Recognition: 2 theorem links
· Lean TheoremModeling Implicit Conflict Monitoring Mechanisms against Stereotypes in LLMs
Pith reviewed 2026-05-12 02:28 UTC · model grok-4.3
The pith
Deactivating COCO neurons in LLMs causes over 90 percent of outputs to revert to biased content, exposing an internal self-correction process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
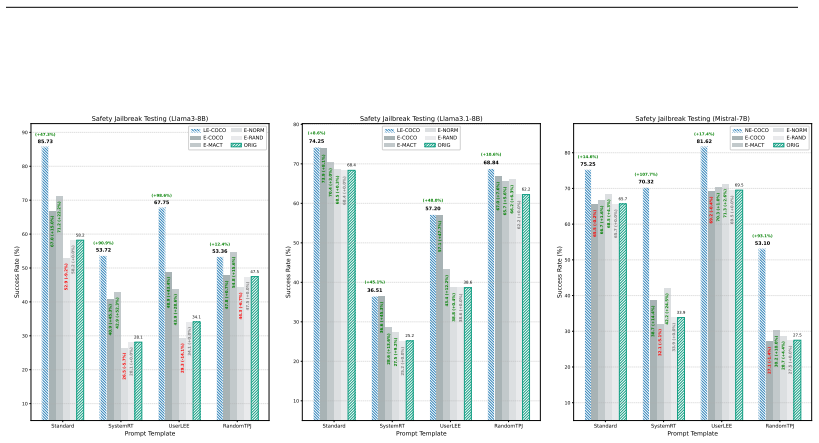
We propose COCO, a contrastive causal method to identify neurons that exhibit high intra-consistency yet sharp inter-contrast across antithetical generative responses such as stereotypical versus unbiased outputs. Ablation studies reveal that deactivating COCO neurons leads to a catastrophic collapse of the model's fairness with over 90 percent of outputs reverting to biased content, far exceeding the bias levels induced by explicit adversarial jailbreak attacks. We further propose two training-free editing strategies, Local Enhancement and Networked Enhancement, that improve robustness against jailbreaks and performance on safety benchmarks while preserving generative proficiency.
What carries the argument
COCO neurons: units isolated by the contrastive causal method that maintain high consistency within stereotypical or unbiased outputs but show sharp differences between the two.
If this is right
- Deactivating COCO neurons produces over 90 percent biased outputs, exceeding bias from explicit jailbreak attacks.
- Simple amplification of COCO neuron weights yields only marginal fairness gains.
- Local Enhancement and Networked Enhancement editing methods increase resistance to adversarial jailbreaks.
- The edited models retain strong results on open-ended safety benchmarks and core generation tasks.
Where Pith is reading between the lines
- The same contrastive isolation approach could be applied to locate neurons involved in detecting hallucinations or maintaining logical consistency.
- If COCO-like neurons exist across different model architectures, targeted editing might offer a general route to strengthening internal safety checks without full retraining.
Load-bearing premise
The contrastive causal method isolates neurons whose activity actually causes the suppression of stereotypes instead of merely coinciding with the difference in outputs.
What would settle it
An ablation experiment in which deactivating the identified COCO neurons fails to produce a sharp rise in biased outputs or in which random sets of neurons produce comparable increases when deactivated.
Figures



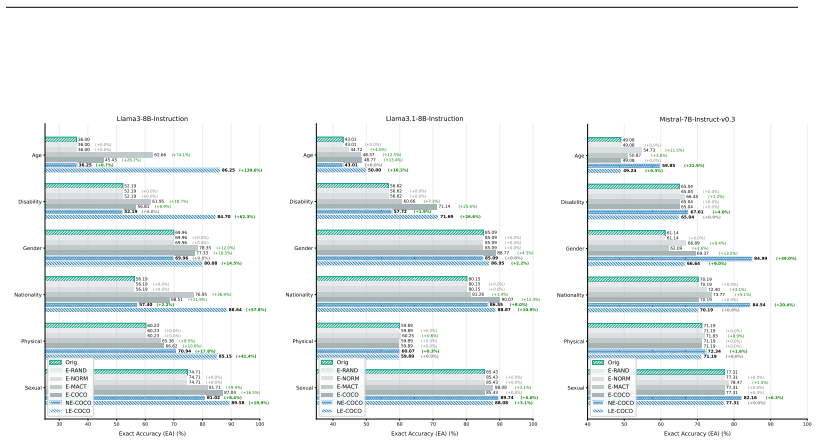



read the original abstract
In this paper, we study an emergent self-debiasing mechanisms against stereotypical content in Large Language Models (LLMs). Unlike traditional safety mechanisms that are primarily triggered by explicit input-level stimuli, self-debiasing mechanisms can involve generation-time intrinsic correction that are not directly reducible to surface-level prompt. Motivated by conflict-monitoring and response-inhibition accounts in cognitive neuroscience, we propose COCO, a contrastive causal method designed to identify COCO neurons that exhibit high intra-\underline{CO}nsistency yet sharp inter-\underline{CO}ntrast across antithetical generative responses, such as stereotypical versus unbiased outputs. Ablation studies reveal that deactivating COCO neurons leads to a catastrophic collapse of the model's fairness; over 90\% of outputs revert to biased content, far exceeding the bias levels induced by explicit adversarial jailbreak attacks. Observing that simple weight amplification of COCO neurons yields only marginal gains, we propose two training-free, lightweight editing strategies: Local Enhancement (LE-COCO) and Networked Enhancement (NE-COCO). Comprehensive evaluations show that our methods bolster robustness against adversarial jailbreaks and achieve strong performance on open-ended safety benchmarks, while preserving foundational generative proficiency. While this study primarily addresses social stereotypes, the COCO mechanism holds significant potential for diverse domains like hallucination detection, offering valuable insights toward the development of self-evolving AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes COCO, a contrastive causal method to identify 'COCO neurons' in LLMs that show high intra-consistency within stereotypical or unbiased generations but large inter-contrast between them. Motivated by cognitive neuroscience accounts of conflict monitoring and response inhibition, the authors claim that ablating these neurons causes over 90% of outputs to revert to biased content—exceeding effects from explicit jailbreak attacks. They introduce two training-free editing strategies (LE-COCO and NE-COCO) that improve robustness on safety benchmarks while preserving generative performance, with potential extension to hallucination detection.
