Recognition: 2 theorem links
· Lean TheoremOne for All: A Non-Linear Transformer can Enable Cross-Domain Generalization for In-Context Reinforcement Learning
Pith reviewed 2026-05-12 03:41 UTC · model grok-4.3
The pith
Non-linear transformers represent value functions from different RL domains with shared weights when those functions lie in the same RKHS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
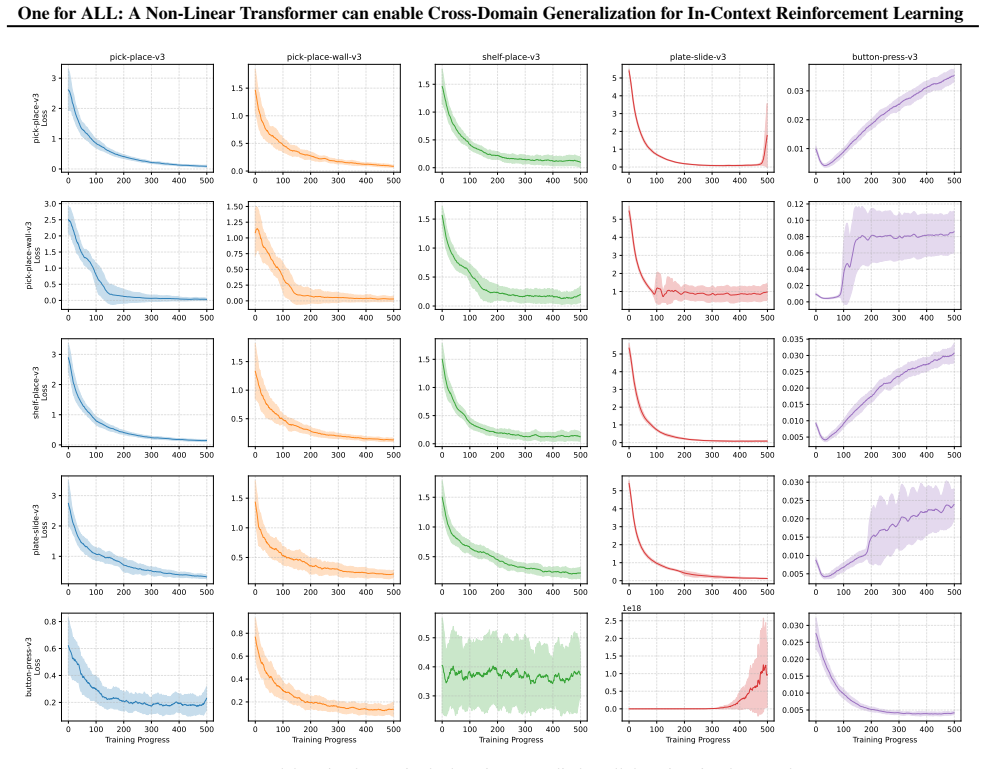
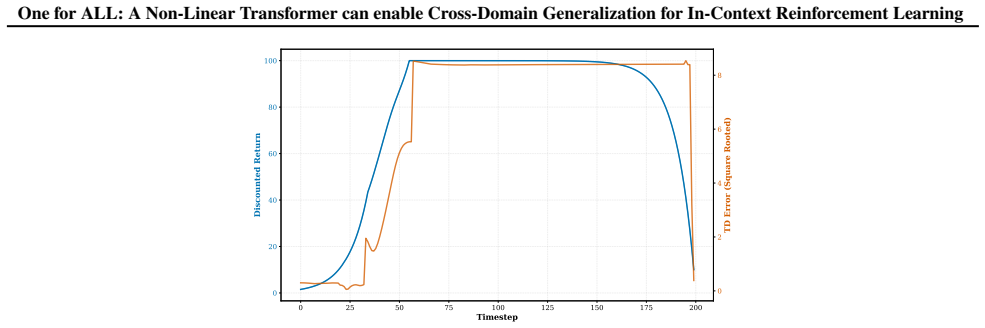
By interpreting the transformer as performing regression in a Reproducing Kernel Hilbert Space (RKHS), we show that value functions from different domains can be represented using a shared set of weights, provided they lie within the same RKHS. Experiments on multiple MetaWorld domains support this interpretation, demonstrating convergence of the temporal-difference objective.
