Recognition: 2 theorem links
· Lean TheoremPDEAgent-Bench: A Multi-Metric, Multi-Library Benchmark for PDE Solver Generation
Pith reviewed 2026-05-12 02:32 UTC · model grok-4.3
The pith
PDEAgent-Bench is the first benchmark to show that AI-generated PDE solver code often runs but rarely meets accuracy and efficiency standards across multiple FEM libraries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
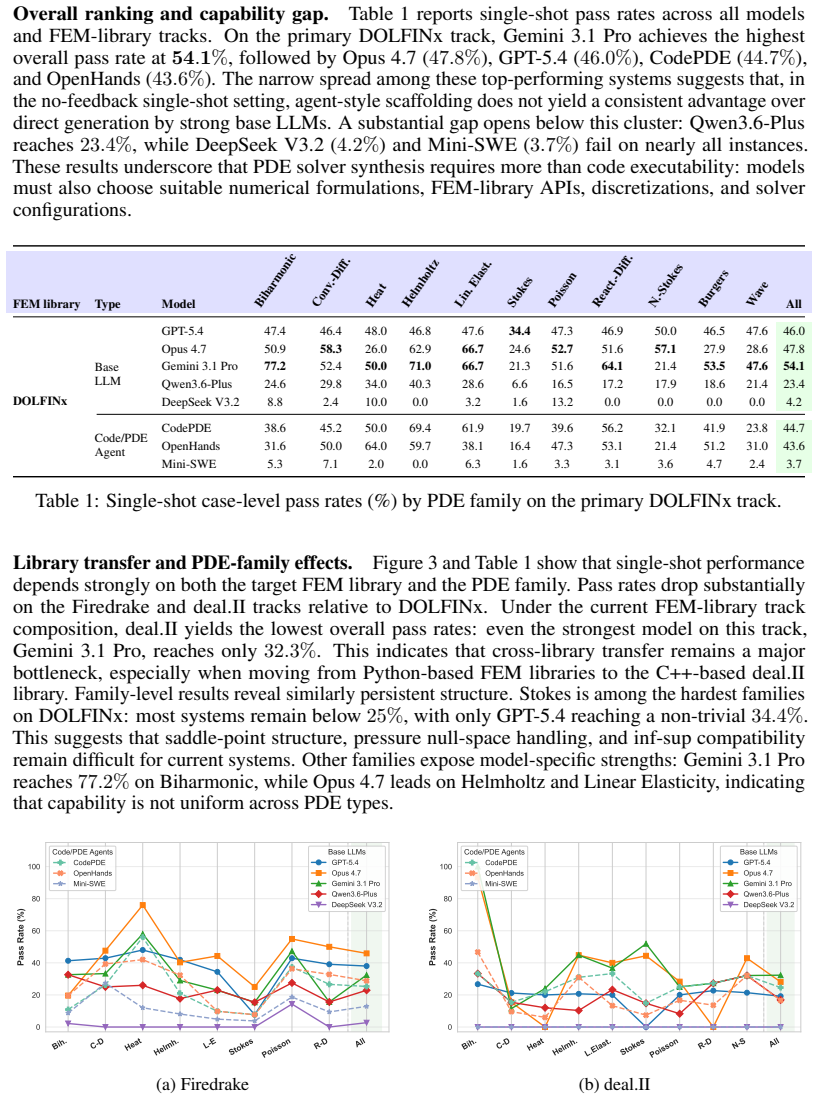
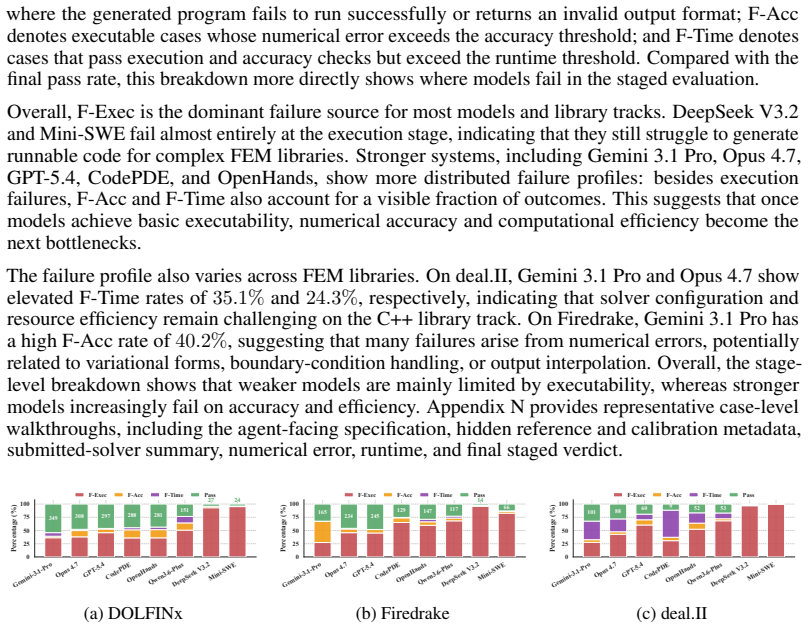
The paper establishes that no prior public benchmark exists for PDE-to-solver code generation and presents PDEAgent-Bench as the first multi-metric, multi-library testbed. It contains 645 instances across 6 mathematical categories and 11 PDE families, each providing an agent-facing specification, a reference solution on a prescribed grid, and case-specific accuracy and runtime targets. The benchmark applies a staged evaluation that requires generated solvers to pass executability, numerical accuracy, and computational efficiency checks in sequence using DOLFINx, Firedrake, and deal.II. Experiments show that representative LLMs and agents frequently produce runnable code, yet pass rates drop,
What carries the argument
PDEAgent-Bench, a collection of 645 PDE instances with staged checks for executability followed by accuracy against reference grids and runtime limits, implemented across three professional FEM libraries.
If this is right
- Current LLMs and code agents remain limited in generating numerically reliable and efficient PDE solvers.
- PDE solver generation now has a reproducible testbed that measures progress against concrete accuracy and efficiency requirements.
- Future agent designs must improve handling of discretization schemes, solver configuration, and library-specific implementations to succeed on this benchmark.
- The staged framework separates syntactic success from numerical correctness, allowing targeted diagnosis of model weaknesses.
Where Pith is reading between the lines
- The benchmark could be adapted to measure progress in generating solvers for other simulation domains that also demand both precision and speed.
- Models might improve if trained on larger corpora of verified FEM code paired with the corresponding PDE specifications.
- The sharp drop in pass rates suggests that purely language-based agents may need integration with symbolic or verification tools to reach professional standards.
Load-bearing premise
The chosen staged checks, accuracy and runtime targets, reference grids, and 645 instances across the six categories and eleven PDE families sufficiently represent the real demands of numerical PDE work in professional libraries.
What would settle it
A model that consistently passes all three stages on a majority of the 645 instances while still producing solvers that match independent real-world FEM applications outside the benchmark.
Figures





read the original abstract
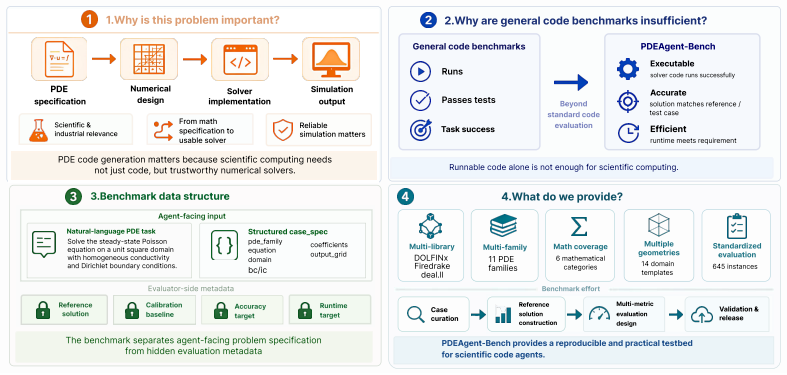
