Recognition: 2 theorem links
· Lean TheoremAwareLLM: A Proactive Multimodal Ecosystem for Personalized Human-AI Collaboration to Enhance Productivity
Pith reviewed 2026-05-12 03:22 UTC · model grok-4.3
The pith
A multimodal AI system uses eye gaze, posture, and heart signals to deliver proactive personalized help that improves task performance and lowers mental fatigue compared to standard assistants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
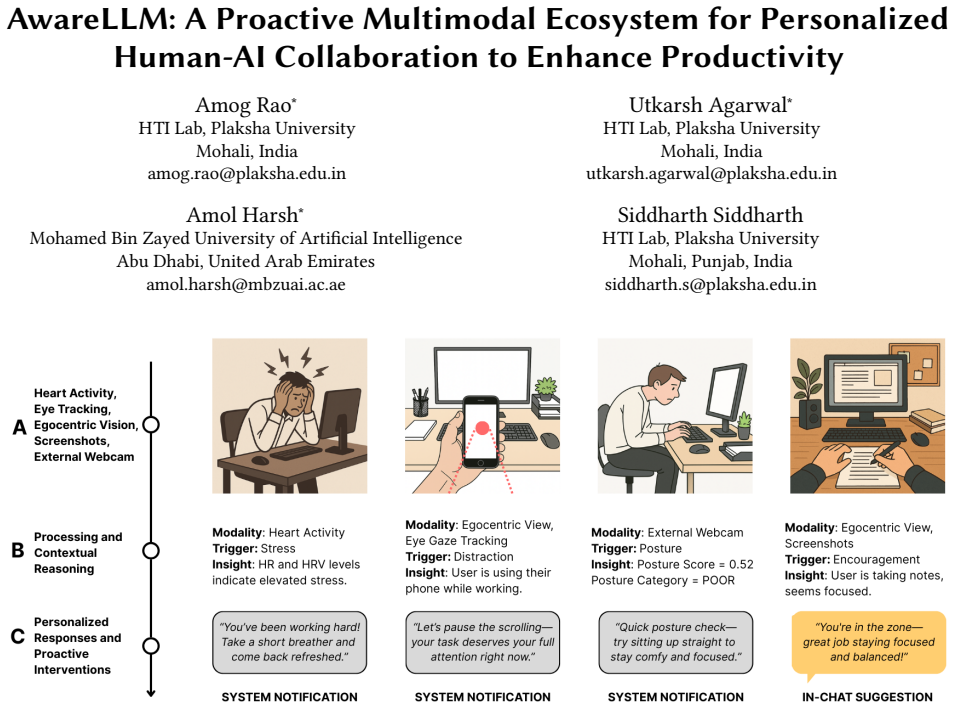
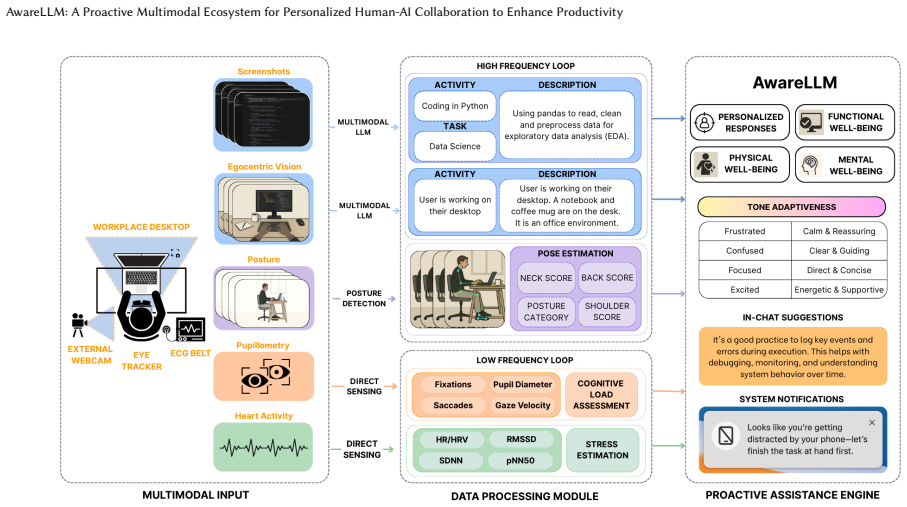
AwareLLM integrates egocentric vision, pupillometry, eye-gaze tracking, posture detection, heart activity monitoring, and large language model inference into a single ecosystem that detects users' psychophysiological states, tracks temporal patterns in behavior, and generates timely personalized interventions, yielding statistically significant gains in task performance together with reductions in cognitive fatigue and mental demand relative to a standard LLM assistant.