What carries the argument
The transformer viewed as an RKHS regressor that maps a context prompt to a task-specific value function, allowing weight sharing across domains.
If this is right
- Value functions across domains share a single set of weights inside one RKHS.
- In-context learning with transformers produces task-specific value functions without gradient updates.
- The temporal-difference objective converges when the transformer operates under the shared RKHS view.
- Cross-domain generalization follows directly from the functional operator being domain-agnostic inside the RKHS.
Where Pith is reading between the lines
- Architectures could be explicitly regularized toward RKHS properties to enlarge the set of domains that can share weights.
- The same unification might extend to other in-context settings where underlying functions share a reproducing kernel.
- Measuring the RKHS distance between value functions of real environments would give a practical test for when the shared-weight regime holds.
Load-bearing premise
Non-linear transformers actually perform regression inside an RKHS and value functions from distinct domains truly inhabit one common RKHS.
What would settle it
Run the same transformer on value functions from two MetaWorld domains that cannot be expressed in a shared RKHS; if the temporal-difference loss fails to converge to a common solution or requires separate weights, the claim is false.
Figures





read the original abstract
A central challenge in reinforcement learning (RL) is to learn models that generalize beyond the tasks on which they are trained, a goal traditionally pursued through multi-task and meta RL. Recently, transformer architectures have emerged as a promising approach, enabling adaptation to new tasks via in-context learning without explicit parameter updates. From a functional perspective, a transformer can be viewed as a functional operator that maps a context to a task-specific function. It is thus fundamental to understand and design this operator to support stronger generalization in RL. In this work, we address this resulting question of generalization from a kernel-based perspective by establishing a connection between non-linear transformers and kernel-based temporal difference learning. By interpreting the transformer as performing regression in a Reproducing Kernel Hilbert Space (RKHS), we show that value functions from different domains can be represented using a shared set of weights, provided they lie within the same RKHS. Experiments on multiple MetaWorld domains support this interpretation, demonstrating convergence of the temporal-difference objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that non-linear transformers can be interpreted as performing regression in a Reproducing Kernel Hilbert Space (RKHS), establishing a link to kernel-based temporal difference learning. This interpretation implies that value functions from different domains can be represented using a shared set of transformer weights provided they lie in the same RKHS, enabling cross-domain generalization in in-context RL without parameter updates. Experiments on multiple MetaWorld domains are presented as support, showing convergence of the temporal-difference objective.
Significance. If the transformer-RKHS equivalence and the shared-RKHS condition for cross-domain value functions hold, the work would provide a principled functional view of in-context adaptation in RL, potentially unifying transformer-based meta-RL with kernel methods and guiding the design of more generalizable operators. The reported TD convergence on MetaWorld tasks is a useful empirical signal, though its explanatory power depends on verification of the underlying assumptions.
major comments (2)
- Abstract: the statement that experiments demonstrate convergence of the TD objective is presented without derivation details for the transformer-to-RKHS mapping, without error bars or statistical tests, and without any account of how RKHS membership was verified or enforced.
- Experiments section: the reported results show TD-objective convergence across MetaWorld domains but contain no diagnostic checks for the central shared-RKHS claim (e.g., no kernel Gram-matrix analysis, no RKHS-norm comparisons across domains, and no ablation that would be expected to fail if the RKHSs were disjoint). Convergence alone therefore does not distinguish the proposed mechanism from alternative explanations.
minor comments (3)
- Add error bars, multiple random seeds, and statistical significance tests to all experimental plots and tables.
- Provide a clearer, step-by-step derivation in the theoretical section that shows how the non-linear transformer layers implement the RKHS regression operator independently of the fitted weights.
- Define the specific kernel and feature map used, and ensure consistent notation for the RKHS inner product and norm throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical and empirical contributions. We address each major comment below and will revise the manuscript accordingly to strengthen the experimental support and clarity.
read point-by-point responses
-
Referee: Abstract: the statement that experiments demonstrate convergence of the TD objective is presented without derivation details for the transformer-to-RKHS mapping, without error bars or statistical tests, and without any account of how RKHS membership was verified or enforced.