PDE-to-solver code generation aims to automatically synthesize executable numerical solvers from partial differential equation (PDE) specifications. This task requires not only understanding the mathematical structure of PDEs, but also selecting appropriate discretization schemes and solver configurations, and correctly implementing the resulting formulations in finite-element method (FEM) libraries. Existing code generation benchmarks mainly evaluate syntactic correctness, or success on predefined test cases. To our knowledge, there is currently no publicly available benchmark specifically for PDE-to-solver code generation, and general-purpose code benchmarks do not fully capture the unique challenges of numerical PDE solution, such as ensuring solver accuracy, efficiency, and compatibility with professional FEM libraries. We introduce PDEAgent-Bench, to the best of our knowledge, the first multi-metric, multi-library benchmark for PDE-to-solver code generation. PDEAgent-Bench contains 645 instances across 6 mathematical categories and 11 PDE families, with common FEM libraries for DOLFINx, Firedrake, and deal.II. Each instance provides an agent-facing problem specification, a reference solution on a prescribed evaluation grid, and case-specific accuracy and runtime targets. PDEAgent-Bench adopts a staged evaluation framework in which generated solvers must sequentially pass executability, numerical accuracy, and computational efficiency checks. Experiments with representative LLMs and code agents show that models can often produce runnable code, but their pass rate drops substantially once accuracy and efficiency requirements are enforced. These results indicate that current agents remain limited in producing numerically reliable and efficient PDE solvers, and that PDEAgent-Bench provides a reproducible testbed grounded in the practical requirements of numerical PDE solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PDEAgent-Bench, the first multi-metric, multi-library benchmark for PDE-to-solver code generation. It consists of 645 instances across 6 mathematical categories and 11 PDE families, supporting DOLFINx, Firedrake, and deal.II. Each instance supplies an agent-facing specification, a reference solution on a prescribed grid, and case-specific accuracy/runtime targets. Evaluation proceeds in stages: executability, then numerical accuracy, then computational efficiency. Experiments with LLMs and code agents show that runnable code is frequently generated, but pass rates drop sharply once accuracy and efficiency gates are enforced, indicating current agents remain limited for producing numerically reliable PDE solvers.
Significance. If the benchmark construction and targets are representative, the work fills a clear gap by moving code-generation evaluation beyond syntax or toy test cases into the practical requirements of FEM-based numerical PDE solving. The staged, multi-library design and reproducible reference grids provide a concrete testbed that can drive progress on agent capabilities for scientific computing tasks. The reported collapse in pass rates under accuracy/efficiency constraints is a falsifiable, actionable finding.
major comments (2)
