Recognition: no theorem link
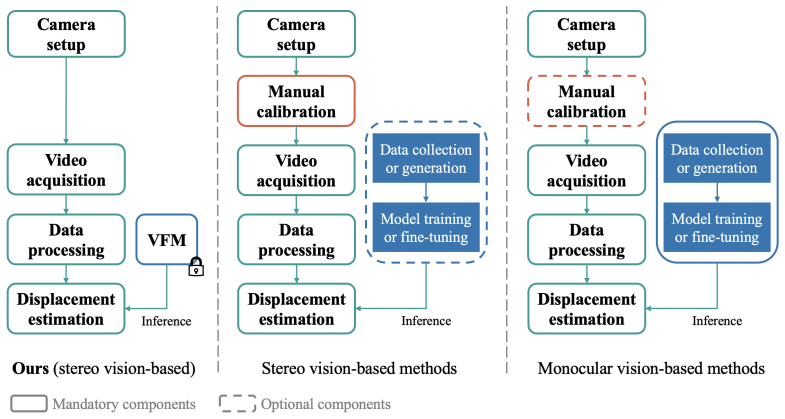
VFM-SDM: A vision foundation model-based framework for training-free, marker-free, and calibration-free structural displacement measurement
Pith reviewed 2026-05-12 04:05 UTC · model grok-4.3
The pith
Vision foundation models enable training-free, marker-free structural displacement measurement from video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
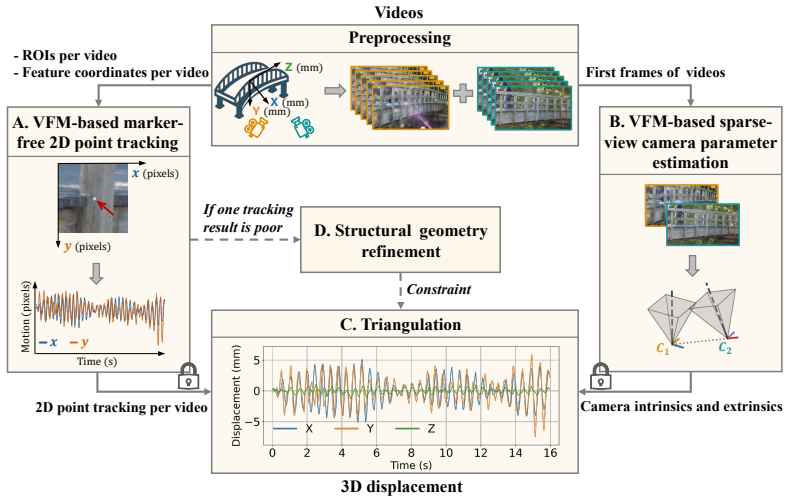
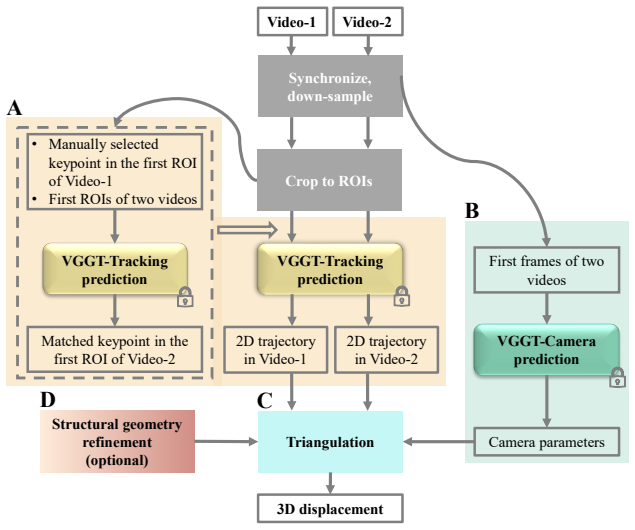
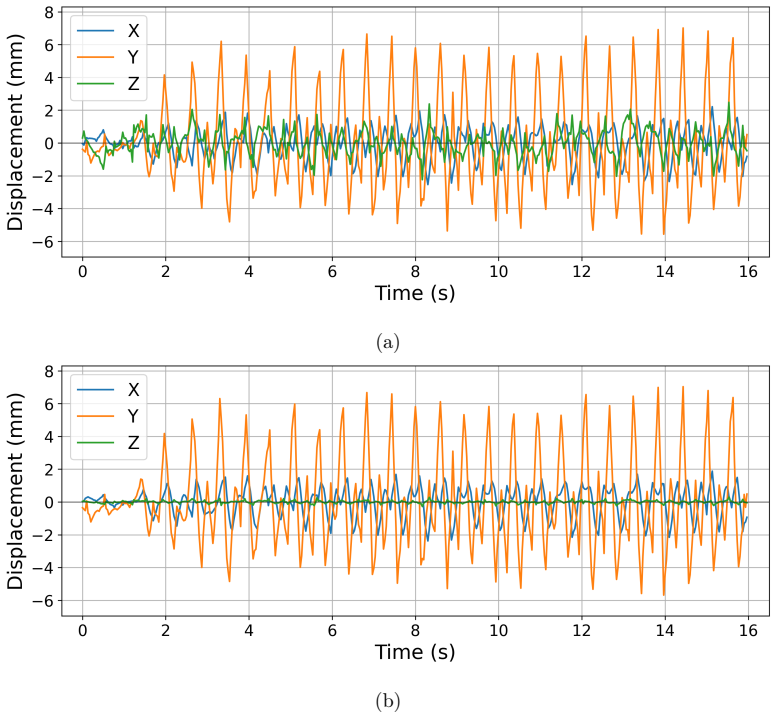
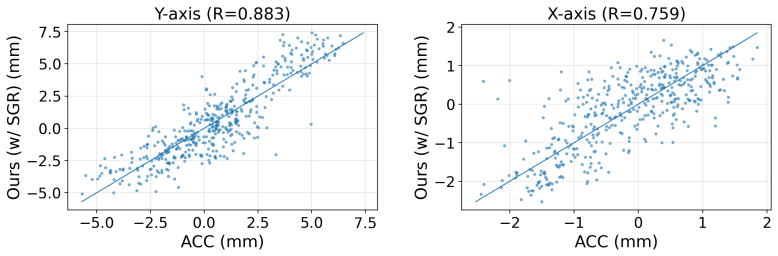
The VFM-SDM framework integrates VFM-inferred camera parameter estimation and point tracking to reconstruct multi-directional structural displacements via triangulation without task-specific training or on-site preparation. Structural geometry constraints suppress physically implausible deviations and improve estimation consistency. On a multi-modal field dataset from a pedestrian bridge, it reports NRMSE_range of 0.11/0.12, correlation coefficients of 0.86/0.88, and RPPAE of 0.01/0.02 for vertical and lateral displacements.
What carries the argument
VFM-inferred camera parameter estimation and point tracking combined with triangulation, regularized by structural geometry constraints.
If this is right
- Allows immediate deployment of non-contact displacement monitoring on existing structures without preparation steps.
- Produces consistent vertical and lateral displacement time series that match observed structural behavior.
- Provides a reproducible evaluation protocol using multi-modal field data for future comparisons.
- Supports scaling toward automated monitoring in digital twin and data-centric construction settings.
Where Pith is reading between the lines
- The same VFM components could be applied to other civil infrastructure like buildings or towers if the geometry constraints transfer.
- Processing speed improvements might enable near-real-time monitoring on standard hardware.
- Integration with existing structural analysis software could allow direct input of measured displacements into finite element models.
Load-bearing premise
Pre-trained vision foundation models can accurately estimate camera parameters and track points in real-world structural videos without fine-tuning or extra preparation.
What would settle it
Simultaneous reference sensor data from the same bridge showing displacement estimates with NRMSE_range above 0.3 or correlation below 0.7 under ordinary lighting and motion conditions.