What carries the argument
The AwareLLM framework, which fuses multimodal sensor streams of vision and physiological signals with LLM reasoning to shift from reactive chat responses to proactive, state-aware interventions.
If this is right
- AI assistants can shift from prompt-driven to sensor-driven support when cognitive load is detected in real time.
- Knowledge work can see measurable drops in fatigue when interventions match a user's current physiological state.
- User confidence and engagement rise when help arrives at moments aligned with observed behavioral patterns.
- Temporal analysis of sensor data enables the system to anticipate productivity dips rather than only react after they occur.
Where Pith is reading between the lines
- Workplace software could evolve to monitor body signals continuously, changing daily human-AI interaction from query-response to ongoing collaboration.
- Privacy safeguards would become necessary if such sensing spreads beyond controlled studies into open office settings.
- The same sensor-plus-LLM pattern could be tested in domains such as education or creative tasks to check whether proactive help generalizes.
- Longer deployments might reveal whether users begin to ignore or over-trust the generated interventions.
Load-bearing premise
The combination of vision, eye, posture, and heart data can be interpreted by the LLM accurately enough to produce interventions that genuinely help rather than introduce new errors or distractions.
What would settle it
A larger study in which participants using AwareLLM show no improvement in task performance metrics or report higher mental demand and interruptions than those using a baseline LLM assistant would falsify the central claim.
Figures










read the original abstract
Information workers' productivity is significantly influenced by their cognitive states and physiological responses. AI assistants such as ChatGPT, Copilot, and others have become integral components of knowledge-intensive workplaces. These AI assistants utilize pre-defined user preferences and chat interaction histories, thus confining themselves to reactive exchanges, lacking sufficient adaptability. Consequently, they fail to cater to individual user preferences and are unable to adapt to their psychophysiological states, diminishing potential productivity gains. To bridge this gap, we introduce AwareLLM, a novel multimodal framework that integrates egocentric vision, pupillometry, eye-gaze tracking, posture detection, heart activity, and the inferencing capabilities of large language models (LLMs) to create a proactive and context-aware ecosystem. AwareLLM dynamically adapts to users' psychophysiological states while analyzing temporal patterns and behavioral tendencies to provide personalized and timely interventions. We evaluated AwareLLM through a user study with 20 participants, comparing it to a standard LLM assistant across multiple tasks. Our results show statistically significant improvements in task performance, along with reductions in cognitive fatigue and mental demand. Participants described AwareLLM's personalized interventions as timely and relevant, helping them boost their confidence and deepen engagement with their work. AwareLLM opens new avenues for Human-AI collaboration where technology adapts to our needs rather than us adhering to technological constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AwareLLM, a multimodal framework that fuses egocentric vision, pupillometry, eye-gaze tracking, posture detection, heart activity, and LLM inference to deliver proactive, personalized interventions adapted to users' real-time psychophysiological states. It contrasts this with reactive AI assistants limited to predefined preferences and chat history. The central empirical claim is that a 20-participant user study demonstrates statistically significant gains in task performance together with reductions in cognitive fatigue and mental demand relative to a standard LLM baseline, with qualitative feedback indicating timely and relevant interventions.
Significance. If the reported gains are robustly supported, the work would advance human-AI collaboration research by showing how continuous multimodal sensing can shift AI assistants from reactive to state-aware behavior, potentially improving productivity and reducing cognitive load in knowledge work. The integration of multiple physiological channels with LLMs is a timely idea. However, the absence of any reported accuracy metrics, ablation results, or statistical details for the user study substantially weakens the ability to judge whether the claimed benefits are attributable to the proposed pipeline.
major comments (2)
- [Abstract] Abstract: The claim of 'statistically significant improvements in task performance, along with reductions in cognitive fatigue and mental demand' is presented without any accompanying information on experimental design, participant demographics, task types, control conditions, statistical tests, p-values, effect sizes, or power analysis. Because the entire contribution rests on this user-study result, the missing methodological details constitute a load-bearing omission that prevents verification of the central claim.