- [§3] §3 (Benchmark Construction): The selection criteria and validation process for the 645 instances (6 categories, 11 families) are described at a high level only. Without explicit documentation of how instances were chosen to reflect realistic discretization and solver-configuration challenges, it is difficult to assess whether the accuracy and runtime targets are load-bearing for the central claim that agents are limited in producing reliable solvers.
- [§4.2] §4.2 (Reference Solutions and Targets): The generation of reference solutions on prescribed grids and the exact definitions of accuracy thresholds (error norms, tolerances) and runtime targets are not specified in sufficient detail to allow independent reproduction or verification of the staged pass-rate results. These elements are central to the experimental claim that pass rates drop substantially once accuracy and efficiency are enforced.
minor comments (3)
- [Abstract] The repeated phrase 'to the best of our knowledge' in the abstract could be consolidated; a single statement suffices.
- [Figures] Figure captions should explicitly list the three FEM libraries and the number of instances per category to improve immediate readability.
- [Related Work] The related-work section should include a brief comparison table against existing code-generation benchmarks (e.g., HumanEval, APPS) to highlight the unique PDE-specific metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the significance of PDEAgent-Bench in addressing a gap in evaluating AI-generated PDE solvers. We address each major comment below and will revise the manuscript to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The selection criteria and validation process for the 645 instances (6 categories, 11 families) are described at a high level only. Without explicit documentation of how instances were chosen to reflect realistic discretization and solver-configuration challenges, it is difficult to assess whether the accuracy and runtime targets are load-bearing for the central claim that agents are limited in producing reliable solvers.
Authors: We agree that more explicit documentation of the instance selection and validation process is required to substantiate the benchmark's design and the load-bearing nature of the targets. In the revised manuscript we will expand §3 with a dedicated subsection detailing the selection criteria (including coverage of discretization schemes, solver configurations, and problem complexities across the 6 categories and 11 families), the validation steps performed to confirm realism and diversity, and the rationale for the resulting distribution of the 645 instances. revision: yes
-
Referee: [§4.2] §4.2 (Reference Solutions and Targets): The generation of reference solutions on prescribed grids and the exact definitions of accuracy thresholds (error norms, tolerances) and runtime targets are not specified in sufficient detail to allow independent reproduction or verification of the staged pass-rate results. These elements are central to the experimental claim that pass rates drop substantially once accuracy and efficiency are enforced.
