Recognition: 2 theorem links
· Lean TheoremAdaptive Data Harvesting for Efficient Neural Network Learning with Universal Constraints
Pith reviewed 2026-05-12 04:12 UTC · model grok-4.3
The pith
A reinforcement learning policy can learn to adaptively select training samples to better enforce universal constraints in neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training a reinforcement learning policy on the network's performance history allows iterative, data-driven adjustment of input samples, resulting in higher empirical constraint satisfaction and greater efficiency on constraint-enforcement tasks for Lyapunov NNs and PINNs.
What carries the argument
The reinforcement learning policy that selects and adjusts training samples based on the neural network's current learning state and constraint violations.
If this is right
- Empirical constraint satisfaction improves on held-out test problems for both Lyapunov NNs and PINNs.
- Training efficiency increases significantly by reducing wasted samples that do not aid constraint enforcement.
- The same policy framework applies to other domains that require adaptive input selection during neural network training.
- No handcrafted sampling rules are needed once the policy is trained.
Where Pith is reading between the lines
- If the policy generalizes, practitioners could apply it to new constraint types without redesigning sampling heuristics each time.
- The method might allow training of larger constrained networks by focusing samples where violations are currently highest.
- Combining the policy with other adaptive techniques, such as curriculum learning on constraint difficulty, could yield further gains not explored here.
Load-bearing premise
A reinforcement learning policy trained on one set of evolving network performances can reliably choose better samples that generalize across different constraint problems and network architectures without introducing instability or requiring per-problem retuning.
What would settle it
Running the learned policy on new test problems and finding no measurable improvement in constraint satisfaction rates or training steps needed compared to fixed sampling heuristics would falsify the central claim.
Figures





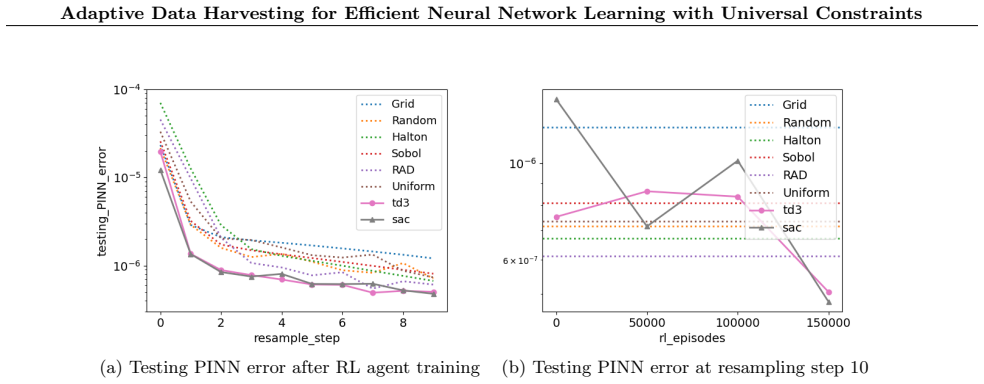

read the original abstract
Training neural networks to satisfy universal constraints over continuous domains poses unique challenges. Common examples include Lyapunov Neural Networks (Lyapunov NNs) and Physics-Informed Neural Networks (PINNs), where analytical solutions are generally either unavailable or overly restrictive. Sample-based methods are therefore commonly used to enforce these constraints, and the choice of samples has a substantial impact on convergence speed, stability, and solution quality. Most existing methods rely on fixed heuristics or handcrafted rules, and are suboptimal in practice. In this paper, we aim to improve upon them by learning, from data and experience, how to dynamically and iteratively adjust the samples in response to the model's evolving learning performance. Trained by reinforcement learning, the learned policy improves empirical constraint satisfaction on test problems while significantly improving efficiency. We validate the approach on both Lyapunov NNs and PINNs, and demonstrate its broader applicability to domains where adaptive input selection is essential for effective training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive data harvesting method that uses reinforcement learning to dynamically select training samples for neural networks enforcing universal constraints over continuous domains. The learned policy adjusts samples iteratively based on the network's evolving performance to improve constraint satisfaction and efficiency over fixed heuristics, with validation on Lyapunov Neural Networks and Physics-Informed Neural Networks, plus claims of applicability to other adaptive input selection domains.
Significance. If the empirical gains and generalization hold, the approach could meaningfully improve training stability and speed for constrained neural networks in control theory and physics-informed modeling by replacing handcrafted sampling rules with data-driven policies. The RL framing for this task is a reasonable extension of adaptive sampling ideas and, if reproducible, would provide a practical tool for domains where sample choice critically affects convergence.
major comments (2)
- The abstract asserts that the RL policy 'improves empirical constraint satisfaction on test problems while significantly improving efficiency' and generalizes across Lyapunov NNs, PINNs, and other domains, but supplies no metrics, baselines, statistical details, experimental setup, or cross-validation results. This is load-bearing for the central claim, as the reader's assessment notes the absence of any quantitative support.
