Recognition: 2 theorem links
· Lean TheoremWISTERIA: Learning Clinical Representations from Noisy Supervision via Multi-View Consistency in Electronic Health Records
Pith reviewed 2026-05-12 02:13 UTC · model grok-4.3
The pith
WISTERIA recovers latent clinical states from EHR by enforcing consistency across multiple noisy supervision views instead of fitting any single label set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WISTERIA models clinical labels in electronic health records as stochastic observations drawn from an underlying latent clinical state. It constructs multiple weak supervision operators from the data and optimizes representations so that the label distributions induced by each operator are consistent with one another. Ontology-aware regularization is added in label space to impose semantic structure. The resulting multi-view consistency acts as an implicit denoiser that recovers clinically meaningful structure by reconciling disagreement among the noisy labelers.
What carries the argument
Multi-view consistency enforcement across weak supervision operators, which reconciles noisy induced label distributions to approximate a shared latent clinical state.
If this is right
- Predictive performance improves on standard EHR benchmarks.
- Representations exhibit greater robustness when label noise is present.
- Cross-institutional generalization exceeds that of sequence-based pretraining objectives.
Where Pith is reading between the lines
- The same consistency principle could be tested on other weakly labeled medical data such as radiology reports or claims databases where multiple noisy proxies for patient state exist.
- If the approach succeeds, it reduces dependence on expensive expert-curated labels by turning readily available but imperfect signals into useful training signal.
- Combining the consistency objective with existing sequence encoders might produce hybrid models that inherit both denoising and temporal modeling strengths.
Load-bearing premise
That multiple weak supervision operators can be derived from EHR data such that requiring consistency among them isolates the true latent clinical state rather than shared noise or new artifacts.
What would settle it
Train WISTERIA and standard baselines on an EHR dataset whose labels have been corrupted with controlled, measured noise levels; if the consistency method does not maintain higher downstream accuracy or cross-site transfer as noise increases, the central claim is falsified.
Figures

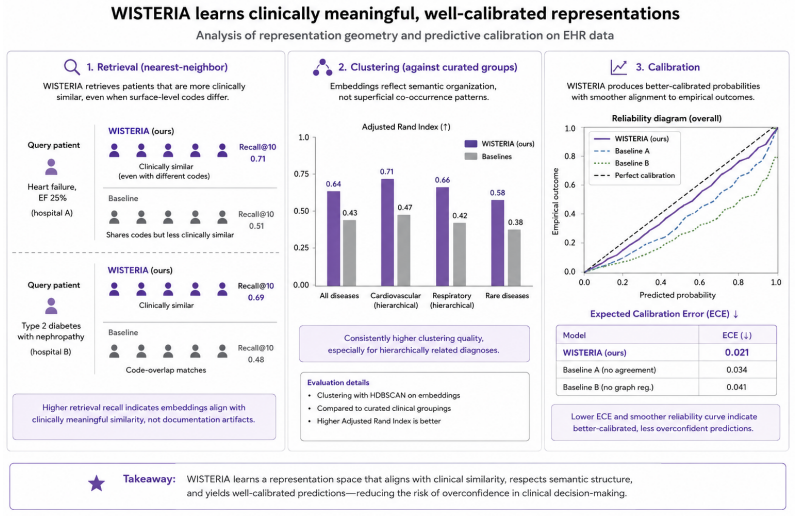
read the original abstract
Representation learning in electronic health records (EHR) has largely followed paradigms inherited from natural language processing, relying on sequence modeling and reconstruction based objectives that treat clinical labels as ground truth. However, real world clinical supervision is inherently weak, arising from heterogeneous, noisy, and institution specific labeling processes such as billing codes, heuristic phenotypes, and incomplete annotations. In this work, we propose WISTERIA, a weakly supervised representation learning framework that models labels as stochastic observations of an underlying latent clinical state. Instead of optimizing against a single supervision signal, WISTERIA constructs multiple weak supervision operators and learns representations by enforcing consistency across their induced label distributions. This multi view formulation induces an implicit denoising mechanism, allowing the model to recover clinically meaningful structure by reconciling disagreement between noisy labelers. We further incorporate ontology aware regularization in the label space to impose semantic structure over supervision signals. Empirically, WISTERIA improves predictive performance across standard EHR benchmarks, demonstrates strong robustness to label noise, and exhibits superior cross institutional generalization compared to sequence based pretraining objectives. These results suggest that explicitly modeling the supervision process rather than treating labels as fixed targets provides a more appropriate inductive bias for learning robust and clinically meaningful representations from EHR data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WISTERIA, a weakly supervised representation learning framework for EHR data. It models clinical labels as stochastic observations of a latent state rather than fixed targets, constructs multiple weak supervision operators (e.g., from billing codes, phenotypes, annotations), and learns by enforcing consistency across the induced label distributions, with added ontology-aware regularization in label space. The authors claim this yields improved predictive performance, robustness to label noise, and superior cross-institutional generalization relative to standard sequence-based pretraining objectives.
