Recognition: 1 theorem link
· Lean TheoremAbsurd World: A Simple Yet Powerful Method to Absurdify the Real-world for Probing LLM Reasoning Capabilities
Pith reviewed 2026-05-12 01:58 UTC · model grok-4.3
The pith
Altering real-world scenarios into absurd but logically identical versions reveals whether LLMs reason from logic or from memorized patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By breaking real-world scenarios into symbols, actions, sequences, and events and then automatically altering those elements to create absurd worlds, Absurd World keeps the original logic intact while stripping away learned real-world patterns, providing a direct test of whether LLMs solve problems through genuine reasoning.
What carries the argument
The Absurd World transformation that decomposes a scenario into symbols, actions, sequences, and events and replaces them with new ones while preserving solvability.
If this is right
- Models that succeed on standard versions but fail on absurd versions are using real-world patterns rather than logic.
- The same original problem can be turned into many absurd variants to test consistency of reasoning.
- Advanced prompting techniques can be measured for how much they improve performance on logic-only versions.
- The framework applies to any real-world task to verify whether reasoning is robust to changes in surface details.
Where Pith is reading between the lines
- The method offers an automated way to generate large numbers of test cases without manual rewriting of each problem.
- Standard benchmarks may overestimate reasoning ability if they only use familiar real-world settings.
- Similar absurdification could be applied to evaluate reasoning in other AI systems or domains.
Load-bearing premise
Automatically changing symbols, actions, sequences, and events always leaves the original logical relationships and solution method unchanged.
What would settle it
Finding a model that solves the absurd versions at the same rate as the original versions, or discovering an alteration that makes the problem unsolvable or logically different.
Figures




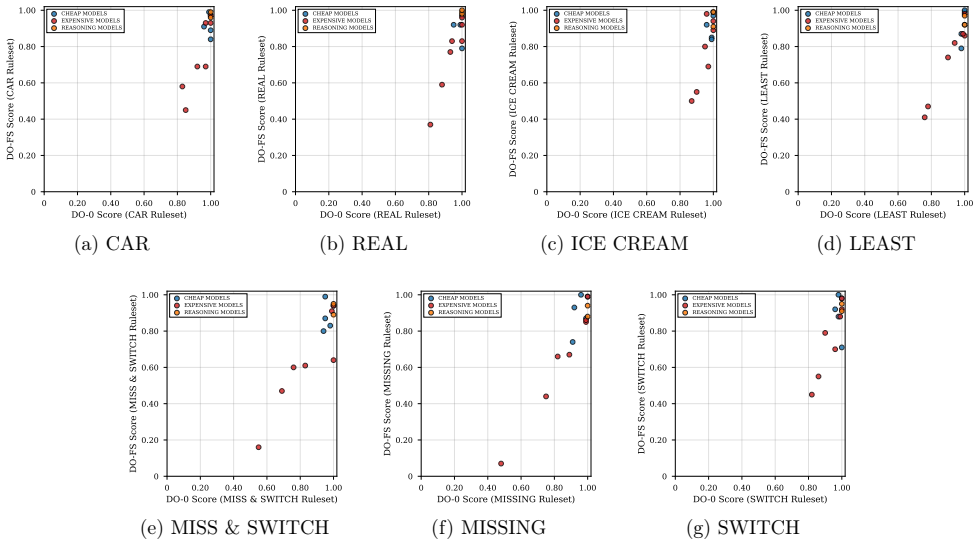
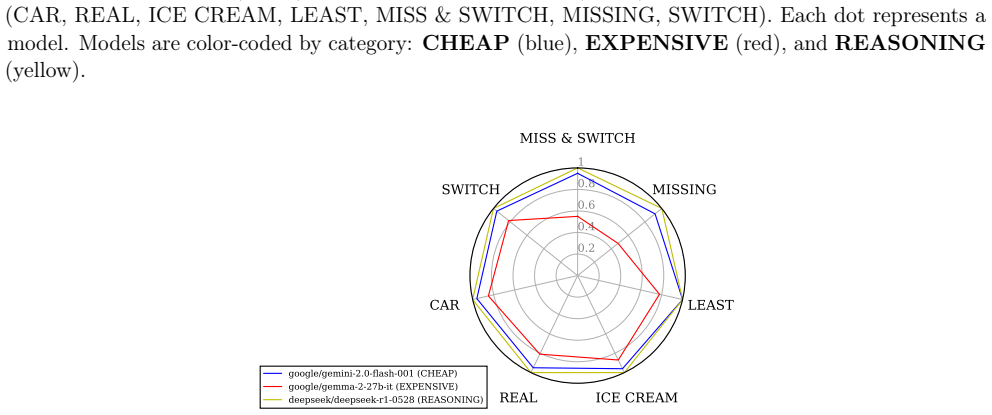


read the original abstract
While extremely powerful and versatile at various tasks, the thinking capabilities of large language models (LLMs) are often put under scrutiny as they sometimes fail to solve problems that humans can systematically solve. However, recent literature focuses on breaking LLM reasoning with increasingly complex problems, and whether an LLM is robust in simple logical reasoning remains underexplored. This paper proposes Absurd World, a benchmarking framework, to test LLMs against altered realism, where scenarios are logically coherent, and humans can easily solve the tasks. Absurd World breaks a real-world model into symbols, actions, sequences, and events, which are automatically altered to create absurd worlds where the logic to solve the tasks remains the same. It evaluates a large collection of models with simple and advanced prompting techniques, and proves that it is an effective tool to determine LLMs' ability to think logically, ignoring the patterns learned from the real world. One can use this framework to extensively test an LLM against a real-world problem to verify whether the LLM's reasoning capability is robust against variations of the task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Absurd World, a benchmarking framework that decomposes real-world scenarios into symbols, actions, sequences, and events, then automatically alters them to generate absurd but logically coherent variants. These variants are intended to preserve the original solution logic while stripping away real-world statistical patterns that LLMs might exploit. The work evaluates a collection of LLMs using both simple and advanced prompting techniques and claims to demonstrate that the framework effectively isolates and reveals deficiencies in logical reasoning.