Significance. If the COCO neurons can be shown to implement a specific implicit conflict-monitoring function rather than simply encoding one response class, the work would advance mechanistic understanding of emergent self-debiasing in LLMs and supply practical, lightweight editing techniques. The training-free nature and reported gains over jailbreaks are potentially useful, but the current evidence does not yet establish the functional interpretation or the claimed superiority.
major comments (3)
- [Abstract] Abstract: The central claim that ablating COCO neurons produces 'catastrophic collapse' with >90% reversion to biased outputs is presented without any description of how the 90% figure was computed, the evaluation dataset size or composition, statistical significance tests, or controls for neuron selection criteria. This information is load-bearing for the causal interpretation of conflict monitoring.
- [Abstract] Abstract: The contrastive selection criterion (high intra-consistency within each class but sharp inter-contrast) selects neurons that differentiate stereotypical from unbiased outputs by construction. Ablation is therefore expected to shift the output distribution toward the alternative class; this outcome does not require or demonstrate a dedicated conflict-detection or inhibition mechanism.
- [Abstract] Abstract: No activation-timing analysis, controlled intervention experiments, or other evidence is supplied to show that the selected neurons activate preferentially upon internal detection of a stereotype conflict rather than simply participating in unbiased continuation generation. The neuroscience analogy therefore rests on an untested functional interpretation.
minor comments (2)
- [Abstract] The acronym COCO is expanded via underlined letters in the abstract but the full phrase is not stated explicitly, which may hinder readability.
- Quantitative results, dataset descriptions, and ablation controls are summarized at a high level; the manuscript would be strengthened by including these details in the main text or a dedicated methods/results section.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating planned revisions where the manuscript can be strengthened without misrepresenting our findings.
read point-by-point responses
-
Referee: The central claim that ablating COCO neurons produces 'catastrophic collapse' with >90% reversion to biased outputs is presented without any description of how the 90% figure was computed, the evaluation dataset size or composition, statistical significance tests, or controls for neuron selection criteria. This information is load-bearing for the causal interpretation of conflict monitoring.
Authors: We agree that the abstract would benefit from additional methodological context. The full manuscript details the computation of the reversion rate, the prompt dataset used for evaluation, and associated statistical analyses in the experimental results section. We will revise the abstract to incorporate a concise summary of these elements to support the causal claims. revision: yes
-
Referee: The contrastive selection criterion (high intra-consistency within each class but sharp inter-contrast between them) selects neurons that differentiate stereotypical from unbiased outputs by construction. Ablation is therefore expected to shift the output distribution toward the alternative class; this outcome does not require or demonstrate a dedicated conflict-detection or inhibition mechanism.
Authors: The selection criterion is contrastive by design, yet the manuscript shows that ablation of these specific neurons produces a collapse exceeding that from explicit jailbreak attacks, while their enhancement yields targeted robustness improvements not achieved by generic weight scaling. To address the concern, we will add controls ablating neurons selected under alternative criteria in the revised manuscript to demonstrate the specificity of the intra-consistency and inter-contrast properties. revision: partial
-
Referee: No activation-timing analysis, controlled intervention experiments, or other evidence is supplied to show that the selected neurons activate preferentially upon internal detection of a stereotype conflict rather than simply participating in unbiased continuation generation. The neuroscience analogy therefore rests on an untested functional interpretation.