Significance. If the results hold under scrutiny, the work offers a meaningful shift in inductive bias for clinical representation learning by explicitly modeling the noisy supervision process. The multi-view consistency approach provides a principled mechanism for implicit denoising that could improve robustness in heterogeneous real-world EHR settings. This is a strength relative to purely reconstruction-based or single-target supervised methods.
major comments (1)
- Abstract and method description: the claim that 'enforcing consistency across their induced label distributions' induces an implicit denoising mechanism that recovers 'clinically meaningful structure' is load-bearing for all empirical claims. However, the weak supervision operators (billing codes, heuristic phenotypes, incomplete annotations) are constructed from overlapping EHR data processes and are therefore likely to share correlated errors (institution-specific coding practices, systematic missingness). When noise is correlated, consistency enforcement can converge to a biased consensus rather than the latent state; the ontology-aware regularization does not obviously break this correlation. The manuscript must provide either a theoretical argument or targeted experiments (e.g., controlled injection of correlated noise or ablation removing one operator class) demonstrating that the
minor comments (1)
- The abstract is information-dense; a single sentence clarifying the concrete construction of the weak supervision operators from raw EHR fields would improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's potential and for raising this important methodological concern about correlated noise across weak supervision views. We address the comment in detail below and commit to revisions that directly respond to it.
read point-by-point responses
-
Referee: Abstract and method description: the claim that 'enforcing consistency across their induced label distributions' induces an implicit denoising mechanism that recovers 'clinically meaningful structure' is load-bearing for all empirical claims. However, the weak supervision operators (billing codes, heuristic phenotypes, incomplete annotations) are constructed from overlapping EHR data processes and are therefore likely to share correlated errors (institution-specific coding practices, systematic missingness). When noise is correlated, consistency enforcement can converge to a biased consensus rather than the latent state; the ontology-aware regularization does not obviously break this correlation. The manuscript must provide either a theoretical argument or targeted experiments (e.g., controlled injection of correlated noise or ablation removing one operator class) demonstrating that the
Authors: We agree that this is a substantive point and that the current manuscript would be strengthened by explicitly addressing the risk of correlated errors. While the three operator classes are motivated by distinct clinical processes (administrative billing, rule-based phenotyping, and direct annotation), they can indeed share systematic biases. In the revision we will add both a concise theoretical argument and targeted experiments. The argument will formalize that the consistency objective, when combined with ontology regularization (which penalizes semantically implausible label co-occurrences), still recovers the latent state provided the views retain some conditionally independent noise; we will include a short derivation showing that the fixed point of the multi-view loss is the posterior over the latent state under a mixture-of-views noise model. Experimentally, we will insert (i) a controlled synthetic study that injects tunable levels of shared noise across views while holding independent noise fixed, and (ii) an ablation that systematically removes one operator class (e.g., phenotypes) and measures degradation in downstream performance and denoising quality. These additions will be placed in a new subsection of the methods and results and will be used to qualify the denoising claim in the abstract and introduction. We believe the revised manuscript will meet the referee's requirement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces WISTERIA as a modeling framework that explicitly constructs multiple weak supervision operators from EHR sources and enforces distributional consistency to recover latent states. This is an inductive bias choice with claimed empirical benefits on benchmarks and robustness tests, rather than any reduction of a claimed prediction to a fitted input or self-citation by construction. No equations, self-definitional steps, or load-bearing self-citations appear in the provided abstract or description that would make the central claim tautological. The derivation remains self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical labels are stochastic observations of an underlying latent clinical state