- The key unverified assumption—that an RL policy trained on evolving network performance learns transferable features rather than problem-specific patterns, without instability or per-problem tuning—is not addressed with state/action/reward definitions, training distribution details, or generalization experiments. This directly risks the broader applicability claim.
minor comments (2)
- Clarify the precise definitions of state, action, and reward for the RL policy early in the manuscript to allow readers to assess transferability.
- The title uses 'Data Harvesting' which is evocative but could be supplemented with a subtitle or abstract sentence that explicitly mentions the RL policy for sampling.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting areas where the presentation of our results and methods could be strengthened. We address each major comment below with point-by-point responses and indicate the revisions we will make.
read point-by-point responses
-
Referee: The abstract asserts that the RL policy 'improves empirical constraint satisfaction on test problems while significantly improving efficiency' and generalizes across Lyapunov NNs, PINNs, and other domains, but supplies no metrics, baselines, statistical details, experimental setup, or cross-validation results. This is load-bearing for the central claim, as the reader's assessment notes the absence of any quantitative support.
Authors: We agree that the abstract is written at a high level and does not contain specific numerical results, which is common given length constraints. The full manuscript presents the quantitative evidence in Section 4, including metrics on constraint satisfaction and training efficiency, comparisons against fixed-heuristic and uniform-sampling baselines, statistical details from repeated trials, complete experimental setups, and cross-validation across problem instances for both Lyapunov NNs and PINNs. To make the central claim more immediately supported, we will revise the abstract to include a concise statement of the key empirical improvements. revision: partial
-
Referee: The key unverified assumption—that an RL policy trained on evolving network performance learns transferable features rather than problem-specific patterns, without instability or per-problem tuning—is not addressed with state/action/reward definitions, training distribution details, or generalization experiments. This directly risks the broader applicability claim.
Authors: Section 3 of the manuscript defines the RL components: the state encodes the current network's constraint-violation profile and loss trajectory, the action selects new sample locations within the continuous domain, and the reward balances constraint satisfaction improvement against sample cost. Training uses a distribution of problems drawn from both Lyapunov NN and PINN families to promote transferable features. Generalization is evaluated on held-out test problems from each domain without per-problem retuning, with results reported in Section 4 showing stable performance. We will add an explicit paragraph in the methods section summarizing these design choices and the evidence for transferability to address the concern directly. revision: yes
Circularity Check
No circularity; empirical RL policy training is independent of claimed outcomes
full rationale
The paper describes an RL-based adaptive sampling method for constraint enforcement in NNs (Lyapunov NNs, PINNs). The central claim is that a trained policy improves empirical constraint satisfaction and efficiency on test problems. No derivation chain, equations, or self-citations are shown that reduce the result to a fitted parameter or input by construction. The method applies standard RL to evolving network performance without self-definitional loops, fitted-input predictions, or load-bearing self-citations that presuppose the target result. The approach is self-contained against external benchmarks via empirical validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate the process of selecting multiple batches of training points as a sequential decision-making problem... Trained by reinforcement learning, the learned policy improves empirical constraint satisfaction
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
task the RL agent to propose α... mixture weights... Algorithm 2 RL-Guided Adaptive Expansion ROA
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI) , year=
Hyp-RL: Hyperparameter Optimization by Reinforcement Learning , author=. Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI) , year=
-
[2]
Journal of Ambient Intelligence and Humanized Computing , volume=
RL based hyper-parameters optimization algorithm (ROA) for convolutional neural network , author=. Journal of Ambient Intelligence and Humanized Computing , volume=. 2023 , publisher=
work page 2023
-
[3]
Intelligent Data Engineering and Automated Learning – IDEAL 2024 , series=
Model-Based Meta-reinforcement Learning for Hyperparameter Optimization , author=. Intelligent Data Engineering and Automated Learning – IDEAL 2024 , series=. 2024 , publisher=
work page 2024
-
[4]
Proceedings of the 37th International Conference on Machine Learning (ICML) , volume=
Data Valuation using Reinforcement Learning , author=. Proceedings of the 37th International Conference on Machine Learning (ICML) , volume=. 2020 , organization=
work page 2020
-
[5]
RLBoost: Boosting supervised models using deep reinforcement learning , author=. Neurocomputing , volume=. 2025 , publisher=
work page 2025