Significance. If the transformations reliably preserve logical equivalence and eliminate exploitable cues, the framework could offer a practical, extensible method for constructing controlled probes of LLM reasoning that go beyond standard benchmarks prone to contamination from training data. This would help address the gap between models' apparent competence on familiar tasks and their robustness to logically equivalent but unfamiliar variants.
major comments (2)
- [Abstract] Abstract: the claim that the method 'proves that it is an effective tool to determine LLMs' ability to think logically, ignoring the patterns learned from the real world' is unsupported without quantitative results; the manuscript must report specific accuracy deltas, error breakdowns, and statistical tests comparing original vs. absurd variants across models and prompts.
- [Method] Method description: no formal preservation argument, human validation study, or cue-removal analysis is described for the automatic alteration of symbols/actions/sequences/events; without evidence that humans solve the absurd versions at rates comparable to the originals and that the new symbol sets introduce no learnable regularities, performance gaps cannot be attributed to logical-reasoning deficits rather than transformation artifacts.
minor comments (2)
- [Experiments] Clarify the exact number of models evaluated, the full list of prompting techniques, and the size of the task suite in the experiments section to allow reproducibility.
- [Introduction] The abstract and introduction would benefit from a brief comparison to related benchmarks (e.g., those using counterfactual or symbolic variants) to better situate the novelty of the automatic alteration pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'proves that it is an effective tool to determine LLMs' ability to think logically, ignoring the patterns learned from the real world' is unsupported without quantitative results; the manuscript must report specific accuracy deltas, error breakdowns, and statistical tests comparing original vs. absurd variants across models and prompts.
Authors: We agree that the abstract's phrasing is overly strong and that more explicit quantitative support would improve clarity. The manuscript already reports evaluation results across multiple LLMs and prompting methods on both original and absurd variants, showing performance differences. In revision we will change 'proves' to 'demonstrates' in the abstract, expand the results section with concrete accuracy deltas between conditions, per-model error breakdowns, and statistical tests (such as paired significance tests) comparing original versus absurd performance. revision: yes
-
Referee: [Method] Method description: no formal preservation argument, human validation study, or cue-removal analysis is described for the automatic alteration of symbols/actions/sequences/events; without evidence that humans solve the absurd versions at rates comparable to the originals and that the new symbol sets introduce no learnable regularities, performance gaps cannot be attributed to logical-reasoning deficits rather than transformation artifacts.