Authors: We acknowledge that the current description of reference-solution generation and the precise definitions of accuracy and runtime thresholds lack the granularity needed for full reproducibility. In the revision we will augment §4.2 with explicit descriptions of the reference-solution procedure (including the numerical methods, grid specifications, and libraries employed to obtain ground-truth values), the exact error norms and tolerance values used for the accuracy gate, and the case-specific runtime targets. These additions will directly support verification of the staged evaluation results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs a new benchmark (PDEAgent-Bench) with 645 instances, staged evaluation gates, reference grids, and accuracy/runtime targets, then runs existing LLMs/agents against it. All load-bearing claims (first-of-kind status, pass-rate collapse under accuracy/efficiency) rest on external model evaluations and the explicit benchmark definition rather than any self-definition, fitted-parameter renaming, or self-citation chain that reduces the result to its inputs. The derivation is a standard empirical benchmark paper and remains self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPDEAgent-Bench adopts a staged evaluation framework in which generated solvers must sequentially pass executability, numerical accuracy, and computational efficiency checks.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce PDEAgent-Bench, to the best of our knowledge, the first multi-metric, multi-library benchmark for PDE-to-solver code generation.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Measuring coding challenge competence with APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/ forum?i...
work page 2021
-
[4]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
work page 2022
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[7]
DOLFINx: the next generation FEniCS problem solving environment
Igor A. Baratta, Joseph P. Dean, Jørgen S. Dokken, Michal Habera, Jack S. Hale, Chris N. Richardson, Marie E. Rognes, Matthew W. Scroggs, Nathan Sime, and Garth N. Wells. DOLFINx: the next generation FEniCS problem solving environment, 2023. URL https: //doi.org/10.5281/zenodo.10447666
-
[8]
David A. Ham, Paul H. J. Kelly, Lawrence Mitchell, Colin J. Cotter, Robert C. Kirby, Koki Sagiyama, Nacime Bouziani, Sophia V orderwuelbecke, Thomas J. Gregory, Jack Betteridge, Daniel R. Shapero, Reuben W. Nixon-Hill, Connor J. Ward, Patrick E. Farrell, Pablo D. Brubeck, India Marsden, Thomas H. Gibson, Miklós Homolya, Tianjiao Sun, Andrew T. T. McRae, F...
work page 2023
-
[9]
Wolfgang Bangerth, Ralf Hartmann, and Guido Kanschat. deal.ii—a general-purpose object- oriented finite element library.ACM Transactions on Mathematical Software, 33(4):24–es,
-
[10]
doi: 10.1145/1268776.1268779
-
[11]
Codepde: An inference framework for llm-driven pde solver generation
Shanda Li, Tanya Marwah, Junhong Shen, Weiwei Sun, Andrej Risteski, Yiming Yang, and Ameet Talwalkar. Codepde: An inference framework for llm-driven pde solver generation. arXiv preprint arXiv:2505.08783, 2025. 10
-
[12]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Self-attention to operator learning-based 3d-ic thermal simulation
Zhen Huang, Hong Wang, Wenkai Yang, Muxi Tang, Depeng Xie, Ting-Jung Lin, Yu Zhang, Wei W Xing, and Lei He. Self-attention to operator learning-based 3d-ic thermal simulation. In 2025 62nd ACM/IEEE Design Automation Conference (DAC), pages 1–7. IEEE, 2025
work page 2025
-
[15]
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. Pdebench: An extensive benchmark for scientific machine learning.Advances in neural information processing systems, 35:1596–1611, 2022
work page 2022
-
[16]
Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
-
[17]
Yining Luo, Yingfa Chen, and Zhen Zhang. Cfdbench: A large-scale benchmark for machine learning methods in fluid dynamics.arXiv preprint arXiv:2310.05963, 2023
-
[18]
https://arxiv.org/abs/2307.10635
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. Scibench: Evaluating college-level scientific problem-solving abilities of large language models.arXiv preprint arXiv:2307.10635, 2023
-
[19]
Minyang Tian, Luyu Gao, Shizhuo D Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, et al. Scicode: A research coding benchmark curated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
work page 2024
-
[20]
Peiyan Hu, Haodong Feng, Hongyuan Liu, Tongtong Yan, Wenhao Deng, Tianrun Gao, Rong Zheng, Haoren Zheng, Chenglei Yu, Chuanrui Wang, et al. Realpdebench: A benchmark for complex physical systems with real-world data.arXiv preprint arXiv:2601.01829, 2026