Figures









read the original abstract
Reliable displacement measurement is fundamental for structural health monitoring and digital engineering workflows, as it provides direct structural response information. Vision-based measurement has emerged as a promising approach for low-cost, non-contact displacement monitoring. However, its deployment often remains constrained by task-specific model training or on-site preparation, such as marker installation or manual camera calibration. This study presents a Vision Foundation Model-based framework for Structural Displacement Measurement (VFM-SDM) that integrates VFM-inferred camera parameter estimation and point tracking to reconstruct multi-directional structural displacements via triangulation without task-specific training or on-site preparation, enabling efficient non-contact deployment in real-world applications. Structural geometry constraints are incorporated to suppress physically implausible deviations and improve estimation consistency. A multi-modal field dataset collected from an in-service pedestrian bridge is introduced alongside a unified benchmarking protocol to support reproducible evaluation. Representative results show low amplitude errors (NRMSE$_{\text{range}}$: 0.11/0.12), strong temporal agreement (correlation coefficient: 0.86/0.88), and small peak-to-peak amplitude errors (RPPAE: 0.01/0.02) for vertical and lateral displacements, indicating robust performance under real-world conditions. The proposed framework advances automated, scalable displacement monitoring and lays the groundwork for VFM-enabled structural response measurements in digital twin and data-centric construction workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VFM-SDM, a framework that uses vision foundation models to estimate camera parameters and track points in videos of structures, enabling multi-directional displacement measurement through triangulation. This is done without task-specific training, markers, or calibration, with structural geometry constraints to improve consistency. A new dataset from an in-service pedestrian bridge is introduced, and results show NRMSE_range of 0.11/0.12, correlations of 0.86/0.88, and low peak-to-peak errors.
Significance. If validated, the approach has high significance for structural health monitoring by providing a scalable, preparation-free method for displacement measurement using off-the-shelf models. The new field dataset and benchmarking protocol are valuable contributions that can facilitate reproducible research in applying VFMs to civil engineering tasks. It supports the shift towards data-centric and digital twin applications in construction.
major comments (2)
- [Methodology] The central claim depends on VFM zero-shot performance for camera intrinsics/extrinsics and point tracking being sufficiently accurate for triangulation to mm-scale displacements on low-texture bridge surfaces. However, no ablation is presented quantifying the raw VFM errors versus the final constrained estimates (see framework description and results), making it difficult to assess how much the geometry constraints suppress deviations versus how much systematic bias remains in the VFM outputs.
- [Experiments and Results] Results section, reported metrics (NRMSE_range 0.11/0.12, correlation 0.86/0.88): while the numbers are promising, the evaluation on a single bridge dataset lacks sensitivity analysis to VFM choice, illumination variation, or repetitive elements, and provides no baseline comparisons (e.g., calibrated traditional methods), which is load-bearing for the claim of reliable training-free performance.
minor comments (2)
- [Abstract] Abstract: the two values in NRMSE_range (0.11/0.12) and correlation (0.86/0.88) are not explicitly mapped to vertical versus lateral displacements; this should be clarified for immediate readability.
- [Introduction] Notation for RPPAE and other metrics could be defined more explicitly on first use in the main text to aid readers unfamiliar with structural monitoring conventions.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We have carefully reviewed the major concerns and provide detailed point-by-point responses below. Where appropriate, we will incorporate revisions to strengthen the presentation of the methodology and experimental validation.
read point-by-point responses
-
Referee: [Methodology] The central claim depends on VFM zero-shot performance for camera intrinsics/extrinsics and point tracking being sufficiently accurate for triangulation to mm-scale displacements on low-texture bridge surfaces. However, no ablation is presented quantifying the raw VFM errors versus the final constrained estimates (see framework description and results), making it difficult to assess how much the geometry constraints suppress deviations versus how much systematic bias remains in the VFM outputs.
Authors: We agree that quantifying the contribution of the geometry constraints is important for validating the framework. In the revised manuscript, we will add a dedicated ablation subsection that directly compares raw VFM-derived displacements (prior to constraint application) against the final geometry-constrained estimates. This will report per-axis errors, NRMSE, and correlation metrics on the bridge dataset to illustrate the degree of deviation suppression and any residual systematic biases. revision: yes
-
Referee: [Experiments and Results] Results section, reported metrics (NRMSE_range 0.11/0.12, correlation 0.86/0.88): while the numbers are promising, the evaluation on a single bridge dataset lacks sensitivity analysis to VFM choice, illumination variation, or repetitive elements, and provides no baseline comparisons (e.g., calibrated traditional methods), which is load-bearing for the claim of reliable training-free performance.
