42]
something that shows the man is playing golf
Sometimes the target is not directly named but clearly referenced. For example, given "something that shows the man is playing golf" and an image of a man holding a golf club, ground the golf club
-
[43]
Do not give up and callreport_no_mask due to small technicalities
Carefully examine all details in the image and reason step by step. Do not give up and callreport_no_mask due to small technicalities. Only callreport_no_mask if there are clear, direct contradictions between the query and the image content
-
[44]
If the query contains typos, grammatical errors, or irrelevant information, reason about the user’s intent based on the image content rather than following the query literally. Available Tools You must call exactly one tool per turn. Enclose the tool call in<tool>...</tool>tags. segment_phrase Use SAM3 to segment all instances of a simple noun phrase in t...
- [45]
-
[46]
Use the object category instead (e.g., "sign" instead of the text on the sign)
Do not try to ground text, letters, or numbers written on objects. Use the object category instead (e.g., "sign" instead of the text on the sign)
-
[47]
If a phrase produces no masks or incomplete results, try a more general noun phrase. For example, if "elementary school teacher" returns nothing, try "person"
-
[48]
Avoid identifying concepts through actions or relationships. Use "vase" instead of "the bigger vase", "dog" instead of "the dog lying down"
-
[49]
Be creative with synonyms and visual common sense
If results are not what you expected, try a differenttext_prompt. Be creative with synonyms and visual common sense
-
[50]
For niche objects that produce no masks, try grounding a more general category. For example, if "sundial" fails, try "statue"
- [51]
-
[52]
Never use the exact sametext_promptmore than once
- [53]
-
[54]
If a previoustext_prompt did not work, think of a new, creative phrase. For example, when grounding the center of a cake with text, try "birthday greeting". 25
-
[55]
Always callsegment_phrase with atext_prompt that represents the entire grounding target. Do not use subparts (e.g., use "adult person" not "adult hand")
-
[56]
If the query refers to one specific instance among several, use the singular category name and then use select_masks_and_returnto pick the correct one
-
[57]
Every call tosegment_phrase generates a fresh set of masks. Previous masks are no longer rendered on the latest image, though they remain visible in earlier images in your conversation history
-
[58]
Only ground objects that fully match the query. Ignore partial matches
-
[59]
Do not propose atext_prompt that covers more area than the query asks for (e.g., do not use "jeans" when asked for broken areas of jeans)
-
[60]
Do not propose atext_prompt that covers less area than the query asks for (e.g., do not use "microphone" when asked for the person holding a microphone)
-
[61]
Try to propose atext_promptthat covers exactly the queried object(s), no more and no less
-
[62]
Be creative in yourtext_prompt choices. Use synonyms and visual common sense. You have multiple turns, so take your time. examine_masks Zoom into specific mask regions for close-up inspection. Returns high-resolution cropped images of the requested mask areas with minimal overlay, preserving material and texture details. Use this when you need to verify f...
-
[63]
You may only callexamine_masksaftersegment_phrasehas produced masks. 2.mask_indices must be a non-empty array of valid mask numbers (1 to N, where N is the number of masks in the most recentsegment_phraseresult). Out-of-range indices will be ignored
-
[64]
Use this tool when you need to inspect material, texture, or fine details to determine whether the mask region truly matches the queried concept
-
[65]
The returned zoom-in images do not have mask number labels to avoid occluding details. The images are returned in the order you requested, with a text description indicating which mask each image corresponds to
-
[66]
You do not need to examine every mask. Only examine the ones where you are uncertain about the concept match. select_masks_and_return Select a subset of (or all) masks from the most recentsegment_phrase result as your final answer. This ends the conversation. Parameters:{"final_answer_masks": [1, 2]} Rules forselect_masks_and_return:
-
[67]
Only call this when you are confident the selected masks correctly cover the queried concept
-
[68]
Do not reference masks from earlier calls
Mask numbers refer to the most recentsegment_phraseresult image. Do not reference masks from earlier calls
-
[69]
The integers infinal_answer_masks must be within range 1 to N (number of masks in the most recent image), with no duplicates
-
[70]
The selected masks should accurately capture the target object(s) and only the target object(s)
-
[71]
Before calling this tool, verify that each selected mask matches the original user query (not just the intermediate text_promptyou used forsegment_phrase)
-
[72]
If the query involves colors, double-check against the original image since mask overlays change object colors
-
[73]
report_no_maskReport that the queried concept does not exist in the image
If the query involves relative positions, explicitly reason about each mask’s spatial position before selecting. report_no_maskReport that the queried concept does not exist in the image. This ends the conversation. Parameters:{}(empty object) Rules forreport_no_mask:
-
[74]
Only call this when you have carefully examined the image and determined that no object matches the queried concept
-
[75]
Use select_masks_and_returninstead
If at any point in your reasoning you identified a matching target, you must not callreport_no_mask. Use select_masks_and_returninstead
-
[76]
Before calling this tool, re-examine the original image and explicitly restate why no object matches the query
-
[77]
Be thorough: if the query is slightly inaccurate but a related object exists, ground that object instead of reporting no mask. 26
-
[78]
Do not callreport_no_mask due to minor discrepancies. Only use it when there is a clear, fundamental mismatch between the query and the image content. Response Format Each turn, first provide your reasoning inside<think> tags, then call exactly one tool inside<tool> tags. Do not call multiple tools in one turn. Your response will be programmatically parse...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.