-
[21]
Automated code development for pde solvers using large language models, 2025
Haoyang Wu, Xinxin Zhang, and Lailai Zhu. Automated code development for pde solvers using large language models, 2025. URLhttps://arxiv.org/abs/2509.25194
-
[22]
Re4: Scientific computing agent with rewriting, resolution, review and revision, 2026
Ao Cheng, Lei Zhang, and Guowei He. Re4: Scientific computing agent with rewriting, resolution, review and revision, 2026. URLhttps://arxiv.org/abs/2508.20729
-
[23]
Mauricio Soroco, Jialin Song, Mengzhou Xia, Kye Emond, Weiran Sun, and Wuyang Chen. Pde- controller: Llms for autoformalization and reasoning of pdes.arXiv preprint arXiv:2502.00963, 2025
-
[24]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
work page internal anchor Pith review arXiv 2025
-
[25]
Ziyi Ni, Huacan Wang, Shuo Zhang, Shuo Lu, Ziyang He, Zhenheng Tang, Sen Hu, Bo Li, Chen Hu, Binxing Jiao, et al. Gittaskbench: A benchmark for code agents solving real-world tasks through code repository leveraging. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32564–32572, 2026
work page 2026
-
[26]
Da-code: Agent data science code generation benchmark for large language models
Yiming Huang, Jianwen Luo, Yan Yu, Yitong Zhang, Fangyu Lei, Yifan Wei, Shizhu He, Lifu Huang, Xiao Liu, Jun Zhao, et al. Da-code: Agent data science code generation benchmark for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13487–13521, 2024. 11
work page 2024
-
[27]
Shuhan Liu, Zhiyi Zhao, Xing Hu, Kui Liu, Xiaohu Yang, and Xin Xia. A benchmark for evaluating repository-level code agents with intermediate reasoning on feature addition task,
- [28]
-
[29]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
work page 2024
-
[30]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=oKn9c6ytLx
work page 2024
-
[31]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InThe Thirty-eight Conference on N...
work page 2024
-
[32]
MCP-bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, and Eugene Siow. MCP-bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=fe8mzHwMxN
work page 2026
-
[33]
Xiangru Tang, Yuliang Liu, Zefan Cai, Yanjun Shao, Junjie Lu, Yichi Zhang, Zexuan Deng, Helan Hu, Kaikai An, Ruijun Huang, Shuzheng Si, Chen Sheng, Haozhe Zhao, Liang Chen, Tianyu Liu, Yujia Qin, Wangchunshu Zhou, Yilun Zhao, Zhiwei Jiang, Baobao Chang, Arman Cohan, and Mark Gerstein. ML-bench: Evaluating large language models and agents for machine learn...
work page 2025
-
[34]
Truong, Weixin Liang, Fan- Yun Sun, and Nick Haber
Tianyu Hua, Harper Hua, Violet Xiang, Benjamin Klieger, Sang T. Truong, Weixin Liang, Fan- Yun Sun, and Nick Haber. Researchcodebench: Benchmarking LLMs on implementing novel machine learning research code. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URLhttps://openreview.net/ forum?id...
work page 2026
-
[35]
MLR-bench: Evaluating AI agents on open-ended machine learning research
Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Yufei He, Jiaying Wu, Yibo Li, Yue Liu, and Bryan Hooi. MLR-bench: Evaluating AI agents on open-ended machine learning research. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URLhttps://openreview.net/forum?id=JX9DE6colf
work page 2026
-
[36]
Efficient benchmarking of AI agents
Franck Ndzomga. Efficient benchmarking of ai agents, 2026. URL https://arxiv.org/ abs/2603.23749
-
[37]
Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, et al. PHYBench: Holistic evaluation of physical perception and reasoning in large language models.arXiv preprint arXiv:2504.16074, 2025
-
[38]
Zhongkai Hao, Jiachen Yao, Chang Su, Hang Su, Ziao Wang, Fanzhi Lu, Zeyu Xia, Yichi Zhang, Songming Liu, Lu Lu, et al. PINNacle: A comprehensive benchmark of physics-informed neural networks for solving PDEs.Advances in Neural Information Processing Systems, 37: 76721–76774, 2024
work page 2024
-
[39]
Towards scientific intelligence: A survey of llm-based scientific agents, 2026
Shuo Ren, Can Xie, Pu Jian, Zhenjiang Ren, Chunlin Leng, and Jiajun Zhang. Towards scientific intelligence: A survey of llm-based scientific agents, 2026. URL https://arxiv.org/abs/ 2503.24047. 12
-
[40]
Reasoning-to-simulation: An agentic framework for discovery of electrolyte materials
Jur ‘gis Ruža and Rafael Gomez-Bombarelli. Reasoning-to-simulation: An agentic framework for discovery of electrolyte materials. InAI for Accelerated Materials Design - ICLR 2026,
work page 2026
-
[41]
URLhttps://openreview.net/forum?id=MEXl18VhBL
- [42]
-
[43]
Explain like i’m five: Using LLMs to improve PDE surrogate models with text, 2024