Authors: We acknowledge the value of additional robustness checks. The revised version will include sensitivity analysis across multiple VFM variants for both camera estimation and point tracking, along with qualitative discussion of performance under varying illumination and repetitive texture conditions observed in the dataset. For baselines, we will add quantitative comparisons against a calibrated traditional vision-based method applied to the same video sequences (where ground-truth calibration data is available), while noting that our approach avoids such preparation. Full exhaustive sensitivity across all environmental factors is limited by the single in-service dataset; we will explicitly discuss this as a limitation and outline directions for future multi-site validation. revision: partial
Circularity Check
No significant circularity; derivation relies on external pre-trained models and new data
full rationale
The paper presents VFM-SDM as an integration of off-the-shelf vision foundation models for camera parameter estimation and point tracking, followed by triangulation and structural geometry constraints on a newly collected multi-modal bridge dataset. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described framework. The central claims rest on external pre-trained VFMs and a reproducible benchmarking protocol rather than reducing to the paper's own inputs by construction. This is the expected honest non-finding for a method that delegates core vision tasks to independently trained models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Abu Dabous, S. Feroz, Condition monitoring of bridges with non- contact testing technologies, Automation in Construction 116 (2020) 103224. doi:10.1016/j.autcon.2020.103224
-
[2]
N. S. Gulgec, M. Takáč, S. N. Pakzad, Convolutional neural network approach for robust structural damage detection and localization, Jour- nal of Computing in Civil Engineering 33 (2019). doi:10.1061/(asce) cp.1943-5487.0000820
-
[3]
S. Ereiz, I. Duvnjak, J. Fernando Jiménez-Alonso, Review of finite element model updating methods for structural applications, Structures 41 (2022) 684–723. doi:10.1016/j.istruc.2022.05.041
-
[4]
V. Nicoletti, D. Arezzo, S. Carbonari, F. Gara, Dynamic monitoring of buildings as a diagnostic tool during construction phases, Journal of Building Engineering 46 (2022) 103764. doi:10.1016/j.jobe.2021. 103764
-
[5]
S.W.Doebling, C.R.Farrar, M.B.Prime, D.W.Shevitz, DamageIden- tification and Health Monitoring of Structural and Mechanical Systems from Changes in Their Vibration Characteristics: A Literature Review, Technical Report LA-13070-MS, Los Alamos National Laboratory, 1996. doi:10.2172/249299
-
[6]
A. Moreno-Gomez, C. A. Perez-Ramirez, A. Dominguez-Gonzalez, M. Valtierra-Rodriguez, O. Chavez-Alegria, J. P. Amezquita-Sanchez, Sensors used in structural health monitoring, Archives of Compu- tational Methods in Engineering 25 (2018) 901–918. doi:10.1007/ s11831-017-9217-4
work page 2018
- [7]
-
[8]
Y. Xiong, Z. Peng, G. Xing, W. Zhang, G. Meng, Accurate and ro- bust displacement measurement for fmcw radar vibration monitoring, IEEE Sensors Journal 18 (2018) 1131–1139. doi:10.1109/jsen.2017. 2778294. 55
-
[10]
M. Huang, B. Zhang, W. Lou, A. Kareem, A deep learning augmented vision-based method for measuring dynamic displacements of structures in harsh environments, Journal of Wind Engineering and Industrial Aerodynamics 217 (2021) 104758. doi:10.1016/j.jweia.2021.104758
-
[11]
Y.Weng, J.Shan, Z.Lu, X.Lu, B.F.Spencer, Homography-basedstruc- tural displacement measurement for large structures using unmanned aerial vehicles, Computer-Aided Civil and Infrastructure Engineering 36 (2021) 1114–1128. doi:10.1111/mice.12645
-
[12]