Authors: The transformer-to-RKHS mapping is derived in Section 3 of the manuscript. We will revise the abstract to explicitly reference this section and add a brief summary of the key steps. In the experiments section, we will include error bars computed over multiple random seeds and report statistical significance tests. RKHS membership follows from the universal kernel and the non-linear transformer architecture as established in the theory; we will add a short explanatory paragraph in the revised experiments section describing this enforcement. revision: yes
-
Referee: Experiments section: the reported results show TD-objective convergence across MetaWorld domains but contain no diagnostic checks for the central shared-RKHS claim (e.g., no kernel Gram-matrix analysis, no RKHS-norm comparisons across domains, and no ablation that would be expected to fail if the RKHSs were disjoint). Convergence alone therefore does not distinguish the proposed mechanism from alternative explanations.
Authors: We agree that additional diagnostics would more directly isolate the shared-RKHS mechanism. The current results demonstrate successful cross-domain in-context TD learning, which is predicted by the theory when value functions share an RKHS. In the revision we will add (i) Gram-matrix visualizations and RKHS-norm comparisons across domains in an appendix and (ii) an ablation using domains with deliberately mismatched feature spaces (hence disjoint RKHS) to show that generalization fails when the shared-RKHS condition is violated. These additions will help distinguish our account from alternatives. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper establishes an interpretive connection between non-linear transformers and kernel-based TD learning by viewing the transformer as RKHS regression. This leads to the claim that value functions from different domains share weights when in the same RKHS. The experiments report TD objective convergence across MetaWorld domains without any fitted parameters being renamed as predictions or any self-citation chains that reduce the central claim to unverified prior results by the same authors. No self-definitional loops, smuggled ansatzes, or uniqueness theorems imported from self-citations are present. The derivation remains self-contained as a proposed functional perspective backed by independent empirical convergence results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A non-linear transformer can be interpreted as performing regression in a Reproducing Kernel Hilbert Space.
- domain assumption Value functions from different domains lie in the same RKHS.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1 (In-context implementation of L steps of TD)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aky¨urek, E., Schuurmans, D., Andreas, J., Ma, T., and Zhou, D
URL https:// arxiv.org/abs/2306.00297. Aky¨urek, E., Schuurmans, D., Andreas, J., Ma, T., and Zhou, D. What learning algorithm is in-context learning? investigations with linear models,
-
[2]
What learning algorithm is in-context learning? investigations with linear models
URL https: //arxiv.org/abs/2211.15661. Cheng, X., Chen, Y ., and Sra, S. Transformers implement functional gradient descent to learn non-linear functions in context,
-
[3]
URL https://arxiv.org/abs/ 2312.06528. Choromanski, K., Likhosherstov, V ., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L., Belanger, D., Colwell, L., and Weller, A. Rethinking attention with performers,
-
[4]
Rethinking Attention with Performers
URL https://arxiv.org/abs/2009.14794. Dai, D., Sun, Y ., Dong, L., Hao, Y ., Ma, S., Sui, Z., and Wei, F. Why can gpt learn in-context? language models implic- itly perform gradient descent as meta-optimizers,
work page internal anchor Pith review arXiv 2009
-
[5]
Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers
URLhttps://arxiv.org/abs/2212.10559. El-Nouby, A., Touvron, H., Caron, M., Bojanowski, P., Douze, M., Joulin, A., Laptev, I., Neverova, N., Syn- naeve, G., Verbeek, J., and Jegou, H. Xcit: Cross- covariance image transformers,
-
[6]
URL https: //arxiv.org/abs/2106.09681. Engel, Y ., Mannor, S., and Meir, R. Reinforcement learning with gaussian processes. InProceedings of the 22nd International Conference on Machine Learning (ICML), pp. 201–208,
- [7]
-
[8]
Kirsch, L., Harrison, J., Freeman, C., Sohl-Dickstein, J., and Schmidhuber, J
URL https: //arxiv.org/abs/2405.20692. Kirsch, L., Harrison, J., Freeman, C., Sohl-Dickstein, J., and Schmidhuber, J. Towards general-purpose in-context learning agents. InNeurIPS 2023 Foundation Models for Decision Making Workshop,
-
[9]
arXiv preprint arXiv:2306.14892 , year=
URL https://arxiv.org/abs/2306.14892. Lin, L., Bai, Y ., and Mei, S. Transformers as decision makers: Provable in-context reinforcement learning via supervised pretraining,
-
[10]
URL https://arxiv. org/abs/2310.08566. Liu, H. and Abbeel, P. Emergent agentic transformer from chain of hindsight experience,
-
[11]
URL https:// arxiv.org/abs/2305.16554. Mahankali, A., Hashimoto, T. B., and Ma, T. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention,
-
[12]
URL https://arxiv.org/abs/2307.03576. Moeini, A., Wang, J., Beck, J., Blaser, E., Whiteson, S., Chandra, R., and Zhang, S. A survey of in-context re- inforcement learning,
-
[13]
arXiv preprint arXiv:2502.07978 , year=
URL https://arxiv. org/abs/2502.07978. Nguyen, T., Nguyen, T. M., Le, D. D., Nguyen, D. K., Tran, V .-A., Baraniuk, R. G., Ho, N., and Osher, S. J. Improving transformers with probabilistic attention keys,
-
[14]
URL https://arxiv.org/abs/2110.08678. Ormoneit, D. and Sen, S. Kernel-based reinforce- ment learning.Machine Learning, 49(2):161–178, November
- [15]
-
[16]
Associa- tion for Computing Machinery. ISBN 9781605585161. doi: 10.1145/1553374.1553504. URL https://doi. org/10.1145/1553374.1553504. Tsai, Y .-H. H., Bai, S., Yamada, M., Morency, L.-P., and Salakhutdinov, R. Transformer dissection: A unified un- derstanding of transformer’s attention via the lens of ker- nel,
-
[17]
URL https://arxiv.org/abs/1908. 11775. von Oswald, J., Niklasson, E., Randazzo, E., Sacramento, J., Mordvintsev, A., Zhmoginov, A., and Vladymyrov, M. Transformers learn in-context by gradient descent,
work page 1908
-
[18]
arXiv preprint arXiv:2212.07677 , title =
URLhttps://arxiv.org/abs/2212.07677. Wang, J., Blaser, E., Daneshmand, H., and Zhang, S. Trans- formers can learn temporal difference methods for in- context reinforcement learning,
-
[19]
Wang, X., Zhu, W., Saxon, M., Steyvers, M., and Wang, W
URL https: //arxiv.org/abs/2405.13861. Wang, X., Zhu, W., Saxon, M., Steyvers, M., and Wang, W. Y . Large language models are latent variable mod- els: Explaining and finding good demonstrations for in- context learning,
- [20]
-
[21]
URL https://arxiv.org/abs/ 2111.02080. Xu, X., Hu, D., and Lu, X. Kernel-based least squares policy iteration for reinforcement learning.Trans. Neur. Netw., 18(4):973–992, July
-
[22]
URL https://doi.org/ 10.1109/TNN.2007.899161
1109/TNN.2007.899161. URL https://doi.org/ 10.1109/TNN.2007.899161. Yu, T., Quillen, D., He, Z., Julian, R., Narayan, A., Shively, H., Bellathur, A., Hausman, K., Finn, C., and Levine, S. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
-
[23]
Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning, 2021
URL https: //arxiv.org/abs/1910.10897. Zhang, R., Frei, S., and Bartlett, P. L. Trained transformers learn linear models in-context,
-
[24]
URL https:// arxiv.org/abs/2306.09927. 10 One for ALL: A Non-Linear Transformer can enable Cross-Domain Generalization for In-Context Reinforcement Learning A. Construction Lemmas Lemma A.1(Construction for Attn1).Recall Attn˜h K,Q,V (Z) =V ZM ˜h(KZ, QZ) , with mask M as defined in (1). Let K= Id 0d×d 0d×1 0d×d 0d×d 0d×1 01×d 01×d 0 , Q= Id 0d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.