Cooper Lorsung and Amir Barati Farimani. Explain like i’m five: Using LLMs to improve PDE surrogate models with text, 2024. URL https://openreview.net/forum?id=D3iJmVAmT7
work page 2024
-
[44]
PINNsagent: Automated PDE surrogation with large language models
Qingpo Wuwu, Chonghan Gao, Tianyu Chen, Yihang Huang, Yuekai Zhang, Jianing Wang, Jianxin Li, Haoyi Zhou, and Shanghang Zhang. PINNsagent: Automated PDE surrogation with large language models. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=RO5OGOzs6M
work page 2025
-
[45]
How do large language models perform on pde discovery: A coarse-to-fine perspective
Xiao Luo, Changhu Wang, Yizhou Sun, and Wei Wang. How do large language models perform on pde discovery: A coarse-to-fine perspective. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 2684–2697, 2025
work page 2025
-
[46]
Opinf-LLM: Parametric PDE solving with LLMs via operator inference
Zhuoyuan Wang, Hanjiang Hu, Xiyu Deng, Saviz Mowlavi, and Yorie Nakahira. Opinf-LLM: Parametric PDE solving with LLMs via operator inference. InAI&PDE: ICLR 2026 Workshop on AI and Partial Differential Equations, 2026. URL https://openreview.net/forum? id=6FocHf1tCE
work page 2026
-
[47]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. Datasheets for datasets, 2021. URL https: //arxiv.org/abs/1803.09010. 13 A Related Work A.1 Code Generation Benchmarks and Code Agents Code generation benchmarks have become standard for evaluating code agents, often using executio...
-
[48]
Design matrix.For each PDE family, we define a small set of variation axes that correspond to interpretable numerical challenges, such as coefficient contrast, source-term regularity, solution smoothness, boundary-condition type, geometry, time horizon, Reynolds or Péclet regime, non- linearity strength, and stiffness. Candidate cases are sampled from the...
-
[49]
This record defines the information available to the agent at generation time
Problem specification.The contributor writes the agent-facing case_spec, including the PDE family, coefficients, forcing, domain, boundary conditions, initial conditions when applicable, tem- poral parameters, output field, and prescribed evaluation grid. This record defines the information available to the agent at generation time
-
[50]
Reference construction path.The contributor specifies how the reference solution is obtained. When possible, the case uses a manufactured solution, from which source terms, boundary data, and initial conditions are derived analytically. When an analytic manufactured solution is unavailable, the contributor provides a high-fidelity reference_config that ge...
-
[51]
Calibration baseline.The contributor provides a separate calibration_config. The calibration run is not used as the scoring reference; instead, it is compared with the reference solution to compute ebase and to derive the case-specific accuracy threshold. Its runtime is used to derive the runtime threshold. This separation prevents the benchmark from requ...
-
[52]
Agent-facing numerical-decision fields.The case record may list high-level numerical decisions that an agent is expected to make, such as mesh resolution, element degree, time-step size, nonlinear iteration strategy, stabilization choice, or solver/preconditioner configuration. These fields describe theroleof each decision but do not include recommended n...
-
[53]
It also verifies that cases without manufactured solutions provide a completereference_config
Static validation.The schema validator checks identifier uniqueness, required-field presence, con- sistency between pde.type and equation_family, domain and boundary-tag validity, output- grid validity, supported-library declarations, and symbolic parsability of expression fields. It also verifies that cases without manufactured solutions provide a comple...
-
[54]
Trial execution and calibration.The build script executes the reference-generation and calibration procedures in the evaluation harness. It verifies that the reference solution is produced successfully, that output-grid sampling is valid, that the calibration error is finite, that runtime measurement succeeds, and that the derived thresholds (τacc, τtime)...
-
[55]
Packaging.Validated cases are exported into the released JSONL files. Agent-visible fields are separated from evaluator-only metadata, reference artifacts are stored under evaluator-controlled paths, and materialized thresholds are recorded for reproducible scoring. The release package also includes schema files, evaluator scripts, container recipes, and ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.