M. Bolognini, G. Izzo, D. Marchisotti, L. Fagiano, M. P. Limongelli, E. Zappa, Vision-based modal analysis of built environment structures with multiple drones, Automation in Construction 143 (2022) 104550. doi:10.1016/j.autcon.2022.104550
- [13]
-
[14]
S. Zhang, P. Ni, J. Wen, Q. Han, X. Du, K. Xu, Automated vision-based multi-plane bridge displacement monitoring, Automation in Construc- tion 166 (2024) 105619. doi:10.1016/j.autcon.2024.105619
-
[15]
Z. Zhang, A flexible new technique for camera calibration, IEEE Transactions on Pattern Analysis and Machine Intelligence 22 (2000) 1330–1334. doi:10.1109/34.888718
-
[16]
J. Wang, C. Rupprecht, D. Novotny, Posediffusion: Solving pose es- timation via diffusion-aided bundle adjustment, in: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2023, p. 9739–9749. doi:10.1109/iccv51070.2023.00896
-
[17]
C. Sun, D. Gu, Y. Zhang, X. Lu, Vision-based displacement measure- ment enhanced by super-resolution using generative adversarial net- 56 works, Structural Control and Health Monitoring 29 (2022). doi:10. 1002/stc.3048
work page 2022
-
[18]
D. Marchisotti, E. Zappa, Feasibility of drone-based modal analysis using tof-grayscale and tracking cameras, IEEE Transactions on Instru- mentation and Measurement 72 (2023) 1–10. doi:10.1109/tim.2023. 3281628
-
[19]
C. Zhang, Z. Lu, X. Li, Y. Zhang, X. Guo, A two-stage correction method for uav movement-induced errors in non-target computer vision- based displacement measurement, Mechanical Systems and Signal Pro- cessing 224 (2025) 112131. doi:10.1016/j.ymssp.2024.112131
-
[20]
Track anything: Segment anything meets videos.arXiv preprint arXiv:2304.11968, 2023
J.Yang, M.Gao, Z.Li, S.Gao, F.Wang, F.Zheng, Trackanything: Seg- ment anything meets videos, arXiv preprint arXiv:2304.11968 (2023). doi:10.48550/arXiv.2304.11968
-
[21]
C. Doersch, Y. Yang, M. Vecerik, D. Gokay, A. Gupta, Y. Aytar, J. Car- reira, A. Zisserman, Tapir: Tracking any point with per-frame initial- ization and temporal refinement, in: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2023, p. 10027–10038. doi:10.1109/iccv51070.2023.00923
-
[22]
J. Zhao, F. Hu, Y. Xu, W. Zuo, J. Zhong, H. Li, Structure-posenet for identification of dense dynamic displacement and three-dimensional poses of structures using a monocular camera, Computer-Aided Civil and Infrastructure Engineering 37 (2022) 704–725. doi:10.1111/mice. 12761
-
[23]
Y. Shao, L. Li, J. Li, Q. Li, S. An, H. Hao, Out-of-plane full-field vibra- tion displacement measurement with monocular computer vision, Au- tomation in Construction 165 (2024) 105507. doi:10.1016/j.autcon. 2024.105507
-
[24]
Y. Ruan, T. Huang, C. Yuan, G. Zong, Q. Kong, A lightweight binocular vision-supported framework for 3d structural dynamic response moni- toring, Computer-Aided Civil and Infrastructure Engineering 40 (2025) 4364–4377. doi:10.1111/mice.13452
-
[26]
Y. Shao, L. Li, J. Li, Q. Li, S. An, H. Hao, Dimmc: A 3d vision ap- proach for structural displacement measurement using a moving camera, Engineering Structures 338 (2025) 120566. doi:10.1016/j.engstruct. 2025.120566
-
[27]
J. Jiao, J. Guo, K. Fujita, I. Takewaki, Displacement measurement and nonlinear structural system identification: A vision-based approach with camera motion correction using planar structures, Structural Control and Health Monitoring 28 (2021). doi:10.1002/stc.2761
-
[28]
L. Xing, W. Dai, Y. Zhang, Improving displacement measurement accu- racy by compensating for camera motion and thermal effect on camera sensor, Mechanical Systems and Signal Processing 167 (2022) 108525. doi:10.1016/j.ymssp.2021.108525
-
[29]
T. Panigati, A. Abbozzo, M. A. Pace, E. Temur, F. Cigan, R. Kroma- nis, Dynamic identification of bridges using multiple synchronized cam- eras and computer vision, Infrastructures 10 (2025) 37. doi:10.3390/ infrastructures10020037
work page 2025
- [30]
-
[31]