-
[6]
International Conference on Learning Representations (ICLR) , year=
Learning to Teach , author=. International Conference on Learning Representations (ICLR) , year=
-
[7]
Proceedings of the 34th International Conference on Machine Learning (ICML) , volume=
Automated Curriculum Learning for Neural Networks , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , volume=. 2017 , organization=
work page 2017
-
[8]
International Conference on Learning Representations (ICLR) , year=
Neural Architecture Search with Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[9]
Proceedings of the 35th International Conference on Machine Learning (ICML) , year=
Addressing Function Approximation Error in Actor-Critic Methods , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , year=
-
[10]
Proceedings of the 35th International Conference on Machine Learning (ICML) , year=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. Proceedings of the 35th International Conference on Machine Learning (ICML) , year=
-
[11]
A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.cma.2022.115671 , url =
-
[12]
International Conference on Learning Representations (ICLR) , year=
Adversarial Adaptive Sampling: Unify PINN and Optimal Transport for the Approximation of PDEs , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
Journal of Computational Physics , volume=
Multi-stage neural networks: Function approximator of machine precision , author=. Journal of Computational Physics , volume=. 2024 , publisher=
work page 2024
-
[14]
An Importance Sampling Method for Generating Optimal Interpolation Points in Training Physics-Informed Neural Networks , author=. Mathematics , volume=. 2025 , publisher=
work page 2025
-
[15]
Ussr Computational Mathematics and Mathematical Physics , year=
On the distribution of points in a cube and the approximate evaluation of integrals , author=. Ussr Computational Mathematics and Mathematical Physics , year=
-
[16]
On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals , author=. Numerische Mathematik , year=
-
[17]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
work page 2019
-
[18]
Conference on Robot Learning (CoRL) , pages=
The Lyapunov neural network: Adaptive stability certification for safe learning of dynamical systems , author=. Conference on Robot Learning (CoRL) , pages=
-
[19]
Advances in neural information processing systems , volume=
Neural lyapunov control , author=. Advances in neural information processing systems , volume=
-
[20]
Control System Analysis and Design Via the “Second Method” of Lyapunov: II—Discrete-Time Systems , author=. Journal of Basic Engineering , volume=. 1960 , publisher=
work page 1960
-
[21]
IEEE transactions on neural networks and learning systems , volume=
Teacher--student curriculum learning , author=. IEEE transactions on neural networks and learning systems , volume=. 2019 , publisher=
work page 2019
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , pages=
Self-paced learning with diversity , author=. Advances in Neural Information Processing Systems (NeurIPS) , pages=
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume=
A Survey on Curriculum Learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , volume=. 2021 , publisher=
work page 2021
-
[24]
Advances in neural information processing systems , volume=
Reinforced continual learning , author=. Advances in neural information processing systems , volume=
-
[25]
Efficient Architecture Search for Continual Learning , year=
Gao, Qiang and Luo, Zhipeng and Klabjan, Diego and Zhang, Fengli , journal=. Efficient Architecture Search for Continual Learning , year=
-
[26]
Continual lifelong learning with neural networks: A review , author=. Neural Networks , volume=. 2019 , publisher=
work page 2019
-
[27]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International conference on machine learning , pages=
Curriculum learning by transfer learning: Theory and experiments with deep networks , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[29]
arXiv preprint arXiv:2001.08437 , year=
Multi-objective neural architecture search via non-stationary policy gradient , author=. arXiv preprint arXiv:2001.08437 , year=
-
[30]
arXiv preprint arXiv:2501.08422 , year=
AdaRFT: Efficient Reinforcement Finetuning via Adaptive Curriculum Learning , author=. arXiv preprint arXiv:2501.08422 , year=
-
[31]
arXiv preprint arXiv:2109.14152 , year=
Lyapunov-stable neural-network control , author=. arXiv preprint arXiv:2109.14152 , year=
-
[32]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Verified Safe Reinforcement Learning for Neural Network Dynamic Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[33]
IEEE Control Systems Letters , volume=
Formal synthesis of Lyapunov neural networks , author=. IEEE Control Systems Letters , volume=. 2020 , publisher=
work page 2020
-
[34]
Advances in neural information processing systems , volume=
Neural lyapunov control for discrete-time systems , author=. Advances in neural information processing systems , volume=
-
[35]
Inverse M-Kernels for Linear Universal Approximators of Non-Negative Functions , year =
Kim, Hideaki , booktitle =. Inverse M-Kernels for Linear Universal Approximators of Non-Negative Functions , year =
-
[36]
Lipschitz regularity of deep neural networks: analysis and efficient estimation , year =
Virmaux, Aladin and Scaman, Kevin , booktitle =. Lipschitz regularity of deep neural networks: analysis and efficient estimation , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.