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WISTERIA constructs multiple weak supervision operators and learns representations by enforcing consistency across their induced label distributions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ontology-aware regularization in the label space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Foundation models for electronic health records: representation dynamics and transferability
Michael C Burkhart, Bashar Ramadan, Zewei Liao, Kaveri Chhikara, Juan C Rojas, William F Parker, and Brett K Beaulieu-Jones. Foundation models for electronic health records: representation dynamics and transferability.arXiv preprint arXiv:2504.10422,
-
[2]
Foundation models in healthcare: Opportunities, risks & strategies forward
Anja Thieme, Aditya Nori, Marzyeh Ghassemi, Rishi Bommasani, Tariq Osman Andersen, and Ewa Luger. Foundation models in healthcare: Opportunities, risks & strategies forward. InExtended abstracts of the 2023 CHI conference on human factors in computing systems, pages 1–4,
work page 2023
-
[3]
9 Manuel Burger, Daphné Chopard, Malte Londschien, Fedor Sergeev, Hugo Yèche, Rita Kuznetsova, Martin Faltys, Eike Gerdes, Polina Leshetkina, Peter Bühlmann, et al. A foundation model for intensive care: Unlocking generalization across tasks and domains at scale.medRxiv, pages 2025–07,
work page 2025
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
work page 2019
-
[5]
Deep Residual Learning for Image Recognition
URLhttps://arxiv.org/abs/1512.03385. Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 558–567,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2503.05768, 2025a. Yihan Lin, Zhirong Bella Yu, and Simon Lee. A case study exploring the current landscape of synthetic medical record generation with commercial llms.arXiv preprint arXiv:2504.14657, April
-
[7]
Wu Hao Ran, Xi Xi, Furong Li, Jingyi Lu, Jian Jiang, Hui Huang, Yuzhuan Zhang, and Shi Li. Structured semantics from unstructured notes: Language model approaches to ehr-based decision support.arXiv preprint arXiv:2506.06340,
-
[8]
Yuanyun Zhang and Shi Li. Chronoformer: Time-aware transformer architectures for structured clinical event modeling.arXiv preprint arXiv:2504.07373, 2025b. Simon A Lee and Timothy Lindsey. Can large language models abstract medical coded language? arXiv preprint arXiv:2403.10822,
-
[9]
Serialized ehr make for good text representations.arXiv preprint arXiv:2510.13843, 2025
10 Zhirong Chou, Quan Qin, and Shi Li. Serialized ehr make for good text representations.arXiv preprint arXiv:2510.13843,
-
[10]
Uncertainty-Aware Foundation Models for Clinical Data
Qian Zhou, Yuanyun Zhang, and Shi Li. Uncertainty-aware foundation models for clinical data. arXiv preprint arXiv:2604.04175,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Discriminative representation learning for clinical prediction.arXiv preprint arXiv:2603.20921,
Yang Zhang, Li Fan, Samuel Lawrence, and Shi Li. Discriminative representation learning for clinical prediction.arXiv preprint arXiv:2603.20921,
-
[12]
Learning clinical representations under systematic distribution shift
Yuanyun Zhang and Shi Li. Learning clinical representations under systematic distribution shift. arXiv preprint arXiv:2603.07348,
-
[13]
Simon A Lee, Cyrus Tanade, Hao Zhou, Juhyeon Lee, Megha Thukral, Minji Han, Rachel Choi, Md Sazzad Hissain Khan, Baiying Lu, Migyeong Gwak, et al. Himae: Hierarchical masked autoencoders discover resolution-specific structure in wearable time series.arXiv preprint arXiv:2510.25785, October
-
[14]
Salar Abbaspourazad, Oussama Elachqar, Andrew C Miller, Saba Emrani, Udhyakumar Nallasamy, and Ian Shapiro. Large-scale training of foundation models for wearable biosignals.arXiv preprint arXiv:2312.05409,