Authors: We acknowledge that additional validation would strengthen the attribution of performance gaps to reasoning rather than artifacts. The transformation is constructed to preserve logical structure by replacing surface elements while retaining relational dependencies and solution steps; we will add an explicit formal preservation argument to the method section. We will also incorporate a small-scale human validation study confirming comparable human accuracy on original and absurd versions, together with an analysis of symbol and sequence distributions to show that no new exploitable regularities are introduced. revision: yes
Circularity Check
No circularity: empirical benchmarking proposal with no derivation chain or self-referential reductions
full rationale
The paper presents Absurd World as an empirical benchmarking framework that breaks scenarios into symbols/actions/sequences/events and alters them to test LLM logical reasoning. No equations, first-principles derivations, or predictions are claimed; the work consists of method description followed by model evaluations under prompting techniques. The assertion that logic is preserved while real-world cues are removed is presented as a design property of the automatic alteration process rather than a result derived from prior fitted parameters or self-citations. No load-bearing step reduces to its own inputs by construction, and the central effectiveness claim rests on experimental outcomes rather than definitional equivalence. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearAbsurd World breaks a real-world model into symbols, actions, sequences, and events, which are automatically altered to create absurd worlds where the logic to solve the tasks remains the same.
Reference graph
Works this paper leans on
-
[1]
E. Abbe, S. Bengio, A. Lotfi, C. Sandon, and O. Saremi. How far can transformers reason? the globality barrier and inductive scratchpad. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=FoGwiFXzuN
work page 2024
-
[2]
J. Barron and D. White. Too big to think: Capacity, memorization, and generalization in pre-trained transformers, 2025. URLhttps://arxiv.org/abs/2506.09099
-
[3]
L. Berglund, M. Tong, M. Kaufmann, M. Balesni, A. C. Stickland, T. Korbak, and O. Evans. The reversal curse: Llms trained on "a is b" fail to learn "b is a", 2024. URLhttps://arxiv.org/abs/ 2309.12288
- [4]
-
[5]
Z. Han, F. Battaglia, K. Mansuria, Y. Heyman, and S. R. Terlecky. Beyond text generation: Assessing large language models’ ability to reason logically and follow strict rules.AI, 6(1), 2025. ISSN 2673-2688. doi: 10.3390/ai6010012. URLhttps://www.mdpi.com/2673-2688/6/1/12
-
[6]
K.-H. Huang, A. Prabhakar, O. Thorat, D. Agarwal, P. K. Choubey, Y. Mao, S. Savarese, C. Xiong, and C.-S. Wu. Crmarena-pro: Holistic assessment of llm agents across diverse business scenarios and interactions, 2025. URLhttps://arxiv.org/abs/2505.18878
- [7]
-
[8]
S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods, 2022. URLhttps://arxiv.org/abs/2109.07958
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [9]
-
[10]
I. R. McKenzie, A. Lyzhov, M. Pieler, A. Parrish, A. Mueller, A. Prabhu, E. McLean, A. Kirtland, A. Ross, A. Liu, A. Gritsevskiy, D. Wurgaft, D. Kauffman, G. Recchia, J. Liu, J. Cavanagh, M. Weiss, S. Huang, T. F. Droid, T. Tseng, T. Korbak, X. Shen, Y. Zhang, Z. Zhou, N. Kim, S. R. Bowman, and E. Perez. Inverse scaling: When bigger isn’t better, 2024. UR...
- [11]
-
[12]
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models
I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models, 2025. URL https://arxiv.org/abs/2410.05229
-
[13]
M. Nezhurina, L. Cipolina-Kun, M. Cherti, and J. Jitsev. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models, 2025. URL https://arxiv.org/abs/2406.02061
-
[14]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback, 2022. URLhttps://arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
P. Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity, 2025. URLhttps://arxiv.org/abs/2506.06941
- [17]
- [18]
- [19]
- [20]
- [21]
-
[22]
C. Zhao, Z. Tan, P. Ma, D. Li, B. Jiang, Y. Wang, Y. Yang, and H. Liu. Is chain-of-thought reasoning of llms a mirage? a data distribution lens, 2026. URLhttps://arxiv.org/abs/2508.01191
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y. Mao, X. Ma, A. Efrat, P. Yu, L. Yu, S. Zhang, G. Ghosh, M. Lewis, L. Zettlemoyer, and O. Levy. Lima: Less is more for alignment, 2023. URL https://arxiv.org/abs/2305.11206. 13 A DO-0 (zero-shot) performance per model in MISSING and MISS & SWITCH rulesets. 0.40 0.50 0.60 0.70 0.80 0.90 1.00 DO-0 Score (MISSING Ru...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.