Authors: The ablation and enhancement interventions constitute controlled experiments establishing the causal necessity and sufficiency of the identified neurons for maintaining unbiased generation. We acknowledge that activation timing analysis is not included and will expand the discussion to clarify the scope of the functional interpretation and the limits of the neuroscience analogy based on the available causal evidence. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical contrastive method (COCO) for neuron identification based on activation consistency and contrast across output classes, followed by ablation experiments and editing strategies as validation steps. No equations, parameter fits, or self-citations are described that reduce any central claim (such as the ablation outcome or mechanism interpretation) to a definitional equivalence or by-construction result. The work presents standard experimental findings without load-bearing self-referential derivations, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
COCO neurons
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
C2-Score(N) = (L(A+,A−) + L(A−,A+))/2 ... lim C(A−)→0, C(A+)→0, D(A−,A+)→+∞
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Motivated by conflict-monitoring and response-inhibition accounts in cognitive neuroscience
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Journal of Neuroscience , year=
Error Effects in Anterior Cingulate Cortex Reverse when Error Likelihood Is High , author=. The Journal of Neuroscience , year=
-
[2]
Diane Swick and And U. Turken , title =. Proceedings of the National Academy of Sciences , volume =. 2002 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.252521499 , abstract =
-
[3]
Michael J. Frank and Brion S. Woroch and Tim Curran , abstract =. Error-Related Negativity Predicts Reinforcement Learning and Conflict Biases , journal =. 2005 , issn =. doi:https://doi.org/10.1016/j.neuron.2005.06.020 , url =
-
[4]
A Statistical Physics of Language Model Reasoning , author=. 2025 , eprint=
work page 2025
-
[5]
Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs , author=. 2025 , eprint=
work page 2025
-
[6]
Efficient Streaming Language Models with Attention Sinks , author=. ArXiv , year=
-
[7]
Neuron-Level Knowledge Attribution in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[8]
Gender bias and stereotypes in Large Language Models , url=
Kotek, Hadas and Dockum, Rikker and Sun, David , year=. Gender bias and stereotypes in Large Language Models , url=. doi:10.1145/3582269.3615599 , booktitle=
-
[9]
Semantics derived automatically from language corpora necessarily contain human biases , volume =
Caliskan-Islam, Aylin and Bryson, Joanna and Narayanan, Arvind , year =. Semantics derived automatically from language corpora necessarily contain human biases , volume =. Science , doi =
-
[10]
Conference on Empirical Methods in Natural Language Processing , year=
Neuron-Level Knowledge Attribution in Large Language Models , author=. Conference on Empirical Methods in Natural Language Processing , year=
- [11]
-
[12]
LLaMA: Open and Efficient Foundation Language Models , author=. ArXiv , year=
-
[13]
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
work page 2019
-
[14]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[15]
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models , author=. 2024 , eprint=
work page 2024
-
[16]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
work page 2018
-
[17]
Disentangling Language and Culture for Evaluating Multilingual Large Language Models , author=. 2025 , eprint=
work page 2025
-
[18]
Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , author=. 2025 , eprint=
work page 2025
-
[19]
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications , author=. 2024 , eprint=
work page 2024
-
[20]
Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting , author=. 2006 , url=
work page 2006
-
[21]
A new approach to linear filtering and prediction problems" transaction of the asme journal of basic , author=. 1960 , url=
work page 1960
-
[22]
A New Approach to Linear Filtering and Prediction Problems , author=. 2002 , url=
work page 2002
- [23]
- [24]
-
[25]
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. 2024 , eprint=
work page 2024
-
[26]
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks , author=. 2024 , eprint=
work page 2024
-
[27]
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
work page 2023
- [28]
- [29]
-
[30]
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , author=. 2016 , eprint=
work page 2016
-
[31]
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
work page 2023
-
[32]
Implicit: Investigating Social Bias in Large Language Models through Self-Reflection , author=
Explicit vs. Implicit: Investigating Social Bias in Large Language Models through Self-Reflection , author=. 2025 , eprint=
work page 2025
-
[33]
Shifting Perspectives: Steering Vectors for Robust Bias Mitigation in LLMs , author=. 2025 , eprint=
work page 2025
-
[34]
Towards Implicit Bias Detection and Mitigation in Multi-Agent LLM Interactions , author=. 2024 , eprint=
work page 2024
-
[35]
Zhao, Yachao and Wang, Bo and Wang, Yan and Zhao, Dongming and Jin, Xiaojia and Zhang, Jijun and He, Ruifang and Hou, Yuexian. A Comparative Study of Explicit and Implicit Gender Biases in Large Language Models via Self-evaluation. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-...