-
[15]
Salar Abbaspourazad, Anshuman Mishra, Joseph Futoma, Andrew C Miller, and Ian Shapiro. Wear- able accelerometer foundation models for health via knowledge distillation.arXiv preprint arXiv:2412.11276,
-
[16]
Brandon Westover, and Jimeng Sun
Chaoqi Yang, M. Brandon Westover, and Jimeng Sun. Biot: Biosignal transformer for cross-data learning in the wild. InNeurIPS 2023,
work page 2023
-
[17]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[18]
Adibvafa Fallahpour, Mahshid Alinoori, Wenqian Ye, Xu Cao, Arash Afkanpour, and Amrit Krishnan. Ehrmamba: Towards generalizable and scalable foundation models for electronic health records. arXiv preprint arXiv:2405.14567,
-
[19]
Simon A Lee, Sujay Jain, Alex Chen, Kyoka Ono, Jennifer Fang, Akos Rudas, and Jeffrey N Chiang. Emergency department decision support using clinical pseudo-notes.arXiv preprint arXiv:2402.00160,
-
[20]
11 Kyoka Ono and Simon A Lee. Text serialization and their relationship with the conventional paradigms of tabular machine learning.arXiv preprint arXiv:2406.13846,
-
[21]
Contrastive representation distilla- tion,
doi: 10.48550/arxiv.1910.10699. URLhttps://arxiv.org/abs/1910.10699. Timo Bertram, Johannes Fürnkranz, and Martin Müller. Contrastive learning of preferences with a contextual infonce loss,
-
[22]
Yonglong Tian, Dilip Krishnan, and Phillip Isola
URLhttps://arxiv.org/abs/2407.05898. Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vi- sion transformer for image classification. InProceedings of the IEEE/CVF international conference on computer vision, pages 357–366,
-
[23]
Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, Ethan Steinberg, Jason Alan Fries, Christopher Ré, Sanmi Koyejo, and Nigam H Shah. Context clues: Evaluating long context models for clinical prediction tasks on ehrs.arXiv preprint arXiv:2412.16178,
-
[24]
Mikkel Odgaard, Kiril Vadimovic Klein, Sanne Møller Thysen, Espen Jimenez-Solem, Martin Sillesen, and Mads Nielsen. Core-behrt: A carefully optimized and rigorously evaluated behrt. arXiv preprint arXiv:2404.15201,
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Generator: a long-context generative genomic foundation model
Wei Wu, Qiuyi Li, Yuanyuan Zhang, Zhihao Zhan, Ruipu Chen, Mingyang Li, Kun Fu, Junyan Qi, Yongzhou Bao, Chao Wang, et al. Generator: a long-context generative genomic foundation model. arXiv preprint arXiv:2502.07272,
-
[27]
Hybridna: A hybrid transformer-mamba2 long-range dna language model.arXiv preprint arXiv:2502.10807,
Mingqian Ma, Guoqing Liu, Chuan Cao, Pan Deng, Tri Dao, Albert Gu, Peiran Jin, Zhao Yang, Yingce Xia, Renqian Luo, et al. Hybridna: A hybrid transformer-mamba2 long-range dna language model.arXiv preprint arXiv:2502.10807,
-
[28]
Ariel Larey, Elay Dahan, Amit Bleiweiss, Raizy Kellerman, Guy Leib, Omri Nayshool, Dan Ofer, Tal Zinger, Dan Dominissini, Gideon Rechavi, et al. Jepa-dna: Grounding genomic foundation models through joint-embedding predictive architectures.arXiv preprint arXiv:2602.17162,
-
[29]
Ulzee An, Moonseong Jeong, Simon A Lee, Aditya Gorla, Yuzhe Yang, and Sriram Sankararaman. Raptor: Scalable train-free embeddings for 3d medical volumes leveraging pretrained 2d foundation models.arXiv preprint arXiv:2507.08254,
-
[30]
13 Haoran Lai, Zihang Jiang, Qingsong Yao, Rongsheng Wang, Zhiyang He, Xiaodong Tao, Wei Wei, Weifu Lv, and S Kevin Zhou. E3d-gpt: Enhanced 3d visual foundation for medical vision-language model.arXiv preprint arXiv:2410.14200,
-
[31]
Zixuan Liu, Hanwen Xu, Addie Woicik, Linda G Shapiro, Marian Blazes, Yue Wu, Cecilia S Lee, Aaron Y Lee, and Sheng Wang. Octcube: a 3d foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis.arXiv preprint arXiv:2408.11227, 2024b. Abdelrahman M Shaker, Muhammad Maaz, Hanoona Ra...
-
[32]
Simon A Lee, Anthony Wu, and Jeffrey N Chiang. Clinical modernbert: An efficient and long context encoder for biomedical text.arXiv preprint arXiv:2504.03964, April
-
[33]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Medhelm: Holistic evaluation of large language models for medical tasks.arXiv preprint arXiv:2505.23802,
-
[34]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 1(2),
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.