- [Evaluation] Evaluation / results section: No quantitative evidence is supplied for the accuracy of multimodal state inference (e.g., classification accuracy or confusion matrices for cognitive states derived from vision, pupillometry, gaze, posture, and heart-rate signals), false-positive rates of interventions, or specific NASA-TLX subscale scores. Without these measurements or an ablation isolating the physiological channels, the causal link between the AwareLLM pipeline and the reported productivity and fatigue benefits cannot be established.
minor comments (1)
- [Introduction] The abstract and introduction repeatedly use the term 'psychophysiological states' without a precise operational definition or reference to how each sensor modality maps to specific states; adding a short table or diagram would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments identify key areas where additional detail will strengthen the presentation of our user study and system evaluation. We address each point below and will revise the manuscript to incorporate the requested information where it is available from our existing data.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'statistically significant improvements in task performance, along with reductions in cognitive fatigue and mental demand' is presented without any accompanying information on experimental design, participant demographics, task types, control conditions, statistical tests, p-values, effect sizes, or power analysis. Because the entire contribution rests on this user-study result, the missing methodological details constitute a load-bearing omission that prevents verification of the central claim.
Authors: We agree that the abstract claim would be more verifiable with additional context. In the revised manuscript we will update the abstract to briefly note the within-subjects design with 20 participants, the standard LLM baseline, the task types, and the statistical tests employed (including p-values and effect sizes). The full methodological description, demographics, power analysis, and exact statistical results will be expanded in the Evaluation section for complete transparency. revision: yes
-
Referee: [Evaluation] Evaluation / results section: No quantitative evidence is supplied for the accuracy of multimodal state inference (e.g., classification accuracy or confusion matrices for cognitive states derived from vision, pupillometry, gaze, posture, and heart-rate signals), false-positive rates of interventions, or specific NASA-TLX subscale scores. Without these measurements or an ablation isolating the physiological channels, the causal link between the AwareLLM pipeline and the reported productivity and fatigue benefits cannot be established.
Authors: We acknowledge that the submitted manuscript omits explicit accuracy metrics, confusion matrices, false-positive rates for interventions, and detailed NASA-TLX subscale scores with statistical comparisons. We will add these quantitative results in the revised Evaluation section, computed from the multimodal signals and questionnaires collected during the 20-participant study. However, we did not conduct ablation experiments that isolate the contribution of individual physiological channels; the study evaluated the integrated system. We will therefore report the available per-modality inference accuracies but note the absence of full ablations as a limitation and direction for future work. revision: partial
- Ablation studies that isolate the contribution of each individual physiological channel (vision, pupillometry, gaze, posture, heart activity) to the observed performance and fatigue benefits, as these experiments were not performed in the original user study.
Circularity Check
No circularity: empirical user study with no derivations or self-referential claims
full rationale
The paper describes a multimodal system and reports results from a 20-participant user study comparing task performance, cognitive fatigue, and subjective feedback against a baseline LLM. No equations, parameter fitting, predictions derived from models, or first-principles derivations are present in the abstract or described methodology. The central claims rest on direct empirical measurements and participant descriptions rather than any chain that reduces to its own inputs by construction, self-citation load-bearing, or renamed known results. This is the expected outcome for a purely empirical HCI evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal psychophysiological signals (vision, pupillometry, gaze, posture, heart activity) can be accurately interpreted to infer cognitive states suitable for LLM-driven interventions.
invented entities (1)
-
AwareLLM framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrates egocentric vision, pupillometry, eye-gaze tracking, posture detection, heart activity, and the inferencing capabilities of large language models (LLMs) to create a proactive and context-aware ecosystem
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NASA-TLX ratings showed that with AwareLLM, mental and temporal demands were reduced by over 22% on average
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi:10 .1101/2024.02.13.580071 [24]Anil Abraham Kuriakose
The Lab Streaming Layer for Synchronized Multimodal Recording. doi:10 .1101/2024.02.13.580071 [24]Anil Abraham Kuriakose. 2025. Pairing Threshold-Based Rules with AI/ML Techniques.Algomox Blog(2025). https://www.algomox.com/resources/blog/h 18 AwareLLM: A Proactive Multimodal Ecosystem for Personalized Human-AI Collaboration to Enhance Productivity ybrid_...
-
[2]
coding”), the broader task category (e.g., “front-end web development
doi:10.1016/j.sigpro.2005.02.002 [32]Manlio MassirisFernández, J. Álvaro Fernández, Juan M. Bajo, and Claudio A. Delrieux. 2020. Ergonomic risk assessment based on computer vision and machine learning.Computers And Industrial Engineering149 (2020), 106816. doi:10.1016/j.cie.2020.106816 [33]Julia M. Mayer, Starr Roxanne Hiltz, and Quentin Jones. 2015. Maki...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.