X. Pan, T. Yang, 3d vision-based out-of-plane displacement quantifica- tion for steel plate structures using structure-from-motion, deep learn- ing, and point-cloud processing, Computer-Aided Civil and Infrastruc- ture Engineering 38 (2023) 547–561. doi:10.1111/mice.12906
-
[33]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, D. Novotny, Vggt: Visual geometry grounded transformer, in: 2025 IEEE/CVF Con- 58 ference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2025, p. 5294–5306. doi:10.1109/cvpr52734.2025.00499
-
[34]
A. Lin, J. Y. Zhang, D. Ramanan, S. Tulsiani, Relpose++: Re- covering 6d poses from sparse-view observations, in: 2024 Inter- national Conference on 3D Vision (3DV), IEEE, 2024, p. 106–115. doi:10.1109/3dv62453.2024.00126
-
[35]
Q. Xian, W. Jiao, H. Cheng, B. J. van der Zwaag, Y. Huang, T-graph: Enhancing sparse-view camera pose estimation by pairwise translation graph, ISPRS Journal of Photogrammetry and Remote Sensing 230 (2025) 109–125. doi:10.1016/j.isprsjprs.2025.08.031
-
[36]
R. Hartley, A. Zisserman, Multiple View Geometry in Computer Vision, Cambridge University Press, 2003. doi:10.1017/CBO9780511811685
-
[37]
X. Ji, Z. Miao, R. Kromanis, Vision-based measurements of deforma- tions and cracks for rc structure tests, Engineering Structures 212 (2020) 110508
work page 2020
-
[38]
R. Kromanis, P. Kripakaran, A multiple camera position approach for accurate displacement measurement using computer vision, Journal of Civil Structural Health Monitoring 11 (2021) 661–678. doi:10.1007/ s13349-021-00473-0
work page 2021
-
[39]
X. Pan, T. Yang, Y. Xiao, H. Yao, H. Adeli, Vision-based real-time structural vibration measurement through deep-learning-based detec- tion and tracking methods, Engineering Structures 281 (2023) 115676. doi:10.1016/j.engstruct.2023.115676
-
[40]
J. Jeong, H. Jo, Real-time generic target tracking for structural displace- ment monitoring under environmental uncertainties via deep learning, Structural Control and Health Monitoring 29 (2021). doi:10.1002/stc. 2902
work page doi:10.1002/stc 2021
-
[41]
Q. He, S. Wang, Improving 2d displacement accuracy in bridge vibration measurement with color space fusion and super resolution, Advanced Engineering Informatics 65 (2025) 103248. 59
work page 2025
- [42]
-
[43]
L. Luo, M. Q. Feng, Z. Y. Wu, Robust vision sensor for multi-point displacement monitoring of bridges in the field, Engineering Structures 163 (2018) 255–266. doi:10.1016/j.engstruct.2018.02.014
-
[44]
Y. Xu, J. Zhang, J. Brownjohn, An accurate and distraction-free vision-based structural displacement measurement method integrating siamese network based tracker and correlation-based template match- ing, Measurement 179 (2021) 109506. doi:10.1016/j.measurement. 2021.109506
-
[46]
Z. Ma, J. Choi, P. Liu, H. Sohn, Structural displacement estimation by fusing vision camera and accelerometer using hybrid computer vi- sion algorithm and adaptive multi-rate kalman filter, Automation in Construction 140 (2022) 104338. doi:10.1016/j.autcon.2022.104338
- [47]
-
[48]
D. Cui, W. Wang, Y. He, Y. Zhang, X. Zhang, Y. Zhao, Y. Zhang, Re- search on wide-area displacement monitoring based on rotating platform and binocular vision, Measurement 253 (2025) 117463. doi:10.1016/j. measurement.2025.117463
work page doi:10.1016/j 2025
-
[49]
C. Xie, B. Huang, Z. Wu, Y. Hu, K. Liang, J. Chen, A. Garg, G. Mei, A new economical approach for measurement of 3d structural displace- ment and motion trajectory: Utilizing binocular vision and subpixel en- hancement with square feature recognition, Structures 77 (2025) 109178. doi:10.1016/j.istruc.2025.109178. 60
-
[50]
Y. Shao, L. Li, J. Li, S. An, H. Hao, Computer vision based target- free 3d vibration displacement measurement of structures, Engineering Structures246(2021)113040.doi:10.1016/j.engstruct.2021.113040