work page 2024
-
[36]
Semantics derived automatically from language corpora contain human-like biases,
Caliskan, Aylin and Bryson, Joanna J. and Narayanan, Arvind , year=. Semantics derived automatically from language corpora contain human-like biases , volume=. Science , publisher=. doi:10.1126/science.aal4230 , number=
-
[37]
North American Chapter of the Association for Computational Linguistics , year=
Gender Bias in Contextualized Word Embeddings , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[38]
PERCEPTRONS AND THE THEORY OF BRAIN MECHANISMS , author=
PRINCIPLES OF NEURODYNAMICS. PERCEPTRONS AND THE THEORY OF BRAIN MECHANISMS , author=. American Journal of Psychology , year=
- [39]
-
[40]
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[41]
Transformer Feed-Forward Layers Are Key-Value Memories , author=. 2021 , eprint=
work page 2021
-
[42]
Neural Machine Translation by Jointly Learning to Align and Translate , author=. 2016 , eprint=
work page 2016
-
[43]
Knowledge Neurons in Pretrained Transformers , author=. 2022 , eprint=
work page 2022
-
[44]
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
work page 2015
- [45]
-
[46]
Understanding and Enhancing Safety Mechanisms of
Yiran Zhao and Wenxuan Zhang and Yuxi Xie and Anirudh Goyal and Kenji Kawaguchi and Michael Shieh , booktitle=. Understanding and Enhancing Safety Mechanisms of. 2025 , url=
work page 2025
-
[47]
A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis , author=. 2023 , eprint=
work page 2023
-
[48]
Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models , author=. 2023 , eprint=
work page 2023
-
[49]
Bias and Fairness in Large Language Models: A Survey , author=. 2024 , eprint=
work page 2024
-
[50]
Debiasing Pretrained Text Encoders by Paying Attention to Paying Attention
Gaci, Yacine and Benatallah, Boualem and Casati, Fabio and Benabdeslem, Khalid. Debiasing Pretrained Text Encoders by Paying Attention to Paying Attention. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.651
-
[51]
B ias A lert: A Plug-and-play Tool for Social Bias Detection in LLM s
Fan, Zhiting and Chen, Ruizhe and Xu, Ruiling and Liu, Zuozhu. B ias A lert: A Plug-and-play Tool for Social Bias Detection in LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.820
-
[52]
Rethinking LLM Bias Probing Using Lessons from the Social Sciences , author=. 2025 , eprint=
work page 2025
-
[53]
Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes , author=. 2024 , eprint=
work page 2024
-
[54]
Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis , author=. 2024 , eprint=
work page 2024
-
[55]
Safety Layers in Aligned Large Language Models: The Key to LLM Security , author=. 2025 , eprint=
work page 2025
-
[56]
Robust Natural Language Understanding with Residual Attention Debiasing , author=. 2023 , eprint=
work page 2023
- [57]
-
[58]
Exploring the Linear Subspace Hypothesis in Gender Bias Mitigation , author=. 2024 , eprint=
work page 2024
-
[59]
Towards Understanding and Mitigating Social Biases in Language Models , author=. 2021 , eprint=
work page 2021
- [60]
-
[61]
LEACE: Perfect linear concept erasure in closed form , author=. 2025 , eprint=
work page 2025
- [62]
-
[63]
Entropy-based Attention Regularization Frees Unintended Bias Mitigation from Lists
Attanasio, Giuseppe and Nozza, Debora and Hovy, Dirk and Baralis, Elena. Entropy-based Attention Regularization Frees Unintended Bias Mitigation from Lists. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.88
- [64]
-
[65]
Prompting Fairness: Integrating Causality to Debias Large Language Models , author=. 2025 , eprint=
work page 2025
-
[66]
Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society , year=
Detecting Emergent Intersectional Biases: Contextualized Word Embeddings Contain a Distribution of Human-like Biases , author=. Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society , year=
work page 2021
-
[67]
May, Chandler and Wang, Alex and Bordia, Shikha and Bowman, Samuel R. and Rudinger, Rachel. On Measuring Social Biases in Sentence Encoders. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1063
- [68]
-
[69]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
work page 2023
-
[70]
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
work page 2022
-
[71]
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
work page 2021
-
[72]
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel. BBQ : A hand-built bias benchmark for question answering. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.165
-
[73]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
work page 2024
-
[74]
An Explanation of In-context Learning as Implicit Bayesian Inference , author=. ArXiv , year=
-
[75]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. 2022 , eprint=
work page 2022
-
[76]
Gender bias in coreference resolution: Evaluation and debiasing methods
Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2003
-
[77]
Bender, Timnit Gebru, Angelina McMillan-Major, and Margaret Mitchell
BOLD: Dataset and Metrics for Measuring Biases in Open-Ended Language Generation , author =. 2021 , isbn =. doi:10.1145/3442188.3445924 , booktitle =
-
[78]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[79]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.