-
[51]
J. Wu, Z. Ma, Y. Xue, J. Qin, D. You, G. Sun, Displacement monitor- ing and modal parameter identification of cable net structure based on feature optical flow and binocular stereo vision, Structures 76 (2025) 108914. doi:10.1016/j.istruc.2025.108914
-
[52]
Y. Narazaki, F. Gomez, V. Hoskere, M. D. Smith, B. F. Spencer, Efficient development of vision-based dense three-dimensional dis- placement measurement algorithms using physics-based graphics mod- els, Structural Health Monitoring 20 (2020) 1841–1863. doi:10.1177/ 1475921720939522
work page 2020
-
[53]
K. Lin, L. Wang, Z. Liu, End-to-end human pose and mesh reconstruc- tion with transformers, in: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2021, p. 1954–1963. doi:10.1109/cvpr46437.2021.00199
-
[54]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, R. Girshick, Segment anything, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4015–4026. doi:10. 1109/ICCV51070.2023.00371
-
[55]
A benchmark for the evaluation of RGB-D SLAM systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, D. Cremers, A bench- mark for the evaluation of rgb-d slam systems, in: 2012 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems, IEEE, 2012, p. 573–580. doi:10.1109/iros.2012.6385773
-
[56]
J. L. Schonberger, J.-M. Frahm, Structure-from-motion revisited, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2016, p. 4104–4113. doi:10.1109/cvpr.2016.445
-
[57]
B. Triggs, P. F. McLauchlan, R. I. Hartley, A. W. Fitzgibbon, Bundle Adjustment — A Modern Synthesis, Springer Berlin Heidelberg, 2000, p. 298–372. doi:10.1007/3-540-44480-7\_21
-
[58]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, H. Zhao, Depth anything: Unleashing the power of large-scale unlabeled data, in: 2024 IEEE/CVF 61 Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2024, p. 10371–10381. doi:10.1109/cvpr52733.2024.00987
-
[59]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al., Dinov2: Learning robust visual features without supervision, arXiv preprint arXiv:2304.07193 (2023). doi:10.48550/arXiv.2304.07193
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2023
-
[60]
R. Ranftl, A. Bochkovskiy, V. Koltun, Vision transformers for dense prediction, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2021, p. 12159–12168. doi:10.1109/iccv48922. 2021.01196
- [61]
-
[62]
R. J. Hyndman, A. B. Koehler, Another look at measures of fore- cast accuracy, International Journal of Forecasting 22 (2006) 679–688. doi:10.1016/j.ijforecast.2006.03.001
-
[63]
J. L. Rodgers, W. A. Nicewander, Thirteen ways to look at the correla- tion coefficient, The American Statistician 42 (1988) 59. doi:10.2307/ 2685263
work page 1988
-
[64]
C.-J. Kat, P. S. Els, Validation metric based on relative error, Math- ematical and Computer Modelling of Dynamical Systems 18 (2012) 487–520. doi:10.1080/13873954.2012.663392
-
[65]
C. Doersch, P. Luc, Y. Yang, D. Gokay, S. Koppula, A. Gupta, J. Hey- ward, I. Rocco, R. Goroshin, J. Carreira, A. Zisserman, BootsTAP: Bootstrapped Training for Tracking-Any-Point, Springer Nature Singa- pore, 2024, p. 483–500. doi:10.1007/978-981-96-0901-7\_28
-
[66]
D. DeTone, T. Malisiewicz, A. Rabinovich, Superpoint: Self-supervised interest point detection and description, in: 2018 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, 2018, p. 337–33712. doi:10.1109/cvprw.2018.00060. 62
-
[67]
nuScenes: A multimodal dataset for autonomous driving,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, A. Rabinovich, Superglue: Learning feature matching with graph neural networks, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2020, p. 4937–4946. doi:10.1109/cvpr42600.2020. 00499. Appendix A. Additional smartphone-based vibration sequence This appendix describes an additiona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.